Deducing Chemical Structure from Crystallographically Determined
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
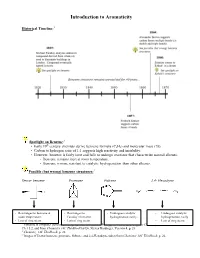
Introduction to Aromaticity
Introduction to Aromaticity Historical Timeline:1 Spotlight on Benzene:2 th • Early 19 century chemists derive benzene formula (C6H6) and molecular mass (78). • Carbon to hydrogen ratio of 1:1 suggests high reactivity and instability. • However, benzene is fairly inert and fails to undergo reactions that characterize normal alkenes. - Benzene remains inert at room temperature. - Benzene is more resistant to catalytic hydrogenation than other alkenes. Possible (but wrong) benzene structures:3 Dewar benzene Prismane Fulvene 2,4- Hexadiyne - Rearranges to benzene at - Rearranges to - Undergoes catalytic - Undergoes catalytic room temperature. Faraday’s benzene. hydrogenation easily. hydrogenation easily - Lots of ring strain. - Lots of ring strain. - Lots of ring strain. 1 Timeline is computer-generated, compiled with information from pg. 594 of Bruice, Organic Chemistry, 4th Edition, Ch. 15.2, and from Chemistry 14C Thinkbook by Dr. Steven Hardinger, Version 4, p. 26 2 Chemistry 14C Thinkbook, p. 26 3 Images of Dewar benzene, prismane, fulvene, and 2,4-Hexadiyne taken from Chemistry 14C Thinkbook, p. 26. Kekulé’s solution: - “snake bites its own tail” (4) Problems with Kekulé’s solution: • If Kekulé’s structure were to have two chloride substituents replacing two hydrogen atoms, there should be a pair of 1,2-dichlorobenzene isomers: one isomer with single bonds separating the Cl atoms, and another with double bonds separating the Cl atoms. • These isomers were never isolated or detected. • Rapid equilibrium proposed, where isomers interconvert so quickly that they cannot be isolated or detected. • Regardless, Kekulé’s structure has C=C’s and normal alkene reactions are still expected. - But the unusual stability of benzene still unexplained. -

On the Harmonic Oscillator Model of Electron Delocalization (HOMED) Index and Its Application to Heteroatomic Π-Electron Systems
Symmetry 2010, 2, 1485-1509; doi:10.3390/sym2031485 OPEN ACCESS symmetry ISSN 2073-8994 www.mdpi.com/journal/symmetry Article On the Harmonic Oscillator Model of Electron Delocalization (HOMED) Index and its Application to Heteroatomic π-Electron Systems Ewa D. Raczyñska 1, *, Małgorzata Hallman 1, Katarzyna Kolczyñska 2 and Tomasz M. Stêpniewski 2 1 Department of Chemistry, Warsaw University of Life Sciences (SGGW), ul. Nowoursynowska 159c, 02-776 Warszawa, Poland 2 Interdisciplinary Department of Biotechnology, Warsaw University of Life Sciences (SGGW), ul. Nowoursynowska 166, 02-776 Warszawa, Poland * Author to whom correspondence should be addressed; E-Mail: [email protected]; Tel.: +48-22-59-37623; Fax: +49-22-59-37635. Received: 23 April 2010; in revised form: 19 May 2010 / Accepted: 7 July 2010 / Published: 12 July 2010 Abstract: The HOMA (Harmonic Oscillator Model of Aromaticity) index, reformulated in 1993, has been very often applied to describe π-electron delocalization for mono- and polycyclic π-electron systems. However, different measures of π-electron delocalization were employed for the CC, CX, and XY bonds, and this index seems to be inappropriate for compounds containing heteroatoms. In order to describe properly various resonance effects (σ-π hyperconjugation, n-π conjugation, π-π conjugation, and aromaticity) possible for heteroatomic π-electron systems, some modifications, based on the original HOMA idea, were proposed and tested for simple DFT structures containing C, N, and O atoms. An abbreviation HOMED was used for the modified index. Keywords: geometry-based index; π -electron delocalization; σ - π hyperconjugation; n-π conjugation; π-π conjugation; aromaticity; heteroatomic compounds; DFT 1. -

Aromaticity Sem- Ii
AROMATICITY SEM- II In 1931, German chemist and physicist Sir Erich Hückel proposed a theory to help determine if a planar ring molecule would have aromatic properties .This is a very popular and useful rule to identify aromaticity in monocyclic conjugated compound. According to which a planar monocyclic conjugated system having ( 4n +2) delocalised (where, n = 0, 1, 2, .....) electrons are known as aromatic compound . For example: Benzene, Naphthalene, Furan, Pyrrole etc. Criteria for Aromaticity 1) The molecule is cyclic (a ring of atoms) 2) The molecule is planar (all atoms in the molecule lie in the same plane) 3) The molecule is fully conjugated (p orbitals at every atom in the ring) 4) The molecule has 4n+2 π electrons (n=0 or any positive integer Why 4n+2π Electrons? According to Hückel's Molecular Orbital Theory, a compound is particularly stable if all of its bonding molecular orbitals are filled with paired electrons. - This is true of aromatic compounds, meaning they are quite stable. - With aromatic compounds, 2 electrons fill the lowest energy molecular orbital, and 4 electrons fill each subsequent energy level (the number of subsequent energy levels is denoted by n), leaving all bonding orbitals filled and no anti-bonding orbitals occupied. This gives a total of 4n+2π electrons. - As for example: Benzene has 6π electrons. Its first 2π electrons fill the lowest energy orbital, and it has 4π electrons remaining. These 4 fill in the orbitals of the succeeding energy level. The criteria for Antiaromaticity are as follows: 1) The molecule must be cyclic and completely conjugated 2) The molecule must be planar. -

Aromaticity in Polyhydride Complexes of Ru, Ir, Os, and Pt† Cite This: DOI: 10.1039/C5cp04330a Elisa Jimenez-Izala and Anastassia N
PCCP View Article Online PAPER View Journal r-Aromaticity in polyhydride complexes of Ru, Ir, Os, and Pt† Cite this: DOI: 10.1039/c5cp04330a Elisa Jimenez-Izala and Anastassia N. Alexandrova*ab Transition-metal hydrides represent a unique class of compounds, which are essential for catalysis, organic i À i À synthesis, and hydrogen storage. In this work we study IrH5(PPh3)2,(RuH5(P Pr3)2) ,(OsH5(PPr3)2) ,and À OsH4(PPhMe2)3 polyhydride complexes, inspired by the recent discovery of the s-aromatic PtZnH5 cluster À anion. The distinctive feature of these molecules is that, like in the PtZnH5 cluster, the metal is five-fold Received 23rd July 2015, coordinated in-plane, and holds additional ligands attheaxialpositions.Thisworkshowsthattheunusual Accepted 17th September 2015 coordination in these compounds indeed can be explained by s-aromaticity in the pentagonal arrangement, DOI: 10.1039/c5cp04330a stabilized by the atomic orbitals on the metal. Based on this newly elucidated bonding principle, we additionally propose a new family of polyhydrides that display a uniquely high coordination. We also report the first www.rsc.org/pccp indications of how aromaticity may impact the reactivity of these molecules. 1 Introduction many catalytic cycles, where they have either been used as catalysts or invoked as key intermediates.15,16 Aromaticity in Aromaticity is a very important concept in the contemporary general is associated with high symmetry, stability, and specific chemistry: the particular electronic structure of aromatic reactivity. Therefore, the stability of transition-metal hydride systems, where electrons are delocalized, explains their large complexes might have an important repercussion in the kinetics energetic stabilization and low reactivity. -

Sc-Homoaromaticity
This is a repository copy of Modern Valence-Bond Description of Homoaromaticity. White Rose Research Online URL for this paper: https://eprints.whiterose.ac.uk/106288/ Version: Accepted Version Article: Karadakov, Peter Borislavov orcid.org/0000-0002-2673-6804 and Cooper, David L. (2016) Modern Valence-Bond Description of Homoaromaticity. Journal of Physical Chemistry A. pp. 8769-8779. ISSN 1089-5639 https://doi.org/10.1021/acs.jpca.6b09426 Reuse Items deposited in White Rose Research Online are protected by copyright, with all rights reserved unless indicated otherwise. They may be downloaded and/or printed for private study, or other acts as permitted by national copyright laws. The publisher or other rights holders may allow further reproduction and re-use of the full text version. This is indicated by the licence information on the White Rose Research Online record for the item. Takedown If you consider content in White Rose Research Online to be in breach of UK law, please notify us by emailing [email protected] including the URL of the record and the reason for the withdrawal request. [email protected] https://eprints.whiterose.ac.uk/ Modern Valence-Bond Description of Homoaromaticity Peter B. Karadakov; and David L. Cooper; Department of Chemistry, University of York, Heslington, York, YO10 5DD, U.K. Department of Chemistry, University of Liverpool, Liverpool L69 7ZD, U.K. Abstract Spin-coupled (SC) theory is used to obtain modern valence-bond (VB) descriptions of the electronic structures of local minimum and transition state geometries of three species that have been con- C sidered to exhibit homoconjugation and homoaromaticity: the homotropenylium ion, C8H9 , the C cycloheptatriene neutral ring, C7H8, and the 1,3-bishomotropenylium ion, C9H11. -

Synthesis and Reactivity of Cyclopentadienyl Based Organometallic Compounds and Their Electrochemical and Biological Properties
Synthesis and reactivity of cyclopentadienyl based organometallic compounds and their electrochemical and biological properties Sasmita Mishra Department of Chemistry National Institute of Technology Rourkela Synthesis and reactivity of cyclopentadienyl based organometallic compounds and their electrochemical and biological properties Dissertation submitted to the National Institute of Technology Rourkela In partial fulfillment of the requirements of the degree of Doctor of Philosophy in Chemistry by Sasmita Mishra (Roll Number: 511CY604) Under the supervision of Prof. Saurav Chatterjee February, 2017 Department of Chemistry National Institute of Technology Rourkela Department of Chemistry National Institute of Technology Rourkela Certificate of Examination Roll Number: 511CY604 Name: Sasmita Mishra Title of Dissertation: ''Synthesis and reactivity of cyclopentadienyl based organometallic compounds and their electrochemical and biological properties We the below signed, after checking the dissertation mentioned above and the official record book(s) of the student, hereby state our approval of the dissertation submitted in partial fulfillment of the requirements of the degree of Doctor of Philosophy in Chemistry at National Institute of Technology Rourkela. We are satisfied with the volume, quality, correctness, and originality of the work. --------------------------- Prof. Saurav Chatterjee Principal Supervisor --------------------------- --------------------------- Prof. A. Sahoo. Prof. G. Hota Member (DSC) Member (DSC) --------------------------- -

Aromaticity As a Guide to Planarity in Conjugated Molecules and Polymers Brandon M
pubs.acs.org/JPCC Article Aromaticity as a Guide to Planarity in Conjugated Molecules and Polymers Brandon M. Wood, Alexander C. Forse, and Kristin A. Persson* Cite This: https://dx.doi.org/10.1021/acs.jpcc.0c01064 Read Online ACCESS Metrics & More Article Recommendations *sı Supporting Information ABSTRACT: Conjugated molecules and polymers have the ability to be transformative semiconducting materials; however, to reach their full potential a detailed understanding of the factors governing the molecular structure is crucial for establishing design principles for improved materials. Creating planar or “locking” structures is of particular interest for tuning electronic properties. While noncovalent locks are an effective strategy for increasing planarity, the precise interactions leading to these planar structures are often unknown or mischaracterized. In this study, we demonstrate that aromaticity can be used to investigate, interpret, and modify the complex physical interactions which lead to planarity. Furthermore, we clearly illustrate the important role aromaticity has in determining the structure through torsional preferences and find that modern noncovalent locks utilize hyperconjugation to alter aromaticity and increase planarity. We envision that our approach and our explanation of prevalent noncovalent locks will assist in the design of improved materials for organic electronics. ■ INTRODUCTION Aromaticity is a common chemical descriptor that can be Organic semiconductors offer unique blends of physical and used to simplify some of the underlying physics and provide electronic properties along with the processability and novel insights into torsional energetics. A key objective of this fabrication potential of polymers and small molecules.1,2 This communication is to highlight how the competition between 10,19,20 fl combination opens up countless opportunities for new aromaticity and conjugation in uences planarity in functional materials that can be tailored for specific organic electronic materials. -
Hyperconjugative Aromaticity and Protodeauration Reactivity of Polyaurated Indoliums
ARTICLE https://doi.org/10.1038/s41467-019-13663-8 OPEN Hyperconjugative aromaticity and protodeauration reactivity of polyaurated indoliums Kui Xiao1, Yu Zhao2, Jun Zhu 2* & Liang Zhao 1* Aromaticity generally describes a cyclic structure composed of sp2-hybridized carbon or hetero atoms with remarkable stability and unique reactivity. The doping of even one sp3-hybridized atom often damages the aromaticity due to the interrupted electron con- 1234567890():,; jugation. Here we demonstrate the occurrence of an extended hyperconjugative aromaticity (EHA) in a metalated indole ring which contains two gem-diaurated tetrahedral carbon atoms. The EHA-involved penta-aurated indolium shows extended electron conjugation because of dual hyperconjugation. Furthermore, the EHA-induced low electron density on the indolyl nitrogen atom enables a facile protodeauration reaction for the labile Au-N bond. In contrast, the degraded tetra-aurated indolium with a single gem-dimetalated carbon atom exhibits poor bond averaging and inertness in the protodeauration reaction. The aromaticity difference in such two polyaurated indoliums is discussed in the geometrical and electronic perspectives. This work highlights the significant effect of metalation on the aromaticity of polymetalated species. 1 Key Laboratory of Bioorganic Phosphorus Chemistry and Chemical Biology (Ministry of Education), Department of Chemistry, Tsinghua University, 100084 Beijing, China. 2 State Key Laboratory of Physical Chemistry of Solid Surfaces and Collaborative Innovation Center -

Description of Aromaticity with the Help of Vibrational Spectroscopy: Anthracene and Phenanthrene Robert Kalescky, Elfi Kraka, and Dieter Cremer*
Article pubs.acs.org/JPCA Description of Aromaticity with the Help of Vibrational Spectroscopy: Anthracene and Phenanthrene Robert Kalescky, Elfi Kraka, and Dieter Cremer* Computational and Theoretical Chemistry Group (CATCO), Department of Chemistry, Southern Methodist University, 3215 Daniel Avenue, Dallas, Texas 75275-0314, United States *S Supporting Information ABSTRACT: A new approach is presented to determine π-delocalization and the degree of aromaticity utilizing measured vibrational frequencies. For this purpose, a perturbation approach is used to derive vibrational force constants from experimental frequencies and calculated normal mode vectors. The latter are used to determine the local counterparts of the vibrational modes. Next, relative bond strength orders (RBSO) are obtained from the local stretching force constants, which provide reliable descriptors of CC and CH bond strengths. Finally, the RBSO values for CC bonds are used to establish a modified harmonic oscillator model and an aromatic delocalization index AI, which is split into a bond weakening (strengthening) and bond alternation part. In this way, benzene, naphthalene, anthracene, and phenanthrene are described with the help of vibrational spectroscopy as aromatic systems with a slight tendency of peripheral π-delocalization. The 6.8 kcal/mol larger stability of phenanthrene relative to anthracene predominantly (84%) results from its higher resonance energy, which is a direct consequence of the topology of ring annelation. Previous attempts to explain the higher stability of phenanthrene via a maximum electron density path between the bay H atoms are misleading in view of the properties of the electron density distribution in the bay region. ■ INTRODUCTION NMR chemical shift of an atomic nucleus is also affected by more π ff − The description of the chemical bond is one of the major than just -delocalization e ects. -

Executive Summary of the Biodata of Dr. Eluvathingal D. Jemmis Education
Executive Summary of the Biodata of Dr. Eluvathingal D. Jemmis Education: Indian Institute of Technology Kanpur (MSc 1973); Princeton University (Ph.D.1978, with Profs Paul Schleyer and John Pople, 1998 Nobel Laureate). Employment: Cornell University (Research Associate 1978-80, with Prof Roald Hoffmann, 1981 Nobel Laureate). University of Hyderabad, India, Lecturer 1980; Reader 1984; Professor 1990; Indian Institute of Science, Bangalore, Professor 2005-2017, Hon Professor 2017-2022. Year of Science Chair Professor (SERB) 2019-2014. Institution Building; administrative engagements: Univ. of Hyderabad, Dean of the School, 2002-5. Established a Centre for Modeling Simulation and Design at the Univ. of Hyderabad in 2002, as a project grant from the Department of Science and Technology, New Delhi. (http://cmsd.uohyd.ac.in). Founding Director 2008-13, Indian Institute of Science Education and Research Thiruvananthapuram, a project of the Ministry of Human Resource Development, Govt of India, on a 5 year deputation from IISc Bangalore (http://www.iisertvm.ac.in). Member, International Board: WATOC, World Association of Theoretical and Computational Chemists; APATCC, Asia Pacific Association of Theoretical and Computational Chemists; IMEBORON, International Meeting on Boron Chemistry. Research: His research aims to bring general understanding of structure, bonding and reactions of molecules, clusters, and solids, using Quantum Chemistry, searching for transferable models from numbers. Transition metal organometallic reactions involving C-C fond formation, and C-H activation, structural chemistry boranes and of allotropes of elemental boron, generalization of Hydrogen-Bonds to similar weak interactions in main group and transition metal chemistry, three dimensional aromaticity, electron counting rules, broron equivalents of graphenes and fullerenes, and unusual structural variations in heavier main group elements are topics that have received particular attention in his laboratory. -

Why Aromaticity Is a Suspicious Concept? Why?
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Frontiers - Publisher Connector OPINION published: 24 March 2017 doi: 10.3389/fchem.2017.00022 Why Aromaticity Is a Suspicious Concept? Why? Miquel Solà* Institut de Química Computacional i Catàlisi and Departament de Química, Universitat de Girona, Girona, Spain Keywords: aromaticity, conjugation, hyperconjugation, multidimensional character, indicators of aromaticity From time to time I have the opportunity to give lectures on topics related to aromaticity. Quite often in these occasions I get comments from the audience complaining about the fact that aromaticity is not a well-defined concept. My usual answer is that the most fruitful concepts in chemistry share the same lack of strict definition (Grunenberg, 2017). In one of these occasions, the comment was formulated by someone who give a talk the day before justifying all the results he/she obtained using the concept of hyperconjugation. His/her comment was a little bit irritating to me because, in a way, he/she was saying I am a serious scientist because I am working with rigorous concepts like hyperconjugation whereas you are a kind of pseudoscientist playing with floppy concepts like aromaticity. Was he/she right? I do not think so. Conjugation involves interactions (electron delocalization) between π-orbitals, although its definition can also be extended to p-orbitals to cover lone pair interactions with the π-system. Hyperconjugation accounts for the interaction between two orbitals with π-symmetry where one or both of them come from a saturated moiety (Mulliken, 1939; Mulliken et al., 1941). -

Theory of Three-Electron Bond in the Four Works with Brief Comments
ry: C ist urr m en e t Dmytrovych, Organic Chem Curr Res 2017, 6:2 h R C e c s i DOI: 10.4172/2161-0401.1000182 e n a a r Organic Chemistry c g r h O ISSN: 2161-0401 Current Research ResearchResearch Article Article Open Accesss Theory of Three-Electron Bond in the Four Works with Brief Comments Bezverkhniy Volodymyr Dmytrovych* Street Chernivtsi 6, Village Nedoboevtsi, Chernivtsi Region, Khotyn District, Ukraine Abstract Using the concept of three-electron bond we can represent the actual electron structure of benzene and other molecules, explain specificity of the aromatic bond and calculate the delocalization energy. Gives theoretical justification and experimental confirmation of existence of the three-electron bond. It was shown, that functional relation y=a+b/x+c/ x2 fully describes dependence of energy and multiplicity of chemical bond from bond distance. Keywords: Benzene; Three-electron bond; Semi-virtual particle; Structure of the Benzene Molecule on the Basis of the Fermion; Entangled quantum state; Interfering universe Three-Electron Bond Introduction Results and Discussion Chemical bond has been always a basis of chemistry. Advancement Supposing that the chemical bond between two atoms can be of chemical science can be considered as evolution, development of established by means of three electrons with oppositely oriented spins concepts about chemical bond. Aromatic bond is fundamental basis ( ) the structure of the benzene molecule can be expressed as follows of organic chemistry. Concept of three-electron bond in benzene (Figures 2 and 3). molecule enables to explain specificity of aromatic bond. It also becomes ↑↓↑ It is interesting to point out that spins of central electrons on opposite apparent, why planar molecules with 6, 10 etc.