Prediction of Possible Biomarkers and Novel Pathways Conferring Risk to Post-Traumatic Stress Disorder
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Binding Specificities of Human RNA Binding Proteins Towards Structured
bioRxiv preprint doi: https://doi.org/10.1101/317909; this version posted March 1, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. 1 Binding specificities of human RNA binding proteins towards structured and linear 2 RNA sequences 3 4 Arttu Jolma1,#, Jilin Zhang1,#, Estefania Mondragón4,#, Teemu Kivioja2, Yimeng Yin1, 5 Fangjie Zhu1, Quaid Morris5,6,7,8, Timothy R. Hughes5,6, Louis James Maher III4 and Jussi 6 Taipale1,2,3,* 7 8 9 AUTHOR AFFILIATIONS 10 11 1Department of Medical Biochemistry and Biophysics, Karolinska Institutet, Solna, Sweden 12 2Genome-Scale Biology Program, University of Helsinki, Helsinki, Finland 13 3Department of Biochemistry, University of Cambridge, Cambridge, United Kingdom 14 4Department of Biochemistry and Molecular Biology and Mayo Clinic Graduate School of 15 Biomedical Sciences, Mayo Clinic College of Medicine and Science, Rochester, USA 16 5Department of Molecular Genetics, University of Toronto, Toronto, Canada 17 6Donnelly Centre, University of Toronto, Toronto, Canada 18 7Edward S Rogers Sr Department of Electrical and Computer Engineering, University of 19 Toronto, Toronto, Canada 20 8Department of Computer Science, University of Toronto, Toronto, Canada 21 #Authors contributed equally 22 *Correspondence: [email protected] 23 24 25 SUMMARY 26 27 Sequence specific RNA-binding proteins (RBPs) control many important 28 processes affecting gene expression. They regulate RNA metabolism at multiple 29 levels, by affecting splicing of nascent transcripts, RNA folding, base modification, 30 transport, localization, translation and stability. Despite their central role in most 31 aspects of RNA metabolism and function, most RBP binding specificities remain 32 unknown or incompletely defined. -

DAZ (Z6Q): Sc-100705
SANTA CRUZ BIOTECHNOLOGY, INC. DAZ (Z6Q): sc-100705 BACKGROUND RECOMMENDED SUPPORT REAGENTS Spermatogenesis is the process by which male spermatogonia develop into To ensure optimal results, the following support reagents are recommended: mature spermatozoa. DAZ (deleted in azoospermia) are RNA-binding proteins 1) Western Blotting: use m-IgGk BP-HRP: sc-516102 or m-IgGk BP-HRP (Cruz that play an essential role in spermatogenesis. DAZ proteins influence the Marker): sc-516102-CM (dilution range: 1:1000-1:10000), Cruz Marker™ first stages of spermatogenesis and the maintenance of germ cell populations. Molecular Weight Standards: sc-2035, UltraCruz® Blocking Reagent: DAZ proteins (DAZ1, DAZ2, DAZ3, DAZ4 and DAZ5) are encoded by separate sc-516214 and Western Blotting Luminol Reagent: sc-2048. 2) Immunopre- genes on chromosome Y, each of which contain an AZFc domain in their cod- cipitation: use Protein A/G PLUS-Agarose: sc-2003 (0.5 ml agarose/2.0 ml). ing region. DAZ proteins are localized to the nucleus of spermatogonia, but 3) Immunofluorescence: use m-IgGk BP-FITC: sc-516140 or m-IgGk BP-PE: relocate to the cytoplasm during meiosis. DAZ proteins contain an RRM (RNA sc-516141 (dilution range: 1:50-1:200) with UltraCruz® Mounting Medium: recognition motif) domain that may regulate mRNA translation by binding sc-24941 or UltraCruz® Hard-set Mounting Medium: sc-359850. 4) Immuno- to the 3' UTR. Deletions in the genes encoding DAZ proteins may cause histochemistry: use m-IgGk BP-HRP: sc-516102 with DAB, 50X: sc-24982 azoospermia or oligospermia which can lead to male infertility. -

Partial Azfc Deletions and Duplications: Clinical Correlates in the Italian Population
FLORE Repository istituzionale dell'Università degli Studi di Firenze Partial AZFc deletions and duplications: clinical correlates in the Italian population. Questa è la Versione finale referata (Post print/Accepted manuscript) della seguente pubblicazione: Original Citation: Partial AZFc deletions and duplications: clinical correlates in the Italian population / Giachini C; Laface I; Guarducci E; Balercia G; Forti G; Krausz C.. - In: HUMAN GENETICS. - ISSN 0340-6717. - STAMPA. - 124(2008), pp. 399-410. Availability: This version is available at: 2158/333113 since: 2019-11-07T18:24:55Z Terms of use: Open Access La pubblicazione è resa disponibile sotto le norme e i termini della licenza di deposito, secondo quanto stabilito dalla Policy per l'accesso aperto dell'Università degli Studi di Firenze (https://www.sba.unifi.it/upload/policy-oa-2016-1.pdf) Publisher copyright claim: (Article begins on next page) 28 September 2021 Hum Genet (2008) 124:399–410 DOI 10.1007/s00439-008-0561-1 ORIGINAL INVESTIGATION Partial AZFc deletions and duplications: clinical correlates in the Italian population Claudia Giachini · Ilaria Laface · Elena Guarducci · Giancarlo Balercia · Gianni Forti · Csilla Krausz Received: 7 August 2008 / Accepted: 9 September 2008 / Published online: 21 September 2008 © Springer-Verlag 2008 Abstract The role of partial AZFc deletions of the Y potential methodological and selection biases were care- chromosome in spermatogenic impairment is currently fully avoided to detect the clinical signiWcance of partial debated. Recently, it was also reported that duplications of AZFc deletions and duplications. Our study provides strong the same region are associated with oligozoospermia in evidence that gr/gr deletion is a risk factor for impaired Han-Chinese men. -

Molecular Pathogenesis of a Malformation Syndrome Associated with a Pericentric Chromosome 2 Inversion
UNIVERSIDADE DE LISBOA FACULDADE DE CIÊNCIAS DEPARTAMENTO DE BIOLOGIA ANIMAL Molecular pathogenesis of a malformation syndrome associated with a pericentric chromosome 2 inversion Manuela Pinto Cardoso Mestrado em Biologia Humana e do Ambiente Dissertação orientada por: Doutor Dezsö David Doutora Deodália Dias 2017 ACKNOWLEDGEMENTS I would like to say “thank you!” to all the people that contributed in some way to this thesis. First and foremost, I would like to express my deepest gratitude to my supervisor, Dr. Dezsö David, for giving me the opportunity to work in his research group and for everything he taught me. Without his mentorship I would have never learned so much. I am grateful for Prof. Deodália Dias’s encouragement and support in all these years that I have been under her wings. I would like to extent my thanks to everyone at the National Health Institute Dr. Ricardo Jorge, for their continuous help in all stages of this thesis. To the team at Harvard Medical School, thank you for the technical assistance, and in special Dr. Cynthia Morton and Dr. Michael Talkowski. I am also grateful to Dr. Rui Gonçalves and Dr. João Freixo, who accompanied this case study and shared their medical knowledge. Of course, I am grateful for the family members for their involvement in this study. To my lab mates, a shout-out to them all! I really hold them dear for their help and the many laughs we shared every day. Thank you Mariana for being there literally since day one and for playing the role of a more mature counterpart. -

Development of Novel Analysis and Data Integration Systems to Understand Human Gene Regulation
Development of novel analysis and data integration systems to understand human gene regulation Dissertation zur Erlangung des Doktorgrades Dr. rer. nat. der Fakult¨atf¨urMathematik und Informatik der Georg-August-Universit¨atG¨ottingen im PhD Programme in Computer Science (PCS) der Georg-August University School of Science (GAUSS) vorgelegt von Raza-Ur Rahman aus Pakistan G¨ottingen,April 2018 Prof. Dr. Stefan Bonn, Zentrum f¨urMolekulare Neurobiologie (ZMNH), Betreuungsausschuss: Institut f¨urMedizinische Systembiologie, Hamburg Prof. Dr. Tim Beißbarth, Institut f¨urMedizinische Statistik, Universit¨atsmedizin, Georg-August Universit¨at,G¨ottingen Prof. Dr. Burkhard Morgenstern, Institut f¨urMikrobiologie und Genetik Abtl. Bioinformatik, Georg-August Universit¨at,G¨ottingen Pr¨ufungskommission: Prof. Dr. Stefan Bonn, Zentrum f¨urMolekulare Neurobiologie (ZMNH), Referent: Institut f¨urMedizinische Systembiologie, Hamburg Prof. Dr. Tim Beißbarth, Institut f¨urMedizinische Statistik, Universit¨atsmedizin, Korreferent: Georg-August Universit¨at,G¨ottingen Prof. Dr. Burkhard Morgenstern, Weitere Mitglieder Institut f¨urMikrobiologie und Genetik Abtl. Bioinformatik, der Pr¨ufungskommission: Georg-August Universit¨at,G¨ottingen Prof. Dr. Carsten Damm, Institut f¨urInformatik, Georg-August Universit¨at,G¨ottingen Prof. Dr. Florentin W¨org¨otter, Physikalisches Institut Biophysik, Georg-August-Universit¨at,G¨ottingen Prof. Dr. Stephan Waack, Institut f¨urInformatik, Georg-August Universit¨at,G¨ottingen Tag der m¨undlichen Pr¨ufung: der 30. M¨arz2018 -

Hypomethylation of the DAZ3 Promoter in Idiopathic Asthenospermia: a Screening Tool for Liquid Biopsy Shichang Zhang1,3, Li Xu2,3, Mengyao Yu1 & Jiexin Zhang1*
www.nature.com/scientificreports OPEN Hypomethylation of the DAZ3 promoter in idiopathic asthenospermia: a screening tool for liquid biopsy Shichang Zhang1,3, Li Xu2,3, Mengyao Yu1 & Jiexin Zhang1* Given the role of the deleted in azoospermia gene in male infertility, whether the somatic deleted in azoospermia methylation status is associated with idiopathic asthenospermia should be determined. To investigate the methylation levels of the deleted in azoospermia promoter in peripheral white blood cells from idiopathic asthenospermia patients relative to those in normozoospermia controls, 61 ethylene diamine tetraacetic acid anticoagulant blood samples were drawn from all participants for DNA isolation. The deleted in azoospermia promoter methylation ratio was detected by MassARRAY-based methylation quantifcation and confrmed by quantitative methylation-specifc polymerase chain reaction. A MassARRAY-based methylation analysis showed that the deleted in azoospermia 3 promoter (0 to − 2 kbp) was signifcantly hypomethylated in peripheral white blood cells from idiopathic asthenospermia males, specifcally one CpG site (− 246 to − 247). Quantitative methylation-specifc polymerase chain reaction data further confrmed that the methylation level of the deleted in azoospermia 3 promoter region in idiopathic asthenospermia patients was signifcantly lower than that in normozoospermia males. The area under the receiver operating characteristic curve determined by quantitative methylation-specifc polymerase chain reaction was 0.737 (95% confdence interval: 0.552 to 0.924), with a sensitivity of 53.9% and a specifcity of 88.2% at a cut- of level of 74.7%. Therefore, our results suggested that methylation ratio detection of the deleted in azoospermia 3 promoter region by real-time polymerase chain reaction assay is a promising and feasible tool for liquid biopsy in the clinical laboratories. -

Rabbit Anti-DAZ4/FITC Conjugated Antibody
SunLong Biotech Co.,LTD Tel: 0086-571- 56623320 Fax:0086-571- 56623318 E-mail:[email protected] www.sunlongbiotech.com Rabbit Anti-DAZ4/FITC Conjugated antibody SL13609R-FITC Product Name: Anti-DAZ4/FITC Chinese Name: FITC标记的无精症缺失基因4抗体 Alias: DAZ4; Deleted in azoospermia 4; Deleted in azoospermia protein 4; DAZ4_HUMAN. Organism Species: Rabbit Clonality: Polyclonal React Species: Human,Mouse,Rat,Dog,Pig,Cow,Horse,Sheep, ICC=1:50-200IF=1:50-200 Applications: not yet tested in other applications. optimal dilutions/concentrations should be determined by the end user. Molecular weight: 65kDa Form: Lyophilized or Liquid Concentration: 1mg/ml immunogen: KLH conjugated synthetic peptide derived from human DAZ4 Lsotype: IgG Purification: affinity purified by Protein A Storage Buffer: 0.01M TBS(pH7.4) with 1% BSA, 0.03% Proclin300 and 50% Glycerol. Store at -20 °C for one year. Avoid repeated freeze/thaw cycles. The lyophilized antibodywww.sunlongbiotech.com is stable at room temperature for at least one month and for greater than a year Storage: when kept at -20°C. When reconstituted in sterile pH 7.4 0.01M PBS or diluent of antibody the antibody is stable for at least two weeks at 2-4 °C. background: Spermatogenesis is the process by which male spermatogonia develop into mature spermatozoa. DAZ (deleted in azoospermia) are RNA-binding proteins that play an essential role in spermatogenesis. DAZ proteins influence the first stages of spermatogenesis and the maintenance of germ cell populations. DAZ proteins (DAZ1, Product Detail: DAZ2, DAZ3, DAZ4 and DAZ5) are encoded by separate genes on chromosome Y, each of which contain an AZFc domain in their coding region. -

TREE1-EIN3–Mediated Transcriptional Repression Inhibits Shoot Growth in Response to Ethylene
TREE1-EIN3–mediated transcriptional repression inhibits shoot growth in response to ethylene Likai Wanga,b, Eun Esther Koa, Jaclyn Trana, and Hong Qiaoa,b,1 aInstitute for Cellular and Molecular Biology, The University of Texas at Austin, Austin, TX 78712; and bDepartment of Molecular Biosciences, The University of Texas at Austin, Austin, TX 78712 Edited by Mark Estelle, University of California San Diego, La Jolla, CA, and approved October 5, 2020 (received for review September 8, 2020) Ethylene is an important plant hormone that regulates plant ethylene response. Whereas the time course transcriptome anal- growth, in which the master transcriptionactivator EIN3 (Ethylene ysis in response to ethylene revealed that most of the genes are Insensitive 3)-mediated transcriptional activation plays vital roles. repressed by ethylene in the early stage (before 1 h) of the eth- However, the EIN3-mediated transcriptional repression in ethylene ylene response, about 50% of ethylene-altered genes are re- response is unknown. We report here that a Transcriptional Re- pressed in the later stage (after 1 h) of ethylene response (18, 21). pressor of EIN3-dependent Ethylene-response 1 (TREE1) interacts More interestingly, parts of the ethylene-repressed genes are the with EIN3 to regulate transcriptional repression that leads to an binding targets of EIN3, the transcription activator (21), sug- inhibition of shoot growth in response to ethylene. Tissue-specific gesting that EIN3 is potentially involved in the transcriptional transcriptome analysis showed that most of the genes are down- repression. However, little research has been focused on the regulated by ethylene in shoots, and a DNA binding motif was EIN3-mediated transcriptional repression in the ethylene re- identified that is important for this transcriptional repression. -

The Tip of the Iceberg: RNA-Binding Proteins with Prion-Like Domains in Neurodegenerative Disease
BRES-42024; No. of pages: 20; 4C: 7, 8, 10, 12, 13 BRAIN RESEARCH XX (2012) XXX– XXX Available online at www.sciencedirect.com www.elsevier.com/locate/brainres Review The tip of the iceberg: RNA-binding proteins with prion-like domains in neurodegenerative disease Oliver D. Kinga,⁎, Aaron D. Gitlerb,⁎⁎, James Shorterc,⁎⁎⁎ aBoston Biomedical Research Institute, 64 Grove St., Watertown, MA 02472, USA bDepartment of Genetics, Stanford University School of Medicine, 300 Pasteur Drive, M322 Alway Building, Stanford, CA 94305-5120, USA cDepartment of Biochemistry and Biophysics, University of Pennsylvania School of Medicine, 805b Stellar-Chance Laboratories, 422 Curie Boulevard, Philadelphia, PA 19104, USA ARTICLE INFO ABSTRACT Article history: Prions are self-templating protein conformers that are naturally transmitted between individ- Accepted 7 January 2012 uals and promote phenotypic change. In yeast, prion-encoded phenotypes can be beneficial, neutral or deleterious depending upon genetic background and environmental conditions. A dis- Keywords: tinctive and portable ‘prion domain’ enriched in asparagine, glutamine, tyrosine and glycine res- Prion idues unifies the majority of yeast prion proteins. Deletion of this domain precludes RNA-binding protein prionogenesis and appending this domain to reporter proteins can confer prionogenicity. An al- TDP-43 gorithm designed to detect prion domains has successfully identified 19 domains that can confer FUS prion behavior. Scouring the human genome with this algorithm enriches a select group of RNA- TAF15 binding proteins harboring a canonical RNA recognition motif (RRM) and a putative prion do- EWSR1 main. Indeed, of 210 human RRM-bearing proteins, 29 have a putative prion domain, and 12 of Amyotrophic lateral sclerosis these are in the top 60 prion candidates in the entire genome. -

Sequence, Structure and Context Preferences of Human RNA
bioRxiv preprint doi: https://doi.org/10.1101/201996; this version posted October 12, 2017. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. Sequence, Structure and Context Preferences of Human RNA Binding Proteins Daniel Dominguez§,1, Peter Freese§,2, Maria Alexis§,2, Amanda Su1, Myles Hochman1, Tsultrim Palden1, Cassandra Bazile1, Nicole J Lambert1, Eric L Van Nostrand3,4, Gabriel A. Pratt3,4,5, Gene W. Yeo3,4,6,7, Brenton R. Graveley8, Christopher B. Burge1,9,* 1. Department of Biology, MIT, Cambridge MA 2. Program in Computational and Systems Biology, MIT, Cambridge MA 3. Department of Cellular and Molecular Medicine, University of California at San Diego, La Jolla, CA 4. Institute for Genomic Medicine, University of California at San Diego, La Jolla, CA 5. Bioinformatics and Systems Biology Graduate Program, University of California San Diego, La Jolla, CA 6. Department of Physiology, Yong Loo Lin School of Medicine, National University of Singapore, Singapore 7. Molecular Engineering Laboratory. A*STAR, Singapore 8. Department of Genetics and Genome Sciences, Institute for Systems Genomics, Univ. Connecticut Health, Farmington, CT 9. Department of Biological Engineering, MIT, Cambridge MA * Address correspondence to: [email protected] 1 of 61 bioRxiv preprint doi: https://doi.org/10.1101/201996; this version posted October 12, 2017. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. -

Prevalent RNA Recognition Motif Duplication in the Human Genome
Downloaded from rnajournal.cshlp.org on October 1, 2021 - Published by Cold Spring Harbor Laboratory Press Prevalent RNA recognition motif duplication in the human genome YIHSUAN S. TSAI,1 SHAWN M. GOMEZ,1,2,3,4 and ZEFENG WANG1,2,5 1Curriculum in Bioinformatics and Computational Biology, 2Department of Pharmacology, 3Department of Computer Science, 4Department of Biomedical Engineering, University of North Carolina at Chapel Hill, Chapel Hill, North Carolina 27599, USA ABSTRACT The sequence-specific recognition of RNA by proteins is mediated through various RNA binding domains, with the RNA recognition motif (RRM) being the most frequent and present in >50% of RNA-binding proteins (RBPs). Many RBPs contain multiple RRMs, and it is unclear how each RRM contributes to the binding specificity of the entire protein. We found that RRMs within the same RBP (i.e., sibling RRMs) tend to have significantly higher similarity than expected by chance. Sibling RRM pairs from RBPs shared by multiple species tend to have lower similarity than those found only in a single species, suggesting that multiple RRMs within the same protein might arise from domain duplication followed by divergence through random mutations. This finding is exemplified by a recent RRM domain duplication in DAZ proteins and an ancient duplication in PABP proteins. Additionally, we found that different similarities between sibling RRMs are associated with distinct functions of an RBP and that the RBPs tend to contain repetitive sequences with low complexity. Taken together, this study suggests that the number of RBPs with multiple RRMs has expanded in mammals and that the multiple sibling RRMs may recognize similar target motifs in a cooperative manner. -
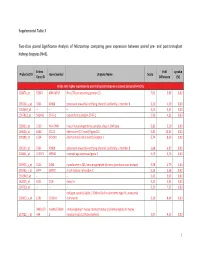
Supplemental Table 3 Two-Class Paired Significance Analysis of Microarrays Comparing Gene Expression Between Paired
Supplemental Table 3 Two‐class paired Significance Analysis of Microarrays comparing gene expression between paired pre‐ and post‐transplant kidneys biopsies (N=8). Entrez Fold q‐value Probe Set ID Gene Symbol Unigene Name Score Gene ID Difference (%) Probe sets higher expressed in post‐transplant biopsies in paired analysis (N=1871) 218870_at 55843 ARHGAP15 Rho GTPase activating protein 15 7,01 3,99 0,00 205304_s_at 3764 KCNJ8 potassium inwardly‐rectifying channel, subfamily J, member 8 6,30 4,50 0,00 1563649_at ‐‐ ‐‐ ‐‐ 6,24 3,51 0,00 1567913_at 541466 CT45‐1 cancer/testis antigen CT45‐1 5,90 4,21 0,00 203932_at 3109 HLA‐DMB major histocompatibility complex, class II, DM beta 5,83 3,20 0,00 204606_at 6366 CCL21 chemokine (C‐C motif) ligand 21 5,82 10,42 0,00 205898_at 1524 CX3CR1 chemokine (C‐X3‐C motif) receptor 1 5,74 8,50 0,00 205303_at 3764 KCNJ8 potassium inwardly‐rectifying channel, subfamily J, member 8 5,68 6,87 0,00 226841_at 219972 MPEG1 macrophage expressed gene 1 5,59 3,76 0,00 203923_s_at 1536 CYBB cytochrome b‐245, beta polypeptide (chronic granulomatous disease) 5,58 4,70 0,00 210135_s_at 6474 SHOX2 short stature homeobox 2 5,53 5,58 0,00 1562642_at ‐‐ ‐‐ ‐‐ 5,42 5,03 0,00 242605_at 1634 DCN decorin 5,23 3,92 0,00 228750_at ‐‐ ‐‐ ‐‐ 5,21 7,22 0,00 collagen, type III, alpha 1 (Ehlers‐Danlos syndrome type IV, autosomal 201852_x_at 1281 COL3A1 dominant) 5,10 8,46 0,00 3493///3 IGHA1///IGHA immunoglobulin heavy constant alpha 1///immunoglobulin heavy 217022_s_at 494 2 constant alpha 2 (A2m marker) 5,07 9,53 0,00 1 202311_s_at