Multi-Pronged Human Protein Mimicry by SARS-Cov-2 Reveals
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Nuclear Organization and the Epigenetic Landscape of the Mus Musculus X-Chromosome Alicia Liu University of Connecticut - Storrs, [email protected]
University of Connecticut OpenCommons@UConn Doctoral Dissertations University of Connecticut Graduate School 8-9-2019 Nuclear Organization and the Epigenetic Landscape of the Mus musculus X-Chromosome Alicia Liu University of Connecticut - Storrs, [email protected] Follow this and additional works at: https://opencommons.uconn.edu/dissertations Recommended Citation Liu, Alicia, "Nuclear Organization and the Epigenetic Landscape of the Mus musculus X-Chromosome" (2019). Doctoral Dissertations. 2273. https://opencommons.uconn.edu/dissertations/2273 Nuclear Organization and the Epigenetic Landscape of the Mus musculus X-Chromosome Alicia J. Liu, Ph.D. University of Connecticut, 2019 ABSTRACT X-linked imprinted genes have been hypothesized to contribute parent-of-origin influences on social cognition. A cluster of imprinted genes Xlr3b, Xlr4b, and Xlr4c, implicated in cognitive defects, are maternally expressed and paternally silent in the murine brain. These genes defy classic mechanisms of autosomal imprinting, suggesting a novel method of imprinted gene regulation. Using Xlr3b and Xlr4c as bait, this study uses 4C-Seq on neonatal whole brain of a 39,XO mouse model, to provide the first in-depth analysis of chromatin dynamics surrounding an imprinted locus on the X-chromosome. Significant differences in long-range contacts exist be- tween XM and XP monosomic samples. In addition, XM interaction profiles contact a greater number of genes linked to cognitive impairment, abnormality of the nervous system, and abnormality of higher mental function. This is not a pattern that is unique to the imprinted Xlr3/4 locus. Additional Alicia J. Liu - University of Connecticut - 2019 4C-Seq experiments show that other genes on the X-chromosome, implicated in intellectual disability and/or ASD, also produce more maternal contacts to other X-linked genes linked to cognitive impairment. -

Gene Knockdown of CENPA Reduces Sphere Forming Ability and Stemness of Glioblastoma Initiating Cells
Neuroepigenetics 7 (2016) 6–18 Contents lists available at ScienceDirect Neuroepigenetics journal homepage: www.elsevier.com/locate/nepig Gene knockdown of CENPA reduces sphere forming ability and stemness of glioblastoma initiating cells Jinan Behnan a,1, Zanina Grieg b,c,1, Mrinal Joel b,c, Ingunn Ramsness c, Biljana Stangeland a,b,⁎ a Department of Molecular Medicine, Institute of Basic Medical Sciences, The Medical Faculty, University of Oslo, Oslo, Norway b Norwegian Center for Stem Cell Research, Department of Immunology and Transfusion Medicine, Oslo University Hospital, Oslo, Norway c Vilhelm Magnus Laboratory for Neurosurgical Research, Institute for Surgical Research and Department of Neurosurgery, Oslo University Hospital, Oslo, Norway article info abstract Article history: CENPA is a centromere-associated variant of histone H3 implicated in numerous malignancies. However, the Received 20 May 2016 role of this protein in glioblastoma (GBM) has not been demonstrated. GBM is one of the most aggressive Received in revised form 23 July 2016 human cancers. GBM initiating cells (GICs), contained within these tumors are deemed to convey Accepted 2 August 2016 characteristics such as invasiveness and resistance to therapy. Therefore, there is a strong rationale for targeting these cells. We investigated the expression of CENPA and other centromeric proteins (CENPs) in Keywords: fi CENPA GICs, GBM and variety of other cell types and tissues. Bioinformatics analysis identi ed the gene signature: fi Centromeric proteins high_CENP(AEFNM)/low_CENP(BCTQ) whose expression correlated with signi cantly worse GBM patient Glioblastoma survival. GBM Knockdown of CENPA reduced sphere forming ability, proliferation and cell viability of GICs. We also Brain tumor detected significant reduction in the expression of stemness marker SOX2 and the proliferation marker Glioblastoma initiating cells and therapeutic Ki67. -

Identification of Conserved Genes Triggering Puberty in European Sea
Blázquez et al. BMC Genomics (2017) 18:441 DOI 10.1186/s12864-017-3823-2 RESEARCHARTICLE Open Access Identification of conserved genes triggering puberty in European sea bass males (Dicentrarchus labrax) by microarray expression profiling Mercedes Blázquez1,2* , Paula Medina1,2,3, Berta Crespo1,4, Ana Gómez1 and Silvia Zanuy1* Abstract Background: Spermatogenesisisacomplexprocesscharacterized by the activation and/or repression of a number of genes in a spatio-temporal manner. Pubertal development in males starts with the onset of the first spermatogenesis and implies the division of primary spermatogonia and their subsequent entry into meiosis. This study is aimed at the characterization of genes involved in the onset of puberty in European sea bass, and constitutes the first transcriptomic approach focused on meiosis in this species. Results: European sea bass testes collected at the onset of puberty (first successful reproduction) were grouped in stage I (resting stage), and stage II (proliferative stage). Transition from stage I to stage II was marked by an increase of 11ketotestosterone (11KT), the main fish androgen, whereas the transcriptomic study resulted in 315 genes differentially expressed between the two stages. The onset of puberty induced 1) an up-regulation of genes involved in cell proliferation, cell cycle and meiosis progression, 2) changes in genes related with reproduction and growth, and 3) a down-regulation of genes included in the retinoic acid (RA) signalling pathway. The analysis of GO-terms and biological pathways showed that cell cycle, cell division, cellular metabolic processes, and reproduction were affected, consistent with the early events that occur during the onset of puberty. -
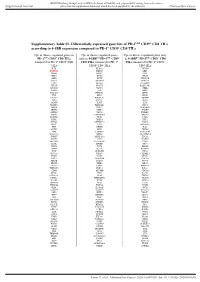
Supplementary Table S5. Differentially Expressed Gene Lists of PD-1High CD39+ CD8 Tils According to 4-1BB Expression Compared to PD-1+ CD39- CD8 Tils
BMJ Publishing Group Limited (BMJ) disclaims all liability and responsibility arising from any reliance Supplemental material placed on this supplemental material which has been supplied by the author(s) J Immunother Cancer Supplementary Table S5. Differentially expressed gene lists of PD-1high CD39+ CD8 TILs according to 4-1BB expression compared to PD-1+ CD39- CD8 TILs Up- or down- regulated genes in Up- or down- regulated genes Up- or down- regulated genes only PD-1high CD39+ CD8 TILs only in 4-1BBneg PD-1high CD39+ in 4-1BBpos PD-1high CD39+ CD8 compared to PD-1+ CD39- CD8 CD8 TILs compared to PD-1+ TILs compared to PD-1+ CD39- TILs CD39- CD8 TILs CD8 TILs IL7R KLRG1 TNFSF4 ENTPD1 DHRS3 LEF1 ITGA5 MKI67 PZP KLF3 RYR2 SIK1B ANK3 LYST PPP1R3B ETV1 ADAM28 H2AC13 CCR7 GFOD1 RASGRP2 ITGAX MAST4 RAD51AP1 MYO1E CLCF1 NEBL S1PR5 VCL MPP7 MS4A6A PHLDB1 GFPT2 TNF RPL3 SPRY4 VCAM1 B4GALT5 TIPARP TNS3 PDCD1 POLQ AKAP5 IL6ST LY9 PLXND1 PLEKHA1 NEU1 DGKH SPRY2 PLEKHG3 IKZF4 MTX3 PARK7 ATP8B4 SYT11 PTGER4 SORL1 RAB11FIP5 BRCA1 MAP4K3 NCR1 CCR4 S1PR1 PDE8A IFIT2 EPHA4 ARHGEF12 PAICS PELI2 LAT2 GPRASP1 TTN RPLP0 IL4I1 AUTS2 RPS3 CDCA3 NHS LONRF2 CDC42EP3 SLCO3A1 RRM2 ADAMTSL4 INPP5F ARHGAP31 ESCO2 ADRB2 CSF1 WDHD1 GOLIM4 CDK5RAP1 CD69 GLUL HJURP SHC4 GNLY TTC9 HELLS DPP4 IL23A PITPNC1 TOX ARHGEF9 EXO1 SLC4A4 CKAP4 CARMIL3 NHSL2 DZIP3 GINS1 FUT8 UBASH3B CDCA5 PDE7B SOGA1 CDC45 NR3C2 TRIB1 KIF14 TRAF5 LIMS1 PPP1R2C TNFRSF9 KLRC2 POLA1 CD80 ATP10D CDCA8 SETD7 IER2 PATL2 CCDC141 CD84 HSPA6 CYB561 MPHOSPH9 CLSPN KLRC1 PTMS SCML4 ZBTB10 CCL3 CA5B PIP5K1B WNT9A CCNH GEM IL18RAP GGH SARDH B3GNT7 C13orf46 SBF2 IKZF3 ZMAT1 TCF7 NECTIN1 H3C7 FOS PAG1 HECA SLC4A10 SLC35G2 PER1 P2RY1 NFKBIA WDR76 PLAUR KDM1A H1-5 TSHZ2 FAM102B HMMR GPR132 CCRL2 PARP8 A2M ST8SIA1 NUF2 IL5RA RBPMS UBE2T USP53 EEF1A1 PLAC8 LGR6 TMEM123 NEK2 SNAP47 PTGIS SH2B3 P2RY8 S100PBP PLEKHA7 CLNK CRIM1 MGAT5 YBX3 TP53INP1 DTL CFH FEZ1 MYB FRMD4B TSPAN5 STIL ITGA2 GOLGA6L10 MYBL2 AHI1 CAND2 GZMB RBPJ PELI1 HSPA1B KCNK5 GOLGA6L9 TICRR TPRG1 UBE2C AURKA Leem G, et al. -

Supplementary Table S1. Correlation Between the Mutant P53-Interacting Partners and PTTG3P, PTTG1 and PTTG2, Based on Data from Starbase V3.0 Database
Supplementary Table S1. Correlation between the mutant p53-interacting partners and PTTG3P, PTTG1 and PTTG2, based on data from StarBase v3.0 database. PTTG3P PTTG1 PTTG2 Gene ID Coefficient-R p-value Coefficient-R p-value Coefficient-R p-value NF-YA ENSG00000001167 −0.077 8.59e-2 −0.210 2.09e-6 −0.122 6.23e-3 NF-YB ENSG00000120837 0.176 7.12e-5 0.227 2.82e-7 0.094 3.59e-2 NF-YC ENSG00000066136 0.124 5.45e-3 0.124 5.40e-3 0.051 2.51e-1 Sp1 ENSG00000185591 −0.014 7.50e-1 −0.201 5.82e-6 −0.072 1.07e-1 Ets-1 ENSG00000134954 −0.096 3.14e-2 −0.257 4.83e-9 0.034 4.46e-1 VDR ENSG00000111424 −0.091 4.10e-2 −0.216 1.03e-6 0.014 7.48e-1 SREBP-2 ENSG00000198911 −0.064 1.53e-1 −0.147 9.27e-4 −0.073 1.01e-1 TopBP1 ENSG00000163781 0.067 1.36e-1 0.051 2.57e-1 −0.020 6.57e-1 Pin1 ENSG00000127445 0.250 1.40e-8 0.571 9.56e-45 0.187 2.52e-5 MRE11 ENSG00000020922 0.063 1.56e-1 −0.007 8.81e-1 −0.024 5.93e-1 PML ENSG00000140464 0.072 1.05e-1 0.217 9.36e-7 0.166 1.85e-4 p63 ENSG00000073282 −0.120 7.04e-3 −0.283 1.08e-10 −0.198 7.71e-6 p73 ENSG00000078900 0.104 2.03e-2 0.258 4.67e-9 0.097 3.02e-2 Supplementary Table S2. -

Non-Synonymous Mutations Mapped to Chromosome X Associated With
de Camargo et al. BMC Genomics (2015) 16:384 DOI 10.1186/s12864-015-1595-0 RESEARCH ARTICLE Open Access Non-synonymous mutations mapped to chromosome X associated with andrological and growth traits in beef cattle Gregório Miguel Ferreira de Camargo1,2,3, Laercio R Porto-Neto2, Matthew J Kelly3, Rowan J Bunch2, Sean M McWilliam2, Humberto Tonhati1, Sigrid A Lehnert2, Marina R S Fortes3* and Stephen S Moore4 Abstract Background: Previous genome-wide association analyses identified QTL regions in the X chromosome for percentage of normal sperm and scrotal circumference in Brahman and Tropical Composite cattle. These traits are important to be studied because they are indicators of male fertility and are correlated with female sexual precocity and reproductive longevity. The aim was to investigate candidate genes in these regions and to identify putative causative mutations that influence these traits. In addition, we tested the identified mutations for female fertility and growth traits. Results: Using a combination of bioinformatics and molecular assay technology, twelve non-synonymous SNPs in eleven genes were genotyped in a cattle population. Three and nine SNPs explained more than 1% of the additive genetic variance for percentage of normal sperm and scrotal circumference, respectively. The SNPs that had a major influence in percentage of normal sperm were mapped to LOC100138021 and TAF7L genes; and in TEX11 and AR genes for scrotal circumference. One SNP in TEX11 was explained ~13% of the additive genetic variance for scrotal circumference at 12 months. The tested SNP were also associated with weight measurements, but not with female fertility traits. -

Bioinformatics Analysis for the Identification of Differentially Expressed Genes and Related Signaling Pathways in H
Bioinformatics analysis for the identification of differentially expressed genes and related signaling pathways in H. pylori-CagA transfected gastric cancer cells Dingyu Chen*, Chao Li, Yan Zhao, Jianjiang Zhou, Qinrong Wang and Yuan Xie* Key Laboratory of Endemic and Ethnic Diseases , Ministry of Education, Guizhou Medical University, Guiyang, China * These authors contributed equally to this work. ABSTRACT Aim. Helicobacter pylori cytotoxin-associated protein A (CagA) is an important vir- ulence factor known to induce gastric cancer development. However, the cause and the underlying molecular events of CagA induction remain unclear. Here, we applied integrated bioinformatics to identify the key genes involved in the process of CagA- induced gastric epithelial cell inflammation and can ceration to comprehend the potential molecular mechanisms involved. Materials and Methods. AGS cells were transected with pcDNA3.1 and pcDNA3.1::CagA for 24 h. The transfected cells were subjected to transcriptome sequencing to obtain the expressed genes. Differentially expressed genes (DEG) with adjusted P value < 0.05, | logFC |> 2 were screened, and the R package was applied for gene ontology (GO) enrichment and the Kyoto Encyclopedia of Genes and Genomes (KEGG) pathway analysis. The differential gene protein–protein interaction (PPI) network was constructed using the STRING Cytoscape application, which conducted visual analysis to create the key function networks and identify the key genes. Next, the Submitted 20 August 2020 Kaplan–Meier plotter survival analysis tool was employed to analyze the survival of the Accepted 11 March 2021 key genes derived from the PPI network. Further analysis of the key gene expressions Published 15 April 2021 in gastric cancer and normal tissues were performed based on The Cancer Genome Corresponding author Atlas (TCGA) database and RT-qPCR verification. -

Arsenic Hexoxide Has Differential Effects on Cell Proliferation And
www.nature.com/scientificreports OPEN Arsenic hexoxide has diferential efects on cell proliferation and genome‑wide gene expression in human primary mammary epithelial and MCF7 cells Donguk Kim1,7, Na Yeon Park2,7, Keunsoo Kang3, Stuart K. Calderwood4, Dong‑Hyung Cho2, Ill Ju Bae5* & Heeyoun Bunch1,6* Arsenic is reportedly a biphasic inorganic compound for its toxicity and anticancer efects in humans. Recent studies have shown that certain arsenic compounds including arsenic hexoxide (AS4O6; hereafter, AS6) induce programmed cell death and cell cycle arrest in human cancer cells and murine cancer models. However, the mechanisms by which AS6 suppresses cancer cells are incompletely understood. In this study, we report the mechanisms of AS6 through transcriptome analyses. In particular, the cytotoxicity and global gene expression regulation by AS6 were compared in human normal and cancer breast epithelial cells. Using RNA‑sequencing and bioinformatics analyses, diferentially expressed genes in signifcantly afected biological pathways in these cell types were validated by real‑time quantitative polymerase chain reaction and immunoblotting assays. Our data show markedly diferential efects of AS6 on cytotoxicity and gene expression in human mammary epithelial normal cells (HUMEC) and Michigan Cancer Foundation 7 (MCF7), a human mammary epithelial cancer cell line. AS6 selectively arrests cell growth and induces cell death in MCF7 cells without afecting the growth of HUMEC in a dose‑dependent manner. AS6 alters the transcription of a large number of genes in MCF7 cells, but much fewer genes in HUMEC. Importantly, we found that the cell proliferation, cell cycle, and DNA repair pathways are signifcantly suppressed whereas cellular stress response and apoptotic pathways increase in AS6‑treated MCF7 cells. -

How Does SUMO Participate in Spindle Organization?
cells Review How Does SUMO Participate in Spindle Organization? Ariane Abrieu * and Dimitris Liakopoulos * CRBM, CNRS UMR5237, Université de Montpellier, 1919 route de Mende, 34090 Montpellier, France * Correspondence: [email protected] (A.A.); [email protected] (D.L.) Received: 5 July 2019; Accepted: 30 July 2019; Published: 31 July 2019 Abstract: The ubiquitin-like protein SUMO is a regulator involved in most cellular mechanisms. Recent studies have discovered new modes of function for this protein. Of particular interest is the ability of SUMO to organize proteins in larger assemblies, as well as the role of SUMO-dependent ubiquitylation in their disassembly. These mechanisms have been largely described in the context of DNA repair, transcriptional regulation, or signaling, while much less is known on how SUMO facilitates organization of microtubule-dependent processes during mitosis. Remarkably however, SUMO has been known for a long time to modify kinetochore proteins, while more recently, extensive proteomic screens have identified a large number of microtubule- and spindle-associated proteins that are SUMOylated. The aim of this review is to focus on the possible role of SUMOylation in organization of the spindle and kinetochore complexes. We summarize mitotic and microtubule/spindle-associated proteins that have been identified as SUMO conjugates and present examples regarding their regulation by SUMO. Moreover, we discuss the possible contribution of SUMOylation in organization of larger protein assemblies on the spindle, as well as the role of SUMO-targeted ubiquitylation in control of kinetochore assembly and function. Finally, we propose future directions regarding the study of SUMOylation in regulation of spindle organization and examine the potential of SUMO and SUMO-mediated degradation as target for antimitotic-based therapies. -

Download From
bioRxiv preprint doi: https://doi.org/10.1101/2020.09.02.279679; this version posted September 2, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. A high-throughput CRISPR interference screen for dissecting functional regulators of GPCR/cAMP signaling Khairunnisa Mentari Semesta1, Ruilin Tian2,3,4, Martin Kampmann2,3, Mark von Zastrow5,6 and Nikoleta G. Tsvetanova1* 1 Department of Pharmacology and Cancer Biology, Duke University, Durham, NC 27710, USA 2 Insitute for Neurodegenerative Diseases, Department of Biochemistry and Biophysics, University of California, San Francisco, CA 94158, USA 3 Chen-Zuckerberg Biohub, San Francisco, CA 94158, USA 4 Biophysics Graduate Program, University of California, San Francisco, CA 94158, USA 5 Department of Psychiatry, University of California, San Francisco, CA 94158, USA 6 Department of Cellular & Molecular Pharmacology, University of California, San Francisco, CA 94158, USA * Correspondence: [email protected] 1 bioRxiv preprint doi: https://doi.org/10.1101/2020.09.02.279679; this version posted September 2, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. 1 Abstract 2 G protein-coupled receptors (GPCRs) allow cells to respond to chemical and sensory 3 stimuli through generation of second messengers, such as cyclic AMP (cAMP), which in 4 turn mediate a myriad of processes, including cell survival, proliferation, and 5 differentiation. -

Nº Ref Uniprot Proteína Péptidos Identificados Por MS/MS 1 P01024
Document downloaded from http://www.elsevier.es, day 26/09/2021. This copy is for personal use. Any transmission of this document by any media or format is strictly prohibited. Nº Ref Uniprot Proteína Péptidos identificados 1 P01024 CO3_HUMAN Complement C3 OS=Homo sapiens GN=C3 PE=1 SV=2 por 162MS/MS 2 P02751 FINC_HUMAN Fibronectin OS=Homo sapiens GN=FN1 PE=1 SV=4 131 3 P01023 A2MG_HUMAN Alpha-2-macroglobulin OS=Homo sapiens GN=A2M PE=1 SV=3 128 4 P0C0L4 CO4A_HUMAN Complement C4-A OS=Homo sapiens GN=C4A PE=1 SV=1 95 5 P04275 VWF_HUMAN von Willebrand factor OS=Homo sapiens GN=VWF PE=1 SV=4 81 6 P02675 FIBB_HUMAN Fibrinogen beta chain OS=Homo sapiens GN=FGB PE=1 SV=2 78 7 P01031 CO5_HUMAN Complement C5 OS=Homo sapiens GN=C5 PE=1 SV=4 66 8 P02768 ALBU_HUMAN Serum albumin OS=Homo sapiens GN=ALB PE=1 SV=2 66 9 P00450 CERU_HUMAN Ceruloplasmin OS=Homo sapiens GN=CP PE=1 SV=1 64 10 P02671 FIBA_HUMAN Fibrinogen alpha chain OS=Homo sapiens GN=FGA PE=1 SV=2 58 11 P08603 CFAH_HUMAN Complement factor H OS=Homo sapiens GN=CFH PE=1 SV=4 56 12 P02787 TRFE_HUMAN Serotransferrin OS=Homo sapiens GN=TF PE=1 SV=3 54 13 P00747 PLMN_HUMAN Plasminogen OS=Homo sapiens GN=PLG PE=1 SV=2 48 14 P02679 FIBG_HUMAN Fibrinogen gamma chain OS=Homo sapiens GN=FGG PE=1 SV=3 47 15 P01871 IGHM_HUMAN Ig mu chain C region OS=Homo sapiens GN=IGHM PE=1 SV=3 41 16 P04003 C4BPA_HUMAN C4b-binding protein alpha chain OS=Homo sapiens GN=C4BPA PE=1 SV=2 37 17 Q9Y6R7 FCGBP_HUMAN IgGFc-binding protein OS=Homo sapiens GN=FCGBP PE=1 SV=3 30 18 O43866 CD5L_HUMAN CD5 antigen-like OS=Homo -

LSD1 Tunes Adipose Tissues in Response to Environmental Cues, Adipose Tissues Adapt Their Metabolism to Maintain Energy Balance
RESEARCH HIGHLIGHTS IN BRIEF METABOLISM LSD1 tunes adipose tissues In response to environmental cues, adipose tissues adapt their metabolism to maintain energy balance. This study shows that Lys-specific histone demethylase 1 (LSD1) promotes oxidative metabolism and the formation of brown-fat-like adipocytes in white adipose tissue (WAT). Following cold exposure or β3‑adrenergic treatment, LSD1 levels were increased in mouse WAT; this enhanced mitochondrial activity in differentiated adipocytes. LSD1, together with nuclear respiratory factor 1 (NRF1), activated genes involved in oxidative phosphorylation and mitochondrial biogenesis. Moreover, transgenic expression of LSD1 in mice led to the formation of metabolically active brown-fat-like adipocytes in WAT, enhanced oxidative capacity and increased energy expenditure, which limited weight gain in response to a high-fat diet. Thus, LSD1 regulates thermogenesis and oxidative metabolism in adipose tissue. ORIGINAL RESEARCH PAPER Duteil, D. et al. LSD1 promotes oxidative metabolism of white adipose tissue. Nature Commun. http://dx.doi.org/10.1038/ncomms5093 (2014) CELL CYCLE Making the spindle checkpoint strong Spindle checkpoint signals (generated by checkpoint proteins, including MAD1 and the RZZ (Rod–Zw10–Zwilch) complex) arrest mitosis until all kinetochores are correctly attached to spindle microtubules, whereupon checkpoint proteins are removed in a dynein-dependent manner. Matson and Stukenberg report that the centromeric protein CENPI is required for the stable association of MAD1 and RZZ with kinetochores. CENPI cooperated with Aurora B in the recruitment of MAD1 and RZZ. Moreover, CENPI prevented their premature removal by dynein in an Aurora B-independent manner. Thus, CENPI and Aurora B create and maintain a robust checkpoint signal until all spindle attachments are correctly formed.