Uncalibrated Camera Based Content Generation for 3D Multi-View Displays
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

ACM Multimedia 2007
ACM Multimedia 2007 Call for Papers (PDF) University of Augsburg Augsburg, Germany September 24 – 29, 2007 http://www.acmmm07.org ACM Multimedia 2007 invites you to participate in the premier annual multimedia conference, covering all aspects of multimedia computing: from underlying technologies to applications, theory to practice, and servers to networks to devices. A final version of the conference program is now available. Registration will be open from 7:30am to 7pm on Monday and 7:30am to 5pm on Tuesday, Wednesday and Thursday On Friday registration is only possible from 7:30am to 1pm. ACM Business Meeting is schedule for Wednesday 9/26/2007 during Lunch (Mensa). Ramesh Jain and Klara Nahrstedt will talk about the SIGMM status SIGMM web status Status of other conferences/journals (TOMCCAP/MMSJ/…) sponsored by SIGMM Miscellaneous Also Chairs of MM’08 will give their advertisement Call for proposals for MM’09 + contenders will present their pitch Announcement of Euro ACM SIGMM Miscellaneous Travel information: How to get to Augsburg How to get to the conference sites (Augsburg public transport) Conference site maps and directions (excerpt from the conference program) Images of Augsburg The technical program will consist of plenary sessions and talks with topics of interest in: (a) Multimedia content analysis, processing, and retrieval; (b) Multimedia networking, sensor networks, and systems support; (c) Multimedia tools, end-systems, and applications; and (d) Multimedia interfaces; Awards will be given to the best paper and the best student paper as well as to best demo, best art program paper, and the best-contributed open-source software. -

Youtube Buys Green Parrot Pictures 15 March 2011
YouTube buys Green Parrot Pictures 15 March 2011 quality, steadier video -- all while your video is simply being uploaded to the site?" Technology developed by Green Parrot Pictures "can do exactly this," Doig said, and has been used by major studios on films such as "Lord of the Rings," "X-Men" and "Spider-Man." "Their technology helps make videos look better while at the same time using less bandwidth and improving playback speed," Doig said. Google-owned YouTube said Tuesday that it has bought (c) 2011 AFP an Irish digital video company whose technology can help improve the quality of amateur footage submitted to the video-sharing site. Google-owned YouTube said Tuesday that it has bought an Irish digital video company whose technology can help improve the quality of amateur footage submitted to the video-sharing site. Financial details of the acquisition of Green Parrot Pictures, which was founded by Anil Kokaram, an associate professor at the engineering school of Trinity College in Dublin, were not disclosed. YouTube said in a blog post that much of the 35 hours of video uploaded to the site every minute is "beautifully shot by professionals or aspiring filmmakers." "But some of YouTube's most popular or moving videos are shot using low-quality mobile phones and video cameras," said Jeremy Doig, director of Google Video Technology. "Take, for example, videos of recent protests in Libya," Doig said. "Although emotionally captivating, they can be jerky, blurry or unsteady. "What if there was a technology that could improve the quality of such videos -- sharpening the image, reducing visual noise and rendering a higher- 1 / 2 APA citation: YouTube buys Green Parrot Pictures (2011, March 15) retrieved 24 September 2021 from https://phys.org/news/2011-03-youtube-green-parrot-pictures.html This document is subject to copyright. -

ICIP 2007 Session Index
ICIP 2007 Session Index Monday Morning MA-L1: Video Coding for Next Generation Displays MA-L2: Image And Video Segmentation I MA-L3: Video Coding I MA-L4: Image and Video Restoration MA-L5: Biometrics I MA-L6: Image and Video Storage and Retrieval I MA-P1: Stereoscopic and 3D Processing I: Coding and Processing MA-P2: Active-Contour, Level-Set, and Cluster-Based Segmentation Methods MA-P3: Image and Video Denoising MA-P4: Biometrics II: Human Activity, Gait, Gaze Analysis MA-P5: Security I: Authentication and Steganography MA-P6: Image and Video Multiresolution Processing MA-P7: Motion Detection and Estimation I MA-P8: Image and Video Enhancement Monday Afternoon MP-L1: Distributed Source Coding I: Low Complexity Video Coding MP-L2: Image And Video Segmentation II: Texture Segmentation MP-L3: Interpolation and Superresolution I MP-L4: Image and Video Modeling I MP-L5: Security II MP-L6: Image Scanning, Display, Printing, Color and Multispectral Processing I MP-P1: Image and Video Storage and Retrieval II MP-P2: Morphological, Level-Set, and Edge or Color Image/Video Segmentation MP-P3: Scalable Video Coding MP-P4: Image Coding I MP-P5: Biometrics III: Fingerprints, Iris, Palmprints MP-P6: Biomedical Imaging I MP-P7: Motion Detection and Estimation II MP-P8: Stereoscopic and 3D Processing II: 3D Modeling & Synthesis Tuesday Morning TA-L1: Distributed Source Coding II: Distributed Image and Video Coding and Their Applications TA-L2: Image and Video Segmentation III: Edge or Color Segmentation TA-L3: Stereoscopic and 3D Processing III TA-L4: -

Measuring Noise Correlation for Improved Video Denoising
MEASURING NOISE CORRELATION FOR IMPROVED VIDEO DENOISING Anil Kokaram∗, Damien Kelly, Hugh Denman, Andrew Crawford Chrome Media Group, Google Inc, 1600 Amphitheatre Parkway, Mountain View, CA 94043, USA ABSTRACT The vast majority of previous work in noise reduction for visual me- dia has assumed uncorrelated, white, noise sources. In practice this is almost always violated by real media. Film grain noise is never 1 white, and this paper highlights that the same applies to almost all 0.8 0.6 consumer video content. We therefore present an algorithm for mea- 0.4 suring the spatial and temporal spectral density of noise in archived 0.2 0 video content, be it consumer digital camera or film orginated. As an 20 15 10 15 example of how this information can be used for video denoising, the 10 5 5 spectral density is then used for spatio-temporal noise reduction in 0 0 the Fourier frequency domain. Results show improved performance 1 for noise reduction in an easily pipelined system. 0.8 0.6 Index Terms— Noise Measurement, Video Denoising, Denois- 0.4 ing, Noise Reduction, Video Noise Reduction, Wiener Filter, 3D 0.2 0 20 Fourier Transform 15 10 20 5 15 10 5 0 0 1. INTRODUCTION Fig. 1. Two examples of typical footage (Top: Consumer footage, Noise reduction for video sequences is a well studied sig- Bottom: 2K Film scan), showing on the left the blocks over which nal processing topic. The core problem is always to remove the N-PSD (shown on the right) was measured. The maximum noise noise without affecting image details. -

Teaching Fellow
Find more on our web: hipeac.net/jobs/12290 Trinity College Dublin Dublin, Ireland Teaching Fellow • Deadline: May 21, 2021 • Career levels: PostDoc • Keywords: Computer architecture, Embedded / Cyber-Physical Systems, Reconfigurable computing Trinity College Dublin Academic Posts Open We are delighted to invite applications for 2 academic posts at Trinity College with the Electronic Engineering Dept. (https://www.tcd.ie/eleceng/) in the School of Engineering. The appointments are in the area of Computational Engin- eering at the level of Asst Prof (€35,509 - €86,247, 4.5 years) and Teaching Fellow (€35,509 - €46,266, 2.5 years). Fur- ther information and applications for these posts are at jobs.tcd.ie (select Academic->Engineering). The positions are part of the new Human Capital Initiative supported by the Government of Ireland. Successful candid- ates will contribute to Computational Engineering research and teaching in the Department. This includes Signal Pro- cessing (Video, Audio, Climate), Communications, Biomedical Engineering, Media Technology and design of computa- tional hardware (FPGAs, ASICS for high throughput computation). The appointees will deliver courses in computation- al methodology including numerical software programming skills (NumPy, TensorFlow etc), computational science and engineering. The Department has a long history of strong collaboration with industry e.g. Google, YouTube, Qualcomm and is espe- cially strong in communications (connectcentre.ie) , DSP, audio/video processing (sigmedia.tv, adaptcentre.ie). The School runs a vibrant Biomedical Engineering initiative with contributions from each of the 3 disciplines including EEE. Please contact [email protected] if further context is required. Further information and applications for these posts are at jobs.tcd.ie (select Academic->Engineering). -

UNIVERSITY of DUBLIN Trinity College Calendar Part 2
UNIVERSITY OF DUBLIN Trinity College Calendar Part 2 Graduate Studies and Higher Degrees 2006/2007 This Calendar, Part 2, contains all information concerning graduate studies in Trinity College, Dublin. The College is not bound by any error in, or omission from, the following information. Euro amounts have been calculated to the nearest unit. For a definitive list of charges and fees, please consult the University of Dublin Calendar Part 1 2006/2007. DEAN OF GRADUATE STUDIES Professor Patrick John Prendergast, B.A., B.A.I., Ph.D., C. Eng., F.I.E.I., F.T.C.D. (1998) STAFF OF THE GRADUATE STUDIES OFFICE Administrative Officers: Ewa Sadowska, M.Phil. (Warsaw), M. Litt., Grad. Dip. Bus. St. (N.C.E.A.), Dip. H.E.P. Helen Thornbury, B.A. (D.C.U.), M.A. (N.U.I.) Paula McDonagh, Dip.Lang.Bus.St. Senior Executive Officer: Michelle Greally, B.A., G.D.B.S. (IT) (N.C.E.A.) Executive Officers: Anne Doyle Teresa Fox Sinead O’Carroll Jacinta Ryan Bernadette Sherlock Yvonne Taylor B.Sc. (Open) ENQUIRIES AND CORRESPONDENCE: Address: Graduate Studies Office Trinity College Dublin 2, Ireland. Tel: +353-1-896 1166 Fax: +353-1-671 2821 Email: [email protected] The Graduate Studies Office is open mornings: 10 a.m. - 12.00 noon afternoons: 2 p.m. - 4 p.m. WEB SITE The Graduate Studies Office maintains a web site: http://www.tcd.ie/Graduate_Studies/ which has links to information on all postgraduate courses and programmes listed in this Calendar, Part 2. The Graduate Studies Office local page gives further details on course development, review, supervision, thesis submission and provides downloadable copies of various forms. -

Consistent Optical Flow for Stereo Video
2010 17th IEEE International Conference on Image Processing (ICIP 2010) Hong Kong 26 - 29 September 2010 Volume 1 Pages 1 - 804 IEEE Catalog Number: CFP10CIP-PRT ISBN: 978-1-4244-7992-4 1 / 6 TABLE OF CONTENTS MA-L1: IMAGE PROCESSING FOR STEREO DIGITAL CINEMA PRODUCTION MA-L1.1: CONSISTENT OPTICAL FLOW FOR STEREO VIDEO.............................................................1 Anita Sellent, Christian Linz, Marcus Magnor, Technische Universität Braunschweig, Germany MA-L1.2: NEW VIEW SYNTHESIS FOR STEREO CINEMA BY HYBRID DISPARITY .......................5 REMAPPING Frédéric Devernay, Sylvain Duchêne, INRIA, France MA-L1.3: STEREOSCOPIC CONTENT PRODUCTION OF COMPLEX DYNAMIC .............................9 SCENES USING A WIDE-BASELINE MONOSCOPIC CAMERA SET-UP Jean-Yves Guillemaut, Muhammad Sarim, Adrian Hilton, University of Surrey, United Kingdom MA-L1.4: PATCH-BASED RECONSTRUCTION AND RENDERING OF HUMAN HEADS .................13 David C. Schneider, Anna Hilsmann, Peter Eisert, Fraunhofer HHI, Germany MA-L1.5: ISSUES IN ADAPTING RESEARCH ALGORITHMS TO STEREOSCOPIC ........................17 VISUAL EFFECTS Peter Hillman, J.P. Lewis, Sebastian Sylwan, Erik Winquist, Weta Digital Ltd, New Zealand MA-L1.6: MATTING WITH A DEPTH MAP .................................................................................................21 Francois Pitie, Anil Kokaram, Trinity College Dublin, Ireland MA-L1.7: 3D VIDEO PERFORMANCE SEGMENTATION ........................................................................25 Tony Tung, Takashi Matsuyama, Kyoto -
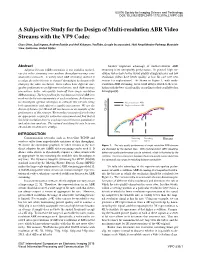
A Subjective Study for the Design of Multi-Resolution ABR Video Streams with the VP9 Codec
©2016 Society for Imaging Science and Technology DOI: 10.2352/ISSN.2470-1173.2016.2.VIPC-235 A Subjective Study for the Design of Multi-resolution ABR Video Streams with the VP9 Codec Chao Chen, Sasi Inguva, Andrew Rankin and Anil Kokaram, YouTube, Google Incorporated, 1600 Amphitheatre Parkway, Mountain View, California, United States Abstract Another important advantage of multi-resolution ABR Adaptive bit rate (ABR) streaming is one enabling technol- streaming is its rate-quality performance. In general, high res- ogy for video streaming over modern throughput-varying com- olution videos have better visual quality at high bit rates and low munication networks. A widely used ABR streaming method is resolution videos have better quality at low bit rate (see next to adapt the video bit rate to channel throughput by dynamically section for explanations). As shown in Figure 1, with multi- changing the video resolution. Since videos have different rate- resolution ABR streaming, users could always switch to the reso- quality performances at different resolutions, such ABR strategy lution with the best visual quality according to their available data can achieve better rate-quality trade-off than single resolution throughput[4]. ABR streaming. The key problem for resolution switched ABR is to work out the bit rate appropriate at each resolution. In this paper, we investigate optimal strategies to estimate this bit rate using Multi-resolution ABR both quantitative and subjective quality assessment. We use the Single-resolution ABR design of bitrates for 2K and 4K resolutions as an example of the Quality performance of this strategy. We introduce strategies for selecting an appropriate corpus for subjective assessment and find that at this high resolution there is good agreement between quantitative 4K and subjective analysis. -

The Life We Left Behind
The Life We Left Behind Disappearing Architecture is the title of a current exhibition at the Alma Jordan Library, featuring some of the work of artist, Jackie Hinkson. This building on the site of The UWI’s Health Education Unit at Warner Street, was once the residence of the DMO for the St. Augustine area. It was later converted into the first Law School building (run by the Council of Legal Education). For more on the exhibition, please see Page 13. PHOTO: SAFIYA ALFONSO. ECONOMY – 04 EDUCATION – 07 HONORARY Building Resilience Transforming Minds GRADUAND – 10 COTE 2012 Premium Teaching Awards Playful Science Maureen Manchouck PUBLIC HEALTH – 14 Walk for Sight Free Eye Care Symposium SUNDAY 28TH OCTOBER, 2012 – UWI TODAY 3 CAMPUS NEWS FROM THE Principal It’s Half-Marathon Day! What Sets Us Apart The ninth annual UWI SPEC Interna- Charles tional Half-Marathon presented by First Spooner Just yesterday we bid adieu to the final graduating Citizens, got off in the wee hours of this class of 2012. I am confident that our graduates will morning, and by the time you read this, do well in their chosen careers, once they continue to have faith in themselves, to be humble and open the challenge between the Kenyan athletes to learning new things and bring the focus and and the cream of Caribbean distance run- discipline they have honed at UWI to whatever ners would have been decided. tasks they may face. This year, our graduates The lead-up to this premier running totaled 3,643: 2,710 at the undergraduate level event had been rife with speculation over and 933 at the postgraduate level (a 6% increase the potency of what was deemed the here). -

Conference Program
CONTENTS FOREWORD ...................................................................................................................................................... 3 MAPS ............................................................................................................................................................... 7 AUGSBURG TRAM LINES .......................................................................................................................................... 7 LIVE ARTS EXHIBITION ............................................................................................................................................ 8 CONFERENCE SITE MAP .......................................................................................................................................... 9 FLOOR PLANS ..................................................................................................................................................... 10 1: Keynote and Best Paper Sessions ......................................................................................................... 10 2: Conference Sessions, Workshops, and Tutorials ................................................................................... 10 OVERVIEW OF THE FULL CONFERENCE PROGRAM ......................................................................................... 11 MONDAY, SEPTEMBER 24 ..................................................................................................................................... 11 -

Asst. Prof in Computational Engineering
Find more on our web: hipeac.net/jobs/12289 Trinity College Dublin Dublin, Ireland Asst. Prof in Computational Engineering • Deadline: May 25, 2021 • Career levels: Assistant Professor • Keywords: Computer architecture, Embedded / Cyber-Physical Systems, Reconfigurable computing Trinity College Dublin Academic Posts Open We are delighted to invite applications for 2 academic posts at Trinity College with the Electronic Engineering Dept (https://www.tcd.ie/eleceng/) in the School of Engineering. The appointments are in the area of Computational Engin- eering at the level of Asst Prof (€35,509 - €86,247, 4.5 years) and Teaching Fellow (€35,509 - €46,266, 2.5 years). Fur- ther information and applications for these posts are at jobs.tcd.ie (select Academic->Engineering). The positions are part of the new Human Capital Initiative supported by the Government of Ireland. Successful candid- ates will contribute to Computational Engineering research and teaching in the Department. This includes Signal Pro- cessing (Video, Audio, Climate), Communications, Biomedical Engineering, Media Technology and design of computa- tional hardware (FPGAs, ASICS for high throughput computation). The appointees will deliver courses in computation- al methodology including numerical software programming skills (NumPy, TensorFlow etc), computational science and engineering. The Department has a long history of strong collaboration with industry e.g. Google, YouTube, Qualcomm and is espe- cially strong in communications (connectcentre.ie) , DSP, audio/video processing (sigmedia.tv, adaptcentre.ie). The School runs a vibrant Biomedical Engineering initiative with contributions from each of the 3 disciplines including EEE. Please contact [email protected] if further context is required. Further information and applications for these posts are at jobs.tcd.ie (select Academic->Engineering). -

Incorporating Spatio-Temporal Mid-Level Features
2008 15th IEEE International Conference on Image Processing (ICIP 2008) San Diego, California, USA 12 – 15 October 2008 Pages 1-644 IEEE Catalog Number: CFP08CIP-PRT ISBN: 978-1-4244-1765-0 TABLE OF CON T EN T S WS-LW: ICIP WORKSHOP ON MULTIMEDIA INFORMATION RETRIEVAL ORAL SESSION WS-LW: INCORPORATING SPATIO-TEMPORAL MID-LEVEL FEATURES ......................................1 IN A REGION SEGMENTATION ALGORITHM FOR VIDEO SEQUENCES Iván González-Díaz, Universidad Carlos III de Madrid, Spain; Kevin McGuinness, Tomasz Adamek, Noel E. O’connor, Dublin City University, Ireland; Fernando Díaz-de-María, Universidad Carlos III de Madrid, Spain WS-LW: SPATIOTEMPORAL MODELING AND MATCHING OF VIDEO ............................................5 SHOTS Eric Galmar, Benoit Huet, EURECOM, France WS-LW: CROWD BEHAVIOURS ANALYSIS IN DYNAMIC VISUAL SCENES ....................................9 OF COMPLEX ENVIRONMENT Li-Qun Xu, Arasanathan Anjulan, British Telecommunications PLC, United Kingdom WS-LW: A PROBABILISTIC MODEL FOR FLOOD DETECTION IN VIDEO .....................................13 SEQUENCES Paulo Vinicius Koerich Borges, Queen Mary, University of London, United Kingdom; Joceli Mayer, Federal University of Santa Catarina, Brazil; Ebroul Izquierdo, Queen Mary, University of London, United Kingdom WS-PW: ICIP WORKSHOP ON MULTIMEDIA INFORMATION RETRIEVAL POSTER SESSION WS-PW: A GROUND-TRUTH FOR MOTION-BASED VIDEO-OBJECT ...............................................17 SEGMENTATION Fabrizio Tiburzi, Marcos Escudero, Jesús Bescós, José María Martínez,