The Grinder 3
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Practice Tips for Open Source Licensing Adam Kubelka
Santa Clara High Technology Law Journal Volume 22 | Issue 4 Article 4 2006 No Free Beer - Practice Tips for Open Source Licensing Adam Kubelka Matthew aF wcett Follow this and additional works at: http://digitalcommons.law.scu.edu/chtlj Part of the Law Commons Recommended Citation Adam Kubelka and Matthew Fawcett, No Free Beer - Practice Tips for Open Source Licensing, 22 Santa Clara High Tech. L.J. 797 (2005). Available at: http://digitalcommons.law.scu.edu/chtlj/vol22/iss4/4 This Article is brought to you for free and open access by the Journals at Santa Clara Law Digital Commons. It has been accepted for inclusion in Santa Clara High Technology Law Journal by an authorized administrator of Santa Clara Law Digital Commons. For more information, please contact [email protected]. ARTICLE NO FREE BEER - PRACTICE TIPS FOR OPEN SOURCE LICENSING Adam Kubelkat Matthew Fawcetttt I. INTRODUCTION Open source software is big business. According to research conducted by Optaros, Inc., and InformationWeek magazine, 87 percent of the 512 companies surveyed use open source software, with companies earning over $1 billion in annual revenue saving an average of $3.3 million by using open source software in 2004.1 Open source is not just staying in computer rooms either-it is increasingly grabbing intellectual property headlines and entering mainstream news on issues like the following: i. A $5 billion dollar legal dispute between SCO Group Inc. (SCO) and International Business Machines Corp. t Adam Kubelka is Corporate Counsel at JDS Uniphase Corporation, where he advises the company on matters related to the commercialization of its products. -

ACS – the Archival Cytometry Standard
http://flowcyt.sf.net/acs/latest.pdf ACS – the Archival Cytometry Standard Archival Cytometry Standard ACS International Society for Advancement of Cytometry Candidate Recommendation DRAFT Document Status The Archival Cytometry Standard (ACS) has undergone several revisions since its initial development in June 2007. The current proposal is an ISAC Candidate Recommendation Draft. It is assumed, however not guaranteed, that significant features and design aspects will remain unchanged for the final version of the Recommendation. This specification has been formally tested to comply with the W3C XML schema version 1.0 specification but no position is taken with respect to whether a particular software implementing this specification performs according to medical or other valid regulations. The work may be used under the terms of the Creative Commons Attribution-ShareAlike 3.0 Unported license. You are free to share (copy, distribute and transmit), and adapt the work under the conditions specified at http://creativecommons.org/licenses/by-sa/3.0/legalcode. Disclaimer of Liability The International Society for Advancement of Cytometry (ISAC) disclaims liability for any injury, harm, or other damage of any nature whatsoever, to persons or property, whether direct, indirect, consequential or compensatory, directly or indirectly resulting from publication, use of, or reliance on this Specification, and users of this Specification, as a condition of use, forever release ISAC from such liability and waive all claims against ISAC that may in any manner arise out of such liability. ISAC further disclaims all warranties, whether express, implied or statutory, and makes no assurances as to the accuracy or completeness of any information published in the Specification. -

Press Release: New and Revised Extensions for Accessible
Press release Leuven, Belgium, 8 November 2011 New and Revised Extensions for Accessible Document Creation with OpenOffice.org and LibreOffice The Katholieke Universiteit Leuven (K.U.Leuven) today released an extension for OpenOffice.org Writer and LibreOffice Writer that enables users to evaluate and repair accessibility issues in word processing documents. “AccessODF” (http://sourceforge.net/p/accessodf/wiki/) is a freeware extension for OpenOffice.org and LibreOffice, two office suites that are freely available for Microsoft Windows, Mac OS X, Linux/Unix and Solaris. At the same time, K.U.Leuven also releases new versions of two other extensions: odt2daisy (http://odt2daisy.sourceforge.net/) and odt2braille (http://odt2braille.sourceforge.net/). The former enables users to export word processing documents to digital talking books in the DAISY format; the latter enables exporting to Braille and printing on a Braille embosser. AccessODF, odt2daisy and odt2braille are being developed in the framework of the AEGIS project, an R&D project funded by the European Commission. The three extensions will be demonstrated at the AEGIS project’s Workshop and Conference, which take place in Brussels on 28-30 November 2011 (http://aegis-conference.eu/). AccessODF AccessODF is an extension that can be used in OpenOffice.org Writer and in LibreOffice Writer. It enables authors to find and repair accessibility issues in their documents, i.e. issues that make their documents difficult or even impossible to read for people with disabilities. This includes -

Pack, Encrypt, Authenticate Document Revision: 2021 05 02
PEA Pack, Encrypt, Authenticate Document revision: 2021 05 02 Author: Giorgio Tani Translation: Giorgio Tani This document refers to: PEA file format specification version 1 revision 3 (1.3); PEA file format specification version 2.0; PEA 1.01 executable implementation; Present documentation is released under GNU GFDL License. PEA executable implementation is released under GNU LGPL License; please note that all units provided by the Author are released under LGPL, while Wolfgang Ehrhardt’s crypto library units used in PEA are released under zlib/libpng License. PEA file format and PCOMPRESS specifications are hereby released under PUBLIC DOMAIN: the Author neither has, nor is aware of, any patents or pending patents relevant to this technology and do not intend to apply for any patents covering it. As far as the Author knows, PEA file format in all of it’s parts is free and unencumbered for all uses. Pea is on PeaZip project official site: https://peazip.github.io , https://peazip.org , and https://peazip.sourceforge.io For more information about the licenses: GNU GFDL License, see http://www.gnu.org/licenses/fdl.txt GNU LGPL License, see http://www.gnu.org/licenses/lgpl.txt 1 Content: Section 1: PEA file format ..3 Description ..3 PEA 1.3 file format details ..5 Differences between 1.3 and older revisions ..5 PEA 2.0 file format details ..7 PEA file format’s and implementation’s limitations ..8 PCOMPRESS compression scheme ..9 Algorithms used in PEA format ..9 PEA security model .10 Cryptanalysis of PEA format .12 Data recovery from -

CSA ガイダンス Version 4.0 を用いた クラウドセキュリティリファレンス (OSS マッピング 2019)
CSA ガイダンス version 4.0 を用いた クラウドセキュリティリファレンス (OSS マッピング 2019) 一般社団法人 日本クラウドセキュリティアライアンス(CSA ジャパン) クラウドセキュリティワーキンググループ Copyright © 2019 Cloud Security Alliance Japan Chapter 目次 1. はじめに ................................................................................................................................................ 4 2. 検討指針 ................................................................................................................................................ 5 3. DOMAIN6 管理画面と事業継続 ............................................................................................................... 6 4. DOMAIN7 インフラストラクチャ・セキュリティ ................................................................................ 10 5. DOMAIN8 仮想化とコンテナ技術 ......................................................................................................... 18 6. DOMAIN10 アプリケーションセキュリティ ......................................................................................... 22 7. DOMAIN11 データセキュリティと暗号化 ............................................................................................ 30 8. DOMAIN12 アイデンティティ管理、権限付与管理、アクセス管理 (IAM) ......................................... 35 9. 参考 URL ............................................................................................................................................... 39 Copyright © 2019 Cloud Security Alliance Japan Chapter 2 l 本書執筆編集メンバー 氏名 所属 井上 淳 NTT テクノクロス株式会社 釜山 公徳 日本電気株式会社 福田 貢士 (個人会員) 森田 翔 (個人会員) ※五十音順 l 変更履歴 日付 版数 変更内容 2019 年 2 月 26 日 1.0 初版発行 l 著作権についての留意事項 本書の著作権は、CSA -
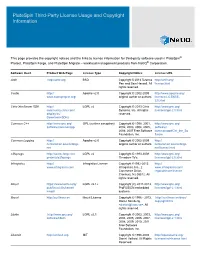
Platespin Third-Party License Usage and Copyright Information
PlateSpin Third-Party License Usage and Copyright Information This page provides the copyright notices and the links to license information for third-party software used in PlateSpin® Protect, PlateSpin Forge, and PlateSpin Migrate – workload management products from NetIQ® Corporation. Software Used Product Web Page License Type Copyright Notice License URL Antlr http://antlr.org BSD Copyright © 2012 Terence http://antlr.org/ Parr and Sam Harwell. All license.html rights reserved. Castle http:// Apache v2.0 Copyright © 2002-2009 http://www.apache.org/ www.castleproject.org/ original author or authors. licenses/LICENSE- 2.0.html Citrix XenServer SDK http:// LGPL v2 Copyright © 2013 Citrix http://www.gnu.org/ community.citrix.com/ Systems, Inc. All rights licenses/lgpl-2.0.html display/xs/ reserved. Download+SDKs Common C++ http://www.gnu.org/ GPL (runtime exception) Copyright © 1998, 2001, http://www.gnu.org/ software/commoncpp 2002, 2003, 2004, 2005, software/ 2006, 2007 Free Software commoncpp#Get_the_So Foundation, Inc. ftware Common.Logging http:// Apache v2.0 Copyright © 2002-2009 http:// netcommon.sourceforge. original author or authors. netcommon.sourceforge. net net/license.html e2fsprogs http://sourceforge.net/ LGPL v2 Copyright © 1993-2008 http://www.gnu.org/ projects/e2fsprogs Theodore Ts'o. licenses/lgpl-2.0.html Infragistics http:// Infragistics License Copyright ©1992-2013 http:// www.infragistics.com Infragistics, Inc., 2 www.infragistics.com/ Commerce Drive, legal/ultimate/license Cranbury, NJ 08512. All rights reserved. Kmod https://www.kernel.org/ LGPL v2.1+ Copyright (C) 2011-2013 http://www.gnu.org/ pub/linux/utils/kernel/ ProFUSION embedded licenses/lgpl-2.1.html kmod/ systems libcurl http://curl.haxx.se libcurl License Copyright © 1996 - 2013, http://curl.haxx.se/docs/ Daniel Stenberg, copyright.html <[email protected]>. -

Are Projects Hosted on Sourceforge.Net Representative of the Population of Free/Open Source Software Projects?
Are Projects Hosted on Sourceforge.net Representative of the Population of Free/Open Source Software Projects? Bob English February 5, 2008 Introduction We are researchers studying Free/Open Source Software (FOSS) projects . Because some of our work uses data gathered from Sourceforge.net (SF), a web site that hosts FOSS projects, we consider it important to understand how representative SF is of the entire population of FOSS projects. While SF is probably hosts the greatest number of FOSS projects, there are many other similar hosting sites. In addition, many FOSS projects maintain their own web sites and other project infrastructure on their own servers. Based on performing an Internet search and literature review (see Appendix for search procedures), it appears that no one knows how many Free/Open Source Software Projects exist in the world or how many people are working on them. Because the population of FOSS projects and developers is unknown, it is not surprising that we were not able to find any empirical analysis to assess how representative SF is of this unknown population. Although an extensive empirical analysis has not been performed, many researchers have considered the question or related questions. The next section of this paper reviews some of the FOSS literature that discusses the representativeness of SF. The third section of the paper describes some ideas for empirically exploring the representativeness of SF. The paper closes with some arguments for believing SF is the best choice for those interested in studying the population of FOSS projects. Literature Review In one of the earliest references to the representativeness of SF, Madley, Freeh and Tynan (2002) mention that they assumed that SF was representative because of its popularity and because of the number of projects hosted there, although they note that this assumption “needs to be confirmed” (p. -

Testing Java EE 6 Applications: Tools and Techniques
Testing Java EE 6 Applications: Tools and Techniques Reza Rahman Expert Group Member, Java EE 6 and EJB 3.1 Resin EJB 3.1 Lite Container Developer Author, EJB 3 in Action [email protected] Testing and Java EE Testing critical in enterprise development Pain-point that was not addressed well by J2EE Java EE 6 helps enormously by providing a number of enabling features geared towards testing Still somewhat a patchwork of evolving solutions Focus on developer (unit and integration) testing Focus on JUnit More about new tools rather than new techniques Testing Java EE Applications Testing Servlet 3 JUnit, HttpUnit, HtmlUnit great choices See if your container can be embedded into a unit test Cactus and Selenium can be good choices too Simulated Servlet containers like ServletUnit or mocking Servlet objects with EasyMock or Mockito options for very simple cases Servlet 3 Testing Demo! Testing JSF 2 JSF 2 project stages invaluable for debugging, test configuration, component development For simple cases, generic Servlet testing tools could be used, especially Selenium JSFUnit ideal for more complete JSF testing JSFUnit uses Cactus, JUnit, HttpUnit, HtmlUnit under the hood JSF 2 Testing Demo! Testing EJB 3.1/CDI CDI increases Java EE middle-tier testability by leaps and bounds EJB 3.1 embedded containers, generic dependency injection, @Alternative, portable extensions, XML deployment descriptors key enablers Arquillian/ShrinkWrap ideal cross-vendor CDI/EJB 3.1 testing tools Apache MyFaces CODI Testing another option Testing EJB 3.1/CDI Check to -

The Business of Free Software: Enterprise Incentives, Investment, and Motivation in the Open Source Community
07-028 The Business of Free Software: Enterprise Incentives, Investment, and Motivation in the Open Source Community Dr. Marco Iansiti, Ph.D. Gregory L. Richards Marco Iansiti David Sarnoff Professor of Business Administration Harvard Business School Gregory L. Richards Managing Director Keystone Strategy, Inc. Copyright © 2006 by Dr. Marco Iansiti, Ph.D. and Gregory L. Richards Working papers are in draft form. This working paper is distributed for purposes of comment and discussion only. It may not be reproduced without permission of the copyright holder. Copies of working papers are available from the author. Harvard Business School Working Paper Series, No. 07-028, 2006 _______________________________________ The Business of Free Software: Enterprise Incentives, Investment, and Motivation in the Open Source Community _______________________________________ Marco Iansiti, David Sarnoff Professor of Business Administration, Harvard Business School Gregory L. Richards, Managing Director, Keystone Strategy, Inc. Boston, MA 02163, USA October 9, 2006 PRELIMINARY DRAFT – COMMENTS WELCOME ACKNOWLEDGEMENTS: We are grateful to Geoff Allan, Lester Chen, Mark McCormick, Boris Perlin, Alan MacCormack, and Karim Lakhani, who provided many valuable inputs and suggestions. 2 ABSTRACT In this paper, we examine the motivations of large information technology (“IT”) vendors, to invest in open source software (“OSS”). What drives companies with large, proprietary software portfolios to invest hundreds of millions of dollars in OSS? We approach this question by grouping a sample of OSS projects into clusters and examining vendors’ motivations for each cluster. We find one cluster has received almost no investment. Contributions to projects in this cluster are confined to the voluntary effort of the vendors’ employees, and vendors are likely altruistically motivated. -

End to End Testing Using Integrated Tools THESIS Presented in Partial
End to end testing using integrated tools THESIS Presented in Partial Fulfillment of the Requirements for the Degree Master of Science in the Graduate School of The Ohio State University By Da Zhang Graduate Program in Computer Science and Engineering The Ohio State University 2012 Dissertation Committee: Rajiv Ramnath, Advisor Jay Ramananthan Thomas Bitterman Copyright by Da Zhang 2012 Abstract Automated functional testing for web applications is a well-researched area. Most organizations confront serious challenges in testing their websites, and these challenges are becoming more and more serious because the number of clients who rely on the web to perform e-commerce activity is increasing. Therefore, thorough, automatic, regressive and lean website testing technology is required to maintain website quality. In this paper, we describe an environment for testing with Selenium and Nagios, as well as customization we develop to incorporate Selenium script into a Nagios executable library. Nagios is an open source framework for monitoring network hosts, services and other hardware conditions with the purpose of failure detection [29]. Based on plug-in mechanisms, each service within the Nagios executable library can be executed as a Nagios plug-in. Selenium is a set of different open source software tools, each with a different approach to supporting web application test automation and agile process automated testing [1]. In this paper, we introduce in the how we combine the Nagios monitoring tool and Selenium testing tool to realize end-to-end testing using integrated tools. ii Dedication This document is dedicated to my family and my friends. iii Acknowledgments I sincerely thank my professors, Dr. -

Essnet SCFE DELIVERABLE D5-4 Guidelines and Recommendations for Development of Training Materials and for Open Source Solutions and Projects
ESSnet SCFE DELIVERABLE D5-4 Guidelines and recommendations for development of training materials and for open source solutions and projects Project acronym: SCFE Project title: “Sharing common functionalities in the ESS” Name(s), title(s) and organization or the auhor(s): Joaquim Machado, Dr. ([email protected]) José Carlos Martins, Eng. ([email protected]) Instituto Nacional de Estatítica Tel: +351 218 426 100 Fax: +351 218 454 083 e-mail: [email protected] This document is licensed under a Creative Commons License: Date: 29 Dec. 2017 Attribution-ShareAlike 4.0 International Table of Contents Introduction.............................................................................................................................1 Guidelines and recommendations.........................................................................................2 Open source solutions and projects.............................................................................2 What is Open Source?........................................................................................2 Why Open Source is good for business..............................................................6 How to make an Open Source Project..............................................................10 Development of training materials..............................................................................18 Sharing and re-using training materials............................................................18 Creating training materials................................................................................18 -

Uporaba Odprte Kode Kot Osnova Za Razvoj Programske Opreme
Univerza v Ljubljani Fakulteta za računalništvo in informatiko Univerzitetni študij Diplomska naloga Uporaba odprte kode kot osnova za razvoj programske opreme Peter Primožič Mentor: prof. dr. Franc Solina, univ. dipl. ing. Ljubljana, februar 2005 Kazalo POVZETEK .............................................................................................................................VI 1 UVOD ................................................................................................................................ 1 2 FENOMEN ODPRTE KODE............................................................................................ 3 2.1 Zgodovina odprte kode............................................................................................... 3 2.1.1 GNU projekt....................................................................................................... 3 2.1.2 Linux .................................................................................................................. 5 2.1.3 Današnji čas........................................................................................................ 6 2.2 Definicija prostega programja in odprte kode............................................................ 7 2.2.1 Prosto programje ................................................................................................ 7 2.2.2 Odprta koda........................................................................................................ 9 2.3 Licenčni modeli prostega programja.......................................................................