An Overview on the Mapping Techniques in Nosql Databases
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Query Optimization Techniques - Tips for Writing Efficient and Faster SQL Queries
INTERNATIONAL JOURNAL OF SCIENTIFIC & TECHNOLOGY RESEARCH VOLUME 4, ISSUE 10, OCTOBER 2015 ISSN 2277-8616 Query Optimization Techniques - Tips For Writing Efficient And Faster SQL Queries Jean HABIMANA Abstract: SQL statements can be used to retrieve data from any database. If you've worked with databases for any amount of time retrieving information, it's practically given that you've run into slow running queries. Sometimes the reason for the slow response time is due to the load on the system, and other times it is because the query is not written to perform as efficiently as possible which is the much more common reason. For better performance we need to use best, faster and efficient queries. This paper covers how these SQL queries can be optimized for better performance. Query optimization subject is very wide but we will try to cover the most important points. In this paper I am not focusing on, in- depth analysis of database but simple query tuning tips & tricks which can be applied to gain immediate performance gain. ———————————————————— I. INTRODUCTION Query optimization is an important skill for SQL developers and database administrators (DBAs). In order to improve the performance of SQL queries, developers and DBAs need to understand the query optimizer and the techniques it uses to select an access path and prepare a query execution plan. Query tuning involves knowledge of techniques such as cost-based and heuristic-based optimizers, plus the tools an SQL platform provides for explaining a query execution plan.The best way to tune performance is to try to write your queries in a number of different ways and compare their reads and execution plans. -
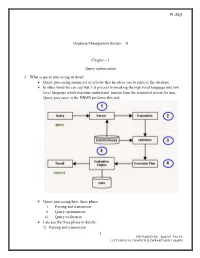
PL/SQL 1 Database Management System
PL/SQL Database Management System – II Chapter – 1 Query optimization 1. What is query processing in detail: Query processing means set of activity that involves you to retrieve the database In other word we can say that it is process to breaking the high level language into low level language which machine understand and perform the requested action for user. Query processor in the DBMS performs this task. Query processing have three phase i. Parsing and transaction ii. Query optimization iii. Query evaluation Lets see the three phase in details : 1) Parsing and transaction : 1 PREPARED BY: RAHUL PATEL LECTURER IN COMPUTER DEPARTMENT (BSPP) PL/SQL . Check syntax and verify relations. Translate the query into an equivalent . relational algebra expression. 2) Query optimization : . Generate an optimal evaluation plan (with lowest cost) for the query plan. 3) Query evaluation : . The query-execution engine takes an (optimal) evaluation plan, executes that plan, and returns the answers to the query Let us discuss the whole process with an example. Let us consider the following two relations as the example tables for our discussion; Employee(Eno, Ename, Phone) Proj_Assigned(Eno, Proj_No, Role, DOP) where, Eno is Employee number, Ename is Employee name, Proj_No is Project Number in which an employee is assigned, Role is the role of an employee in a project, DOP is duration of the project in months. With this information, let us write a query to find the list of all employees who are working in a project which is more than 10 months old. SELECT Ename FROM Employee, Proj_Assigned WHERE Employee.Eno = Proj_Assigned.Eno AND DOP > 10; Input: . -

An Overview of Query Optimization
An Overview of Query Optimization Why? Improving query processing time. Fast response is important in several db applications. Is it possible? Yes, but relative. A query can be evaluated in several ways. We can list all of them and then find the best among them. Sometime, we might not be able to do it because of the number of possible ways to evaluate the query is huge. We need to settle for a compromise: we try to find one that is reasonably good. Typical Query Evaluation Steps in DBMS. The DBMS has the following components for query evaluation: SQL parser, quey optimizer, cost estimator, query plan interpreter. The SQL parser accepts a SQL query and generates a relational algebra expression (sometime, the system catalog is considered in the generation of the expression). This expression is fed into the query optimizer, which works in conjunction with the cost estimator to generate a query execution plan (with hopefully a reasonably cost). This plan is then sent to the plan interpreter for execution. How? The query optimizer uses several heuristics to convert a relational algebra expression to an equivalent expres- sion which (hopefully!) can be computed efficiently. Different heuristics are (see explaination in textbook): (i) transformation between selection and projection; 1. Cascading of selection: σC1∧C2 (R) ≡ σC1 (σC2 (R)) 2. Commutativity of selection: σC1 (σC2 (R)) ≡ σC2 (σC1 (R)) 0 3. Cascading of projection: πAtts(R) = πAtts(πAtts0 (R)) if Atts ⊆ Atts 4. Commutativity of projection: πAtts(σC (R)) = σC (πAtts((R)) if Atts includes all attributes used in C. (ii) transformation between Cartesian product and join; 1. -

Franz's Allegrograph 7.1 Accelerates Complex Reasoning Across
Franz’s AllegroGraph 7.1 Accelerates Complex Reasoning Across Massive, Distributed Knowledge Graphs and Data Fabrics Distributed FedShard Queries Improved 10X. New SPARQL*, RDF* and SHACL Features Added. Lafayette, Calif., February 8, 2021 — Franz Inc., an early innovator in Artificial Intelligence (AI) and leading supplier of Graph Database technology for AI Knowledge Graph Solutions, today announced AllegroGraph 7.1, which provides optimizations for deeply complex queries across FedShard™ deployments – making complex reasoning up to 10X faster. AllegroGraph with FedShard offers a breakthrough solution that allows infinite data integration through a patented approach unifying all data and siloed knowledge into an Entity-Event Knowledge Graph solution for Enterprise scale analytics. AllegroGraph’s unique capabilities drive 360-degree insights and enable complex reasoning across enterprise-wide Knowledge Fabrics in Healthcare, Media, Smart Call Centers, Pharmaceuticals, Financial and much more. “The proliferation of Artificial Intelligence has resulted in the need for increasingly complex queries over more data,” said Dr. Jans Aasman, CEO of Franz Inc. “AllegroGraph 7.1 addresses two of the most daunting challenges in AI – continuous data integration and the ability to query across all the data. With this new version of AllegroGraph, organizations can create Data Fabrics underpinned by AI Knowledge Graphs that take advantage of the infinite data integration capabilities possible with our FedShard technology and the ability to query across -

Using Microsoft Power BI with Allegrograph,Knowledge Graphs Rise
Using Microsoft Power BI with AllegroGraph There are multiple methods to integrate AllegroGraph SPARQL results into Microsoft Power BI. In this document we describe two best practices to automate queries and refresh results if you have a production AllegroGraph database with new streaming data: The first method uses Python scripts to feed Power BI. The second method issues SPARQL queries directly from Power BI using POST requests. Method 1: Python Script: Assuming you know Python and have it installed locally, this is definitely the easiest way to incorporate SPARQL results into Power BI. The basic idea of the method is as follows: First, the Python script enables a connection to your desired AllegroGraph repository. Then we utilize AllegroGraph’s Python API within our script to run a SPARQL query and return it as a Pandas dataframe. When running this script within Power BI Desktop, the Python scripting service recognizes all unique dataframes created, and allows you to import the dataframe into Power BI as a table, which can then be used to create visualizations. Requirements: 1. You must have the AllegroGraph Python API installed. If you do not, installation instructions are here: https://franz.com/agraph/support/documentation/current/p ython/install.html 2. Python scripting must be enabled in Power BI Desktop. Instructions to do so are here: https://docs.microsoft.com/en-us/power-bi/connect-data/d esktop-python-scripts a) As mentioned in the article, pandas and matplotlib must be installed. This can be done with ‘pip install pandas’ and ‘pip install matplotlib’ in your terminal. -

Practical Semantic Web and Linked Data Applications
Practical Semantic Web and Linked Data Applications Common Lisp Edition Uses the Free Editions of Franz Common Lisp and AllegroGraph Mark Watson Copyright 2010 Mark Watson. All rights reserved. This work is licensed under a Creative Commons Attribution-Noncommercial-No Derivative Works Version 3.0 United States License. November 3, 2010 Contents Preface xi 1. Getting started . xi 2. Portable Common Lisp Code Book Examples . xii 3. Using the Common Lisp ASDF Package Manager . xii 4. Information on the Companion Edition to this Book that Covers Java and JVM Languages . xiii 5. AllegroGraph . xiii 6. Software License for Example Code in this Book . xiv 1. Introduction 1 1.1. Who is this Book Written For? . 1 1.2. Why a PDF Copy of this Book is Available Free on the Web . 3 1.3. Book Software . 3 1.4. Why Graph Data Representations are Better than the Relational Database Model for Dealing with Rapidly Changing Data Requirements . 4 1.5. What if You Use Other Programming Languages Other Than Lisp? . 4 2. AllegroGraph Embedded Lisp Quick Start 7 2.1. Starting AllegroGraph . 7 2.2. Working with RDF Data Stores . 8 2.2.1. Creating Repositories . 9 2.2.2. AllegroGraph Lisp Reader Support for RDF . 10 2.2.3. Adding Triples . 10 2.2.4. Fetching Triples by ID . 11 2.2.5. Printing Triples . 11 2.2.6. Using Cursors to Iterate Through Query Results . 13 2.2.7. Saving Triple Stores to Disk as XML, N-Triples, and N3 . 14 2.3. AllegroGraph’s Extensions to RDF . -
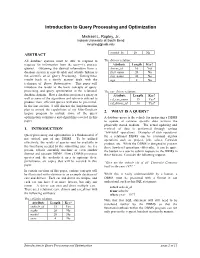
Introduction to Query Processing and Optimization
Introduction to Query Processing and Optimization Michael L. Rupley, Jr. Indiana University at South Bend [email protected] owned_by 10 No ABSTRACT All database systems must be able to respond to The drivers relation: requests for information from the user—i.e. process Attribute Length Key? queries. Obtaining the desired information from a driver_id 10 Yes database system in a predictable and reliable fashion is first_name 20 No the scientific art of Query Processing. Getting these last_name 20 No results back in a timely manner deals with the age 2 No technique of Query Optimization. This paper will introduce the reader to the basic concepts of query processing and query optimization in the relational The car_driver relation: database domain. How a database processes a query as Attribute Length Key? well as some of the algorithms and rule-sets utilized to cd_car_name 15 Yes* produce more efficient queries will also be presented. cd_driver_id 10 Yes* In the last section, I will discuss the implementation plan to extend the capabilities of my Mini-Database Engine program to include some of the query 2. WHAT IS A QUERY? optimization techniques and algorithms covered in this A database query is the vehicle for instructing a DBMS paper. to update or retrieve specific data to/from the physically stored medium. The actual updating and 1. INTRODUCTION retrieval of data is performed through various “low-level” operations. Examples of such operations Query processing and optimization is a fundamental, if for a relational DBMS can be relational algebra not critical, part of any DBMS. To be utilized operations such as project, join, select, Cartesian effectively, the results of queries must be available in product, etc. -

Gábor Melis to Keynote European Lisp Symposium
Gábor Melis to Keynote European Lisp Symposium OAKLAND, Calif. — April 14, 2014 —Franz Inc.’s Senior Engineer, Gábor Melis, will be a keynote speaker at the 7th annual European Lisp Symposium (ELS’14) this May in Paris, France. The European Lisp Symposium provides a forum for the discussion and dissemination of all aspects of design, implementationand application of any of the Lisp and Lisp- inspired dialects, including Common Lisp, Scheme, Emacs Lisp, AutoLisp, ISLISP, Dylan, Clojure, ACL2, ECMAScript, Racket, SKILL, Hop etc. Sending Beams into the Parallel Cube A pop-scientific look through the Lisp lens at machine learning, parallelism, software, and prize fighting We send probes into the topic hypercube bounded by machine learning, parallelism, software and contests, demonstrate existing and sketch future Lisp infrastructure, pin the future and foreign arrays down. We take a seemingly random walk along the different paths, watch the scenery of pairwise interactions unfold and piece a puzzle together. In the purely speculative thread, we compare models of parallel computation, keeping an eye on their applicability and lisp support. In the the Python and R envy thread, we detail why lisp could be a better vehicle for scientific programming and how high performance computing is eroding lisp’s largely unrealized competitive advantages. Switching to constructive mode, a basic data structure is proposed as a first step. In the machine learning thread, lisp’s unparalleled interactive capabilities meet contests, neural networks cross threads and all get in the way of the presentation. Video Presentation About Gábor Melis Gábor Melis is a consultant at Franz Inc. -

Query Optimization for Dynamic Imputation
Query Optimization for Dynamic Imputation José Cambronero⇤ John K. Feser⇤ Micah J. Smith⇤ Samuel Madden MIT CSAIL MIT CSAIL MIT LIDS MIT CSAIL [email protected] [email protected] [email protected] [email protected] ABSTRACT smaller than the entire database. While traditional imputation Missing values are common in data analysis and present a methods work over the entire data set and replace all missing usability challenge. Users are forced to pick between removing values, running a sophisticated imputation algorithm over a tuples with missing values or creating a cleaned version of their large data set can be very expensive: our experiments show data by applying a relatively expensive imputation strategy. that even a relatively simple decision tree algorithm takes just Our system, ImputeDB, incorporates imputation into a cost- under 6 hours to train and run on a 600K row database. based query optimizer, performing necessary imputations on- Asimplerapproachmightdropallrowswithanymissing the-fly for each query. This allows users to immediately explore values, which can not only introduce bias into the results, but their data, while the system picks the optimal placement of also result in discarding much of the data. In contrast to exist- imputation operations. We evaluate this approach on three ing systems [2, 4], ImputeDB avoids imputing over the entire real-world survey-based datasets. Our experiments show that data set. Specifically,ImputeDB carefully plans the placement our query plans execute between 10 and 140 times faster than of imputation or row-drop operations inside the query plan, first imputing the base tables. Furthermore, we show that resulting in a significant speedup in query execution while the query results from on-the-fly imputation differ from the reducing the number of dropped rows. -

Evaluation of Current RDF Database Solutions
Evaluation of Current RDF Database Solutions Florian Stegmaier1, Udo Gr¨obner1, Mario D¨oller1, Harald Kosch1 and Gero Baese2 1 Chair of Distributed Information Systems University of Passau Passau, Germany [email protected] 2 Corporate Technology Siemens AG Munich, Germany [email protected] Abstract. Unstructured data (e.g., digital still images) is generated, distributed and stored worldwide at an ever increasing rate. In order to provide efficient annotation, storage and search capabilities among this data and XML based description formats, data stores and query languages have been introduced. As XML lacks on expressing semantic meanings and coherences, it has been enhanced by the Resource Descrip- tion Format (RDF) and the associated query language SPARQL. In this context, the paper evaluates currently existing RDF databases that support the SPARQL query language by the following means: gen- eral features such as details about software producer and license infor- mation, architectural comparison and efficiency comparison of the inter- pretation of SPARQL queries on a scalable test data set. 1 Introduction The production of unstructured data especially in the multimedia domain is overwhelming. For instance, recent studies3 report that 60% of today's mobile multimedia devices equipped with an image sensor, audio support and video playback have basic multimedia functionalities, almost nine out of ten in the year 2011. In this context, the annotation of unstructured data has become a necessity in order to increase retrieval efficiency during search. In the last couple of years, the Extensible Markup Language (XML) [16], due to its interoperability features, has become a de-facto standard as a basis for the use of description formats in various domains. -

Scalable Query Optimization for Efficient Data Processing Using
1 Scalable Query Optimization for Efficient Data Processing using MapReduce Yi Shan #1, Yi Chen 2 # School of Computing, Informatics, and Decision Systems Engineering, Arizona State University, Tempe, AZ, USA School of Management, New Jersey Institute of Technology, Newark, NJ, USA 1 [email protected] 2 [email protected] 1#*#!2_ Abstract—MapReduce is widely acknowledged by both indus- $0-+ --- try and academia as an effective programming model for query 5�# 0X0,"0X0,"0X0 processing on big data. It is crucial to design an optimizer which finds the most efficient way to execute an SQL query using Fig. 1. Query Q1 MapReduce. However, existing work in parallel query processing either falls short of optimizing an SQL query using MapReduce '8#/ '8#/ or the time complexity of the optimizer it uses is exponential. Also, industry solutions such as HIVE, and YSmart do not '8#/ optimize the join sequence of an SQL query and cannot guarantee '8#/ '8#/ '8#/ an optimal execution plan. In this paper, we propose a scalable '8#/ optimizer for SQL queries using MapReduce, named SOSQL. '8#/ Experiments performed on Google Cloud Platform confirmed '8#/ the scalability and efficiency of SOSQL over existing work. '8#/ '8#/ '8#/ '8#/ '8#/ (a) QP1 (b) QP2 I. INTRODUCTION Fig. 2. Query Plans of Query Q1 It becomes increasingly important to process SQL queries further generates a query execution plan consisting of three on big data. Query processing consists of two parts: query parallel jobs, one for each binary join operation, as illustrated optimization and query execution. The query optimizer first in Figure 3(a). -

Query Optimization
Query Optimization Query Processing: Query processing refers to activities including translation of high level languages (HLL) queries into operations at physical file level, query optimization transformations, and actual evaluation of queries. Steps in Query Processing: Function of query parser is parsing and translation of HLL query into its immediate form relation algebraic expression. A parse tree of the query is constructed and then translated in to relational algebraic expression. Example: consider the following SQL query: SELECT s.name FROM reserves R, sailors S Where R.sid=S.sid AND R.bid=100 And S.rating>5 Its corresponding relational algebraic expression Query Optimization : Query optimization is the process of selecting an efficient execution plan for evaluating the query. After parsing of the query, parsed query is passed to query optimizer, which generates different execution plans to evaluate parsed query and select the plan with least estimated cost. Catalog manager helps optimizer to choose best plan to execute query generating cost of each plan. Query optimization is used for accessing the database in an efficient manner. It is an art of obtaining desired information in a predictable, reliable and timely manner. Formally defines query optimization as a process of transforming a query into an equivalent form which can be evaluated more efficiently. The essence of query optimization is to find an execution plan that minimizes time needed to evaluate a query. To achieve this optimization goal, we need to accomplish two main tasks. First one is to find out the best plan and the second one is to reduce the time involved in executing the query plan.