Cataloguing Over-Expressed Genes in Epstein Barr Virus Immortalized Lymphoblastoid Cell Lines Through Consensus Analysis of Pacb
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
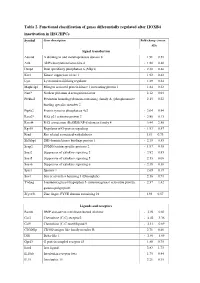
Table 2. Functional Classification of Genes Differentially Regulated After HOXB4 Inactivation in HSC/Hpcs
Table 2. Functional classification of genes differentially regulated after HOXB4 inactivation in HSC/HPCs Symbol Gene description Fold-change (mean ± SD) Signal transduction Adam8 A disintegrin and metalloprotease domain 8 1.91 ± 0.51 Arl4 ADP-ribosylation factor-like 4 - 1.80 ± 0.40 Dusp6 Dual specificity phosphatase 6 (Mkp3) - 2.30 ± 0.46 Ksr1 Kinase suppressor of ras 1 1.92 ± 0.42 Lyst Lysosomal trafficking regulator 1.89 ± 0.34 Mapk1ip1 Mitogen activated protein kinase 1 interacting protein 1 1.84 ± 0.22 Narf* Nuclear prelamin A recognition factor 2.12 ± 0.04 Plekha2 Pleckstrin homology domain-containing. family A. (phosphoinosite 2.15 ± 0.22 binding specific) member 2 Ptp4a2 Protein tyrosine phosphatase 4a2 - 2.04 ± 0.94 Rasa2* RAS p21 activator protein 2 - 2.80 ± 0.13 Rassf4 RAS association (RalGDS/AF-6) domain family 4 3.44 ± 2.56 Rgs18 Regulator of G-protein signaling - 1.93 ± 0.57 Rrad Ras-related associated with diabetes 1.81 ± 0.73 Sh3kbp1 SH3 domain kinase bindings protein 1 - 2.19 ± 0.53 Senp2 SUMO/sentrin specific protease 2 - 1.97 ± 0.49 Socs2 Suppressor of cytokine signaling 2 - 2.82 ± 0.85 Socs5 Suppressor of cytokine signaling 5 2.13 ± 0.08 Socs6 Suppressor of cytokine signaling 6 - 2.18 ± 0.38 Spry1 Sprouty 1 - 2.69 ± 0.19 Sos1 Son of sevenless homolog 1 (Drosophila) 2.16 ± 0.71 Ywhag 3-monooxygenase/tryptophan 5- monooxygenase activation protein. - 2.37 ± 1.42 gamma polypeptide Zfyve21 Zinc finger. FYVE domain containing 21 1.93 ± 0.57 Ligands and receptors Bambi BMP and activin membrane-bound inhibitor - 2.94 ± 0.62 -
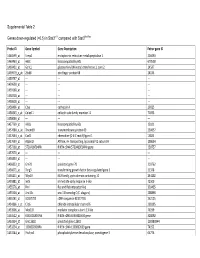
0.5) in Stat3∆/∆ Compared with Stat3flox/Flox
Supplemental Table 2 Genes down-regulated (<0.5) in Stat3∆/∆ compared with Stat3flox/flox Probe ID Gene Symbol Gene Description Entrez gene ID 1460599_at Ermp1 endoplasmic reticulum metallopeptidase 1 226090 1460463_at H60c histocompatibility 60c 670558 1460431_at Gcnt1 glucosaminyl (N-acetyl) transferase 1, core 2 14537 1459979_x_at Zfp68 zinc finger protein 68 24135 1459747_at --- --- --- 1459608_at --- --- --- 1459168_at --- --- --- 1458718_at --- --- --- 1458618_at --- --- --- 1458466_at Ctsa cathepsin A 19025 1458345_s_at Colec11 collectin sub-family member 11 71693 1458046_at --- --- --- 1457769_at H60a histocompatibility 60a 15101 1457680_a_at Tmem69 transmembrane protein 69 230657 1457644_s_at Cxcl1 chemokine (C-X-C motif) ligand 1 14825 1457639_at Atp6v1h ATPase, H+ transporting, lysosomal V1 subunit H 108664 1457260_at 5730409E04Rik RIKEN cDNA 5730409E04Rik gene 230757 1457070_at --- --- --- 1456893_at --- --- --- 1456823_at Gm70 predicted gene 70 210762 1456671_at Tbrg3 transforming growth factor beta regulated gene 3 21378 1456211_at Nlrp10 NLR family, pyrin domain containing 10 244202 1455881_at Ier5l immediate early response 5-like 72500 1455576_at Rinl Ras and Rab interactor-like 320435 1455304_at Unc13c unc-13 homolog C (C. elegans) 208898 1455241_at BC037703 cDNA sequence BC037703 242125 1454866_s_at Clic6 chloride intracellular channel 6 209195 1453906_at Med13l mediator complex subunit 13-like 76199 1453522_at 6530401N04Rik RIKEN cDNA 6530401N04 gene 328092 1453354_at Gm11602 predicted gene 11602 100380944 1453234_at -

4-6 Weeks Old Female C57BL/6 Mice Obtained from Jackson Labs Were Used for Cell Isolation
Methods Mice: 4-6 weeks old female C57BL/6 mice obtained from Jackson labs were used for cell isolation. Female Foxp3-IRES-GFP reporter mice (1), backcrossed to B6/C57 background for 10 generations, were used for the isolation of naïve CD4 and naïve CD8 cells for the RNAseq experiments. The mice were housed in pathogen-free animal facility in the La Jolla Institute for Allergy and Immunology and were used according to protocols approved by the Institutional Animal Care and use Committee. Preparation of cells: Subsets of thymocytes were isolated by cell sorting as previously described (2), after cell surface staining using CD4 (GK1.5), CD8 (53-6.7), CD3ε (145- 2C11), CD24 (M1/69) (all from Biolegend). DP cells: CD4+CD8 int/hi; CD4 SP cells: CD4CD3 hi, CD24 int/lo; CD8 SP cells: CD8 int/hi CD4 CD3 hi, CD24 int/lo (Fig S2). Peripheral subsets were isolated after pooling spleen and lymph nodes. T cells were enriched by negative isolation using Dynabeads (Dynabeads untouched mouse T cells, 11413D, Invitrogen). After surface staining for CD4 (GK1.5), CD8 (53-6.7), CD62L (MEL-14), CD25 (PC61) and CD44 (IM7), naïve CD4+CD62L hiCD25-CD44lo and naïve CD8+CD62L hiCD25-CD44lo were obtained by sorting (BD FACS Aria). Additionally, for the RNAseq experiments, CD4 and CD8 naïve cells were isolated by sorting T cells from the Foxp3- IRES-GFP mice: CD4+CD62LhiCD25–CD44lo GFP(FOXP3)– and CD8+CD62LhiCD25– CD44lo GFP(FOXP3)– (antibodies were from Biolegend). In some cases, naïve CD4 cells were cultured in vitro under Th1 or Th2 polarizing conditions (3, 4). -

The Genomic Organization and Expression Pattern of the Low-Affinity Fc Gamma Receptors (Fcγr) in the Göttingen Minipig
Immunogenetics (2019) 71:123–136 https://doi.org/10.1007/s00251-018-01099-1 ORIGINAL ARTICLE The genomic organization and expression pattern of the low-affinity Fc gamma receptors (FcγR) in the Göttingen minipig Jerome Egli1 & Roland Schmucki1 & Benjamin Loos1 & Stephan Reichl1 & Nils Grabole1 & Andreas Roller1 & Martin Ebeling1 & Alex Odermatt2 & Antonio Iglesias1 Received: 9 August 2018 /Accepted: 24 November 2018 /Published online: 18 December 2018 # The Author(s) 2018 Abstract Safety and efficacy of therapeutic antibodies are often dependent on their interaction with Fc receptors for IgG (FcγRs). The Göttingen minipig represents a valuable species for biomedical research but its use in preclinical studies with therapeutic antibodies is hampered by the lack of knowledge about the porcine FcγRs. Genome analysis and sequencing now enabled the localization of the previously described FcγRIIIa in the orthologous location to human FCGR3A. In addition, we identified nearby the gene coding for the hitherto undescribed putative porcine FcγRIIa. The 1′241 bp long FCGR2A cDNA translates to a 274aa transmembrane protein containing an extracellular region with high similarity to human and cattle FcγRIIa. Like in cattle, the intracellular part does not contain an immunoreceptor tyrosine-based activation motif (ITAM) as in human FcγRIIa. Flow cytometry of the whole blood and single-cell RNA sequencing of peripheral blood mononuclear cells (PBMCs) of Göttingen minipigs revealed the expression profile of all porcine FcγRs which is compared to human and mouse. The new FcγRIIa is mainly expressed on platelets making the minipig a good model to study IgG-mediated platelet activation and aggregation. In contrast to humans, minipig blood monocytes were found to express inhibitory FcγRIIb that could lead to the underestimation of FcγR-mediated effects of monocytes observed in minipig studies with therapeutic antibodies. -

Genetic and Genomic Analysis of Hyperlipidemia, Obesity and Diabetes Using (C57BL/6J × TALLYHO/Jngj) F2 Mice
University of Tennessee, Knoxville TRACE: Tennessee Research and Creative Exchange Nutrition Publications and Other Works Nutrition 12-19-2010 Genetic and genomic analysis of hyperlipidemia, obesity and diabetes using (C57BL/6J × TALLYHO/JngJ) F2 mice Taryn P. Stewart Marshall University Hyoung Y. Kim University of Tennessee - Knoxville, [email protected] Arnold M. Saxton University of Tennessee - Knoxville, [email protected] Jung H. Kim Marshall University Follow this and additional works at: https://trace.tennessee.edu/utk_nutrpubs Part of the Animal Sciences Commons, and the Nutrition Commons Recommended Citation BMC Genomics 2010, 11:713 doi:10.1186/1471-2164-11-713 This Article is brought to you for free and open access by the Nutrition at TRACE: Tennessee Research and Creative Exchange. It has been accepted for inclusion in Nutrition Publications and Other Works by an authorized administrator of TRACE: Tennessee Research and Creative Exchange. For more information, please contact [email protected]. Stewart et al. BMC Genomics 2010, 11:713 http://www.biomedcentral.com/1471-2164/11/713 RESEARCH ARTICLE Open Access Genetic and genomic analysis of hyperlipidemia, obesity and diabetes using (C57BL/6J × TALLYHO/JngJ) F2 mice Taryn P Stewart1, Hyoung Yon Kim2, Arnold M Saxton3, Jung Han Kim1* Abstract Background: Type 2 diabetes (T2D) is the most common form of diabetes in humans and is closely associated with dyslipidemia and obesity that magnifies the mortality and morbidity related to T2D. The genetic contribution to human T2D and related metabolic disorders is evident, and mostly follows polygenic inheritance. The TALLYHO/ JngJ (TH) mice are a polygenic model for T2D characterized by obesity, hyperinsulinemia, impaired glucose uptake and tolerance, hyperlipidemia, and hyperglycemia. -

Downloaded from USCS Tables (
bioRxiv preprint doi: https://doi.org/10.1101/318329; this version posted February 4, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. The selection arena in early human blastocysts resolves the pluripotent inner cell mass Manvendra Singh1, Thomas J. Widmann2, Vikas Bansal7, Jose L. Cortes2, Gerald G. Schumann3, Stephanie Wunderlich4, Ulrich Martin4, Marta Garcia-Canadas2, Jose L. Garcia- Perez2,5*, Laurence D. Hurst6*#, Zsuzsanna Izsvák1* 1 Max-Delbrück-Center for Molecular Medicine in the Helmholtz Society, Robert-Rössle- Strasse 10, 13125 Berlin, Germany. 2 GENYO. Centre for Genomics and Oncological Research: Pfizer/University of Granada/Andalusian Regional Government, PTS Granada, 18016 Granada, Spain. 3 Paul-Ehrlich-Institute, Division of Medical Biotechnology, Paul-Ehrlich-Strasse 51-59, 63225 Langen, Germany. 4Center for Regenerative Medicine Hannover Medical School (MHH) Carl-Neuberg-Str.1, Building J11, D-30625 Hannover, Germany 5Institute of Genetics and Molecular Medicine (IGMM), University of Edinburgh, Crewe Road, Edinburgh EH4 2XU, United Kingdom 6 The Milner Centre for Evolution, Department of Biology and Biochemistry, University of Bath, Bath, Somerset, UK, BA2 7AY. 7 Institute of Medical Systems Biology, Center for Molecular Neurobiology (ZMNH), University Medical Center Hamburg-Eppendorf (UKE), 20246, Hamburg, Germany. *Corresponding authors *Zsuzsanna Izsvák Max Delbrück Center for Molecular Medicine Robert Rössle Strasse 10, 13092 Berlin, Germany Telefon: +49 030-9406-3510 Fax: +49 030-9406-2547 email: [email protected] http://www.mdcberlin.de/en/research/research_teams/mobile_dna/index.html and *Laurence D. -

UNIVERSITY of CALIFORNIA RIVERSIDE Investigations Into The
UNIVERSITY OF CALIFORNIA RIVERSIDE Investigations into the Role of TAF1-mediated Phosphorylation in Gene Regulation A Dissertation submitted in partial satisfaction of the requirements for the degree of Doctor of Philosophy in Cell, Molecular and Developmental Biology by Brian James Gadd December 2012 Dissertation Committee: Dr. Xuan Liu, Chairperson Dr. Frank Sauer Dr. Frances M. Sladek Copyright by Brian James Gadd 2012 The Dissertation of Brian James Gadd is approved Committee Chairperson University of California, Riverside Acknowledgments I am thankful to Dr. Liu for her patience and support over the last eight years. I am deeply indebted to my committee members, Dr. Frank Sauer and Dr. Frances Sladek for the insightful comments on my research and this dissertation. Thanks goes out to CMDB, especially Dr. Bachant, Dr. Springer and Kathy Redd for their support. Thanks to all the members of the Liu lab both past and present. A very special thanks to the members of the Sauer lab, including Silvia, Stephane, David, Matt, Stephen, Ninuo, Toby, Josh, Alice, Alex and Flora. You have made all the years here fly by and made them so enjoyable. From the Sladek lab I want to thank Eugene, John, Linh and Karthi. Special thanks go out to all the friends I’ve made over the years here. Chris, Amber, Stephane and David, thank you so much for feeding me, encouraging me and keeping me sane. Thanks to the brothers for all your encouragement and prayers. To any I haven’t mentioned by name, I promise I haven’t forgotten all you’ve done for me during my graduate years. -

Mouse Fcrla Conditional Knockout Project (CRISPR/Cas9)
https://www.alphaknockout.com Mouse Fcrla Conditional Knockout Project (CRISPR/Cas9) Objective: To create a Fcrla conditional knockout Mouse model (C57BL/6J) by CRISPR/Cas-mediated genome engineering. Strategy summary: The Fcrla gene (NCBI Reference Sequence: NM_001160215 ; Ensembl: ENSMUSG00000038421 ) is located on Mouse chromosome 1. 5 exons are identified, with the ATG start codon in exon 1 and the TGA stop codon in exon 5 (Transcript: ENSMUST00000046322). Exon 2~4 will be selected as conditional knockout region (cKO region). Deletion of this region should result in the loss of function of the Mouse Fcrla gene. To engineer the targeting vector, homologous arms and cKO region will be generated by PCR using BAC clone RP23-100H5 as template. Cas9, gRNA and targeting vector will be co-injected into fertilized eggs for cKO Mouse production. The pups will be genotyped by PCR followed by sequencing analysis. Note: Mice homozygous for a targeted allele exhibit largely normal T-dependent and T-independent antibody responses with an increase in IgG1 after secondary challenge with sheep red blood cells. Exon 2~4 is not frameshift exon, and covers 69.69% of the coding region. The size of intron 1 for 5'-loxP site insertion: 5054 bp, and the size of intron 4 for 3'-loxP site insertion: 2439 bp. The size of effective cKO region: ~2074 bp. The cKO region does not have any other known gene. Page 1 of 8 https://www.alphaknockout.com Overview of the Targeting Strategy Wildtype allele 5' gRNA region gRNA region 3' 1 2 3 4 5 Targeting vector Targeted allele Constitutive KO allele (After Cre recombination) Legends Exon of mouse Fcrla Homology arm cKO region loxP site Page 2 of 8 https://www.alphaknockout.com Overview of the Dot Plot Window size: 10 bp Forward Reverse Complement Sequence 12 Note: The sequence of homologous arms and cKO region is aligned with itself to determine if there are tandem repeats. -

Alternate-Locus Aware Variant Calling in Whole Genome Sequencing Marten Jäger1,2, Max Schubach1, Tomasz Zemojtel1,Knutreinert3, Deanna M
Jäger et al. Genome Medicine (2016) 8:130 DOI 10.1186/s13073-016-0383-z RESEARCH Open Access Alternate-locus aware variant calling in whole genome sequencing Marten Jäger1,2, Max Schubach1, Tomasz Zemojtel1,KnutReinert3, Deanna M. Church4 and Peter N. Robinson1,2,3,5,6* Abstract Background: The last two human genome assemblies have extended the previous linear golden-path paradigm of the human genome to a graph-like model to better represent regions with a high degree of structural variability. The new model offers opportunities to improve the technical validity of variant calling in whole-genome sequencing (WGS). Methods: We developed an algorithm that analyzes the patterns of variant calls in the 178 structurally variable regions of the GRCh38 genome assembly, and infers whether a given sample is most likely to contain sequences from the primary assembly, an alternate locus, or their heterozygous combination at each of these 178 regions. We investigate 121 in-house WGS datasets that have been aligned to the GRCh37 and GRCh38 assemblies. Results: We show that stretches of sequences that are largely but not entirely identical between the primary assembly and an alternate locus can result in multiple variant calls against regions of the primary assembly. In WGS analysis, this results in characteristic and recognizable patterns of variant calls at positions that we term alignable scaffold-discrepant positions (ASDPs). In 121 in-house genomes, on average 51.8 ± 3.8 of the 178 regions were found to correspond best to an alternate locus rather than the primary assembly sequence, and filtering these genomes with our algorithm led to the identification of 7863 variant calls per genome that colocalized with ASDPs. -

PRODUCT SPECIFICATION Prest Antigen TEX9
PrEST Antigen TEX9 Product Datasheet PrEST Antigen PRODUCT SPECIFICATION Product Name PrEST Antigen TEX9 Product Number APrEST81497 Gene Description testis expressed 9 Corresponding Anti-TEX9 (HPA039415) Antibodies Description Recombinant protein fragment of Human TEX9 Amino Acid Sequence Recombinant Protein Epitope Signature Tag (PrEST) antigen sequence: QEELDNVVCECNKKEDEIQNLKSQVKNFEEDFMRQQRTINMQQSQVEKYK TLFEEANKKYDGLQQQLSSVERELENKRRLQKQAASSQSAT Fusion Tag N-terminal His6ABP (ABP = Albumin Binding Protein derived from Streptococcal Protein G) Expression Host E. coli Purification IMAC purification Predicted MW 28 kDa including tags Usage Suitable as control in WB and preadsorption assays using indicated corresponding antibodies. Purity >80% by SDS-PAGE and Coomassie blue staining Buffer PBS and 1M Urea, pH 7.4. Unit Size 100 µl Concentration Lot dependent Storage Upon delivery store at -20°C. Avoid repeated freeze/thaw cycles. Notes Gently mix before use. Optimal concentrations and conditions for each application should be determined by the user. Product of Sweden. For research use only. Not intended for pharmaceutical development, diagnostic, therapeutic or any in vivo use. No products from Atlas Antibodies may be resold, modified for resale or used to manufacture commercial products without prior written approval from Atlas Antibodies AB. Warranty: The products supplied by Atlas Antibodies are warranted to meet stated product specifications and to conform to label descriptions when used and stored properly. Unless otherwise stated, this warranty is limited to one year from date of sales for products used, handled and stored according to Atlas Antibodies AB's instructions. Atlas Antibodies AB's sole liability is limited to replacement of the product or refund of the purchase price. All products are supplied for research use only. -

Genomic Organization of Mouse Fcy Receptor Genes
Proc. Nail. Acad. Sci. USA Vol. 87, pp. 2856-2860, April 1990 Immunology Genomic organization of mouse Fcy receptor genes (Fc receptors/exon-ntron junctions/protein domains/immunoglobulin gene superfamily) ANTHONY KULCZYCKI, JR.*t, JENNIFER WEBBER*, HAUNANI A. SOARES*, MICHAEL D. ONKEN*, JAMES A. THOMPSON*, DAVID D. CHAPLIN*t, DENNIS Y. LOH*t, AND JEFFREY P. TILLINGHAST* *Department of Medicine and tHoward Hughes Medical Institute, Washington University School of Medicine, Saint Louis, MO 63110 Communicated by David M. Kipnis, January 16, 1990 ABSTRACT We have isolated and characterized the gene responsible for intrathymic deletion of a large fraction of coding for the mouse Fc receptor that is termed Fc,,RHa. The potentially self-reactive T-cell clones (11-13). gene contains five exons and spans approximately 9 kilobases. An understanding of the relationship of the various Fc Unlike most members of the immunoglobulin gene superfam- receptor genes to each other, the factors influencing their ily, this gene utilizes multiple exons to encode its leader peptide. evolution, and molecular mechanisms regulating their The first exon encodes the hydrophobic region of the signal expression requires a detailed analysis of the structures of sequence; the second exon, which contains only 21 base pairs, their genes. Here we report the characterization of two encodes a segment of the signal peptidase recognition site; and members of this gene family. the beginning of the third exon encodes the predicted site of peptidase cleavage. The third and fourth exons each code for immunoglobulin-like extracellular domains. The fifth exon MATERIALS AND METHODS encodes the hydrophobic transmembrane domain and the Screening of Mouse cDNA and Genomic Libraries. -

Genome-Wide Detection of Natural Selection in African Americans Pre- and Post-Admixture
Downloaded from genome.cshlp.org on September 29, 2021 - Published by Cold Spring Harbor Laboratory Press Method Genome-wide detection of natural selection in African Americans pre- and post-admixture Wenfei Jin,1 Shuhua Xu,1,6 Haifeng Wang,2 Yongguo Yu,3 Yiping Shen,4,5 Bailin Wu,4,5 and Li Jin1,4,6 1Chinese Academy of Sciences Key Laboratory of Computational Biology, Chinese Academy of Sciences and Max Planck Society (CAS-MPG) Partner Institute for Computational Biology, Shanghai Institutes for Biological Sciences, Chinese Academy of Sciences, Shanghai 200031, China; 2Chinese National Human Genome Center, Shanghai 201203, China; 3Shanghai Children’s Medical Center, Shanghai Jiaotong University School of Medicine, Shanghai 200127, China; 4Ministry of Education (MOE) Key Laboratory of Contemporary Anthropology, School of Life Sciences and Institutes of Biomedical Sciences, Fudan University, Shanghai 200433, China; 5Children’s Hospital Boston, Harvard Medical School, Boston, Massachusetts 02115, USA It is particularly meaningful to investigate natural selection in African Americans (AfA) due to the high mortality their African ancestry has experienced in history. In this study, we examined 491,526 autosomal single nucleotide poly- morphisms (SNPs) genotyped in 5210 individuals and conducted a genome-wide search for selection signals in 1890 AfA. Several genomic regions showing an excess of African or European ancestry, which were considered the footprints of selection since population admixture, were detected based on a commonly used approach. However, we also developed a new strategy to detect natural selection both pre- and post-admixture by reconstructing an ancestral African population (AAF) from inferred African components of ancestry in AfA and comparing it with indigenous African populations (IAF).