Rocket Universe NLS Guide
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Run-Commands-Windows-10.Pdf
Run Commands Windows 10 by Bettertechtips.com Command Action Command Action documents Open Documents Folder devicepairingwizard Device Pairing Wizard videos Open Videos Folder msdt Diagnostics Troubleshooting Wizard downloads Open Downloads Folder tabcal Digitizer Calibration Tool favorites Open Favorites Folder dxdiag DirectX Diagnostic Tool recent Open Recent Folder cleanmgr Disk Cleanup pictures Open Pictures Folder dfrgui Optimie Drive devicepairingwizard Add a new Device diskmgmt.msc Disk Management winver About Windows dialog dpiscaling Display Setting hdwwiz Add Hardware Wizard dccw Display Color Calibration netplwiz User Accounts verifier Driver Verifier Manager azman.msc Authorization Manager utilman Ease of Access Center sdclt Backup and Restore rekeywiz Encryption File System Wizard fsquirt fsquirt eventvwr.msc Event Viewer calc Calculator fxscover Fax Cover Page Editor certmgr.msc Certificates sigverif File Signature Verification systempropertiesperformance Performance Options joy.cpl Game Controllers printui Printer User Interface iexpress IExpress Wizard charmap Character Map iexplore Internet Explorer cttune ClearType text Tuner inetcpl.cpl Internet Properties colorcpl Color Management iscsicpl iSCSI Initiator Configuration Tool cmd Command Prompt lpksetup Language Pack Installer comexp.msc Component Services gpedit.msc Local Group Policy Editor compmgmt.msc Computer Management secpol.msc Local Security Policy: displayswitch Connect to a Projector lusrmgr.msc Local Users and Groups control Control Panel magnify Magnifier -
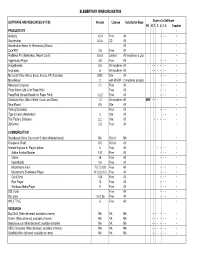
Elementary Windows Matrix
ELEMENTARY WINDOWS MATRIX SOFTWARE AND RESOURCES 8/17/05 Version License Installation Base Access to Software PK K 1 2 3 4 5 Teacher PRODUCTIVITY • Audacity 1.2.4 Free All • • • • Boardmaker 5.3.6 CD All • Boardmaker Addon for Elementary Schools All • Cute PDF 2.6 Free All • FileMaker Pro (Networked, Report Cards) 5.0v3 Limited AV machines & Lab • Hyperstudio Player 4.5 Free All • • • • ImageBlender 2.5 All machines All • • • • • • • • Inspiration 8 All machines All • • • • • • • Microsoft Office (Word, Excel, Access, PP, Publisher) 2000 Site All • • • • MovieMaker 2 with WinXP 2 machines on carts • Netscape Composer 7.1 Free All • • • • Photo Album add-in for PowerPoint Free All • • • • PowerTalk (Screen Reader for Power Point) 1.2.2 Free All • • • • Scholastic Keys (Max's Write, Count, and Show) 1.2 All machines All MW • • • • SmartBoard 9.5 Site All • Talking Calculator Free All • • • • Type to Learn (Networked) 3 Site All • • • Tool Factory Database 2.2 Site All • • • • • • ZipCentral 2.6 Free All • COMMUNICATION Blackboard Online Classroom Builder (Web-delivered) NA District NA • Groupwise Client 6.5 District All • Internet Explorer w. Plugins below: 6 Free All • • • • • Adobe Acrobat Reader 7.07 Free All • • • • Chime v6 Free All • • • • HyperStudio 4.5 Free All Macromedia Flash 7 (7.0.19.0) Free All • • • • Macromedia Shockwave Player 10 (0.0.21.0) Free All • • • • QuickTime 7.04 Free All • • • • Real Player 10 Free All • • • • Windows Media Player 9 Free All • • • • SOL Fonts Free All • • • • Sun Java 1.5.0_06 Free All • • • • -

Document Preparation in Classical Languages
4.2. Operating System Support: Windows tional language is not the same as anging the language of the user interface. If you want all your menus and so forth in German, that is an additional step. Additional Keyboard Resources Tom Gewee has created keyboards for many languages in addition to those provided by OS X. ey can be found at http://homepage. mac.com/thgewecke/tckbs.html. He also has a general “Multilin- gual Mac” page at http://homepage.mac.com/thgewecke/mlingos9. html and a blog at http://m10lmac.blogspot.com/, both of whi are excellent sources of information about using the Mac OS when writ- ing in languages other than English. ird-party Utilities You can use third-party utilities su as the well known PopChar to e out and enter aracters; see http://www.macility.com/ products/popcharx/), where a demo version is available. e Unicode Cheer utility from earthlingso does a few things that Character Palee doesn’t, su as convert Unicode values to HTML entities or help with normalization issues. In some ways it is more convenient than the Character Palee. See http://earthlingsoft. net/UnicodeChecker/index.html. See also the discussion of GreekKeys in §7.3, page 131. Warning for Mac Users! Be careful not to log out while using a keyboard that does not allow you to enter your password in order to get ba in — for example, logging out when a Hebrew or Greek keyboard is in effect if your password requires Latin aracters. SAMPLE4.2 Operating System Support: Windows -key Methods Windows, by contrast, provides two system-wide methods for access- ing non-English aracters, both of them clumsy. -

Copyrighted Material
18_579274 bindex.qxd 2/22/05 7:41 PM Page 312 Index A C accounts call waiting, dial-up account setup, 196 computer administrator, 157 cascade windows, 35 create, 156–157 CD Writing Wizard, 143 delete, 166–167 CDs Internet connection, manual setup, 194–197 backups to, 289 limited user, 157 burn music to, 124–125 name changes, 160–161 copy files to, 140–143 name restrictions, 161 music, Media Player and, 112–115, 120–123 passwords, 162–163 program installation, 18 picture change, 164–165 rip with Media Player, 120–121 sharing and, 155 view files, 135 switch between, 158–159 Character Map, special symbols, 62–63 User Accounts window, 154–155 check boxes, dialog boxes, 26 Welcome screen, 4 circles (Paint), 91 Activate Windows screen, 12–13 click mouse, 8–9 activate Windows XP, 12–13 close button, 23 Add or Remove Programs close windows, 33 installation and, 19 color uninstall programs, 40–41 background, 253 address bar (Internet Explorer), 206 custom, 256–257 Address Book (Outlook Express), 226–227 color box (Paint) addresses, Web, 204, 208–209 color selection, 99 airbrush freehand drawing (Paint), 96 eraser, 101 All Programs menu, 22 introduction, 86 Appearances and Themes, Display Properties and, 250–251 replace color, 101 attachments to e-mail (Outlook Express), 230-231, 240–241 color fills (Paint), 97 audio, play in Media Player, 110 combo boxes automatic updates, 280–281 dialog boxes, 26 item selection, 29 command buttons, dialog boxes, 27 B compressed folders, extract files, 150–151 Background, 252–253 computer administrator account, 157 Backup or Restore Wizard, 286–289 configuration, startup and, 4 Backup program, 286–287 connections, Internet. -

Improved Correlation Attacks on SOSEMANUK and SOBER-128
Improved Correlation Attacks on SOSEMANUK and SOBER-128 Joo Yeon Cho Helsinki University of Technology Department of Information and Computer Science, Espoo, Finland 24th March 2009 1 / 35 SOSEMANUK Attack Approximations SOBER-128 Outline SOSEMANUK Attack Method Searching Linear Approximations SOBER-128 2 / 35 SOSEMANUK Attack Approximations SOBER-128 SOSEMANUK (from Wiki) • A software-oriented stream cipher designed by Come Berbain, Olivier Billet, Anne Canteaut, Nicolas Courtois, Henri Gilbert, Louis Goubin, Aline Gouget, Louis Granboulan, Cedric` Lauradoux, Marine Minier, Thomas Pornin and Herve` Sibert. • One of the final four Profile 1 (software) ciphers selected for the eSTREAM Portfolio, along with HC-128, Rabbit, and Salsa20/12. • Influenced by the stream cipher SNOW and the block cipher Serpent. • The cipher key length can vary between 128 and 256 bits, but the guaranteed security is only 128 bits. • The name means ”snow snake” in the Cree Indian language because it depends both on SNOW and Serpent. 3 / 35 SOSEMANUK Attack Approximations SOBER-128 Overview 4 / 35 SOSEMANUK Attack Approximations SOBER-128 Structure 1. The states of LFSR : s0,..., s9 (320 bits) −1 st+10 = st+9 ⊕ α st+3 ⊕ αst, t ≥ 1 where α is a root of the primitive polynomial. 2. The Finite State Machine (FSM) : R1 and R2 R1t+1 = R2t ¢ (rtst+9 ⊕ st+2) R2t+1 = Trans(R1t) ft = (st+9 ¢ R1t) ⊕ R2t where rt denotes the least significant bit of R1t. F 3. The trans function Trans on 232 : 32 Trans(R1t) = (R1t × 0x54655307 mod 2 )≪7 4. The output of the FSM : (zt+3, zt+2, zt+1, zt)= Serpent1(ft+3, ft+2, ft+1, ft)⊕(st+3, st+2, st+1, st) 5 / 35 SOSEMANUK Attack Approximations SOBER-128 Previous Attacks • Authors state that ”No linear relation holds after applying Serpent1 and there are too many unknown bits...”. -

A History of Syntax Isaac Quinn Dupont Facult
Proceedings of the 2011 Great Lakes Connections Conference—Full Papers Email: A History of Syntax Isaac Quinn DuPont Faculty of Information University of Toronto [email protected] Abstract the arrangement of word tokens in an appropriate Email is important. Email has been and remains a (orderly) manner for processing by computers. Per- “killer app” for personal and corporate correspond- haps “computers” refers to syntactical processing, ence. To date, no academic or exhaustive history of making my definition circular. So be it, I will hide email exists, and likewise, very few authors have behind the engineer’s keystone of pragmatism. Email attempted to understand critical issues of email. This systems work (usually), because syntax is arranged paper explores the history of email syntax: from its such that messages can be passed. origins in time-sharing computers through Request This paper demonstrates the centrality of for Comments (RFCs) standardization. In this histori- syntax to the history of email, and investigates inter- cal capacity, this paper addresses several prevalent esting socio–technical issues that arise from the par- historical mistakes, but does not attempt an exhaus- ticular development of email syntax. Syntax is an tive historiography. Further, as part of the rejection important constraint for contemporary computers, of “mainstream” historiographical methodologies this perhaps even a definitional quality. Additionally, as paper explores a critical theory of email syntax. It is machines, computers are physically constructed. argued that the ontology of email syntax is material, Thus, email syntax is material. This is a radical view but contingent and obligatory—and in a techno– for the academy, but (I believe), unproblematic for social assemblage. -

On Distinguishing Attack Against the Reduced Version of the Cipher Nlsv2
Ø Ñ ÅØÑØÐ ÈÙ ÐØÓÒ× DOI: 10.2478/v10127-012-0037-5 Tatra Mt. Math. Publ. 53 (2012), 21–32 ON DISTINGUISHING ATTACK AGAINST THE REDUCED VERSION OF THE CIPHER NLSV2 Michal Braˇsko — Jaroslav Boor ABSTRACT. The Australian stream cipher NLSv2 [Hawkes, P.—Paddon, M.– –Rose, G. G.—De Vries, M. W.: Primitive specification for NLSv2, Project eSTREAM web page, 2007, 1–25] is a 32-bit word oriented stream cipher that was quite successful in the stream ciphers competition—the project eSTREAM. The cipher achieved Phase 3 and successfully accomplished one of the main require- ments for candidates in Profile 1 (software oriented proposals)—to have a better performance than AES in counter mode. However the cipher was not chosen into the final portfolio [Babbage, S.–De Canni`ere, Ch.–Canteaut, A.–Cid, C.– –Gilbert, H.–Johansson, T.–Parker, M.–Preneel, B.–Rijmen, V.–Robshaw, M.: The eSTREAM Portfolio, Project eSTREAM web page, 2008], because its per- formance was not so perfect when comparing with other finalist. Also there is a security issue with a high correlation in the used S-Box, which some effective distinguishers exploit. In this paper, a practical demonstration of the distinguish- ing attack against the smaller version of the cipher is introduced. In our experi- ments, we have at disposal a machine with four cores (IntelR CoreTM Quad @ 2.66 GHz) and single attack lasts about 6 days. We performed successful practi- cal experiments and our results demonstrate that the distingushing attack against the smaller version is working. 1. Introduction The cipher NLSv2 is a synchronous, word-oriented stream cipher developed by Australian researchers P h i l i p H a w k e s, C a m e r o n M c D o n a l d, M i - chael Paddon,Gregory G.Rose andMiriam Wiggers de Vreis in 2007 [6]. -
| Independent Consultant Logo
| INDEPENDENT CONSULTANT LOGO PRIMARY LOGO PRIMARY TWO-TONE HEXAGON LOGO The Scentsy Independent Consultant logo can be used by Consultants on their personal printed materials and websites to promote their business. The space between the elements within the logo should not be modified. The logo should always appear upright, with clearance on either side and clearance on the top and bottom equal to the height of the lower case “S” character as it’s used in the sized logo (see example). SPECIAL NOTE: If you need a two colour option for this logo, use Pantone 522 to replace the 80% screen. Pantone 519 Pantone 519 — 80% C 60 M 100 Y 0 K 40 C 45 M 57 Y 23 K 6 #5c305e #8f7290 7/22/15 SCENTSY CONSULTANT STYLE GUIDE 1 | FONT - INDEPENDENT CONSULTANT LOGO TYPE The logo displays the company name in the Scentsy Spirit font, and the accompanying type in Knockout-HTF34-Junior Sumo. No other fonts should be used to alter Scentsy Spirit the look of the Scentsy Independent Consultant logo. 1234567890!@#$%^&*()_=+ ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz Knockout-HTF34-JuniorSumo 1234567890!@#$%^&*()_=+ ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz 7/22/15 SCENTSY CONSULTANT STYLE GUIDE 2 | INDEPENDENT CONSULTANT LOGO SECONDARY LOGO OPTIONS ONE-COLOUR HEXAGON LOGO ONE-COLOUR LOGO + STAR TRIO The following secondary logos may be used on specific Scentsy Family Store materials and by Scentsy Consultants to promote their personal business. The space between the elements within the secondary logos should not be modified. The logos should always appear upright, with clearance on either side and clearance on the top and bottom equal to the height of the lower case “S” character as it’s used in the sized logo. -

SAC 2006 Preliminary Program Wednesday August 16, 2006
SAC 2006 Preliminary Program All events, except the Banquet, are held at the EV building (1515 St. Catherine W.) All the presentations will be held at EV2.260 The Wednesday reception will be held at EV2.184 The board meeting (open only to board members) will be held at EV9.221 Wednesday August 16, 2006 18:30-20:00 Light social reception (EV2.184) Thursday August 17, 2006 08:00 Registration and Morning Coffee 08:50-09:00 Welcome Remarks Block Cipher Cryptanalysis Chair: Bart Preneel 09:25-09:50 Improved DST Cryptanalysis of IDEA Eyup Serdar Ayaz, Ali Aydin Selcuk 09:50-10:15 Improved Related-Key Impossible Differential Attacks on Reduced-Round AES-192 Wentao Zhang, Wenling Wu, Lei Zhang, Dengguo Feng 09:00-09:25 Related-Key Rectangle Attack on the Full SHACAL-1 Orr Dunkelman, Nathan Keller, Jongsung Kim 10:15-10:45 Coffee Break Stream Cipher Cryptanalysis I Chair: Helena Handschuh 10:45-11:10 Cryptanalysis of Achterbahn-Version 2 Martin Hell, Thomas Johansson 11:10-11:35 Cryptanalysis of the Stream Cipher ABC v2 Hongjun Wu, Bart Preneel Invited Talk I: The Stafford Tavares Lecture Chair: Eli Biham 11:35-12:30 A Top View of Side Channels Adi Shamir 12:30-14:00 Lunch (EV2.184) Block and Stream Ciphers Chair: Orr Dunkelman 14:00-14:25 The Design of a Stream Cipher Lex Alex Biryukov 14:25-14:50 Dial C for Cipher Thomas Baignères, Matthieu Finiasz 14:50-15:15 Tweakable Block Cipher Revisited Kazuhiko Minematsu 15:15-15:45 Coffee Break Side-Channel Attacks Chair: Carlisle Adams 15:45-16:10 Extended Hidden Number Problem and its Cryptanalytic -

A Records, 244–245, 279 -A Switch in Nbtstat, 190 in Netstat, 186 AAS Deployment Package, 710 .Aas Extension, 712 Abstract
22_InsideWin_Index 13/3/03 9:50 AM Page 1269 Index A A records, 244–245, 279 ACEs (Access Control Entries) -a switch access masks in, 568–570 in Nbtstat, 190 command-line tools for, 572–576 in Netstat, 186 for cumulative permissions, 577 AAS deployment package, 710 for deny permissions, 578 .aas extension, 712 inheritance in, 579–580, 725–728 Abstract classes, 299–300 object ownership in, 572 Accelerated Graphics Port (AGP) adapters, 164 viewing and modifying, 570–571 Access Control Entries. See ACEs (Access ACKs in DHCP, 101–102 Control Entries) ACL Editor, 570, 723 Access control lists (ACLs) Advanced view in Active Directory security, 732–734 for inheritance, 578, 581 objects in, 339 for ownership, 572 in security descriptors, 559 for special permissions, 723–724 Access Control Settings window, 728 Edit view, 725–726 Access masks for permissions inheritance, 578 in ACEs, 568–570 blocking, 579 in DSOs, 733 settings for, 581 Access requests in Kerberos, 621 viewings, 582 Access rights. See also Permissions ACLs (access control lists) in Active Directory security in Active Directory security, 732–734 delegation, 729–732 objects in, 339 types of, 724–725 in security descriptors, 559 for group policies, 682 ACPI (Advanced Configuration and Power Access tokens Interface) contents of, 560–561 compatibility of, 23–28, 148–149 local, 559 kernel version for, 135 SIDs in, 559, 561, 581 for PnP,17, 147–149 ACCM (Asynchronous-Control- ACPIEnable option, 149 Character-Map), 1124 Activation Account domain upgrades, 496–498 in IA64, 130 BDC, 494–496 in installation, 49–50 PDC, 490–493 unattended setup scripts for, 95 Account lockout policies Active Directory, 238 in domain design, 429 bulk imports and exports in, 353–356 in password security, 593–594 DNS deployment in, 242–243 Account logons, auditing, 647 DNS integration in, 238–239 Account management, auditing, 511, 648 dynamic updates, 244–245 Accounts in domain migration. -

ISDN Configuration Wizard Charmap
Windows Commands and Shortcuts Commands calc - Calculator cfgwiz32 - ISDN Configuration Wizard charmap - Character Map chkdisk - Repair damaged files cleanmgr - Cleans up hard drives clipbrd - Windows Clipboard viewer cmd - Opens a new Command Window (cmd.exe) control - Displays Control Panel dcomcnfg - DCOM user security debug - Assembly language programming tool defrag - Defragmentation tool drwatson - Records programs crash & snapshots dxdiag - DirectX Diagnostic Utility explorer - Windows Explorer fontview - Graphical font viewer ftp - ftp.exe program hostname - Returns Computer's name ipconfig - Displays IP configuration for all network adapters jview - Microsoft Command-line Loader for Java classes MMC - Microsoft Management Console msconfig - Configuration to edit startup files msinfo32 - Microsoft System Information Utility nbtstat - Displays stats and current connections using NetBios over TCP/IP netstat - Displays all active network connections nslookup - Returns your local DNS server odbcad32 - ODBC Data Source Administrator ping - Sends data to a specified host/IP regedit - registry Editor regsvr32 - register/de-register DLL/OCX/ActiveX regwiz - Reistration wizard sfc /scannow - Sytem File Checker sndrec32 - Sound Recorder sndvol32 - Volume control for soundcard sysedit - Edit system startup files (config.sys, autoexec.bat, win.ini, etc.) systeminfo - display various system information in text console taskmgr - Task manager telnet - Telnet program taskkill - kill processes using command line interface tskill - reduced version -

3 the Windows Files
Chapter 3 The Windows Files A question that technical people often ask about Microsoft Windows is: What does this file do? This chapter describes the purpose for each file in the WINDOWS directory and the SYSTEM subdirectory. For information about how to add to the list of files that are installed automatically with Windows, see “Modifying . INF Files for Custom Installations” in Chapter 2, “The Windows Setup Information Files.” Related information ••• Windows Resource Kit: Chapter 2, “The Windows Setup Information Files”; Chapter 4, “The Windows Initialization Files”; Appendix C, “Windows 3.1 Disks and Files” ••• Glossary terms: code page, EMS , XMS , protected mode, virtual device Contents of this chapter About the Windows Files .................................................................................136 WIN.COM ..........................................................................................................136 The Core Files ..................................................................................................137 Drivers, Fonts, and International Support Files................................................137 Driver Files................................................................................................137 Font Files...................................................................................................144 International Support Files ........................................................................147 MS-DOS Support Components of Windows .....................................................148