The Spoken British National Corpus 2014
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Talk Bank: a Multimodal Database of Communicative Interaction
Talk Bank: A Multimodal Database of Communicative Interaction 1. Overview The ongoing growth in computer power and connectivity has led to dramatic changes in the methodology of science and engineering. By stimulating fundamental theoretical discoveries in the analysis of semistructured data, we can to extend these methodological advances to the social and behavioral sciences. Specifically, we propose the construction of a major new tool for the social sciences, called TalkBank. The goal of TalkBank is the creation of a distributed, web- based data archiving system for transcribed video and audio data on communicative interactions. We will develop an XML-based annotation framework called Codon to serve as the formal specification for data in TalkBank. Tools will be created for the entry of new and existing data into the Codon format; transcriptions will be linked to speech and video; and there will be extensive support for collaborative commentary from competing perspectives. The TalkBank project will establish a framework that will facilitate the development of a distributed system of allied databases based on a common set of computational tools. Instead of attempting to impose a single uniform standard for coding and annotation, we will promote annotational pluralism within the framework of the abstraction layer provided by Codon. This representation will use labeled acyclic digraphs to support translation between the various annotation systems required for specific sub-disciplines. There will be no attempt to promote any single annotation scheme over others. Instead, by promoting comparison and translation between schemes, we will allow individual users to select the custom annotation scheme most appropriate for their purposes. -

Weaponized Humor: the Cultural Politics Of
WEAPONIZED HUMOR: THE CULTURAL POLITICS OF TURKISH-GERMAN ETHNO-COMEDY by TIM HÖLLERING B.A. Georg-August Universität Göttingen, 2008 M.Ed., Georg-August Universität Göttingen, 2010 A DISSERTATION SUBMITTED IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF DOCTOR OF PHILOSOPHY in THE FACULTY OF GRADUATE AND POSTDOCTORAL STUDIES (Germanic Studies) THE UNIVERSITY OF BRITISH COLUMBIA (Vancouver) June 2016 © Tim Höllering, 2016 Abstract My thesis aims to show how the humor of Turkish-German ethno-comedians fulfills a double purpose of entertaining its audience while advancing a cultural political agenda that Kathrin Bower called “transnational humanism.” It includes notions of human rights consensus, critical self-reflection, respect, tolerance, and openness to cultural diversity. Promoting these values through comedy, the artists hope to contribute to abating prejudice and discrimination in Germany’s multi-ethnic society. Fusing the traditional theatrical principle of “prodesse et delectare” with contemporary cultural politics, these comedians produce something of political relevance: making their audience aware of its conceptions of “self” and “other” and fostering a sense of community across diverse cultural identifications. My thesis builds mainly on the works of Kathrin Bower, Maha El Hissy, Erol Boran, Deniz Göktürk, and Christie Davies. Whereas Davies denies humor’s potential for cultural impact, Göktürk elucidates its destabilizing power in immigrant films. Boran elaborates this function for Turkish-German Kabarett. El Hissy connects Kabarett, film, and theater of polycultural artists and ties them to Bakhtin’s concept of the carnivalesque and the medieval jester. Bower published several essays on the works of ethno-comedians as humorous catalysts for advancing a multiethnic Germany. -

Collection of Usage Information for Language Resources from Academic Articles
Collection of Usage Information for Language Resources from Academic Articles Shunsuke Kozaway, Hitomi Tohyamayy, Kiyotaka Uchimotoyyy, Shigeki Matsubaray yGraduate School of Information Science, Nagoya University yyInformation Technology Center, Nagoya University Furo-cho, Chikusa-ku, Nagoya, 464-8601, Japan yyyNational Institute of Information and Communications Technology 4-2-1 Nukui-Kitamachi, Koganei, Tokyo, 184-8795, Japan fkozawa,[email protected], [email protected], [email protected] Abstract Recently, language resources (LRs) are becoming indispensable for linguistic researches. However, existing LRs are often not fully utilized because their variety of usage is not well known, indicating that their intrinsic value is not recognized very well either. Regarding this issue, lists of usage information might improve LR searches and lead to their efficient use. In this research, therefore, we collect a list of usage information for each LR from academic articles to promote the efficient utilization of LRs. This paper proposes to construct a text corpus annotated with usage information (UI corpus). In particular, we automatically extract sentences containing LR names from academic articles. Then, the extracted sentences are annotated with usage information by two annotators in a cascaded manner. We show that the UI corpus contributes to efficient LR searches by combining the UI corpus with a metadata database of LRs and comparing the number of LRs retrieved with and without the UI corpus. 1. Introduction Thesaurus1. In recent years, such language resources (LRs) as corpora • He also employed Roget’s Thesaurus in 100 words of and dictionaries are being widely used for research in the window to implement WSD. -

The Spoken BNC2014: Designing and Building a Spoken Corpus Of
The Spoken BNC2014 Designing and building a spoken corpus of everyday conversations Robbie Love i, Claire Dembry ii, Andrew Hardie i, Vaclav Brezina i and Tony McEnery i i Lancaster University / ii Cambridge University Press This paper introduces the Spoken British National Corpus 2014, an 11.5-million-word corpus of orthographically transcribed conversations among L1 speakers of British English from across the UK, recorded in the years 2012–2016. After showing that a survey of the recent history of corpora of spo- ken British English justifies the compilation of this new corpus, we describe the main stages of the Spoken BNC2014’s creation: design, data and metadata collection, transcription, XML encoding, and annotation. In doing so we aim to (i) encourage users of the corpus to approach the data with sensitivity to the many methodological issues we identified and attempted to overcome while com- piling the Spoken BNC2014, and (ii) inform (future) compilers of spoken corpora of the innovations we implemented to attempt to make the construction of cor- pora representing spontaneous speech in informal contexts more tractable, both logistically and practically, than in the past. Keywords: Spoken BNC2014, transcription, corpus construction, spoken corpora 1. Introduction The ESRC Centre for Corpus Approaches to Social Science (CASS) 1 at Lancaster University and Cambridge University Press have compiled a new, publicly- accessible corpus of present-day spoken British English, gathered in informal con- texts, known as the Spoken British National Corpus 2014 (Spoken BNC2014). This 1. The research presented in this paper was supported by the ESRC Centre for Corpus Approaches to Social Science, ESRC grant reference ES/K002155/1. -

Student Research Workshop Associated with RANLP 2011, Pages 1–8, Hissar, Bulgaria, 13 September 2011
RANLPStud 2011 Proceedings of the Student Research Workshop associated with The 8th International Conference on Recent Advances in Natural Language Processing (RANLP 2011) 13 September, 2011 Hissar, Bulgaria STUDENT RESEARCH WORKSHOP ASSOCIATED WITH THE INTERNATIONAL CONFERENCE RECENT ADVANCES IN NATURAL LANGUAGE PROCESSING’2011 PROCEEDINGS Hissar, Bulgaria 13 September 2011 ISBN 978-954-452-016-8 Designed and Printed by INCOMA Ltd. Shoumen, BULGARIA ii Preface The Recent Advances in Natural Language Processing (RANLP) conference, already in its eight year and ranked among the most influential NLP conferences, has always been a meeting venue for scientists coming from all over the world. Since 2009, we decided to give arena to the younger and less experienced members of the NLP community to share their results with an international audience. For this reason, further to the first successful and highly competitive Student Research Workshop associated with the conference RANLP 2009, we are pleased to announce the second edition of the workshop which is held during the main RANLP 2011 conference days on 13 September 2011. The aim of the workshop is to provide an excellent opportunity for students at all levels (Bachelor, Master, and Ph.D.) to present their work in progress or completed projects to an international research audience and receive feedback from senior researchers. We have received 31 high quality submissions, among which 6 papers have been accepted as regular oral papers, and 18 as posters. Each submission has been reviewed by -

E-Language: Communication in the Digital Age Dawn Knight1, Newcastle University
e-Language: Communication in the Digital Age Dawn Knight1, Newcastle University 1. Introduction Digital communication in the age of ‘web 2.0’ (that is the second generation of in the internet: an internet focused driven by user-generated content and the growth of social media) is becoming ever-increasingly embedded into our daily lives. It is impacting on the ways in which we work, socialise, communicate and live. Defining, characterising and understanding the ways in which discourse is used to scaffold our existence in this digital world is, therefore, emerged as an area of research that is a priority for applied linguists (amongst others). Corpus linguists are ideally situated to contribute to this work as they have the appropriate expertise to construct, analyse and characterise patterns of language use in large- scale bodies of such digital discourse (labelled ‘e-language’ here - also known as Computer Mediated Communication, CMC: see Walther, 1996; Herring, 1999 and Thurlow et al., 2004, and ‘netspeak’, Crystal, 2003: 17). Typically, forms of e-language are technically asynchronous insofar as each of them is ‘stored at the addressee’s site until they can be ‘read’ by the recipient (Herring 2007: 13). They do not require recipients to be present/ready to ‘receive’ the message at the same time that it is sent, as spoken discourse typically does (see Condon and Cech, 1996; Ko, 1996 and Herring, 2007). However, with the increasing ubiquity of digital communication in daily life, the delivery and reception of digital messages is arguably becoming increasingly synchronous. Mobile apps, such as Facebook, WhatsApp and I-Message (the Apple messaging system), for example, have provisions for allowing users to see when messages are being written, as well as when they are received and read by the. -
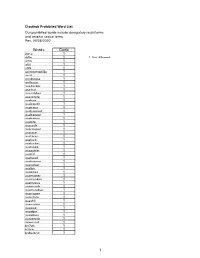
2020-05-25 Prohibited Words List
Clouthub Prohibited Word List Our prohibited words include derogatory racial terms and graphic sexual terms. Rev. 05/25/2020 Words Code 2g1c 1 4r5e 1 1 Not Allowed a2m 1 a54 1 a55 1 acrotomophilia 1 anal 1 analprobe 1 anilingus 1 ass-fucker 1 ass-hat 1 ass-jabber 1 ass-pirate 1 assbag 1 assbandit 1 assbang 1 assbanged 1 assbanger 1 assbangs 1 assbite 1 asscock 1 asscracker 1 assface 1 assfaces 1 assfuck 1 assfucker 1 assfukka 1 assgoblin 1 asshat 1 asshead 1 asshopper 1 assjacker 1 asslick 1 asslicker 1 assmaster 1 assmonkey 1 assmucus 1 assmunch 1 assmuncher 1 assnigger 1 asspirate 1 assshit 1 asssucker 1 asswad 1 asswipe 1 asswipes 1 autoerotic 1 axwound 1 b17ch 1 b1tch 1 babeland 1 1 Clouthub Prohibited Word List Our prohibited words include derogatory racial terms and graphic sexual terms. Rev. 05/25/2020 ballbag 1 ballsack 1 bampot 1 bangbros 1 bawdy 1 bbw 1 bdsm 1 beaner 1 beaners 1 beardedclam 1 bellend 1 beotch 1 bescumber 1 birdlock 1 blowjob 1 blowjobs 1 blumpkin 1 boiolas 1 bollock 1 bollocks 1 bollok 1 bollox 1 boner 1 boners 1 boong 1 booobs 1 boooobs 1 booooobs 1 booooooobs 1 brotherfucker 1 buceta 1 bugger 1 bukkake 1 bulldyke 1 bumblefuck 1 buncombe 1 butt-pirate 1 buttfuck 1 buttfucka 1 buttfucker 1 butthole 1 buttmuch 1 buttmunch 1 buttplug 1 c-0-c-k 1 c-o-c-k 1 c-u-n-t 1 c.0.c.k 1 c.o.c.k. -

Bess Lomax Hawes Student Folklore Collection
http://oac.cdlib.org/findaid/ark:/13030/c85d8v11 No online items Guide to the Bess Lomax Hawes Student Folklore Collection Special Collections & Archives University Library California State University, Northridge 18111 Nordhoff Street Northridge, CA 91330-8326 URL: https://library.csun.edu/SCA Contact: https://library.csun.edu/SCA/Contact © Copyright 2020 Special Collections & Archives. All rights reserved. Guide to the Bess Lomax Hawes URB.BLH 1 Student Folklore Collection Contributing Institution: Special Collections & Archives Title: Bess Lomax Hawes Student Folklore Collection Creator: Hawes, Bess Lomax, 1921-2009 Identifier/Call Number: URB.BLH Extent: 10.50 linear feet Date (inclusive): 1959-1975 Abstract: Bess Lomax Hawes is the daughter of famed folklorist John A. Lomax. Ms. Hawes had an active musical career as a singer, instrumentalist and songwriter. Her career as an educator began in 1954 when she became an instructor in guitar, banjo and folk music in the extension division at the University of California, Los Angeles. In 1963, she joined the Anthropology Department at San Fernando Valley State College. The material contained in this collection consists of folkloric data collected between 1958 and 1977 by students enrolled in Anthropology 309: American Folk Music, Anthropology 311: Introduction to Folklore, and various senior seminars at San Fernando Valley State College (now California State University, Northridge). Language of Material: English Biographical Information: Bess Lomax Hawes was born in Austin, Texas in 1921 to Bess Bauman-Brown Lomax and John A. Lomax, famed folklorist and author of Cowboy Songs, American Ballads and Folksongs, Adventures of a Ballad Hunter, and director of the Archive of American Folksong at the Library of Congress. -

Lexical Ambiguity • Syntactic Ambiguity • Semantic Ambiguity • Pragmatic Ambiguity
Welcome to the course! IntroductionIntroduction toto NaturalNatural LanguageLanguage ProcessingProcessing (NLP)(NLP) Professors:Marta Gatius Vila Horacio Rodríguez Hontoria Hours per week: 2h theory + 1h laboratory Web page: http://www.cs.upc.edu/~gatius/engpln2017.html Main goal Understand the fundamental concepts of NLP • Most well-known techniques and theories • Most relevant existing resources • Most relevant applications NLP Introduction 1 Welcome to the course! IntroductionIntroduction toto NaturalNatural LanguageLanguage ProcessingProcessing Content 1. Introduction to Language Processing 2. Applications. 3. Language models. 4. Morphology and lexicons. 5. Syntactic processing. 6. Semantic and pragmatic processing. 7. Generation NLP Introduction 2 Welcome to the course! IntroductionIntroduction toto NaturalNatural LanguageLanguage ProcessingProcessing Assesment • Exams Mid-term exam- November End-of-term exam – Final exams period- all the course contents • Development of 2 Programs – Groups of two or three students Course grade = maximum ( midterm exam*0.15 + final exam*0.45, final exam * 0.6) + assigments *0.4 NLP Introduction 3 Welcome to the course! IntroductionIntroduction toto NaturalNatural LanguageLanguage ProcessingProcessing Related (or the same) disciplines: •Computational Linguistics, CL •Natural Language Processing, NLP •Linguistic Engineering, LE •Human Language Technology, HLT NLP Introduction 4 Linguistic Engineering (LE) • LE consists of the application of linguistic knowledge to the development of computer systems able to recognize, understand, interpretate and generate human language in all its forms. • LE includes: • Formal models (representations of knowledge of language at the different levels) • Theories and algorithms • Techniques and tools • Resources (Lingware) • Applications NLP Introduction 5 Linguistic knowledge levels – Phonetics and phonology. Language models – Morphology: Meaningful components of words. Lexicon doors is plural – Syntax: Structural relationships between words. -

Discriminatory Language Research Presented to the BBFC on 15Th November 2010
Discriminatory Language Research Presented to the BBFC on 15th November 2010 Slesenger Research Research objectives To understand the role of context and how it changes attitudes to discriminatory language / issues To establish the degree to which the public expect to be warned about potentially offensive language/behaviour/stereotyping in CA, ECI/ECA To understand spontaneous reactions to a number of discriminatory terms To explore what mitigates the impact of these words and how To understand the public’s response to the Video Recordings Act and their appreciation of the ‘E’ classification 2 Slesenger Research Recruitment Criteria Group Discussions 2 hours 7/8 respondents All had personally watched a film either at the cinema or at home (DVD rental/purchase) at least once in the last two to three months Spread of occasional and more regular film viewers Even spread of parents of different ages of children and boys/girls All respondents were pre - placed with three relevant film/TV works All respondents completed a short questionnaire/diary about the material they had viewed Paired Depths 1-1 1/2 hours As for group discussions 3 Slesenger Research Sample and Methodology 9 x Group discussions 18-25 Single, working/students, BC1 Race Female Edgware 18-25 Single, working/students, C2D Sexuality Male Leeds 25-40 Children under 8 years Female Leeds Working, part-time and non, C2D Sexuality 25-40 Children under 8 years Male Scotland Working, BC1 Sexuality 25-40 Children 8-12 years Female Birmingham Working, part-time and non, -

From CHILDES to Talkbank
From CHILDES to TalkBank Brian MacWhinney Carnegie Mellon University MacWhinney, B. (2001). New developments in CHILDES. In A. Do, L. Domínguez & A. Johansen (Eds.), BUCLD 25: Proceedings of the 25th annual Boston University Conference on Language Development (pp. 458-468). Somerville, MA: Cascadilla. a similar article appeared as: MacWhinney, B. (2001). From CHILDES to TalkBank. In M. Almgren, A. Barreña, M. Ezeizaberrena, I. Idiazabal & B. MacWhinney (Eds.), Research on Child Language Acquisition (pp. 17-34). Somerville, MA: Cascadilla. Recent years have seen a phenomenal growth in computer power and connectivity. The computer on the desktop of the average academic researcher now has the power of room-size supercomputers of the 1980s. Using the Internet, we can connect in seconds to the other side of the world and transfer huge amounts of text, programs, audio and video. Our computers are equipped with programs that allow us to view, link, and modify this material without even having to think about programming. Nearly all of the major journals are now available in electronic form and the very nature of journals and publication is undergoing radical change. These new trends have led to dramatic advances in the methodology of science and engineering. However, the social and behavioral sciences have not shared fully in these advances. In large part, this is because the data used in the social sciences are not well- structured patterns of DNA sequences or atomic collisions in super colliders. Much of our data is based on the messy, ill-structured behaviors of humans as they participate in social interactions. Categorizing and coding these behaviors is an enormous task in itself. -

Conference Abstracts
EIGHTH INTERNATIONAL CONFERENCE ON LANGUAGE RESOURCES AND EVALUATION Held under the Patronage of Ms Neelie Kroes, Vice-President of the European Commission, Digital Agenda Commissioner MAY 23-24-25, 2012 ISTANBUL LÜTFI KIRDAR CONVENTION & EXHIBITION CENTRE ISTANBUL, TURKEY CONFERENCE ABSTRACTS Editors: Nicoletta Calzolari (Conference Chair), Khalid Choukri, Thierry Declerck, Mehmet Uğur Doğan, Bente Maegaard, Joseph Mariani, Asuncion Moreno, Jan Odijk, Stelios Piperidis. Assistant Editors: Hélène Mazo, Sara Goggi, Olivier Hamon © ELRA – European Language Resources Association. All rights reserved. LREC 2012, EIGHTH INTERNATIONAL CONFERENCE ON LANGUAGE RESOURCES AND EVALUATION Title: LREC 2012 Conference Abstracts Distributed by: ELRA – European Language Resources Association 55-57, rue Brillat Savarin 75013 Paris France Tel.: +33 1 43 13 33 33 Fax: +33 1 43 13 33 30 www.elra.info and www.elda.org Email: [email protected] and [email protected] Copyright by the European Language Resources Association ISBN 978-2-9517408-7-7 EAN 9782951740877 All rights reserved. No part of this book may be reproduced in any form without the prior permission of the European Language Resources Association ii Introduction of the Conference Chair Nicoletta Calzolari I wish first to express to Ms Neelie Kroes, Vice-President of the European Commission, Digital agenda Commissioner, the gratitude of the Program Committee and of all LREC participants for her Distinguished Patronage of LREC 2012. Even if every time I feel we have reached the top, this 8th LREC is continuing the tradition of breaking previous records: this edition we received 1013 submissions and have accepted 697 papers, after reviewing by the impressive number of 715 colleagues.