Automated Spyware Collection and Analysis
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Complete Malware Protection for Your Business
Complete Malware Protection for your Business ENDPOINT MALWARE PROTECTION WITH FLEXIBLE CLIENT MANAGEMENT Undetected malware on corporate computers can lead to theft of confidential data, network corruption, drained system resources, and considerable financial damage due to loss of valuable working time. With the nature of today’s cyber threats, busi- nesses need advanced workstation solutions in place to prevent the risks that insuf- ficient security brings. Lavasoft, the makers of industry-leading Ad-Aware Internet Security, are introducing an innovative new solution for today’s companies in need of effectively protecting their network computers, without sacrificing limited budgets or straining IT infrastructures. Ad-Aware Business Security combines the powerful protection and efficiency of our strong antimalware solutions with a central, easy-to-use management tool. Proactively defend corporate data with maximum security against viruses, spyware, rootkits and other malicious threats – allowing your IT professionals to centrally ad- minister, protect and control the security of workstations in your company’s network. COMPREHENSIVE MALWARE PROTECTION Secure business PCs with an advanced online defense against blended malware, spyware, viruses, worms, and other potential data thieves with Ad-Aware Business Security’s extensive threat database, along with continuous pulse updates to guard KEY FEATURES against new attacks. Business Client and Management Agent for Leading behavior-based heuristics anti-malware technology and continuous push WinCentrally managed Internet security (pulse) updates to guard your business’ PCs against immediate and unknown emerg- ing - threats. High performance, low resource impact Integrated real-time protection that immediately detects and blocks malware ap- Powerful antimalware engines plications to prevent further system damage. -

Your Member Benefit
Your Member Benefit General tech support at no additional cost to you. Friendly Tech Helpline analysts can help you resolve problems with your computers, (866) 232-1831 tablets, printers, scanners, smartphones, and more. http://chat.TechHelpline.com The best part is that Tech Helpline is your member benefit included in your association dues. [email protected] Monday-Friday: 9AM to 8PM Saturday: 9AM to 5PM ET brought to you by SM Basic Coverage • Instruction for installing and configuring new hardware and software • Diagnosis and repair of computer hardware and software issues • Advice for purchasing hardware, software and services • Basic instruction for major software applications • Recommendations for upgrades and updates • Advice for performance optimization • Troubleshooting network issues Support Operating Systems: Software Applications: All PC compatible, Mac • Microsoft Windows 10® Email and clones such as: • Microsoft Windows 7® • MS Outlook • Acer • Microsoft Windows 8® • Webmail • Apple • Mac OS X ® (10.3 and higher) • Windows Mail • AST • ASUS Hardware: Real Estate Specific • Clones / Whitebox • Form Simplicity • Dell • Smartphones: iPhones, Android, • The Living Network • Epson Windows • Fujitsu • Tablets: iOS, Android, Windows Office/Financial • Gateway • Digital Cameras • Adaptec Toast • Hewlett Packard • CD/DVD Drives & Blu-ray • Adaptec EZCD Creator • IBM • Laptops • Adobe Acrobat • Lenovo • Monitors • Corel Offi ce Products: • Sony • Network Adaptors WordPerfect, Quattro Pro • Toshiba • PC add-on cards Presentations, -

Usability and Security of Personal Firewalls
Usability and Security of Personal Firewalls Almut Herzog^ and Nahid Shahmehri^ Dept. of Computer and Information Science, Linkopings universitet,Sweden {almhe, nahsh}@ida.liu.se Abstract. Effective security of a personal firewall depends on (1) the rule granularity and the implementation of the rule enforcement and (2) the correctness and granularity of user decisions at the time of an alert. A misconfigured or loosely configured firewall may be more dangerous than no firewall at all because of the user's false sense of security. This study assesses effective security of 13 personal firewalls by comparing possible granularity of rules as well as the usability of rule set-up and its influence on security. In order to evaluate usability, we have submitted each firewall to use cases that require user decisions and cause rule creation. In order to evaluate the firewalls' security, we analysed the created rules. In ad dition, we ran a port scan and replaced a legitimate, network-enabled application with another program to etssess the firewalls' behaviour in misuse cases. We have conducted a cognitive walkthrough paying special attention to user guidance and user decision support. We conclude that a stronger emphasis on user guidance, on conveying the design of the personal firewall application, on the principle of least privilege and on implications of default settings would greatly enhance both usability and security of personal firewalls. 1 Introduction In times where roaming users connect their laptops to a variety of public, pri vate and corporate wireless or wired networks and in times where more and more computers are always online, host-based firewalls implemented in soft ware, called personal firewalls, have become an important part of the security armour of a personal computer. -

Hostscan 4.8.01064 Antimalware and Firewall Support Charts
HostScan 4.8.01064 Antimalware and Firewall Support Charts 10/1/19 © 2019 Cisco and/or its affiliates. All rights reserved. This document is Cisco public. Page 1 of 76 Contents HostScan Version 4.8.01064 Antimalware and Firewall Support Charts ............................................................................... 3 Antimalware and Firewall Attributes Supported by HostScan .................................................................................................. 3 OPSWAT Version Information ................................................................................................................................................. 5 Cisco AnyConnect HostScan Antimalware Compliance Module v4.3.890.0 for Windows .................................................. 5 Cisco AnyConnect HostScan Firewall Compliance Module v4.3.890.0 for Windows ........................................................ 44 Cisco AnyConnect HostScan Antimalware Compliance Module v4.3.824.0 for macos .................................................... 65 Cisco AnyConnect HostScan Firewall Compliance Module v4.3.824.0 for macOS ........................................................... 71 Cisco AnyConnect HostScan Antimalware Compliance Module v4.3.730.0 for Linux ...................................................... 73 Cisco AnyConnect HostScan Firewall Compliance Module v4.3.730.0 for Linux .............................................................. 76 ©201 9 Cisco and/or its affiliates. All rights reserved. This document is Cisco Public. -

A Glance Into the Eye Pyramid Technical Article V2
A glance into the Eye Pyramid RĂZVAN OLTEANU Security Reasercher We keep you safe and we keep it simple. 01 Introduction On January 11, 2017 Italian news agency AGI, published a court order regarding cyber-attacks against high ranking Italian government members and Italian institutions. The attacks were conducted by two Italian brothers to get financial information that would help them gain an advantage when trading on financial markets. Overview The campaign was carried out over several years starting in 2008 and continuing into 2010, 2011, 2012 and 2014. The mechanism the brothers used to distribute their malware was simple; targeted spear-phishing emails aimed at victims who had already been selected. The emails con- tained a malware attachment, which once opened harvested information from the victims’ computers. This information consisted of pictures, documents, archives, presenta- tions, email contacts, email bodies, usernames, passwords, keystrokes, web pages content and databases. Technical details The malware was written in VisualBasic.net and was obfuscated twice using common obfuscators: Dotfuscator and Skater .NET which can be easily reversed. The malware stored its sensitive data – license keys, URLs and paths – by encrypting with the Triple DES algorithm using the MD5 of a provided password as key and SHA256 of the pass- word as initialization vector. A glance into the Eye Pyramid 01 02 Figure 1 Security applications To remain unnoticed, it tried to disable any security application installed on the victim’s computer. Targeted -

Speed up Your Computer
Speed Up Your Computer Clean Up Your Hard Drive Uninstall unneeded programs: Get rid of old or unused programs. Have only one anti-virus software. Run Disk Cleanup: (Programs > Accessories > System Tools) Disk Cleanup gets rid of the temporary files that accumulate through web browsing, program installation, and general usage. Defragment: (Programs > Accessories > System Tools) Your hard drive is made up of many layers. When a program is installed, pieces of it can be written on different areas of the hard drive. Defragmenting reorganizes the hard drive so all the files are closer together, therefore the computer can find the files quicker. Run a Full Anti-virus and Anti-spyware Scan Some viruses, such as Trojans, convert your computer into a spamming host, crippling your computer. Several anti-virus programs are very efficient and free of charge. Two of these programs, Microsoft Security Essentials and AVG, are linked on the AU Install website (http://www.auburn.edu/download). Spyware & Malware is the #1 cause of slowness of computers. Get anti-spyware software and run it often. In addition to your anti-virus software, Malwarebytes, Lavasoft’s Ad-Aware, and Spybot’s Search & Destroy are good free products. A couple other good tools are TDSSKiller and ComboFix. Stop Auto-Starting Programs These programs start when you boot your computer and remain running. Go to Start > Programs > Startup and delete the items in this folder. To identify other programs running at start but not listed in that folder, go to Start > Run > type “msconfig”. On the Startup tab you can select which programs to enable/disable. -

Excerpts from Virus Bulletin Comparative Reviews August – December 2011
VIRUS BULLETIN AUTHORIZED REPRINT EXCERPTS FROM VIRUS BULLETIN COMPARATIVE REVIEWS AUGUST – DECEMBER 2011 VIRUS BULLETIN VB100 TESTING AUGUST 2011: WINDOWS VISTA X64 The basic requirements for a product Vista has been plagued by criticisms and complaints since its to achieve VB100 certifi cation status fi rst appearance in 2007, and has quickly been superseded by are that a product detects, in its a far superior replacement in Windows 7. Usage of Vista has default settings, all malware known declined very gradually though, with latest estimates putting to be ‘In the Wild’ at the time of it on around 10% to 15% of desktops. This makes it still a the review, and generates no false pretty signifi cant player in the market, and we feel obliged to positives when scanning a set of continue checking how well the current crop of anti-malware clean fi les. solutions perform on the platform. The clean test set saw a fair bit of attention this month, with Various other tests are also carried the usual cleanup of older and less relevant items, and the out as part of the comparative review addition of a swathe of new fi les culled from magazine cover process, including speed and overhead CDs, the most popular items from major download sites, measurements and ‘RAP’ (Reactive and Proactive) tests. as well as items from the download areas of some leading The RAP tests measure products’ detection rates across software brands. The fi nal set weighed in at just over half a four distinct sets of malware samples. The fi rst three of million fi les, 140GB. -
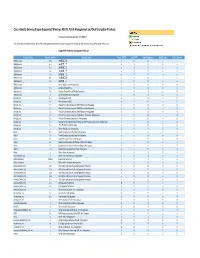
Cisco Identity Services Engine Supported Windows AV/AS/PM/DE
Cisco Identity Services Engine Supported Windows AS/AV, Patch Management and Disk Encryption Products Compliance Module Version 3.6.10363.2 This document provides Windows AS/AV, Patch Management and Disk Encryption support information on the the Cisco AnyConnect Agent Version 4.2. Supported Windows Antispyware Products Vendor_Name Product_Version Product_Name Check_FSRTP Set_FSRTP VirDef_Signature VirDef_Time VirDef_Version 360Safe.com 10.x 360安全卫士 vX X v v 360Safe.com 4.x 360安全卫士 vX X v v 360Safe.com 5.x 360安全卫士 vX X v v 360Safe.com 6.x 360安全卫士 vX X v v 360Safe.com 7.x 360安全卫士 vX X v v 360Safe.com 8.x 360安全卫士 vX X v v 360Safe.com 9.x 360安全卫士 vX X v v 360Safe.com x Other 360Safe.com Antispyware Z X X Z X Agnitum Ltd. 7.x Outpost Firewall Pro vX X X O Agnitum Ltd. 6.x Outpost Firewall Pro 2008 [AntiSpyware] v X X v O Agnitum Ltd. x Other Agnitum Ltd. Antispyware Z X X Z X AhnLab, Inc. 2.x AhnLab SpyZero 2.0 vv O v O AhnLab, Inc. 3.x AhnLab SpyZero 2007 X X O v O AhnLab, Inc. 7.x AhnLab V3 Internet Security 2007 Platinum AntiSpyware v X O v O AhnLab, Inc. 7.x AhnLab V3 Internet Security 2008 Platinum AntiSpyware v X O v O AhnLab, Inc. 7.x AhnLab V3 Internet Security 2009 Platinum AntiSpyware v v O v O AhnLab, Inc. 7.x AhnLab V3 Internet Security 7.0 Platinum Enterprise AntiSpyware v X O v O AhnLab, Inc. 8.x AhnLab V3 Internet Security 8.0 AntiSpyware v v O v O AhnLab, Inc. -

Cisco Identity Services Engine Release 1.2 Supported Windows
Cisco Identity Services Engine Supported Windows AV/AS Products Compliance Module Version 3.5.6317.2 This document provides Windows 8/7/Vista/XP AV/AS support information on the Cisco NAC Agent version 4.9.0.x and later. For other support information and complete release updates, refer to the Release Notes for Cisco Identity Services Engine corresponding to your Cisco Identity Services Engine release version. Supported Windows AV/AS Product Summary Added New AV Definition Support: COMODO Antivirus 5.x COMODO Internet Security 3.5.x COMODO Internet Security 3.x COMODO Internet Security 4.x Kingsoft Internet Security 2013.x Added New AV Products Support: V3 Click 1.x avast! Internet Security 8.x avast! Premier 8.x avast! Pro Antivirus 8.x Gen-X Total Security 1.x K7UltimateSecurity 13.x Kaspersky Endpoint Security 10.x Kaspersky PURE 13.x Norman Security Suite 10.x Supported Windows AntiVirus Products Product Name Product Version Installation Virus Definition Live Update 360Safe.com 360 Antivirus 1.x 4.9.0.28 / 3.4.21.1 4.9.0.28 / 3.4.21.1 yes 360 Antivirus 3.x 4.9.0.29 / 3.5.5767.2 4.9.0.29 / 3.5.5767.2 - 360杀毒 1.x 4.9.0.28 / 3.4.21.1 4.9.0.28 / 3.4.21.1 - 360杀毒 2.x 4.9.0.29 / 3.4.25.1 4.9.0.29 / 3.4.25.1 - 360杀毒 3.x 4.9.0.29 / 3.5.2101.2 - Other 360Safe.com Antivirus x 4.9.0.29 / 3.5.2101.2 - AEC, spol. -

Automated Malware Analysis Report For
ID: 314925 Sample Name: WebCompanion.exe Cookbook: default.jbs Time: 05:11:03 Date: 12/11/2020 Version: 31.0.0 Red Diamond Table of Contents Table of Contents 2 Analysis Report WebCompanion.exe 4 Overview 4 General Information 4 Detection 4 Signatures 4 Classification 4 Analysis Advice 4 Startup 4 Malware Configuration 4 Yara Overview 4 Sigma Overview 4 Signature Overview 5 Mitre Att&ck Matrix 5 Behavior Graph 5 Screenshots 6 Thumbnails 6 Antivirus, Machine Learning and Genetic Malware Detection 7 Initial Sample 7 Dropped Files 7 Unpacked PE Files 7 Domains 7 URLs 7 Domains and IPs 8 Contacted Domains 8 URLs from Memory and Binaries 8 Contacted IPs 10 Public 11 Private 11 General Information 11 Simulations 12 Behavior and APIs 12 Joe Sandbox View / Context 12 IPs 12 Domains 12 ASN 13 JA3 Fingerprints 13 Dropped Files 13 Created / dropped Files 13 Static File Info 14 General 14 File Icon 14 Static PE Info 14 General 14 Authenticode Signature 15 Entrypoint Preview 15 Data Directories 16 Sections 17 Resources 17 Imports 17 Network Behavior 17 UDP Packets 17 Code Manipulations 18 Statistics 19 Behavior 19 Copyright null 2020 Page 2 of 20 System Behavior 19 Analysis Process: WebCompanion.exe PID: 7132 Parent PID: 5936 19 General 19 File Activities 19 File Created 19 File Read 19 Analysis Process: dw20.exe PID: 4164 Parent PID: 7132 20 General 20 File Activities 20 Registry Activities 20 Disassembly 20 Code Analysis 20 Copyright null 2020 Page 3 of 20 Analysis Report WebCompanion.exe Overview General Information Detection Signatures Classification -

Everyone Has Technology Questions Tech Helpline Has the Answers
Everyone Has Technology Questions Tech Helpline has the answers. Access U.S.-Based Tech Support at NO ADDITIONAL COST. Tech Helpline is brought to you by REALTORS® Association of York & Adams Counties, Inc. Tech Helpline gives you U.S.-based tech support for hardware, software, networking and mobile devices. Our analysts are friendly 866-379-2113 technology experts who will assist you via phone, chat or email. They troubleshoot problems 9 a.m. - 8 p.m. Mon. - Fri. 9 a.m. - 5 p.m. Sat. and offer solutions, often by connecting remotely Eastern Time into your computer while you relax. Most importantly, they understand your needs as a REALTOR® http://chat.techhelpline.com [email protected] How Can Tech Helpline Assist You? Included Services • Instruction for installing and configuring new hardware and software • Diagnosis and repair of computer hardware and software issues • Advice for purchasing hardware, software and services • Basic instruction for major software applications • Recommendations for upgrades and updates • Advice for performance optimization • Troubleshooting network issues Tech Helpline Basic Coverage Operating Systems: Software Applications: All PC compatible, Mac and • Microsoft Windows 10® Email clones such as: • Microsoft Windows Vista® • MS Outlook • Acer • Microsoft Windows 7® • Webmail • Apple • Microsoft Windows 8® • Windows Mail • AST • Mac OS X (10.3 and higher)® • ASUS • Microsoft Windows XP ® Real Estate Specific • Clones / Whitebox • Form Simplicity • Dell Hardware: • The Living Network • Epson • Fujitsu -
ESAP 2.5.3 Release Notes
ESAP 2.5.3 Release Notes Version Windows and Mac 3.6.8682.2 (V2 Unified + V3) Published July 2015 ESAP 2.5.3 Release Notes ESAP 2.5.3 and Pulse Secure Access/Access Control Service Compatibility Chart: This ESAP package can be installed on the following Pulse Secure Access/Access Control Service software versions. • SA 8.0Rx • SA 7.4Rx • SA 7.3Rx • SA 7.2Rx • SA 7.1Rx • SA 7.0Rx • SA 6.5Rx • UAC 5.0Rx • UAC 4.4Rx • UAC 4.3Rx • UAC 4.2Rx • UAC 4.1Rx • UAC 4.0Rx • UAC 3.1Rx Note: The ESAP package may install and function without any errors on older releases however as the install has not been tested, we recommend that it be used only on the above versions of software releases. Support has been added for the following products in ESAP2.5.3 Windows OS Antivirus Products [Lavasoft, Inc.] Ad-Aware Free Antivirus + (11.x) [Lavasoft, Inc.] Ad-Aware Personal Security (11.x) [Lavasoft, Inc.] Ad-Aware Pro Security (11.x) [N-able Technologies Inc] Security Manager AV Defender (5.x) [Check Point, Inc] ZoneAlarm Internet Security Suite (12.x) © 2015 by Pulse Secure, LLC. All rights reserved 2 ESAP 2.5.3 Release Notes Antispyware Products [Lavasoft, Inc.] Ad-Aware Free Antivirus + (11.x) [Lavasoft, Inc.] Ad-Aware Personal Security (11.x) [Lavasoft, Inc.] Ad-Aware Pro Security (11.x) [Check Point, Inc] ZoneAlarm Internet Security Suite (12.x) Mac OS Antivirus Products [Doctor Web] Dr.Web for Mac (9.x) [Kaspersky Labs] Kaspersky Anti-Virus (13.x) [Kaspersky Labs] Kaspersky Anti-Virus (14.x) [McAfee, Inc.] McAfee All Access - Internet Security (3.1.x) [Symantec Corp.] Norton AntiVirus (12.x) Antispyware Products [Doctor Web] Dr.Web for Mac (9.x) [McAfee, Inc.] McAfee All Access - Internet Security (3.1.x) Firewall Products [McAfee, Inc.] McAfee All Access - Internet Security (3.1.x) Issues Fixed in ESAP2.5.3 OPSWAT issues fixed: 1.