A Study on South Ethiosemitic Languages
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
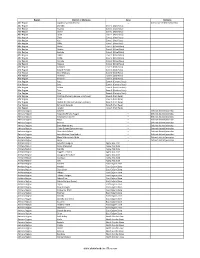
Districts of Ethiopia
Region District or Woredas Zone Remarks Afar Region Argobba Special Woreda -- Independent district/woredas Afar Region Afambo Zone 1 (Awsi Rasu) Afar Region Asayita Zone 1 (Awsi Rasu) Afar Region Chifra Zone 1 (Awsi Rasu) Afar Region Dubti Zone 1 (Awsi Rasu) Afar Region Elidar Zone 1 (Awsi Rasu) Afar Region Kori Zone 1 (Awsi Rasu) Afar Region Mille Zone 1 (Awsi Rasu) Afar Region Abala Zone 2 (Kilbet Rasu) Afar Region Afdera Zone 2 (Kilbet Rasu) Afar Region Berhale Zone 2 (Kilbet Rasu) Afar Region Dallol Zone 2 (Kilbet Rasu) Afar Region Erebti Zone 2 (Kilbet Rasu) Afar Region Koneba Zone 2 (Kilbet Rasu) Afar Region Megale Zone 2 (Kilbet Rasu) Afar Region Amibara Zone 3 (Gabi Rasu) Afar Region Awash Fentale Zone 3 (Gabi Rasu) Afar Region Bure Mudaytu Zone 3 (Gabi Rasu) Afar Region Dulecha Zone 3 (Gabi Rasu) Afar Region Gewane Zone 3 (Gabi Rasu) Afar Region Aura Zone 4 (Fantena Rasu) Afar Region Ewa Zone 4 (Fantena Rasu) Afar Region Gulina Zone 4 (Fantena Rasu) Afar Region Teru Zone 4 (Fantena Rasu) Afar Region Yalo Zone 4 (Fantena Rasu) Afar Region Dalifage (formerly known as Artuma) Zone 5 (Hari Rasu) Afar Region Dewe Zone 5 (Hari Rasu) Afar Region Hadele Ele (formerly known as Fursi) Zone 5 (Hari Rasu) Afar Region Simurobi Gele'alo Zone 5 (Hari Rasu) Afar Region Telalak Zone 5 (Hari Rasu) Amhara Region Achefer -- Defunct district/woredas Amhara Region Angolalla Terana Asagirt -- Defunct district/woredas Amhara Region Artuma Fursina Jile -- Defunct district/woredas Amhara Region Banja -- Defunct district/woredas Amhara Region Belessa -- -

The Case of Sasakawa Global 2000 Ethiopia in Gumer Woreda By
Addis Ababa University School of Graduate Studies College of Business and Economics Department of Public Administration and Development Management Assessing the role of Development partners on agricultural extension delivery: The case of Sasakawa Global 2000 Ethiopia in Gumer woreda By: Temesgen Tamrat Advisor: Mulugeta Abebe (PH.D) A thesis submitted to the School of Graduate Studies of Addis Ababa University in partial fulfillment of the requirements for the Degree of Masters in Public Management and Policy (MPMP) Specialized In Development Management June, 2017 Addis Ababa, Ethiopia Addis Ababa University School of Graduate Studies College of Business and Economics Department of Public Administration and Development Management This is to certify that the thesis prepared by Temesgen Tamrat Yohans entitled “Assessing the role of Development partners on agricultural extension delivery: The case of Sasakawa Global 2000 Ethiopia in Gumer woreda”, which is submitted in partial fulfillment of the requirements for the Degree of Public Management and Policy (MPMP), complies with the regulations of the University and meets the accepted standards with respect to standards to originality and quality. Approved by Board of Examiners: Mulugeta Abebe (PhD) ___________________ _______________ Advisor Signature Date Elias Berhanu (PhD) ___________________ _________________ Internal Examiner Signature Date Flimon Handaro (PhD) ___________________ _______________ External Examiner Signature Date Declaration Student ID: GSE/0632/06 I declare that this research report on ‘Assessing the role of Development partners on agricultural extension delivery:The case of Sasakawa Global 2000 Ethiopia in Gumer woreda’ is my own original work with assistances and guidance from my advisor and not submitted before for any institution and any purpose. -

Modeling Malaria Cases Associated with Environmental Risk Factors in Ethiopia Using Geographically Weighted Regression
MODELING MALARIA CASES ASSOCIATED WITH ENVIRONMENTAL RISK FACTORS IN ETHIOPIA USING GEOGRAPHICALLY WEIGHTED REGRESSION Berhanu Berga Dadi i MODELING MALARIA CASES ASSOCIATED WITH ENVIRONMENTAL RISK FACTORS IN ETHIOPIA USING THE GEOGRAPHICALLY WEIGHTED REGRESSION MODEL, 2015-2016 Dissertation supervised by Dr.Jorge Mateu Mahiques,PhD Professor, Department of Mathematics University of Jaume I Castellon, Spain Ana Cristina Costa, PhD Professor, Nova Information Management School University of Nova Lisbon, Portugal Pablo Juan Verdoy, PhD Professor, Department of Mathematics University of Jaume I Castellon, Spain March 2020 ii DECLARATION OF ORIGINALITY I declare that the work described in this document is my own and not from someone else. All the assistance I have received from other people is duly acknowledged, and all the sources (published or not published) referenced. This work has not been previously evaluated or submitted to the University of Jaume I Castellon, Spain, or elsewhere. Castellon, 30th Feburaury 2020 Berhanu Berga Dadi iii Acknowledgments Before and above anything, I want to thank our Lord Jesus Christ, Son of GOD, for his blessing and protection to all of us to live. I want to thank also all consortium of Erasmus Mundus Master's program in Geospatial Technologies for their financial and material support during all period of my study. Grateful acknowledgment expressed to Supervisors: Prof.Dr.Jorge Mateu Mahiques, Universitat Jaume I(UJI), Prof.Dr.Ana Cristina Costa, Universidade NOVA de Lisboa, and Prof.Dr.Pablo Juan Verdoy, Universitat Jaume I(UJI) for their immense support, outstanding guidance, encouragement and helpful comments throughout my thesis work. Finally, but not least, I would like to thank my lovely wife, Workababa Bekele, and beloved daughter Loise Berhanu and son Nethan Berhanu for their patience, inspiration, and understanding during the entire period of my study. -

Awareness of Community on Fishery and Aquaculture Production in Central Ethiopia
Alemu A. J Aquac Fisheries 2021, 5: 039 DOI: 10.24966/AAF-5523/100039 HSOA Journal of Aquaculture & Fisheries Research Article The domestic fishery of Africa involvement is projected to be Awareness of Community about 2.1 million tons of fish per year; it epitomizes 24% of the total world fish production from inland water bodies. The inland water on Fishery and Aquaculture body of Ethiopia is enclosed about 7,400 km2 of the lakes and about 7,000 km a total length of the rivers [2]. Further, 180 fish species were Production in Central Ethiopia harbored in these water bodies [3]. In Ethiopia, fish comes exclusively from inland water bodies with lakes, rivers, streams, reservoirs and substantial wetlands that are of great socio-economic, ecological and Tena Alemu * scientific importance [4,5]. Department of Animal Production and Technology, Wolkite University, Wol- kite, Ethiopia Ethiopia being a land locked country its fisheries is entirely based on inland water bodies, lakes, reservoirs and rivers. Fish production potential of the country is estimated to be 51,400 tonnes per annum [6]. Fishing has been the main source of protein supply for many Abstract people particularly for those who are residing in the locality of major water bodies like Lake Tana, Ziway, Awassa, Chamo, Baro River, etc The study was conducted in three different districts Gumer, [5]. Ethiopia is capable with numerous water bodies that cover a high Enemornaener and Cheha Woreda on awareness and perception of community on fishery and aquaculture production. In those diversity of aquatic wildlife. Reservoir fishery plays an important study areas majority of the people had the limitation of knowledge role in the economy of the country and the livelihoods of the people on production, consumption, and use of fish and aquaculture living adjacent to those reservoirs. -

World Bank Document
Sample Procurement Plan (Text in italic font is meant for instruction to staff and should be deleted in the final version of the PP) Public Disclosure Authorized (This is only a sample with the minimum content that is required to be included in the PAD. The detailed procurement plan is still mandatory for disclosure on the Bank’s website in accordance with the guidelines. The initial procurement plan will cover the first 18 months of the project and then updated annually or earlier as necessary). I. General 1. Bank’s approval Date of the procurement Plan: Updated Procurement Plan, M 2. Date of General Procurement Notice: Dec 24, 2006 Public Disclosure Authorized 3. Period covered by this procurement plan: The procurement period of project covered from year June 2010 to December 2012 II. Goods and Works and non-consulting services. 1. Prior Review Threshold: Procurement Decisions subject to Prior Review by the Bank as stated in Appendix 1 to the Guidelines for Procurement: [Thresholds for applicable procurement methods (not limited to the list below) will be determined by the Procurement Specialist /Procurement Accredited Staff based on the assessment of the implementing agency’s capacity.] Public Disclosure Authorized Procurement Method Prior Review Comments Threshold US$ 1. ICB and LIB (Goods) Above US$ 500,000 All 2. NCB (Goods) Above US$ 100,000 First contract 3. ICB (Works) Above US$ 15 million All 4. NCB (Works) Above US$ 5 million All 5. (Non-Consultant Services) Below US$ 100,000 First contract [Add other methods if necessary] 2. Prequalification. Bidders for _Not applicable_ shall be prequalified in accordance with the provisions of paragraphs 2.9 and 2.10 of the Public Disclosure Authorized Guidelines. -

Knowledge of Health Professionals on Cold Chain Management and Associated Factors in Ezha District, Gurage Zone, Ethiopia
Hindawi Scientifica Volume 2019, Article ID 6937291, 7 pages https://doi.org/10.1155/2019/6937291 Research Article Knowledge of Health Professionals on Cold Chain Management and Associated Factors in Ezha District, Gurage Zone, Ethiopia Zeyneba Jemal Yassin,1 Habtamu Yimer Nega,2 Behailu Tariku Derseh ,3 Yetnayet Sisay Yehuala,4 and Abel Fekadu Dad 5,6 1Ethiopian Field Epidemiology and Laboratory Training Program Resident, University of Gondar, Gondar, Ethiopia 2South Wollo Zone, Institute of Public Health Emergency Management Department, Dessie, Ethiopia 3Debre Berhan University, College of Health Sciences, Department of Public Health, Debre Berhan, Ethiopia 4University of Gondar, Institute of Public Health, Department of Health Promotion and Behavioral Sciences, Gondar, Ethiopia 5College of Medicine and Public Health, School of Public Health, Flinders University, Adelaide, Australia 6University of Gondar, Institute of Public Health, Department of Epidemiology Biostatistics, Gondar, Ethiopia Correspondence should be addressed to Abel Fekadu Dad; [email protected] Received 26 December 2018; Revised 3 April 2019; Accepted 22 April 2019; Published 9 June 2019 Academic Editor: Haiqi He Copyright © 2019 Zeyneba Jemal Yassin et al. -is is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. Background. Maintaining quality of vaccines has been one of the main challenges of immunization programs in Africa including Ethiopia, and this could mainly be explained by health professional’s knowledge about cold chain management. -ere are limited studies done in Ethiopia linking the knowledge of health professionals on cold chain management, and that is why we needed to conduct this study. -

World Bank Document
Sample Procurement Plan (Text in italic font is meant for instruction to staff and should be deleted in the final version of the PP) Public Disclosure Authorized (This is only a sample with the minimum content that is required to be included in the PAD. The detailed procurement plan is still mandatory for disclosure on the Bank’s website in accordance with the guidelines. The initial procurement plan will cover the first 18 months of the project and then updated annually or earlier as necessary). I. General 1. Bank’s approval Date of the procurement Plan: Updated Procurement Plan, M 2. Date of General Procurement Notice: Dec 24, 2006 3. Period covered by this procurement plan: The procurement period of project covered from year June 2010 to December 2012 Public Disclosure Authorized II. Goods and Works and non-consulting services. 1. Prior Review Threshold: Procurement Decisions subject to Prior Review by the Bank as stated in Appendix 1 to the Guidelines for Procurement: [Thresholds for applicable procurement methods (not limited to the list below) will be determined by the Procurement Specialist /Procurement Accredited Staff based on the assessment of the implementing agency’s capacity.] Procurement Method Prior Review Threshold Comments US$ 1. ICB and LIB (Goods) Public Disclosure Authorized Above US$ 500,000 All 2. NCB (Goods) Above US$ 100,000 First contract 3. ICB (Works) Above US$ 15 million All 4. NCB (Works) Above US$ 5 million All 5. (Non-Consultant Services) Below US$ 100,000 First contract [Add other methods if necessary] 2. Prequalification. Bidders for _Not applicable_ shall be prequalified in accordance with the provisions of paragraphs 2.9 and 2.10 of the Guidelines. -

The Embeddedness of Development in Sebat Bet Gurage Identities Thesis
Open Research Online The Open University’s repository of research publications and other research outputs Doing development and being Gurage : the embeddedness of development in Sebat Bet Gurage identities Thesis How to cite: Henry, Leroi Wendel (2002). Doing development and being Gurage : the embeddedness of development in Sebat Bet Gurage identities. PhD thesis The Open University. For guidance on citations see FAQs. c 2001 The Author https://creativecommons.org/licenses/by-nc-nd/4.0/ Version: Version of Record Link(s) to article on publisher’s website: http://dx.doi.org/doi:10.21954/ou.ro.0000e344 Copyright and Moral Rights for the articles on this site are retained by the individual authors and/or other copyright owners. For more information on Open Research Online’s data policy on reuse of materials please consult the policies page. oro.open.ac.uk UTSi11CTT Doing development and being Gurage: the embeddedness of development in Sebat Bet Gurage identities Leroi Wendel Henry BA (Hons.) A Thesis Submitted to the The Development Policy and Practice Discipline Faculty of Technology Open University for the degree of Doctor of Philosophy September 2001 c ç 3c c- I Pe'Qu t&-1 o Acknowledgements I would firstly like to express my gratitude to my supervisors, Hazel Johnson and David Turton and my mentor David Wield for their advice, enthusiasm, continual support and patience during this project. I thank everyone in DPP and CCC for providing a stimulating and helpful environment in which to undertake research. Special thanks go to Seife Ayele, who provided advice on research in Ethiopia and sparked my interest in the Gurages and to Stephen Potter and Roger Spear for co-ordinating the CTS doctoral training programme. -

Effectiveness of the PHE Approach Achieving FP and Fertility Outcomes in Ethiopia
Effectiveness of the PHE approach for achieving family planning and fertility outcomes in Ethiopia: A comparative study in the Guraghe Zone Research Team Prof. Tefera Belachew (MD, MSc, PhD), Jimma University Department of Population and Family Health - Principal Investigator Makeda Sinaga (BSc, MPH/RH), Jimma University Department of Nursing Ahmed Mohammed (MSc), PHE Ethiopia Consortium Negash Teklu (MA), PHE Ethiopia Consortium Kristen Stelljes (MA), PHE Ethiopia Consortium/ Packard Foundation/USAID Global Health Fellows Program II January, 2013 Addis Ababa © Copyright 2013 PHE Ethiopia Consortium Phone: + 251-11-663 0833/ + 251-11-860 8190 Fax: + 251-11-663 8127 P.O.Box - 4408 Addis Ababa, Ethiopia. E-mail: [email protected] [email protected] www.phe-ethiopia.org Unless indicated, all pictures are courteous of GPSDO project field staff. Table of Contents Executive Summary....................................... 7 Background.................................................. 10 Literature Review............................................12 Methods......................................................... 16 Results........................................................... 22 Discussion....................................................... 42 Conclusions......................................................45 Recommendations........................................ 46 References...................................................... 47 Annex............................................................. 50 Survey Questionnaire..................................... -

Periodic Monitoring Report Working 2016 Humanitarian Requirements Document – Ethiopia Group
DRMTechnical Periodic Monitoring Report Working 2016 Humanitarian Requirements Document – Ethiopia Group Covering 1 Jan to 31 Dec 2016 Prepared by Clusters and NDRMC Introduction The El Niño global climactic event significantly affected the 2015 meher/summer rains on the heels of failed belg/ spring rains in 2015, driving food insecurity, malnutrition and serious water shortages in many parts of the country. The Government and humanitarian partners issued a joint 2016 Humanitarian Requirements Document (HRD) in December 2015 requesting US$1.4 billion to assist 10.2 million people with food, health and nutrition, water, agriculture, shelter and non-food items, protection and emergency education responses. Following the delay and erratic performance of the belg/spring rains in 2016, a Prioritization Statement was issued in May 2016 with updated humanitarian requirements in nutrition (MAM), agriculture, shelter and non-food items and education.The Mid-Year Review of the HRD identified 9.7 million beneficiaries and updated the funding requirements to $1.2 billion. The 2016 HRD is 69 per cent funded, with contributions of $1.08 billion from international donors and the Government of Ethiopia (including carry-over resources from 2015). Under the leadership of the Government of Ethiopia delivery of life-saving and life- sustaining humanitarian assistance continues across the sectors. However, effective humanitarian response was challenged by shortage of resources, limited logistical capacities and associated delays, and weak real-time information management. This Periodic Monitoring Report (PMR) provides a summary of the cluster financial inputs against outputs and achievements against cluster objectives using secured funding since the launch of the 2016 HRD. -

Towards the Trachoma Elimination Target in the Southern Region of Ethiopia: How Well Is the SAFE Strategy Being Implemented?
The Ethiopian SORT IT Course Towards the trachoma elimination target in the Southern region of Ethiopia: How well is the SAFE strategy being implemented? Mekuria Asnakew Asfaw1, Maria Zolfo2, Nebiyu Negussu3, Fantahun Tadesse3, Tafese Tadele4, Alemayehu Sisay5, Dawit Seyum5, Tigist Gezmu1, Mbazi Senkoro6, Philip Owiti7,8, Wim Adriaensen2 1 Arba Minch University, Collaborative Research and Training Centre for NTDs, Arba Minch, Ethiopia 2 Institute of Tropical Medicine, Clinical Sciences Department, Antwerp, Belgium 3 Federal Ministry of Health, Neglected Tropical Diseases, Addis Ababa, Ethiopia 4 Southern Nation Nationalities and Peoples Regional Government Health Bureau, Neglected Tropical Diseases, Hawassa, Ethiopia 5 Orbis International, Ethiopia, Country Office, Addis Ababa, Ethiopia 6 National Institute for Medical Research, Muhimbili Centre, Dar es Salaam, Tanzania 7 International Union Against Tuberculosis and Lung Disease (The Union), Paris, France 8 National Tuberculosis, Leprosy, Lung Disease Programme, Nairobi, Kenya Abstract Introduction: Trachoma is one of the 20 neglected tropical diseases and a serious public health problem in Ethiopia. To reach the WHO elimination target by 2020, SAFE (Surgery, Antibiotics, Facial cleanliness, Environmental improvement) strategy has been implemented in the Southern Nations, Nationalities, and Peoples' Region (SNNPRs), Ethiopia. Scarce evidence exists regarding recent progress in achieving elimination of active trachoma (< 5%) and how well the SAFE strategy implemented. Methodology: A retrospective analysis of programmatic data in the period 2013-2018 was used. All trachoma endemic districts in SNNPR were included. Data collected from the Federal Ministry of Health on trachoma prevalence and SAFE strategy were analyzed. Results: Out of 134 endemic districts, only 35 had their planned impact survey, of which only 11 districts achieved the elimination target. -

World Bank Document
Sample Procurement Plan (Text in italic font is meant for instruction to staff and should be deleted in the final version of the PP) Public Disclosure Authorized (This is only a sample with the minimum content that is required to be included in the PAD. The detailed procurement plan is still mandatory for disclosure on the Bank’s website in accordance with the guidelines. The initial procurement plan will cover the first 18 months of the project and then updated annually or earlier as necessary). I. General 1. Bank’s approval Date of the procurement Plan: Updated Procurement Plan, M 2. Date of General Procurement Notice: Dec 24, 2006 3. Period covered by this procurement plan: The procurement period of project covered from year June 2010 to December 2012 Public Disclosure Authorized II. Goods and Works and non-consulting services. 1. Prior Review Threshold: Procurement Decisions subject to Prior Review by the Bank as stated in Appendix 1 to the Guidelines for Procurement: [Thresholds for applicable procurement methods (not limited to the list below) will be determined by the Procurement Specialist /Procurement Accredited Staff based on the assessment of the implementing agency’s capacity.] Procurement Method Prior Review Threshold Comments US$ 1. ICB and LIB (Goods) Public Disclosure Authorized Above US$ 500,000 All 2. NCB (Goods) Above US$ 100,000 First contract 3. ICB (Works) Above US$ 15 million All 4. NCB (Works) Above US$ 5 million All 5. (Non-Consultant Services) Below US$ 100,000 First contract [Add other methods if necessary] 2. Prequalification. Bidders for _Not applicable_ shall be prequalified in accordance with the provisions of paragraphs 2.9 and 2.10 of the Guidelines.