Insights Into the Teaching of Gradient from an Exploratory Study of Mathematics Textbooks from Germany, Singapore, and South Korea
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Matrix Calculus You Need for Deep Learning
The Matrix Calculus You Need For Deep Learning Terence Parr and Jeremy Howard July 3, 2018 (We teach in University of San Francisco's MS in Data Science program and have other nefarious projects underway. You might know Terence as the creator of the ANTLR parser generator. For more material, see Jeremy's fast.ai courses and University of San Francisco's Data Institute in- person version of the deep learning course.) HTML version (The PDF and HTML were generated from markup using bookish) Abstract This paper is an attempt to explain all the matrix calculus you need in order to understand the training of deep neural networks. We assume no math knowledge beyond what you learned in calculus 1, and provide links to help you refresh the necessary math where needed. Note that you do not need to understand this material before you start learning to train and use deep learning in practice; rather, this material is for those who are already familiar with the basics of neural networks, and wish to deepen their understanding of the underlying math. Don't worry if you get stuck at some point along the way|just go back and reread the previous section, and try writing down and working through some examples. And if you're still stuck, we're happy to answer your questions in the Theory category at forums.fast.ai. Note: There is a reference section at the end of the paper summarizing all the key matrix calculus rules and terminology discussed here. arXiv:1802.01528v3 [cs.LG] 2 Jul 2018 1 Contents 1 Introduction 3 2 Review: Scalar derivative rules4 3 Introduction to vector calculus and partial derivatives5 4 Matrix calculus 6 4.1 Generalization of the Jacobian . -

Line Integrals for Work, Circulation, and Plane Flux
Classroom Tips and Techniques: Line Integrals for Work, Circulation, and Plane Flux Robert J. Lopez Emeritus Professor of Mathematics and Maple Fellow © Maplesoft, a division of Waterloo Maple Inc., 2005 Introduction In our last column, we discussed how to address the iterated integral in Maple 9.5. This month, we will continue discussing integrals that arise in the subject area of vector calculus. In particular, we will discuss line integrals of the tangential and normal components of a vector field. The line integral of the tangential component of a force field produces the work done by the force on a particle of unit mass, as the mass moves along a specified curve. For the tangential component of the velocity field of a planar fluid flow, the line integral around a closed curve - typically a circle - is the circulation of the flow. The line integral of the normal component of a vector field is the flux of the field through the curve, and is a measure of the net "flow" of the field in the direction of the normal. If F = i + j represents the vector field in Cartesian coordinates, and is a planar curve parametrized by the equations then work (or circulation), the line integral of the tangential component of F along , is given by + or Flux, the line integral of the normal component of F along , is given by or (The mnemonic I always provided my students for the flux integral in the plane is that the form starts and ends with the same letters as the word "flux" and has a minus sign in the middle, thus determining where the letters and must go.) All of these physically meaningful quantities can be computed with the LineInt command in Maple's VectorCalculus package. -

A Brief Tour of Vector Calculus
A BRIEF TOUR OF VECTOR CALCULUS A. HAVENS Contents 0 Prelude ii 1 Directional Derivatives, the Gradient and the Del Operator 1 1.1 Conceptual Review: Directional Derivatives and the Gradient........... 1 1.2 The Gradient as a Vector Field............................ 5 1.3 The Gradient Flow and Critical Points ....................... 10 1.4 The Del Operator and the Gradient in Other Coordinates*............ 17 1.5 Problems........................................ 21 2 Vector Fields in Low Dimensions 26 2 3 2.1 General Vector Fields in Domains of R and R . 26 2.2 Flows and Integral Curves .............................. 31 2.3 Conservative Vector Fields and Potentials...................... 32 2.4 Vector Fields from Frames*.............................. 37 2.5 Divergence, Curl, Jacobians, and the Laplacian................... 41 2.6 Parametrized Surfaces and Coordinate Vector Fields*............... 48 2.7 Tangent Vectors, Normal Vectors, and Orientations*................ 52 2.8 Problems........................................ 58 3 Line Integrals 66 3.1 Defining Scalar Line Integrals............................. 66 3.2 Line Integrals in Vector Fields ............................ 75 3.3 Work in a Force Field................................. 78 3.4 The Fundamental Theorem of Line Integrals .................... 79 3.5 Motion in Conservative Force Fields Conserves Energy .............. 81 3.6 Path Independence and Corollaries of the Fundamental Theorem......... 82 3.7 Green's Theorem.................................... 84 3.8 Problems........................................ 89 4 Surface Integrals, Flux, and Fundamental Theorems 93 4.1 Surface Integrals of Scalar Fields........................... 93 4.2 Flux........................................... 96 4.3 The Gradient, Divergence, and Curl Operators Via Limits* . 103 4.4 The Stokes-Kelvin Theorem..............................108 4.5 The Divergence Theorem ...............................112 4.6 Problems........................................114 List of Figures 117 i 11/14/19 Multivariate Calculus: Vector Calculus Havens 0. -

Mathematics 1
Mathematics 1 MATH 1141 Calculus I for Chemistry, Engineering, and Physics MATHEMATICS Majors 4 Credits Prerequisite: Precalculus. This course covers analytic geometry, continuous functions, derivatives Courses of algebraic and trigonometric functions, product and chain rules, implicit functions, extrema and curve sketching, indefinite and definite integrals, MATH 1011 Precalculus 3 Credits applications of derivatives and integrals, exponential, logarithmic and Topics in this course include: algebra; linear, rational, exponential, inverse trig functions, hyperbolic trig functions, and their derivatives and logarithmic and trigonometric functions from a descriptive, algebraic, integrals. It is recommended that students not enroll in this course unless numerical and graphical point of view; limits and continuity. Primary they have a solid background in high school algebra and precalculus. emphasis is on techniques needed for calculus. This course does not Previously MA 0145. count toward the mathematics core requirement, and is meant to be MATH 1142 Calculus II for Chemistry, Engineering, and Physics taken only by students who are required to take MATH 1121, MATH 1141, Majors 4 Credits or MATH 1171 for their majors, but who do not have a strong enough Prerequisite: MATH 1141 or MATH 1171. mathematics background. Previously MA 0011. This course covers applications of the integral to area, arc length, MATH 1015 Mathematics: An Exploration 3 Credits and volumes of revolution; integration by substitution and by parts; This course introduces various ideas in mathematics at an elementary indeterminate forms and improper integrals: Infinite sequences and level. It is meant for the student who would like to fulfill a core infinite series, tests for convergence, power series, and Taylor series; mathematics requirement, but who does not need to take mathematics geometry in three-space. -

Problem Set 1
Mathematics 41C - 43C Mathematics Department Phillips Exeter Academy Exeter, NH August 2019 Table of Contents 41C Laboratory 0: Graphing . 6 Problem Set 1 . 9 Laboratory 1: Differences . 13 Problem Set 2 . .15 Laboratory 2: Functions and Rate of Change Graphs . 19 Problem Set 3 . .21 Laboratory 3: Approximating Instantaneous Rate of Change . 28 Problem Set 4 . .29 Laboratory 4: Linear Approximation . 34 Problem Set 5 . .36 Laboratory 5: Transformations and Derivatives . 41 Problem Set 6 . .43 Laboratory 6: Addition Rule and Product Rule for Derivatives . 47 Problem Set 7 . .49 Laboratory 7: Graphs and the Derivative . .53 Problem Set 8 . .54 Laboratory 8: The Most Exciting Moment on the Tilt-a-Whirl . 58 42C Laboratory 9: Graphs and the Second Derivative . 62 Problem Set 10 . .63 Laboratory 10: The Chain Rule for Derivatives . 66 Problem Set 11 . .69 Laboratory 11: Discovering Differential Equations . 74 Problem Set 12 . .76 Laboratory 12: Projectile Motion . .80 Problem Set 13 . .81 Laboratory 13: Introducing Slope Fields . .84 Problem Set 14 . .86 Laboratory 14: Introducing Euler's Method . 89 Problem Set 15 . .91 Laboratory 15: Skydiving . 95 Problem Set 16 . .97 43C Problem Set 17 . 102 Laboratory 17: The Gini Index . .107 Problem Set 18 . 111 Laboratory 18: Integration as Accumulation . .115 Problem Set 19 . 117 Laboratory 19: Geometric Probability . 120 Problem Set 20 . 121 August 2019 3 Phillips Exeter Academy Table of Contents Laboratory 20: The Normal Curve . 124 Problem Set 21 . 126 Laboratory 21: The Exponential Distribution . 129 Problem Set 22 . 131 Laboratory 22: Calculus and Data Analysis . 134 Problem Set 23 . 138 Laboratory 23: Predator/Prey Model . -

Policy Gradient
Lecture 7: Policy Gradient Lecture 7: Policy Gradient David Silver Lecture 7: Policy Gradient Outline 1 Introduction 2 Finite Difference Policy Gradient 3 Monte-Carlo Policy Gradient 4 Actor-Critic Policy Gradient Lecture 7: Policy Gradient Introduction Policy-Based Reinforcement Learning In the last lecture we approximated the value or action-value function using parameters θ, V (s) V π(s) θ ≈ Q (s; a) Qπ(s; a) θ ≈ A policy was generated directly from the value function e.g. using -greedy In this lecture we will directly parametrise the policy πθ(s; a) = P [a s; θ] j We will focus again on model-free reinforcement learning Lecture 7: Policy Gradient Introduction Value-Based and Policy-Based RL Value Based Learnt Value Function Implicit policy Value Function Policy (e.g. -greedy) Policy Based Value-Based Actor Policy-Based No Value Function Critic Learnt Policy Actor-Critic Learnt Value Function Learnt Policy Lecture 7: Policy Gradient Introduction Advantages of Policy-Based RL Advantages: Better convergence properties Effective in high-dimensional or continuous action spaces Can learn stochastic policies Disadvantages: Typically converge to a local rather than global optimum Evaluating a policy is typically inefficient and high variance Lecture 7: Policy Gradient Introduction Rock-Paper-Scissors Example Example: Rock-Paper-Scissors Two-player game of rock-paper-scissors Scissors beats paper Rock beats scissors Paper beats rock Consider policies for iterated rock-paper-scissors A deterministic policy is easily exploited A uniform random policy -
Lecture 19, March 1
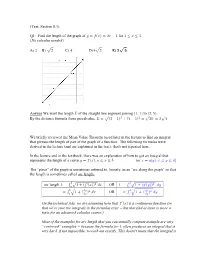
(Text, Section 8.1) Q1: Find the length of the graph of for No calculus needed A) B) C) D) E) Answer We want the length of the straight line segment joining to By the distance formula from precalculus, We briefly reviewed the Mean Value Theorem (used later in the lecture to find an integral that givesus the length of part of the graph of a function. The following formulas were derived in the lecture (and are explained in the text): that's not repeated here. In the lecture and in the textbook, there was an explanation of how to get an integral that represents the length of a curve , (or The “piece” of the graph is sometimes referred to, loosely, as an “arc along the graph” so that the length is sometimes called arc length. arc length OR OR On the technical side, we are assuming here that is a continuous function (so that we're sure the integrals in the formulas exist but that find of issue is more a topic for an advanced calculus course.) Most of the examples for arc length that you can actually compute example are very “contrived” examples because the formula for often produces an integral that is very hard, if not impossible, to work out exactly. This doesn't mean that the integral is useless, however. Apart from certain theoretical uses, you can always write down the integral for any arc length and then use the Midpoint Rule, or some more sophisticated approximation rule, to approximate the value of the integral. For the Midpoint Rule, just pick as large an as you can tolerate working with, subdivide the interval into equal parts of length = , and plug into the formula for We can verify that these formulas do work in the simplest case (a straight line segment) which we did in Q1 without any calculus at all. -

High Order Gradient, Curl and Divergence Conforming Spaces, with an Application to NURBS-Based Isogeometric Analysis
High order gradient, curl and divergence conforming spaces, with an application to compatible NURBS-based IsoGeometric Analysis R.R. Hiemstraa, R.H.M. Huijsmansa, M.I.Gerritsmab aDepartment of Marine Technology, Mekelweg 2, 2628CD Delft bDepartment of Aerospace Technology, Kluyverweg 2, 2629HT Delft Abstract Conservation laws, in for example, electromagnetism, solid and fluid mechanics, allow an exact discrete representation in terms of line, surface and volume integrals. We develop high order interpolants, from any basis that is a partition of unity, that satisfy these integral relations exactly, at cell level. The resulting gradient, curl and divergence conforming spaces have the propertythat the conservationlaws become completely independent of the basis functions. This means that the conservation laws are exactly satisfied even on curved meshes. As an example, we develop high ordergradient, curl and divergence conforming spaces from NURBS - non uniform rational B-splines - and thereby generalize the compatible spaces of B-splines developed in [1]. We give several examples of 2D Stokes flow calculations which result, amongst others, in a point wise divergence free velocity field. Keywords: Compatible numerical methods, Mixed methods, NURBS, IsoGeometric Analyis Be careful of the naive view that a physical law is a mathematical relation between previously defined quantities. The situation is, rather, that a certain mathematical structure represents a given physical structure. Burke [2] 1. Introduction In deriving mathematical models for physical theories, we frequently start with analysis on finite dimensional geometric objects, like a control volume and its bounding surfaces. We assign global, ’measurable’, quantities to these different geometric objects and set up balance statements. -

The Linear Algebra Version of the Chain Rule 1
Ralph M Kaufmann The Linear Algebra Version of the Chain Rule 1 Idea The differential of a differentiable function at a point gives a good linear approximation of the function – by definition. This means that locally one can just regard linear functions. The algebra of linear functions is best described in terms of linear algebra, i.e. vectors and matrices. Now, in terms of matrices the concatenation of linear functions is the matrix product. Putting these observations together gives the formulation of the chain rule as the Theorem that the linearization of the concatenations of two functions at a point is given by the concatenation of the respective linearizations. Or in other words that matrix describing the linearization of the concatenation is the product of the two matrices describing the linearizations of the two functions. 1. Linear Maps Let V n be the space of n–dimensional vectors. 1.1. Definition. A linear map F : V n → V m is a rule that associates to each n–dimensional vector ~x = hx1, . xni an m–dimensional vector F (~x) = ~y = hy1, . , yni = hf1(~x),..., (fm(~x))i in such a way that: 1) For c ∈ R : F (c~x) = cF (~x) 2) For any two n–dimensional vectors ~x and ~x0: F (~x + ~x0) = F (~x) + F (~x0) If m = 1 such a map is called a linear function. Note that the component functions f1, . , fm are all linear functions. 1.2. Examples. 1) m=1, n=3: all linear functions are of the form y = ax1 + bx2 + cx3 for some a, b, c ∈ R. -

Math 125: Calculus II - Dr
Math 125: Calculus II - Dr. Loveless Essential Course Info My Course Website: math.washington.edu/~aloveles/ Homework Log-In (use UWNetID): webassign.net/washington/login.html Directions for Webassign code purchase: math.washington.edu/webassign Math Department 125 Course Page: math.washington.edu/~m125/ First week to do list 1. Read 4.9, 5.1, 5.2, and 5.3 of the book. Start attempting HW. 2. Print off the “worksheets” and bring them to quiz sections. Today 1st HW assignments Syllabus/Intro Closing time is always 11pm. Section 4.9 - HW1A,1B,1C close Oct 4 - antiderivatives (Wed) (covers 4.9, 5.1, and 5.2) Expect 6-8 hrs of work, start today! What we will do in this course: 4. Ch. 8-9 – More Applications We learn the basic tools of integral - Arc Length, Center of Mass calculus which provide the essential - Differential Equations language for engineering, science and economics. Specifically, 5. Practicing Algebra, Trig and Precalc Students often say: The hardest part 1. Ch. 5 – Defining the Integral of calculus is you have to know all - Definition and basic techniques your precalculus, and they are right. 2. Ch. 6 – Basic Integral Applications Improving your algebra, trig and - Areas, Volumes precalculus skills will be one of the - Average Value best benefits you will gain from this - Measuring Work course (arguably as valuable as the course content itself). You will use 3. Ch. 7 – Integration Techniques these skills often in your other - by parts, trig, trig sub, partial courses at UW. frac Entry Task: Differentiate 7 1. 퐹(푥) = − 5√푥3 + 4ln (푥) 푥10 6푥 2. -

1 Space Curves and Tangent Lines 2 Gradients and Tangent Planes
CLASS NOTES for CHAPTER 4, Nonlinear Programming 1 Space Curves and Tangent Lines Recall that space curves are de¯ned by a set of parametric equations, x1(t) 2 x2(t) 3 r(t) = . 6 . 7 6 7 6 xn(t) 7 4 5 In Calc III, we might have written this a little di®erently, ~r(t) =< x(t); y(t); z(t) > but here we want to use n dimensions rather than two or three dimensions. The derivative and antiderivative of r with respect to t is done component- wise, x10 (t) x1(t) dt 2 x20 (t) 3 2 R x2(t) dt 3 r(t) = . ; R(t) = . 6 . 7 6 R . 7 6 7 6 7 6 xn0 (t) 7 6 xn(t) dt 7 4 5 4 5 And the local linear approximation to r(t) is alsoRdone componentwise. The tangent line (in n dimensions) can be written easily- the derivative at t = a is the direction of the curve, so the tangent line is given by: x1(a) x10 (a) 2 x2(a) 3 2 x20 (a) 3 L(t) = . + t . 6 . 7 6 . 7 6 7 6 7 6 xn(a) 7 6 xn0 (a) 7 4 5 4 5 In Class Exercise: Use Maple to plot the curve r(t) = [cos(t); sin(t); t]T ¼ and its tangent line at t = 2 . 2 Gradients and Tangent Planes Let f : Rn R. In this case, we can write: ! y = f(x1; x2; x3; : : : ; xn) 1 Note that any function that we wish to optimize must be of this form- It would not make sense to ¯nd the maximum of a function like a space curve; n dimensional coordinates are not well-ordered like the real line- so the fol- lowing statement would be meaningless: (3; 5) > (1; 2). -

Integrating Gradients
Integrating gradients 1 dimension The \gradient" of a function f(x) in one dimension (i.e., depending on only one variable) is just the derivative, f 0(x). We want to solve f 0(x) = k(x); (1) where k(x) is a known function. When we find a primitive function K(x) to k(x), the general form of f is K plus an arbitrary constant, f(x) = K(x) + C: (2) Example: With f 0(x) = 2=x we find f(x) = 2 ln x + C, where C is an undetermined constant. 2 dimensions We let the function depend on two variables, f(x; y). When the gradient rf is known, we have known functions k1 and k2 for the partial derivatives: @ f(x; y) = k (x; y); @x 1 @ f(x; y) = k (x; y): (3) @y 2 @f To solve this, we integrate one of them. To be specific, we here integrate @x over x. We find a primitive function with respect to x (thus keeping y constant) to k1 and call it k3. The general form of f will be k3 plus an arbitrary term whose x-derivative is zero. In other words, f(x; y) = k3(x; y) + B(y); (4) where B(y) is an unknown function of y. We have made some progress, because we have replaced an unknown function of two variables with another unknown function depending only on one variable. @f The best way to come further is not to integrate @y over y. That would give us a second unknown function, D(x).