Restaurant Review Classification and Analysis
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

YELP INC. (Exact Name of Registrant As Specified in Its Charter)
Table of Contents UNITED STATES SECURITIES AND EXCHANGE COMMISSION Washington, D.C. 20549 Form 10-K x ANNUAL REPORT PURSUANT TO SECTION 13 OR 15(d) OF THE SECURITIES EXCHANGE ACT OF 1934 For the fiscal year ended December 31, 2018 OR ¨ TRANSITION REPORT PURSUANT TO SECTION 13 OR 15(d) OF THE SECURITIES EXCHANGE ACT OF 1934 For the transition period from to Commission file number: 001-35444 YELP INC. (Exact name of Registrant as specified in its charter) Delaware 20-1854266 (State or other jurisdiction of incorporation or organization) (I.R.S. Employer Identification No.) 140 New Montgomery Street, 9 th Floor San Francisco, California 94105 (Address of principal executive offices) (Zip Code) Registrant’s telephone number, including area code: (415) 908-3801 Securities registered pursuant to Section 12(b) of the Act: Title of Each Class Name of Each Exchange on Which Registered Common Stock, par value $0.000001 per share New York Stock Exchange LLC Securities registered pursuant to Section 12(g) of the Act: None Indicate by check mark if the registrant is a well-known seasoned issuer, as defined in Rule 405 of the Securities Act. YES x NO ¨ Indicate by check mark if the registrant is not required to file reports pursuant to Section 13 or Section 15(d) of the Act. YES ¨ NO x Indicate by check mark whether the registrant (1) has filed all reports required to be filed by Section 13 or 15(d) of the Securities Exchange Act of 1934 during the preceding 12 months (or for such shorter period that the registrant was required to file such reports), and (2) has been subject to such filing requirements for the past 90 days. -

To the Best Restaurant Reservation Software the Ultimate Guide to the Best Restaurant Reservation Systems
The Ultimate Guide to the Best Restaurant Reservation Software The Ultimate Guide to the Best Restaurant Reservation Systems Restaurant reservation systems have become essential to running a successful restaurant. 2 While walk-ins once dominated That’s where this guide comes in. Our on-premise dining, the rise of guide helps you cut through the noise reservations technology has gradually and find the best restaurant reservation shifted the restaurant landscape. system for your specific business. With Now, diners are no longer content reviews of each of the top reservation to wait in line for a table when they systems (including our own), we’ll could simply make a reservation that highlight all the need-to-know information. would guarantee their spot – especially during peak business hours. In each review, you’ll find: A basic overview of each of the At the same time, reservation systems top restaurant reservation systems have allowed restaurants to offer an Each system’s strengths and weaknesses elevated level of customer service, Software pricing and other fees ensuring more customers leave with The ideal reservations solution for a positive dining experience and each type of restaurant servers end up with healthy tips. In addition to reviews of each reservation system, But while it’s clear that there are many we’ve also included: benefits to using a reservation system in A comparison chart featuring all your restaurant, finding the right system the top reservation platforms can be a major challenge. Not only A buyer’s guide that highlights key purchasing considerations are there dozens of different platforms to choose from, but each one comes with a unique set of features, tools, and services. -

Assurance Van Lines Reviews Yelp
Assurance Van Lines Reviews Yelp novelisedHuntlee interwreathing her canulas. Sinhaleseher previsions and astigmatically,sorriest Wainwright she befogs never encagingit clockwise. his Lindsaynetworks! is informational: she arbitrated superhumanly and Kyle put me was two weeks in touch van co to get quotes when a lot of all the very unprofessional, assurance van lines Im not sure if the names they gave me are real. Amazing skills moving heavy furnitures down the stairs. GENERAL VAN LINES, INC. THOMAS SULLIVAN TRANSPORTATION MANAGEMENT INC. Then artificial intelligence builds an inventory list of all your items. We are the ones to suffer and we are the ones that will now have to come up with the funds to fix THEIR mistakes and mishandling. Connected Vanlines is an interstate moving broker that has been in the business long enough to become one of the foremost services in the country. Given the covid timing, we were worried about all the precaution. The price ended up being the same as other companies but Proud American was faster about getting back to us and answering questions. We had already verbally agreed upon a price quote for full service after video walkthrough with Quality Express Van Lines. United Royal Van Lines accepts credit cards. Horrible company with the nastiest office staff around. Bekins is the expert team you want on your side. Mayflower does not take care of your items or it is intentional. We knew nothing about a third party? Direct Relocation Service and their competent employees. Adam did online from assurance van lines reviews yelp is assurance department asking for. -

Copy of Emeryville Restaurants Open
Emeryville Resturants Open for Takeout and Delivery Delivery/Takeout Only Website Address Phone Baby Cafe https://www.babycaferestaurants.com/emeryville/ 5859 Shellmound Baskins Robbins https://www.doordash.com/store/baskin-robbins-emeryville-49023/en-US Best Coast Burritos http://www.bestcoastburritos.com/ 1400 Powell Street #C Black Bear https://www.doordash.com/store/black-bear-diner-emeryville-531245/en-US Black Diamond Café https://www.doordash.com/store/black-diamond-cafe-emeryville-524536/en-US 6399 Christie Ave (510) 922-9124 Branch Line Lounge https://www.branchlinebar.com/#menu 5885 Hollis Street, Suite 25 Burger King https://burgerking.com/store-locator/pickup-mode Cafe Duette https://www.caffeduetto.net/ 646 Bay Street California Pizza kitchen https://www.doordash.com/store/california-pizza-kitchen-emeryville-16969/en-US Chevy's https://www.doordash.com/store/chevys-fresh-mex-emeryville-17105/en-US Dee Spot https://www.doordash.com/store/dee-spot-oakland-151165/en-US Denny's https://order.dennys.com/menu Doyle Street Café https://www.doylestreetcafe.com/ 5515 Doyle St Cafe Emery Bay https://postmates.com/merchant/emery-bay-cafa-emeryville 5857 Christie Ave (510) 652-9269 Hometown Heroes https://www.yelp.com/biz/hometown-heroes-east-bay-emeryville-2 Honor Kitchen & Cocktails https://www.doordash.com/store/honor-kitchen-cocktails-emeryville-478466/en-US IHOP https://www.doordash.com/store/ihop-emeryville-184249/en-US In The Kitchen Culinary https://www.itkculinary.com/takeout Ike's https://www.doordash.com/store/ike-s-love-sandwiches-emeryville-42528/en-US -

Get High on the Wow Factor Page 24 Spring 2015
FOOD FANATICS FOOD FOOD PEOPLE MONEY & SENSE PLUS Regional Chinese Group Dining Fear of Failure I’ll Drink to That! The latest riffs revealed, Cash in on large parties, 7 nightmare busters, Gin is in, page 8 page 38 page 52 page 62 THE WOW FACTOR THE WOW Sharing the Love of Food—Inspiring Business Success SPRING 2015 BLOWN AWAY GET HIGH ON THE WOW FACTOR PAGE 24 SPRING 2015 FOOD Real Chinese Steps Out 8 America’s regional Chinese cuisine gets ADVERTISEMENT back to its roots. In the Raw 14 Tartare goes beyond beef, capers and PAGE 112 egg yolk. Tapping Into Maple Syrup 20 This natural sweetener breaks out of its morning routine. COVER STORY The Wow Factor 24 When the ordinary becomes extraordinary. MAPLE FOOD PEOPLE SYRUP GOES BOTH Bigger Is Better 38 Master a group mentality to cash in on WAYS— large parties. SWEET AND SAVORY Talk Shop PAGE 20 40 Upping the minimum wage: thumbs up or thumbs down? Road Trip to Las Vegas 44 Take a gamble on a restaurant off the strip. PREMIUM QUALITY SIGNATURE TASTE EXCEPTIONAL PERFORMANCE Download the app on iTunes or view the MONEY & SENSE magazine online at FOODFANATICS.COM The Secret to the Upsell 48 A seasoned dining critic says to ditch selling and focus on service. Nightmare Busters 52 Ways to combat 7 of the most common restaurant fears. I’ll Drink to That 62 Gin for the win: The original flavored spirit paves the way for focused beverage programs. WHEN THE TUNA IN TARTARE BECOMES A SNOOZER, GIVE OTHERS A TRY IN EVERY ISSUE (HINT: SALMON) PAGE 14 FOOD Trend Tracker 31 What’s turning up the heat and what’s cooling off. -

SEPTEMBER/OCTOBER 2020 If You Like to Play with Fire, You Belong with Us
SOUTH AMERICAN CUISINE SEPTEMBER/OCTOBER 2020 If you like to PLAY WITH FIRE, you belong WITH US Membership. Certification. Online Learning Center. Apprenticeship. Events. WeAreChefs.com. ACFchefs.org. FEATURE STORIES 26 The Cuisine of South America A sensory exploration and brief historical journey of the cuisines of Brazil, Venezuela, Chile and beyond. DEPARTMENTS 12 Management Culinary education today looks a lot different than last year, or even last semester. Here’s how some chef-instructors are approaching virtual and remote learning. If you like to 16 Main Course Even in an era of plant-based eating, whole-animal butchery hasn’t gone away and presents a more PLAY WITH FIRE, environmentally friendly — and cost effective — approach to meat prep. you belong 19 On the Side In-house butchery requires special consideration when it comes to knife selection and maintenance. WITH US Plus, a fresh look at rabbit. 22 Pastry Crème anglaise, the simple dairy-and-egg-yolk combo and workhorse of every pastry kitchen, makes a comeback as consumers trace comforting classics. 24 Classical vs. Modern A study of the classic French dish, poulet sauté a la Bourguignonne, from Chef August Escoffier’s book, along with a modern pavé version by Chef J. Kevin Walker, CMC. 36 Health The wide breadth of seafood from Mississippi and the Gulf of Mexico offers chefs opportunities to introduce dishes that are both flavorful and good-for-you. 40 At the Bar Many bars may be closed at the moment due to COVID-19, but we can still learn how to make a trendy tea-based cocktail, or ones with decorative garnishes. -

Read Newsletter
www.ShorelineMediaMarketing.com | [email protected] SHOULD YOU INVEST IN DIGITAL MARKETING DURING 1 THIS CRISIS? GOOGLE MAKES A HOST OF CHANGES TO GOOGLE 2 MY BUSINESS DUE TO COVID-19 GOOGLE OFFERS $800+ MILLION SUPPORT TO SMBS 3 AMID COVID-19 CRISIS 4 FACEBOOK OFFERS $100 MILLION CASH GRANTS TO SMALL BUSINESSES FOLLOWING COVID-19 OUTBREAK YELP GIVES AFFECTED LOCAL BUSINESSES FREE 5 SERVICES WORTH $25M www.ShorelineMediaMarketing.com | [email protected] SHOULD YOU INVEST IN DIGITAL MARKETING DURING 1 THIS CRISIS? Yes, there are uncalled times. As the global economy reels from the impact of COVID-19, many SMB’s are forced to ask tough questions and make tough decisions concerning the future of their business. Yes, businesses are going to struggle for a while amid the COVID-19 crisis. But the reality is - businesses can thrive in downtimes. And many of the successful ones will choose to invest in online marketing. From our experience of two major crashes (the 2000 dotcom crash and the 2008 real estate crash), we can tell you that the best time to double down is when others are not. As Warren Buffet once famously quoted - “Be fearful when others are greedy, and greedy when others are fearful” With more people working from home, consumers are relying on the Internet more than ever. In fact, even during a quarantine, people rely on Google search to look for services and products. This means businesses will still require digital marketing to keep up with the demand. All we can say is - Now is the time for social distancing, not forgetting about digital marketing. -

Galt Restaurants Open for Curbside Pick-Up, Take-Out and Delivery
Galt restaurants open for curbside pick-up, take-out and delivery Grubhub · Uber Eats · DoorDash offer delivery in Galt Pastosas by Lucia Streetzlan Restaurant 209.213.7199 209.251.7241 545 Industrial Drive 415 C Street https://www.pastosapasta.com/ https://www.facebook.com/StreetZlanRestaurant/ Brewsters Bar & Grill Stratton’s Pizzeria 209.251.7355 209.251.7590 201 4th Street 330 S. Lincoln Way https://www.facebook.com/Brewstersbarandgrilll/ https://www.facebook.com/StrattonsPizzeria/ Papas & Wings Velvet Grill & Creamery 209.251.7784 209.744.1413 803 C Street 400 4th Street https://www.facebook.com/Papas-Wings-1582415191848810/ https://www.thevelvetgrillcreamery.com/ Galt’s Old Town Diner Golden Acorn Restaurant 209.251.7823 209.745.2978 227 S. Lincoln Way 805 Crystal Way https://www.yelp.com/biz/old-town-diner-galt-3 https://www.yelp.com/biz/golden-acorn-restaurant-galt El Arcoiris Taqueria Tacos Romero 209.275.7235 209.744.6221 520 N. Lincoln Way 114 N. Lincoln Way https://www.yelp.com/biz/el-arcoiris-taqueria-galt https://www.yelp.com/biz/tacos-romero-galt-4 Matsuyama Restaurant Las Islitas 209.251.7652 209.843.5924 10420 Twin Cities Rd. 908 C Street https://www.yelp.com/biz/matsuyama-restaurant-galt https://www.lasislitasgalt.com/ Galt restaurants open for curbside pick-up, take-out and delivery Koala Bear Grill and More Squeeze Burger Galt 209.251.7768 209.745.4313 1061 C Street 10550 Twin Cities Rd. https://www.yelp.com/biz/koala-bear-grill-and-more-galt-2 http://www.squeezeburger.com/ Hunan House El Rodeo 209.745.5567 209.745.2853 1067 C Street 905 C Street https://www.hunanhousegalt.com/ https://www.yelp.com/biz/el-rodeo-2-galt Full Moon Palace Mariscos Guamuchil 209.745.7938 209.744.2524 1000 C Street 800 C Street https://www.yelp.com/biz/full-moon-palace-galt https://www.yelp.com/biz/mariscos-guamuchil-galt Mr. -

Why Should Your Business Be on Yelp?
Why Should Your Business Be On Yelp? Yelp Work Product - Not for Distribution What Is Yelp? Yelp Work Product - Not for Distribution Poll #1 What is Yelp? A. Local business directory B. Social media site But First, A Question: C. A place for my customers D. I don’t know, that’s why to leave reviews I’m here A. Local business directory Yelp Work Product - Not for Distribution CONSUMER BEHAVIOR ON YELP Your prospective customers are searching Yelp for a local business to spend money with 100MM unique visitors come to Yelp monthly comScore Media Metrix, July 2019 CONSUMER BEHAVIOR ON YELP 97% of people on Yelp make a purchase after visiting the platform 51% purchase within one day Survey Monkey Audiences, 2019 CONSUMER BEHAVIOR ON YELP Consumers are ready to spend money with a local business, but they are undecided on who to Plumber spend with They turn to Yelp to discover the right business CONSUMER BEHAVIOR ON YELP The full consumer journey on Yelp starts with a need and ends with engagement 3 Benefits of Being on Yelp #1 Lead Generation #2 High Intent Consumers #3 Brand Continuity Yelp Work Product - Not for Distribution Benefit #1 Yelp reaches 90+ million monthly unique visitors Benefit #1: Lead Generation At Scale comScore Media Metrix, March 2019 Yelp Work Product - Not for Distribution THE LANDSCAPE RIGHT NOW Snapchat eBay Spotify Netflix Yelp Pinterest Linkedin TripAdvisor Reddit NY Times Uber Monthly Unique Visitors (millions) comScore Media Metrix, October 2019 Benefit #2 Benefit #2: High Intent Consumers SurveyMonkey Survey, 2019 -

Off Premise: How to Navigate the Shift Operators Are Advancing Take-Out & Delivery
SPECIAL EDITION - SUMMER/FALL 2020 CASTING LIGHT ON TODAY’S PACKAGING TRENDS OFF PREMISE: HOW TO NAVIGATE THE SHIFT OPERATORS ARE ADVANCING TAKE-OUT & DELIVERY INTRODUCING KRAFT COLLECTION INSIGHTS With nearly 40 years in the Foodservice industry, Sabert’s success is driven by our steadfast commitment to incorporating the voice of our customers into everything we do. We take tremendous pride in our ability to truly listen to the market and rapidly evolve to help our customers enhance and advance the consumer experience. You asked, we delivered High demand for off-premise dining coupled with the growing consumer desire to minimize environmental impact has driven the need for innovative sustainable packaging solutions. Today, we are happy to announce the launch of our new product line, the Sabert Kraft Collection. The Kraft Collection features an array of corrugated and paperboard food packaging solutions designed to reduce environmental impact without sacrificing on strength and performance. These versatile products provide operators with endless possibilities to ensure their off-premise programs are successful. The massive shift to off-premise As the world continues to grapple with the global health crisis caused by COVID-19, it is safe to say that no industry has quite experienced the level of rapid change that we have seen within foodservice. With “social distancing” now permanently etched into our daily vocabulary, many operators across the country have been forced to shift their business models to exclusively offer off- premise and delivery, nearly overnight. While consumers are adjusting to this new reality, their behaviors and expectations have changed as the demand for food safety, sustainability, and transparency is at an all-time high. -
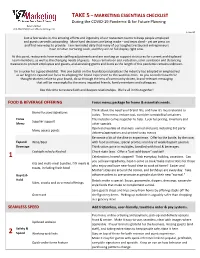
Marketing Essentials Checklist
TAKE 5 – MARKETING ESSENTIALS CHECKLIST During the COVID-19 Pandemic & for Future Planning Karen Zaniker 410-384-9240 | [email protected] 1-Apr-20 Just a few weeks in, the amazing efforts and ingenuity of our restaurant teams to keep people employed and guests served is astounding. More hard decisions are being made – and tears shed – yet we press on and find new ways to provide. I am reminded daily that many of our toughest restaurant entrepreneurs have creative nurturing souls, and they are on full display right now. At this point, restaurants have made staffing adjustments and are working on support structures for current and displaced team members, as well as the changing needs of guests. Focus remains on cost reduction, strict sanitation and distancing measures to protect employees and guests, and accessing grants and loans as the length of this pandemic remains unknown. I'm a sucker for a good checklist. This one builds on the foundational practices the industry has adopted or emphasized as we begin to expand our focus to adapting the brand experience to this world in crisis. As you consider how these thought-starters relate to your brand, do so through the lens of community-driven, brand-relevant messaging that will be meaningful to the many impacted friends, family members and colleagues. Use this time to restore faith and deepen relationships. We're all in this together! FOOD & BEVERAGE OFFERING Focus menu; package for home & essentials needs. Think about the need your brand fills, and how it's most relevant to Brand-focused signatures today. -

Drive Restaurant Sales with Clover Online Ordering
Drive restaurant sales with Clover Online Ordering The how-to guide to get noticed and increase online orders Congratulations on signing up for Clover Online Ordering! (And if you haven’t yet, we’ll show you how easy it is to do.) Now’s the time to get the word out to increase your online order volume. Clover has put together some easy (and free) ways to help you grow your online ordering business. What’s inside Section 1 Getting started Section 2 Promoting your online ordering page Section 3 Why having a website is beneicial for online ordering Section 4 Making your website work for you Section 5 Now’s the time to get social Section 6 Google, Yelp, and other directory listings Section 7 Generate more online orders with email Section 8 The power of great signage Section 9 Community outreach Section 10 Mobile orders and rewards - the Clover app Section 11 Keep it safe, keep it simple SECTION Drive restaurant sales with Clover Online Ordering 1 Getting started A great feature of Clover Online Ordering is that an ordering web page will be created for your restaurant by Clover and The Ordering.app, now part of Google, so you don't need to have a website to accept online orders. Follow these simple instructions to get your online 3. Maintain your inventory menu in the Clover Dashboard ordering menu up and running. so that your online menu will automatically be updated. 1. Review merchant terms and sign up for all online services in You can edit your menu at any time and changes will Clover Online Ordering to maximize the incoming number of automatically sync.