Spark and DB2 -- a Perfect Couple
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Weather Company History on Demand
Solution Brief The Weather Company History on Demand Learn from the past’s data to prepare for the future’s business demands Highlights Anecdotes are great for telling stories, but they lose credibility when your near real-time business decisions depend on – Precision them for actionable data. History on Demand (HoD), from The – Accuracy Weather Company, an IBM Business, provides the historical – Speed of scale context we believe you need to extrapolate relationships and – Competetive pricing make correlations with your past business and operational – 35km grid results to help you predict future business needs and – 5+ years historical data outcomes. HoD offers competitively priced and accurate historical weather information, featuring a 35 km worldwide grid and hourly historical information dating back to July 2011. Make global decisions locally HoD provides a worldwide, consistent dataset of the most important and commonly used weather parameters accessible via web API. You can obtain large historical datasets specific to your geography and time without having to rummage through unorganized public datasets. Couple the historical data with your analysis and our forecast products, and you’ll have the tools to help you manage and minimize significant weather impacts on your business and better plan for them in the future. Convenient access in one package HoD offers a comprehensive dataset spanning July 2011 to the present, and new data is regularly added as it becomes available. HoD contains hourly values for surface temperature, wind speed, wind direction, relative humidity, atmospheric pressure, dewpoint and precipitation rate. Access can be gained by latitude/longitude and is supported for a list of latitudinal/longitudinal points, as well as a bounding box specification. -

Ogeorgia's Economy
GEORGIA’S CREA TIVE OECONOMY Creative Industries GEORGIA’S 1 Establishments: 11,426 Jobs: 116,5771 Wages: $8.4 billion1 Self-Employed: 58,9592 Earnings: $1.6 billion2 CREA Revenue: $29 billion3 Economic Impact: $48 billion4 Sources: 1EMSI 2013 2Nonemployer Statistics 2012, TIVE 3Creative Industries in the South 2012 4ACPSA Issue Brief #5: ECONOMY The Impact of New Demand for Arts and Culture Film and Television Combined Productions: 158 Direct Spend of Productions: $1.4 billion Direct Jobs: 23,500 Direct and Indirect Jobs: 77,900 Direct and Indirect Wages: $3.8 billion Economic Impact: $5.1 billion Source: Georgia Entertainment Industry Profile FY14 2 Music Direct and Indirect Jobs: 26,2211 Direct and Indirect Wages: $1.1 billion1 Total Revenues to State and Local Governments: $314 million2 1 Economic Impact: $3.6 billion Source: 1Estimated Economic Impact of the Music Industry on Georgia’s Metropolitan Areas and the State, 2014 2Source: Economic and Fiscal Impact Analysis of the Music Industry in Georgia, 2011 Digital Entertainment Direct Jobs: 1,824 Direct and Indirect Jobs: 8,719 Wages: $528 million Revenue: $758 million State Tax Revenue: $49 million Exports: $47 million Economic Impact: $1.9 billion Source: Georgia’s Digital Entertainment Industry, 2012 3 Arts & Culture Organizations: 2,3911 Jobs: 24,2282 Wages: $478 million2 Revenue: $1.1 billion3 Assets: $2.5 billion4 Economic Impact: $1.8 billion5 Source: 1National Center for Charitable Statistics, 2013 2Economic Census, 2007 and Nonemployer Statistics, 2012 3National Center for Charitable Statistics, 2013 and Nonemployer Statistics, 2012 4National Center for Charitable Statistics, 2013 5ACPSA Issue Brief #5: The Impact of New Demand for Arts and Culture 4 GEORGIA COUNCIL FOR THE ARTS A division of the Georgia Department of Economic Development, Georgia Council for the Arts (GCA) empowers the arts industry in Georgia and artists around the state to cultivate healthy, vibrant communities that are rich in civic participation, cultural experiences, and economic prosperity. -

IBM Services ISMS / PIMS Products / Pids in Scope
1H 2021 Certified Product List IBM services ISMS/PIMS Product/Service Offerings/PIDs in scope The following is a list of products associated with the offering bundles in scope of the IBM services information security management system (ISMS). The Cloud services ISMS has been certified on: ISO/IEC 27001:2013 ISO/IEC 27017:2015 ISO/IEC 27018:2019 ISO/IEC 27701:2019 As well as the IBM Cloud Services STAR Self-Assessment found here: This listing is current as of 07/20/2021 IBM Cloud Services STAR Self-Assessment Cloud Controls Matrix v3.0.1 https://cloudsecurityalliance.org/registry/ibm-cloud/ To find out more about IBM Cloud compliance go to: https://www.ibm.com/cloud/compliance/global type groupNameproductName pids ISO Group AccessHub-at-IBM Offering AccessHub-at-IBM N/A ISO Group AI Applications - Maximo and TRIRIGA Offering IBM Enterprise Asset Management Anywhere on Cloud (Maximo) 5725-Z55 Offering IBM Enterprise Asset Management Anywhere on Cloud (Maximo) Add-On 5725-Z55 Offering IBM Enterprise Asset Management on Cloud (Maximo) Asset Configuration Manager Add-On 5725-P73 Offering IBM Enterprise Asset Management on Cloud (Maximo) Aviation Add-On 5725-P73 Offering IBM Enterprise Asset Management on Cloud (Maximo) Calibration Add-On 5725-P73 Offering IBM Enterprise Asset Management on Cloud (Maximo) for Managed Service Provider Add-On 5725-P73 Offering IBM Enterprise Asset Management on Cloud (Maximo) Health, Safety and Environment Manager Add-On 5725-P73 Offering IBM Enterprise Asset Management on Cloud (Maximo) Life Sciences Add-On -

Weather Company Alerts Console
2 August 2 021 May 2019 Alerts Console Weather Company USER GUIDE ALERTS CONSOLE 2 COPYRIGHT © 2021 The Weather Company, an IBM Business © 2016 IBM Corporation All Rights Reserved; Confidential Material T he Weather Company 4 00 Minuteman Road Andover, MA 01810 DOCUMENT INFORMATION Weather Alerts User Guide Last updated August 10, 2 021 © 2021 The Weather Company, an IBM Business © 2016 IBM Corporation ALERTS CONSOLE 3 CONTENTS ABOUT THIS GUIDE ............................................................................................................................................... 4 Related resources .................................................................................................................................... 4 Getting help .............................................................................................................................................. 4 OVERVIEW OF WEATHER ALERTS ...................................................................................................................... 5 Scenario: Improving customer loyalty through alerts ............................................................................... 5 Technical requirements and compatibility ................................................................................................ 5 Planning your alert service ....................................................................................................................... 6 Setting up Weather Alerts ....................................................................................................................... -

Corporate Responsibility Report 2 2016 IBM Corporate Responsibility Report
2016 Corporate Responsibility Report 2 2016 IBM Corporate Responsibility Report 3 Chairman’s letter 4 Year in review 8 Our approach to corporate responsibility 12 Awards and recognition 14 Performance summary 18 Communities 34 The IBMer 42 Environment 84 Supply chain 98 Governance About this report IBM’s annual Corporate Responsibility Report is published during the Unless otherwise noted, the data in this report covers our global second quarter of the subsequent calendar year. This report covers operations. Information about our business and financial performance is our performance in 2016 and some notable activities during the first half provided in our 2016 Annual Report. IBM did not employ an external of 2017. agency or organization to audit the 2016 Corporate Responsibility Report. In selecting the content for inclusion in our 2016 report, we have used the As we continue our journey to transform IBM into a cognitive solutions and Global Reporting Initiative (GRI) reporting principles of materiality, cloud platform company, we regularly review our strategy and approach sustainability context, stakeholder inclusiveness, and completeness. A to corporate responsibility. This ongoing analysis helps us to identify and GRI report utilizing the GRI G4 Sustainability Guidelines, as well as prioritize the issues of relevance to our business and our stakeholders. In additional details about IBM’s corporate responsibility activities and 2014 we engaged Business for Social Responsibility, a global nonprofit performance, can be found at our corporate responsibility website. business network and consultancy dedicated to sustainability, to conduct a materiality analysis. That analysis maps corporate responsibility priorities to IBM’s business strategy, stakeholders, and impact on global society. -

Identifying Your Contributions in an Evolving
The Global high-Resolution Atmospheric Forecast (GRAF) System: Advancing NWP through Strategic Partnerships Kevin R. Petty, Ph.D. Director of Science and Forecast Operations The Weather Company/IBM WMO OCP May 2021 Courtesy NCAR The Weather Company, an IBM Business / May 26, 2021 / © 2021 IBM Corporation GOALS AND CONSIDERATIONS Remain at the forefront of weather forecasting science and technology Advance the TWC/IBM forecast stack, with a focus on global, convective-allowing, rapidly-updating NWP Generate measurable, operational results on a relatively short time horizon (i.e., < 2years) Ensure initial investments result in sustainable, long- term capabilities that can be continually improved Leverage trusted, capable partners that have well- aligned objectives The Weather Company, an IBM Business / May 26, 2021 / © 2021 IBM Corporation KEY PARTNERS IN THE OPERATIONAL IMPLEMENTATION OF GRAF IBM Research IBM Systems NCAR Facilitate top performance on IBM Design and deliver the Power9 GPU- Lead the development of the GPU- systems, with a particular focus on based HPC upon which the GRAF accelerated MPAS system and work code optimization system operates with TWC to ensure optimal forecast output from IBM GRAF NVIDIA TWC/IBM Univ. of Washington Deliver knowledge and resources Testing, implementation and Support the porting of MPAS code aimed at supporting code operation of the MPAS core, as well and work in parallel on exploring optimization on GPU technology as advancements related to TWC- new, novel data sources that have specific goals and requirements the potential to contribute to improved weather forecasts The Weather Company, an IBM Business / May 26, 2021 / © 2021 IBM Corporation GLOBAL WEATHER ENTERPRISE Delivering public programs, goods, or Supplying products, services, and services (national, state, local) solutions targeting B2B and B2C markets Public Private Society Academic CBOs Provide core education and research NGOs Community-Based Organizations: elements Dedicated to working at a local level to improve life for residents. -
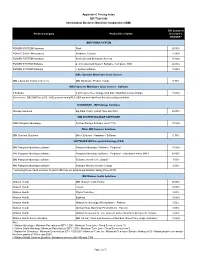
IBM Pricing Index New.Xlsx
Appendix C Pricing Index DIR-TSO-3996 International Business Machines Corporation (IBM) DIR Customer Product Category Product Description Discount % off MSRP * IBM POWER SYSTEM POWER-SYSTEM Hardware Rack 26.00% POWER-SYSTEM Hardware Hardware Console 15.00% POWER-SYSTEM Hardware Scale Out and Enterprise Servers 15.00% POWER SYSTEM Software p: AIX, Linux and System Software, Compilers, HMC 26.00% POWER SYSTEM Software i: System software 18.00% IBM z Systems Mainframe Class Servers IBM z Systems Family of Servers IBM Mainframe Product Family 0.75% IBM Z Systems Mainframe Class Servers - Software z Software z OTC (One Time Charge) and MLC (Monthly License Charge 15.00% Exclusions - DB2 QMF for z/OS, VUE products and zIPLA S&S are excluded from this discounting schedule HARDWARE - IBM Storage Solutions Storage Solutions Big Data, Flash, Hybrid,Tape and SAN 25.00% IBM SYSTEM STOARGE SOFTWARE NON Passport Advantage System Storage Software not in PPA 15.00% Other IBM Systems Solutions IBM Systems Solutions Other Systems - Hardware / Software 0.75% SOFTWARE IBM Passport Advantage (PPA) IBM Passport Advantage software Passport Advantage Software - Perpetual 15.00% IBM Passport Advantage software Passport Advantage Software - Perpetual - Education Entities ONLY 60.00% IBM Passport Advantage software Software as a Service (SaaS)* 3.00% IBM Passport Advantage software Software Monthly License Charge 2.00% * excluding those SaaS products for which IBM has not established Relative Selling Price (RSP) IBM Watson Health Solutions Watson Health IBM Watson -

The Weather Company, an IBM Business, Helps People Make Informed Expands Decisions and Take Action in the Face of Weather
Business challenge The Weather Company’s websites serve millions of users per day. When extreme weather hits and usage peaks, the sites must be at their fastest and most reliable to provide the information people need to stay safe. Transformation To optimize for elasticity in handling extreme spikes in demand, The Weather Company worked with IBM to migrate Chris Hill, VP and its web platform quickly and seamlessly Chief Information and from its existing cloud provider to the Technology Officer for IBM Watson Media and IBM® Cloud™. Weather Business benefits: “IBM Cloud is the perfect The Weather Company, engine to power the world’s largest weather Unlocks an IBM Business websites and deliver the significant cost savings on fastest, most accurate cloud hosting and support Migrating the world’s top weather insight to millions of users around the globe.” weather web property to Chris Hill VP, CIO and CTO Accelerates IBM Watson Media and Weather deployment of new services a secure, scalable global with Kubernetes architecture in the IBM Cloud The Weather Company, an IBM Business, helps people make informed Expands decisions and take action in the face of weather. The company offers the most global reach with access accurate forecasts globally with personalized and actionable weather data to a larger number of data and insights to millions of consumers, as well as thousands of marketers and Share this centers in local markets businesses via Weather’s API, its business solutions division, and its own digital products from The Weather Channel -

Corporate Responsibility Report 2020 Environmental Results to Removing More Than 11,000 Passenger Vehicles from the Road During the Year
2020 Corporate Responsibility Report Letter from the Chairman and CEO While the events of 2020 have tested and tried the world’s resolve in entirely new ways, they also revealed humanity’s determination to adapt and emerge stronger. It was a profound reminder that, when pressed for more, individuals and organizations will rise to reinvent themselves and apply ingenuity to the most challenging of societal problems. I am extremely proud of the work that IBMers have done to combat the global COVID-19 emergency, address systemic racism and establish new protocols for the future of work. At IBM: – We led with purpose and culture, empowering the IBMer at the center of our efforts. As IBM focuses on leadership in the era of hybrid cloud and AI, we are taking a number of decisive steps to create a culture where all employees can thrive. In March 2020, we transitioned 95 percent of IBMers to remote work within days, and throughout the year, we launched global initiatives to support the health and well-being of IBMers amid the pandemic. Today, we are shaping the future of work for a post-COVID era, building on our longtime approach to flexible and collaborative innovation. We are making every effort to address employee needs and commitments for empathy, transparency and social responsibility in this new era. Arvind Krishna Chairman and – We applied science and technology to accelerate Chief Executive Officer discovery, provide trusted information and respond resiliently to the pandemic. We helped organize the High – We reinforced our fight against climate change with Performance Computing Consortium to equip scientists leadership and innovation. -

La Contribution D'ibm Pour Les Villes Et Les Territoires
Philippe SAJHAU VP Smarter Cities IBM France Smarter Cities, Energy & Utilities [email protected] Twitter: @philippenog smartcities2016.wordpress.com LA CONTRIBUTION D’IBM POUR LES VILLES ET LES TERRITOIRES INTELLIGENTS ©2015 IBM Corporation IBM une société globale 12 laboratoires de et d’innovation tournée Plus de 6 recherche répartis dans milliards de 7 pays dans le monde ; plus sur le traitement de la dollars investis de 3000 chercheurs. donnée chaque année en R&D IBM Institute for Business Value : plus de Plus de 200 000 experts techniques 50 consultants qui effectuent des recherches et des analyses dans répartis dans des Centres de multiples secteurs d’activités et d’excellence partout le monde disciplines fonctionnelles. Forte valeur de Une stratégie la marque IBM : d’acquisition pour étendre 4e du classement le portefeuille d’offres IBM Interbrand 2014 Ex : SoftLayer Technologies (Cloud), Trusteer (Security), Fiberlink (Mobilité), Aspera, The Weather Company IBM aujourd’hui 2015 Chiffre 6’affaires 2000 IBM Corporation Chiffre d’affaires = 81,741M$* IBM Corporation Pilotés par l’innovation, = 88,396M$* nous assurons ainsi la productivité et la 38% 60% croissance de nos clients. Services 14% Logiciels 27% Systèmes et Financement Plus de 150 acquisitions depuis 48% 13% 2000 en logiciels et services. *Source : IBM Annual Report © 2016 International Business Machines Corporation – IBM Confidential 3 IBM – De la transformation à la réinvention digitale Digital Economie traditionnelle Intelligence Nouvelle économie Plateforme Valoriser -

Join IBM DB2 for I Table with IBM Bluemix Weather Web Service Record Set Use SQL to Get Weather Data for Each Line of Your DB2 for I Table
Join IBM DB2 for i table with IBM Bluemix Weather web service record set Use SQL to get weather data for each line of your DB2 for i table Christophe Lalevée February 22, 2017 This article explains how to create a join between REST API (web service) and an IBM DB2 for i table. Examples provided in this article show how to get weather data for geolocalized stores from a retail database. IBM Bluemix Weather Company Data service provides APIs to retrieve weather data from The Weather Company (TWC). Introduction In today's world, APIs provide access to more and more data and capabilities beyond the firewall. APIs are sources of strategic value in today's digital economy. Weather is a good illustration of the added value of API to business: building a weather-driven solution for better decision making can solve business problems where weather has a significant impact on the outcome. For instance, a retail store can sell more on a sunny day, and so sales targets should be changed accordingly. But, how difficult is it to integrate these web services with existing business data and applications? How can you join data from core business relational databases with data returned by web services? IBM® DB2® for i provides all capabilities to easily develop a data centric solution to get access to APIs, and to make join between data returned as JSON and DB2 tables. This article explains how to create a Weather Company Data service in IBM Bluemix® and provides examples to use it directly from DB2 for i, using JSON_TABLE and httpGetCLOB functions. -

Weather Company Max Weather
Data Sheet Weather Company Max Weather A Cirrus-based solution for your weather broadcasting needs For years, The Weather Company, an IBM Business’ Max ecosystem has helped advance the innovation of weather visualizations as an industry leading weather production system. Now they’ve taken another leap in innovation: Weather Company Max Weather powered by Weather Company Max Cirrus. Max Weather is an on-demand solution delivering weather information and content over the Cloud through our innovative Max Cirrus product. With Max Weather, you get the tools you need to deliver great weathercasts through a Cloud-based data delivery solution that’s simple to manage and easy to use. Tomorrow’s forecast calls for Max Cirrus – Lower upfront costs for higher, faster returns on new sponsorships – Professionally built scenes and up-to-the-minute data – Works seamlessly with the Max ecosystem for one of the industry’s only fully integrated multiplatform publishing solution – Ideal for smaller stations with limited IT resources and smaller budgets Radar – Features a simple-to-use interface for customization and control – Use on-air and social media content for richer storytelling – Includes: – Comprehensive data package – World-wide satellite imagery – Tropical package – Custom scene creation – Optional Weather Company Max Studio Interactivity Easy to use interface Page 2 Weather Company Max Weather About The Weather Company, an IBM Business The Weather Company, an IBM Business, helps people make informed decisions and take action in the face of weather. The company offers the most accurate forecasts globally with personalized and actionable weather data and insights to millions of consumers, as well as thousands of marketers and businesses via Weather’s API, its business solutions division, and its own digital products from The Weather Channel (weather.com) and Weather Underground (wunderground.com).