Predicting a T20 Cricket Match Result While the Match Is in Progress Authors Name Fahad Munir
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

MATCH UPDATES and TIME TABLE for Caribbean Premier League 2020
MATCH UPDATES AND TIME TABLE FOR Caribbean Premier League 2020 Date Time (IST) Match Venue 7:30 PM August 18 Trinbago Knight Brian Lara Cricket Riders vs Guyana Academy, Trinidad Amazon Warriors & Tobago Barbados Tridents Brian Lara Cricket August 19 3:00 AM vs St Kitts & Nevis Academy, Trinidad Patriots & Tobago 7:30 PM Brian Lara Cricket Jamaica Tallawahs August 19 Academy, Trinidad vs St Lucia Zouks & Tobago Guyana Amazon Brian Lara Cricket August 20 3:00 AM Warriors vs St Kitts Academy, Trinidad & Nevis Patriots & Tobago Brian Lara Cricket St Lucia Zouks vs August 20 7:30 PM Academy, Trinidad Barbados Tridents & Tobago Trinbago Knight Brian Lara Cricket August 21 3:00 AM Riders vs Jamaica Academy, Trinidad Tallawahs & Tobago St Kitts & Nevis Brian Lara Cricket August 22 7:30 PM Patriots vs St Lucia Academy, Trinidad Zouks & Tobago Guyana Amazon Brian Lara Cricket August 22 11:45 PM Warriors vs Jamaica Academy, Trinidad Tallawahs & Tobago August 23 7:30 PM Trinbago Knight Brian Lara Cricket Riders vs Barbados Academy, Trinidad Tridents & Tobago Guyana Amazon Brian Lara Cricket August 23 11:45 PM Warriors vs St Lucia Academy, Trinidad Zouks & Tobago St Kitts & Nevis Queen's Park Oval, August 25 7:30 PM Patriots vs Barbados Port of Spain Tridents Jamaica Tallawahs Queen's Park Oval, August 26 3:00 AM vs Guyana Amazon Port of Spain Warriors St Lucia Zouks vs Queen's Park Oval, August 26 7:30 PM Trinbago Knight Port of Spain Riders Barbados Tridents Queen's Park Oval, August 27 3:00 AM vs Jamaica Port of Spain Tallawahs St Lucia Zouks -

Download Sample Thesis
Predicting a T20 Cricket Match Result While The Match is in Progress By Fahad Munir 11201014 Md. Kamrul Hasan 11201032 Sakib Ahmed 11201009 Sultan Md. Quraish 11201017 A thesis submitted to the Department of Computer Science and Engineering in partial fulfillment of the requirements for the degree of B.Sc. in Computer Science Department of Computer Science and Engineering Brac University August 2015 © 2015. Brac University All rights reserved. Declaration It is hereby declared that 1. The thesis submitted is my/our own original work while completing degree at Brac University. 2. The thesis does not contain material previously published or written by a third party, except where this is appropriately cited through full and accurate referencing. 3. The thesis does not contain material which has been accepted, or submitted, for any other degree or diploma at a university or other institution. 4. We have acknowledged all main sources of help. Student’s Full Name & Signature: Fahad Munir Md. Kamrul Hasan 11201014 11201032 Sakib Ahmed Sultan Md. Quraish 11201009 11201017 ii Approval The thesis/project titled “Predicting a T20 Cricket Match Result While The Match is in Progress” submitted by 1. Fahad Munir (11201014) 2. Md. Kamrul Hasan (11201032) 3. Sakib Ahmed (11201009) 4. Sultan Md. Quraish (11201017) Of Summer, 2015 has been accepted as satisfactory in partial fulfillment of the requirement for the degree of B.Sc. in Computer Science on August 23, 2015. Examining Committee: _______________________________ Rubel Biswas Senior Lecturer, Department of Computer Science and Engineering Brac University _______________________________ Professor Md. Haider Ali, PhD Chairperson, Department of Computer Science and Engineering Brac University iii Ethics Statement iv Abstract Data Mining and Machine learning in Sports Analytics, is a brand new research field in Computer Science with a lot of challenge. -

International Cricket Council
TMUN INTERNATIONAL CRICKET COUNCIL FEBRUARY 2019 COMITTEEE DIRECTOR VICE DIRECTORS MODERATOR MRUDUL TUMMALA AADAM DADHIWALA INAARA LATIFF IAN MCAULIFFE TMUN INTERNATIONAL CRICKET COUNCIL A Letter from Your Director 2 Background 3 Topic A: Cricket World Cup 2027 4 Qualification 5 Hosting 5 In This Committee 6 United Arab Emirates 7 Singapore and Malaysia 9 Canada, USA, and West Indies 10 Questions to Consider 13 Topic B: Growth of the Game 14 Introduction 14 Management of T20 Tournaments Globally 15 International Tournaments 17 Growing The Role of Associate Members 18 Aid to Troubled Boards 21 Questions to Consider 24 Topic C: Growing Women’s Cricket 25 Introduction 25 Expanding Women’s T20 Globally 27 Grassroots Development Commitment 29 Investing in More Female Umpires and Match Officials 32 Tying it All Together 34 Questions to Consider 35 Advice for Research and Preparation 36 Topic A Key Resources 37 Topic B Key Resources 37 Topic C Key Resources 37 Bibliography 38 Topic A 38 Topic B 40 Topic C 41 1 TMUN INTERNATIONAL CRICKET COUNCIL A LETTER FROM YOUR DIRECTOR Dear Delegates, The International Cricket Council (ICC) is the governing body of cricket, the second most popular sport worldwide. Much like the UN, the ICC brings representatives from all cricket-playing countries together to make administrative decisions about the future of cricket. Unlike the UN, however, not all countries have an equal input; the ICC decides which members are worthy of “Test” status (Full Members), and which are not (Associate Members). While the Council has experienced many successes, including hosting the prestigious World Cup and promoting cricket at a grassroots level, it also continues to receive its fair share of criticism, predominantly regarding the ICC’s perceived obstruction of the growth of the game within non- traditionally cricketing nations and prioritizing the commercialization of the sport over globalizing it. -

Men's Global Employment Report 2020
FICA MEN’S PROFESSIONAL CRICKET GLOBAL EMPLOYMENT REPORT 2020 IT’S ESSENTIAL THE GLOBAL CRICKET STRUCTURE AND LEADERSHIP PROTECTS THE HISTORY OF THE GAME AND PLAYERS SHOULD BE ALSO ITS FUTURE. DOMESTIC ENCOURAGED TO SPEAK LEAGUES AND INTERNATIONAL UP ON BIG ISSUES IN SPORT CRICKET BOTH HAVE A REALLY AND SOCIETY. WITH STRONG IMPORTANT PLACE AND THERE LEADERSHIP CRICKET CAN BE NEEDS TO BE A BALANCE A GENUINE FORCE FOR GOOD. BETWEEN THEM. Jason Holder Eoin Morgan I WOULD LOVE TO SEE ONE OF THE THINGS OUR THE ROLE OF PLAYERS’ EYES HAVE BEEN OPENED TO ASSOCIATIONS EMBRACED SINCE FORMING A PLAYERS’ ACROSS THE WHOLE CRICKET ASSOCIATION... IS THAT PLAYERS WORLD. PLAYER VOICE IS ARE OFTEN THE ONES LEFT ON IMPORTANT TO PROTECTING THE END OF THE LINE WHEN BOTH PLAYERS AND THE GAME. LEAGUES FALL OVER OR WHEN IN MY EXPERIENCE PLAYERS CLUBS AND LEAGUES DON’T CARE DEEPLY ABOUT THE GAME HONOUR COMMITMENTS. WE AND WANT TO ENSURE IT’S HOPE THE ICC WORK WITH FICA HEALTHY AND THRIVING. TO PROPERLY ADDRESS THIS. Aaron Finch William Porterfield 2 THE FICA 2020 EMPLOYMENT REPORT 3 BACKGROUND AT THE TIME OF WRITING, THERE We know that structural issues, terms and conditions CRICKET SHOULD BE PROACTIVELY ARE MORE THAN 4191 REGISTERED of employment, and wage gaps all remain key drivers PROTECTING FUNDAMENTAL MEN’S PROFESSIONAL CRICKETERS of player employment decisions, particularly given there PLAYER RIGHTS AT GLOBAL LEVEL. is now an alternative, global domestic league market for IN THE WORLD. players to play in. We have also seen flexible and effective The ICC currently regulates the ‘sanctioned cricket’ A significant number of these, along with past players, arrangements implemented in several progressive framework, which purports to give it, and it’s members, are represented by FICA, and FICA’s member players’ countries to address some of the inherent issues the right to sanction cricket events in certain associations. -

Additional Information for Clubs 2020 Contents: • Home Office Professional Sportsperson Definition. • ICC Full Member List
Additional Information for Clubs 2020 Contents: • Home Office Professional Sportsperson definition. • ICC Full Member list A domestic t20 competitions • List of coaching qualifications accepted under Tier 5 as equivalent to UKC2 • Overseas Police checks • Responsibility of Cricket Clubs • Supplementary work • Tier 5 - three-month Concession • How to renew your Sponsor Licence Home Office Definition of a Professional Sportsperson: The Home Office change took effect for all visa applications and permission to enter the UK from the 10th January 2019. Any Visa issued prior to that date must comply with the definition at that point. Note - There is only one policy for all sport, not all points will apply to Cricket. For example, in Cricket, all state teams have First Class status meaning that they come under point 3 and not point 5. A Professional Sportsperson”, is someone, whether paid or unpaid, who: 1. is currently providing services as a sportsperson, playing or coaching in any capacity, at a professional or semi-professional level of sport; 2. is currently receiving payment, including payment in kind, for playing or coaching that is covering all, or the majority of, their costs for travelling to, and living in the UK, or who has done so within the previous four years; 3. is currently registered to a professional or semi-professional sports team, or who has been so registered within the previous four years. This includes all academy and development team age groups; 4. has represented their nation or national team within the previous two years, including all youth and development age groups from under 17’s upwards; 5. -

November 18, 2020 • Tel: 905-738-5005 • 312 Brownridge Dr
CANADIAN SUPERBILT SHUTTERS AND BLINDS Providing smart motorized Window Coverings from Hunter Douglas, Altex/SunProject Provider of Hardwood Flooring. Visit our Showroom at 1571 The Queensway, Etobicoke, Ontario Beautifying homes one window at a time through light control and energy efficiency. John Persaud, CEO B: (416) 201-0109 • C: (416) 239 2863 • [email protected] • www.superbilt.com KEEPING ALIVE THE TIES THAT BIND NOW IN OUR 38TH YEAR: 1983 - 2020 Vol. 38 • No 6 • November 18, 2020 • Tel: 905-738-5005 • 312 Brownridge Dr. Thornhill, ON L4J 5X1 • indocaribbeanworld.com • [email protected] INSURANCE Paul Ram Kamla Persad-Bissessar Despite restrictions imposed by the Covid-19 pandemic on crowd sizes and Life & Investment Broker the number of persons allowed to assemble, celebrants of this year’s Diwali MONEY FREEDOM INC. festivities found novel ways to overcome the constraints and maintain the Membership spirit of the occasion. One way was a broadcast on November 8 of the grand musical extravaganza, Ayee Diwali 2020, which was viewed world- wide via Youtube, Facebook, and on other social media. The program was support for based in New York and featured several well-known artistes from Canada and the US, among them Terry Gajraj, Geeta Bisram, Steve Mohabir, Ami Sha, Randy Recklez, Ravi Babooram, Alex Shay, Navin & Hemant UNC leader Ramsaran Maharaj, Devin Ramoutar, and the Amar Geet group. The pro- Port-of-Spain – Oropouche gram was hosted by DJ Navin and Ryan Bemaul. Representing Canada East MP Dr Roodal Moonilal was The Wave Band (in photo above), with (from left), Omesh Singh on threw his support behind Kamla Also offered: *Non Medical & Mortgage the keyboard, Khaydan Pardassie on rhythm guitar, Sudesh Siewkumar on Persad-Bissessar on Monday, say- Insurance *No Load Funds *No Penalty RESP bass, and Avin Singh on drums. -

Barbados Advocate
Established October 1895 Schools to resume online from Tuesday PAGE 3 Friday April 23, 2021 $2 VAT Inclusive Level 4 travel advisory a cause for concern WHILST the recent Level-4 travel advi- that the BTMI (Barbados Tourism however require us to continue practising sory issued by the United States Marketing Inc.) and the Ministry of social distancing, physical washing of our Department of State against Barbados Foreign Affairs will be the ones as the our hands, ensuring that we engage in all has been described as cause for competent entities to deal with this of the correct practices, particularly at a concern, especially given that the issue,” Senator Grant remarked. time when we’re looking to reopen the tourism sector is preparing to welcome He added, “If we reflect on the reports sector; or I should say at a time when visitors again, a key tourism official that we’ve been receiving from the we’re looking to encourage more visitors maintains that there has been good Ministry of Health and Wellness, those to come to the Barbados,” Grant further management of the COVID-19 pandemic reports suggest that the number of infec- commented. in Barbados. tions are being reduced, as well as the in- He maintained, “…I think there are The United States Department of State fection rate. In fact, when I looked at the measures that have been instituted to recently updated its travel advisories to number of persons who yesterday would demonstrate that there’s been good and Barbados, Antigua and Barbuda, St. have been tested and those that were proper management of the COVID-19 Lucia, and St. -

BUAV Secures Review Into Home Office Investigation of Animal Abuse
felixonline.co.uk @felixImperial /FelixImperial [email protected] Keeping the cat free since 1949 issue 1606 May 22nd 2015 Students stage peaceful protest against Inside... The latest scandal arrest of popular homeless book critic in Game of Thrones Page 7 BUAV secures review into Comment 10 Felix asks: where is our Home Office investigation petting zoo? of animal abuse at Imperial Features 9 Is it time for electoral reform? BUAV claim: Politics 22-23 • Home Office report has discredited them in Arts: the Jack Steadman issue media • Imperial is “misleading the public” • Sanctions against researchers were “extremely weak” • “Home Office guilty of foul play” Pages 4 and 5 Arts 25- 32 8 22.05.2015 THE STUDENT PAPER OF IMPERIAL COLLEGE LONDON FELIX This week’s issue... [email protected] Felix Editor Philippa Skett Contents EDITORIAL TEAM “The use of animals in science Editor-In-Chief PHILIPPA SKETT News 3-8 Deputy Editor research is a necessity but should PHILIP KENT Features 9 Treasurer THOMAS LIM Comment 10-11 still be treated as a privilege” Technical Hero Film 13-15 LUKE GRANGER-BROWN his week we’re covering the is still developing, but for the time News Editors Television 16 latest developments in the being, we rely on those little mice, CAROL ANN CHEAH TBUAV investigation against fish, ferrets and rabbits to test and CECILY JOHNSON Fashion 17 Imperial. The BUAV has been refine the drugs that keep us healthy KUNAL WAGLE granted a judicial review against the and save our lives. Politics 22-23 Home Office findings, stating that There will always be casualties in Comment Editor their sanctions weren’t too severe. -

Approved Events List
Department of Law and Public Safety Division of Gaming Enforcement Approved Leagues/Events for Sports Wagering Last Updated: July 28, 2021 Summary Pursuant to N.J.A.C. 13:69N-1.11, the Division has prepared this document for informational purposes only to answer frequently asked questions about how new events and bets are reviewed as well as to provide a list of currently approved leagues and events. Procedure for Approval of New Events/Wagers N.J.A.C. 13:69N-1.11: A sports pool operator shall not accept any wager on a sports event unless it has provided written notification to the Division of Gaming Enforcement of the first time that wagering on a category of wagering event (for example, wagering on a particular type of professional sport) or type of wager (for example, an in-play wager or exchange wager) is offered to the public. The Division reserves the right to prohibit the acceptance of wagers and may order the cancellation of wagers and require refunds on any event for which wagering would be contrary to the public policies of the State. To give the Division sufficient time to review a submission, sports pool operators should email [email protected] at least 72 hours prior to offering the new event or wager to the public. Pursuant to N.J.A.C. 13:69N-1.11(a), this notice must include (1) the name of the sport’s governing body in charge of administering the event or wager and (2) a description of the policies and procedures regarding the event or wager’s integrity. -
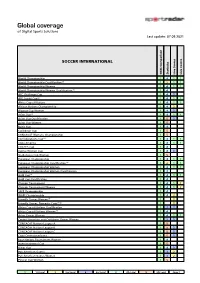
Sportradar Coverage List
Global coverage of Digital Sports Solutions Last update: 07.09.2021 SOCCER INTERNATIONAL Odds Comparison Statistics Live Scores Live Centre World Championship 1 4 1 1 World Championship Qualification (1) 1 2 1 1 World Championship Women 1 4 1 1 World Championship Women Qualification (1) 1 4 AFC Challenge Cup 1 4 3 AFF Suzuki Cup (6) 1 4 1 1 Africa Cup of Nations 1 4 1 1 African Nations Championship 1 4 2 Algarve Cup Women 1 4 3 Asian Cup (6) 1 4 1 1 Asian Cup Qualification 1 5 3 Asian Cup Women 1 5 Baltic Cup 1 4 Caribbean Cup 1 5 CONCACAF Womens Championship 1 5 Confederations Cup (1) 1 4 1 1 Copa America 1 4 1 1 COSAFA Cup 1 4 Cyprus Women Cup 1 4 3 SheBelieves Cup Women 1 5 European Championship 1 4 1 1 European Championship Qualification (1) 1 2 1 1 European Championship Women 1 4 1 1 European Championship Women Qualification 1 4 Gold Cup (6) 1 4 1 1 Gold Cup Qualification 1 4 Olympic Tournament 1 4 1 2 Olympic Tournament Women 1 4 1 2 SAFF Championship 1 4 WAFF Championship 1 4 2 Friendly Games Women (1) 1 2 Friendly Games, Domestic Cups (1) (2) 1 2 Africa Cup of Nations Qualification 1 3 3 Africa Cup of Nations Women (1) 1 4 Asian Games Women 1 4 1 1 Central American and Caribbean Games Women 1 3 3 CONCACAF Nations League A 1 5 CONCACAF Nations League B 1 5 3 CONCACAF Nations League C 1 5 3 Copa Centroamericana 1 5 3 Four Nations Tournament Women 1 4 Intercontinental Cup 1 5 Kings Cup 1 4 3 Pan American Games 1 3 2 Pan American Games Women 1 3 2 Pinatar Cup Women 1 5 1 1st Level 2 2nd Level 3 3rd Level 4 4th Level 5 5th Level Page: -

Hero Motocorp Sets the Stage for Return of Twenty20 Cricket
New Delhi, August 17, 2020 HERO MOTOCORP SETS THE STAGE FOR RETURN OF TWENTY20 CRICKET CATCH THE LIVE ACTION OF HERO CARIBBEAN PREMIER LEAGUE T20 STARTING FROM AUGUST 18 Hero MotoCorp – Title Sponsor of Caribbean Premier League since 2015 First mainstream Twenty20 cricket league to commence since Covid-19 lockdown Scheduled from Aug 18-Sep 10 in Trinidad and Tobago; To be broadcasted on Star Sports and Live Streamed on FanCode The wait is over! Hero MotoCorp, the world’s largest two-wheeler manufacturer is set to bring the exciting cricketing action back with Hero Caribbean Premier League (Hero CPL), popularly known as the ‘Biggest Party in Sport’, starting from 18 August to 10 September 2020. Marking the return of the electrifying Twenty20 format of the game in the ‘New Normal’, the tournament will be conducted in a bio-secure environment to meet the safety and social distancing protocols. In a first for a cricket premier league, the matches would be played in stadiums without any spectators, with the objective to maintain social distancing. Dr. Pawan Munjal, Chairman & CEO of Hero MotoCorp, said, “Hero MotoCorp has always believed in supporting and promoting sporting action across the world and we are glad to be leading the efforts towards the resumption of top sporting event in the Caribbean. The Hero CPL T20 marks the gradual return of live action sports after a gap of nearly four months. The Hero Caribbean Premier League is an exciting opportunity to highlight the cricketing Heroes from around the world.” The Hero CPL will bring the best T20 cricketers in action from the Caribbean and from around the world. -

PSL's Marketing Case Study
Citation: Malik, H. A., Khan, H., & Haider, G. (2020). The Journey of PSL Brand (PSL’s Marketing Case Study). Global Regional Review, V(II), 40-52. https://doi.org/10.31703/grr.2020(V-II).05 URL: http://dx.doi.org/10.31703/grr.2020(V-II).05 DOI: 10.31703/grr.2020(V-II).05 The Journey of PSL Brand (PSL’s Marketing Case Study) Haider Ali Malik* Haroon Khan† Ghazala Haider‡ Vol. V, No. II (Spring 2020) | Pages: 40 ‒ 52 p- ISSN: 2616-955X | e-ISSN: 2663-7030 | ISSN-L: 2616-955X PSL Marketing Case Back in 2014, Najam Sethi was pondering over the dilapidated situation of International cricket in Pakistan. He felt dismayed at the prospects of inviting international players after the country’s track record of security and terrorism. Feeling nostalgic about the cricket in Pakistan, Sethi went through the PCB’s documents and shockingly discovered that PCB is generating no revenue like it used to do until 2009. He was well aware of the fact cricket is the sport that is Pakistan’s blood, and every nook and cranny is yearning for live cricket in Pakistan—comparing it with other countries like India, where IPL generates staggering revenues and proved the bordering country with amazement and thrill every year. Indians remain excited that the IPL will continue every year and they will witness the spectacle of deadly yorkers and loft sixes very soon. Sethi feels every other cricket- loving nation have their own leagues like County Cricket, Big Bash League, Sri Lankan Premier League, Caribbean Premier League, etc.