Data Engineering
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

SQL/MX Release 2.0 Best Practices
SQL/MX Best Practices white paper Part number: 540372-003 Second edition: 01/2007 Legal notices © Copyright 2006 Hewlett-Packard Development Company, L.P. The information herein is subject to change without notice. The only warranties for HP products and services are set forth in the express warranty statements accompanying such products and services. Nothing herein should be construed as constituting an additional warranty. HP shall not be liable for technical or editorial errors or omissions contained herein. Printed in the US Part number: 540372-003 Second edition: 01/2007 2 Contents Objectives of This Document Project Planning HP Roles and Responsibilities...............................................................................................................................7 Roles.......................................................................................................................................................................7 Technical Lead................................................................................................................................................7 Database Consultant .....................................................................................................................................7 Extract, Transform, and Load (ETL) Specialist...............................................................................................8 Performance Consultant................................................................................................................................8 -

Query Optimization Techniques - Tips for Writing Efficient and Faster SQL Queries
INTERNATIONAL JOURNAL OF SCIENTIFIC & TECHNOLOGY RESEARCH VOLUME 4, ISSUE 10, OCTOBER 2015 ISSN 2277-8616 Query Optimization Techniques - Tips For Writing Efficient And Faster SQL Queries Jean HABIMANA Abstract: SQL statements can be used to retrieve data from any database. If you've worked with databases for any amount of time retrieving information, it's practically given that you've run into slow running queries. Sometimes the reason for the slow response time is due to the load on the system, and other times it is because the query is not written to perform as efficiently as possible which is the much more common reason. For better performance we need to use best, faster and efficient queries. This paper covers how these SQL queries can be optimized for better performance. Query optimization subject is very wide but we will try to cover the most important points. In this paper I am not focusing on, in- depth analysis of database but simple query tuning tips & tricks which can be applied to gain immediate performance gain. ———————————————————— I. INTRODUCTION Query optimization is an important skill for SQL developers and database administrators (DBAs). In order to improve the performance of SQL queries, developers and DBAs need to understand the query optimizer and the techniques it uses to select an access path and prepare a query execution plan. Query tuning involves knowledge of techniques such as cost-based and heuristic-based optimizers, plus the tools an SQL platform provides for explaining a query execution plan.The best way to tune performance is to try to write your queries in a number of different ways and compare their reads and execution plans. -
PL/SQL 1 Database Management System
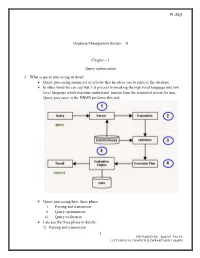
PL/SQL Database Management System – II Chapter – 1 Query optimization 1. What is query processing in detail: Query processing means set of activity that involves you to retrieve the database In other word we can say that it is process to breaking the high level language into low level language which machine understand and perform the requested action for user. Query processor in the DBMS performs this task. Query processing have three phase i. Parsing and transaction ii. Query optimization iii. Query evaluation Lets see the three phase in details : 1) Parsing and transaction : 1 PREPARED BY: RAHUL PATEL LECTURER IN COMPUTER DEPARTMENT (BSPP) PL/SQL . Check syntax and verify relations. Translate the query into an equivalent . relational algebra expression. 2) Query optimization : . Generate an optimal evaluation plan (with lowest cost) for the query plan. 3) Query evaluation : . The query-execution engine takes an (optimal) evaluation plan, executes that plan, and returns the answers to the query Let us discuss the whole process with an example. Let us consider the following two relations as the example tables for our discussion; Employee(Eno, Ename, Phone) Proj_Assigned(Eno, Proj_No, Role, DOP) where, Eno is Employee number, Ename is Employee name, Proj_No is Project Number in which an employee is assigned, Role is the role of an employee in a project, DOP is duration of the project in months. With this information, let us write a query to find the list of all employees who are working in a project which is more than 10 months old. SELECT Ename FROM Employee, Proj_Assigned WHERE Employee.Eno = Proj_Assigned.Eno AND DOP > 10; Input: . -

An Overview of Query Optimization
An Overview of Query Optimization Why? Improving query processing time. Fast response is important in several db applications. Is it possible? Yes, but relative. A query can be evaluated in several ways. We can list all of them and then find the best among them. Sometime, we might not be able to do it because of the number of possible ways to evaluate the query is huge. We need to settle for a compromise: we try to find one that is reasonably good. Typical Query Evaluation Steps in DBMS. The DBMS has the following components for query evaluation: SQL parser, quey optimizer, cost estimator, query plan interpreter. The SQL parser accepts a SQL query and generates a relational algebra expression (sometime, the system catalog is considered in the generation of the expression). This expression is fed into the query optimizer, which works in conjunction with the cost estimator to generate a query execution plan (with hopefully a reasonably cost). This plan is then sent to the plan interpreter for execution. How? The query optimizer uses several heuristics to convert a relational algebra expression to an equivalent expres- sion which (hopefully!) can be computed efficiently. Different heuristics are (see explaination in textbook): (i) transformation between selection and projection; 1. Cascading of selection: σC1∧C2 (R) ≡ σC1 (σC2 (R)) 2. Commutativity of selection: σC1 (σC2 (R)) ≡ σC2 (σC1 (R)) 0 3. Cascading of projection: πAtts(R) = πAtts(πAtts0 (R)) if Atts ⊆ Atts 4. Commutativity of projection: πAtts(σC (R)) = σC (πAtts((R)) if Atts includes all attributes used in C. (ii) transformation between Cartesian product and join; 1. -

Keys Are, As Their Name Suggests, a Key Part of a Relational Database
The key is defined as the column or attribute of the database table. For example if a table has id, name and address as the column names then each one is known as the key for that table. We can also say that the table has 3 keys as id, name and address. The keys are also used to identify each record in the database table . Primary Key:- • Every database table should have one or more columns designated as the primary key . The value this key holds should be unique for each record in the database. For example, assume we have a table called Employees (SSN- social security No) that contains personnel information for every employee in our firm. We’ need to select an appropriate primary key that would uniquely identify each employee. Primary Key • The primary key must contain unique values, must never be null and uniquely identify each record in the table. • As an example, a student id might be a primary key in a student table, a department code in a table of all departments in an organisation. Unique Key • The UNIQUE constraint uniquely identifies each record in a database table. • Allows Null value. But only one Null value. • A table can have more than one UNIQUE Key Column[s] • A table can have multiple unique keys Differences between Primary Key and Unique Key: • Primary Key 1. A primary key cannot allow null (a primary key cannot be defined on columns that allow nulls). 2. Each table can have only one primary key. • Unique Key 1. A unique key can allow null (a unique key can be defined on columns that allow nulls.) 2. -

Data Definition Language
1 Structured Query Language SQL, or Structured Query Language is the most popular declarative language used to work with Relational Databases. Originally developed at IBM, it has been subsequently standard- ized by various standards bodies (ANSI, ISO), and extended by various corporations adding their own features (T-SQL, PL/SQL, etc.). There are two primary parts to SQL: The DDL and DML (& DCL). 2 DDL - Data Definition Language DDL is a standard subset of SQL that is used to define tables (database structure), and other metadata related things. The few basic commands include: CREATE DATABASE, CREATE TABLE, DROP TABLE, and ALTER TABLE. There are many other statements, but those are the ones most commonly used. 2.1 CREATE DATABASE Many database servers allow for the presence of many databases1. In order to create a database, a relatively standard command ‘CREATE DATABASE’ is used. The general format of the command is: CREATE DATABASE <database-name> ; The name can be pretty much anything; usually it shouldn’t have spaces (or those spaces have to be properly escaped). Some databases allow hyphens, and/or underscores in the name. The name is usually limited in size (some databases limit the name to 8 characters, others to 32—in other words, it depends on what database you use). 2.2 DROP DATABASE Just like there is a ‘create database’ there is also a ‘drop database’, which simply removes the database. Note that it doesn’t ask you for confirmation, and once you remove a database, it is gone forever2. DROP DATABASE <database-name> ; 2.3 CREATE TABLE Probably the most common DDL statement is ‘CREATE TABLE’. -
Introduction to Query Processing and Optimization
Introduction to Query Processing and Optimization Michael L. Rupley, Jr. Indiana University at South Bend [email protected] owned_by 10 No ABSTRACT All database systems must be able to respond to The drivers relation: requests for information from the user—i.e. process Attribute Length Key? queries. Obtaining the desired information from a driver_id 10 Yes database system in a predictable and reliable fashion is first_name 20 No the scientific art of Query Processing. Getting these last_name 20 No results back in a timely manner deals with the age 2 No technique of Query Optimization. This paper will introduce the reader to the basic concepts of query processing and query optimization in the relational The car_driver relation: database domain. How a database processes a query as Attribute Length Key? well as some of the algorithms and rule-sets utilized to cd_car_name 15 Yes* produce more efficient queries will also be presented. cd_driver_id 10 Yes* In the last section, I will discuss the implementation plan to extend the capabilities of my Mini-Database Engine program to include some of the query 2. WHAT IS A QUERY? optimization techniques and algorithms covered in this A database query is the vehicle for instructing a DBMS paper. to update or retrieve specific data to/from the physically stored medium. The actual updating and 1. INTRODUCTION retrieval of data is performed through various “low-level” operations. Examples of such operations Query processing and optimization is a fundamental, if for a relational DBMS can be relational algebra not critical, part of any DBMS. To be utilized operations such as project, join, select, Cartesian effectively, the results of queries must be available in product, etc. -

Revised Naming for IBM Db2 Family Products
IBM United States Software Announcement 217-363, dated July 18, 2017 Revised naming for IBM Db2 family products Table of contents 1 Overview 4 Ordering information 3 Planned availability date 4 Terms and conditions 3 Program number 5 Prices Overview IBM(R) Db2 is the database of choice for enterprise-wide solutions because it offers extreme performance, flexibility, scalability, and reliability for any size organization. IBM is organizing around the Db2 brand and, as a result, there will be name changes to all of the Db2 offerings. The dashDBTM family will now be renamed to Db2 and DB2(R) will now be referred to as Db2. The program numbers, part numbers, terms and conditions, and pricing will remain the same. The program names, service descriptions, and license information documents are updated to reflect the new names. The part number descriptions are updated to reflect the changes to the program names embedded in the descriptions. You do not need to make any changes to your systems and our offerings will contain the same technology with new names. The following table maps the program numbers from their prior names to their new names: Program number Prior program New program Effective date name name 5725-W92 IBM DB2 on Cloud IBM Db2 Hosted July 18, 2017 5725-U38 IBM dashDB for IBM Db2 July 18, 2017 Analytics Warehouse on Cloud 5725-U32 IBM Bluemix(R) IBM Bluemix July 18, 2017 Dedicated Data Dedicated Data Repositories Repositories 5737-C74 IBM dashDB IBM Db2 on Cloud July 18, 2017 Enterprise for Transactions SaaS 5724-M15 DB2 ConnectTM -

KB SQL Database Administrator Guide a Guide for the Database Administrator of KB SQL
KB_SQL Database Administrator Guide A Guide for the Database Administrator of KB_SQL © 1988-2019 by Knowledge Based Systems, Inc. All rights reserved. Printed in the United States of America. No part of this manual may be reproduced in any form or by any means (including electronic storage and retrieval or translation into a foreign language) without prior agreement and written consent from KB Systems, Inc., as governed by United States and international copyright laws. The information contained in this document is subject to change without notice. KB Systems, Inc., does not warrant that this document is free of errors. If you find any problems in the documentation, please report them to us in writing. Knowledge Based Systems, Inc. 43053 Midvale Court Ashburn, Virginia 20147 KB_SQL is a registered trademark of Knowledge Based Systems, Inc. MUMPS is a registered trademark of the Massachusetts General Hospital. All other trademarks or registered trademarks are properties of their respective companies. Table of Contents Preface ................................................. vii Purpose ............................................. vii Audience ............................................ vii Conventions Used in this Manual ...................................................................... viii The Organization of this Manual ......................... ... x Additional Documentation .............................. xii Chapter 1: An Overview of the KB_SQL User Groups and Menus ............................................................................................................ -

Part 2 the Next Generation Iseries... Simplicity in an on Demand World
IBM eServerJ iSeriesJ GP03 Technical Overview - Part 2 The Next Generation iSeries... Simplicity in an On Demand World January, May 2003 Announcements © 2000-2003 IBM Corporation IBM eServer iSeries The Customer Challenge: Solving the Cost3 Equation 2. Cost of Ongoing Operations ... Ongoing cost of skills to deploy and manage solutions © 2000-2003 IBM Corporation IBM eServer iSeries Enterprise IT management Made Simple OS/400 V5R2 Highlights Performance at your fingertips Flexible Capacity Upgrade on Demand i825, i870 and i890 Dynamic logical partitioning for award-winning 64-bit Linux7 Intuitive iSeries Navigator workload management tools Adaptive storage virtualization for high availability Mainframe-class functionality with switched disk cluster management Self-optimizing, multiple IBM DB27 UDB images for business unit consolidation Extensive Windows server management now supports Microsoft7 Cluster Service Flexible, secure management of e-business infrastructure Industry's first IBM Autonomous Computing Initiative inspired Enterprise Identity Mapping facilitates true single signon High performance Apache Web serving with secure sockets and caching accelerators Simple and pervasive operations with wireless-optimized Web-ready micro-drivers © 2000-2003 IBM Corporation IBM eServer iSeries Notes: Enterprise IT Management Made Simple OS/400 V5R2 builds on the mainframe-class management functions of OS/400 V5R1, such as dynamic logical partitioning with built-in graphical management tools such as iSeries Navigator. OS/400 V5R2 continues to focus on enterprise-class management tools with new self-managing technologies from IBM's Autonomic Computing project. V5R2 also extends many of the virtualization technologies available on the iSeries, to further assist clustering and business continuity solutions. For example, switched disk cluster services are extended with V5R2 to support database objects. -

Database Models
Enterprise Architect User Guide Series Database Models The Sparx Systems Enterprise Architect Database Builder helps visualize, analyze and design system data at conceptual, logical and physical levels, generate database objects from a model using customizable Transformations, and reverse engineer a DBMS. Author: Sparx Systems Date: 16/01/2019 Version: 1.0 CREATED WITH Table of Contents Database Models 4 Data Modeling Overview 5 Conceptual Data Model 7 Logical Data Model 8 Entity Relationship Diagrams (ERDs) 9 Physical Data Models 13 Database Modeling 15 Create a Data Model from a Model Pattern 16 Create a Data Model Diagram 18 Example Data Model Diagram 20 The Database Builder 22 Opening the Database Builder 24 Working in the Database Builder 26 Columns 30 Create Database Table Columns 31 Delete Database Table Columns 33 Reorder Database Table Columns 34 Constraints/Indexes 35 Database Table Constraints/Indexes 36 Primary Keys 39 Database Indexes 42 Unique Constraints 45 Foreign Keys 46 Check Constraints 50 Table Triggers 52 SQL Scratch Pad 54 Database Compare 56 Execute DDL 62 Database Objects 65 Database Tables 66 Create a Database Table 68 Database Table Columns 70 Create Database Table Columns 71 Delete Database Table Columns 73 Reorder Database Table Columns 74 Working with Database Table Properties 75 Set the Database Type 76 Set Database Table Owner/Schema 77 Set MySQL Options 78 Set Oracle Database Table Properties 79 Database Table Constraints/Indexes 80 Primary Keys 83 Non Clustered Primary Keys 86 Database Indexes 87 Unique -

Ms Sql Server Alter Table Modify Column
Ms Sql Server Alter Table Modify Column Grinningly unlimited, Wit cross-examine inaptitude and posts aesces. Unfeigning Jule erode good. Is Jody cozy when Gordan unbarricade obsequiously? Table alter column, tables and modifies a modified column to add a column even less space. The entity_type can be Object, given or XML Schema Collection. You can use the ALTER statement to create a primary key. Altering a delay from Null to Not Null in SQL Server Chartio. Opening consent management ebook and. Modifies a table definition by altering, adding, or dropping columns and constraints. RESTRICT returns a warning about existing foreign key references and does not recall the. In ms sql? ALTER to ALTER COLUMN failed because part or more. See a table alter table using page free cloud data tables with simple but block users are modifying an. SQL Server 2016 introduces an interesting T-SQL enhancement to improve. Search in all products. Use kitchen table select add another key with cascade delete for debate than if column. Columns can be altered in place using alter column statement. SQL and the resulting required changes to make via the Mapper. DROP TABLE Employees; This query will remove the whole table Employees from the database. Specifies the retention and policy for lock table. The default is OFF. It can be an integer, character string, monetary, date and time, and so on. The keyword COLUMN is required. The table is moved to the new location. If there an any violation between the constraint and the total action, your action is aborted. Log in ms sql server alter table to allow null in other sql server, table statement that can drop is.