An Efficient Normalized Rank-Based SVM for Room Level Indoor Wifi
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
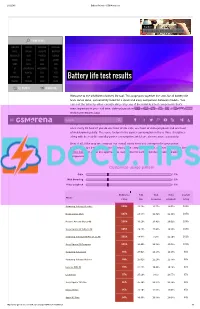
Battery Life Test Results HUAWEI TOSHIBA INTEX PLUM
2/12/2015 Battery life tests GSMArena.com Starborn SAMSUNG GALAXY S6 EDGE+ REVIEW PHONE FINDER SAMSUNG LENOVO VODAFONE VERYKOOL APPLE XIAOMI GIGABYTE MAXWEST MICROSOFT ACER PANTECH CELKON NOKIA ASUS XOLO GIONEE SONY OPPO LAVA VIVO LG BLACKBERRY MICROMAX NIU HTC ALCATEL BLU YEZZ MOTOROLA ZTE SPICE PARLA Battery life test results HUAWEI TOSHIBA INTEX PLUM ALL BRANDS RUMOR MILL Welcome to the GSMArena battery life tool. This page puts together the stats for all battery life tests we've done, conveniently listed for a quick and easy comparison between models. You can sort the table by either overall rating or by any of the individual test components that's most important to you call time, video playback or web browsing.TIP US 828K 100K You can find all about our84K 137K RSS LOG IN SIGN UP testing procedures here. SearchOur overall rating gives you an idea of how much battery backup you can get on a single charge. An overall rating of 40h means that you'll need to fully charge the device in question once every 40 hours if you do one hour of 3G calls, one hour of video playback and one hour of web browsing daily. The score factors in the power consumption in these three disciplines along with the reallife standby power consumption, which we also measure separately. Best of all, if the way we compute our overall rating does not correspond to your usage pattern, you are free to adjust the different usage components to get a closer match. Use the sliders below to adjust the approximate usage time for each of the three battery draining components. -

Barometer of Mobile Internet Connections in Indonesia Publication of March 14Th 2018
Barometer of mobile Internet connections in Indonesia Publication of March 14th 2018 Year 2017 nPerf is a trademark owned by nPerf SAS, 87 rue de Sèze 69006 LYON – France. Contents 1 Methodology ................................................................................................................................. 2 1.1 The panel ............................................................................................................................... 2 1.2 Speed and latency tests ....................................................................................................... 2 1.2.1 Objectives and operation of the speed and latency tests ............................................ 2 1.2.2 nPerf servers .................................................................................................................. 2 1.3 Tests Quality of Service (QoS) .............................................................................................. 2 1.3.1 The browsing test .......................................................................................................... 2 1.3.2 YouTube streaming test ................................................................................................ 3 1.4 Filtering of test results .......................................................................................................... 3 1.4.1 Filtering of devices ........................................................................................................ 3 2 Overall results 2G/3G/4G ............................................................................................................ -

Electronic 3D Models Catalogue (On July 26, 2019)
Electronic 3D models Catalogue (on July 26, 2019) Acer 001 Acer Iconia Tab A510 002 Acer Liquid Z5 003 Acer Liquid S2 Red 004 Acer Liquid S2 Black 005 Acer Iconia Tab A3 White 006 Acer Iconia Tab A1-810 White 007 Acer Iconia W4 008 Acer Liquid E3 Black 009 Acer Liquid E3 Silver 010 Acer Iconia B1-720 Iron Gray 011 Acer Iconia B1-720 Red 012 Acer Iconia B1-720 White 013 Acer Liquid Z3 Rock Black 014 Acer Liquid Z3 Classic White 015 Acer Iconia One 7 B1-730 Black 016 Acer Iconia One 7 B1-730 Red 017 Acer Iconia One 7 B1-730 Yellow 018 Acer Iconia One 7 B1-730 Green 019 Acer Iconia One 7 B1-730 Pink 020 Acer Iconia One 7 B1-730 Orange 021 Acer Iconia One 7 B1-730 Purple 022 Acer Iconia One 7 B1-730 White 023 Acer Iconia One 7 B1-730 Blue 024 Acer Iconia One 7 B1-730 Cyan 025 Acer Aspire Switch 10 026 Acer Iconia Tab A1-810 Red 027 Acer Iconia Tab A1-810 Black 028 Acer Iconia A1-830 White 029 Acer Liquid Z4 White 030 Acer Liquid Z4 Black 031 Acer Liquid Z200 Essential White 032 Acer Liquid Z200 Titanium Black 033 Acer Liquid Z200 Fragrant Pink 034 Acer Liquid Z200 Sky Blue 035 Acer Liquid Z200 Sunshine Yellow 036 Acer Liquid Jade Black 037 Acer Liquid Jade Green 038 Acer Liquid Jade White 039 Acer Liquid Z500 Sandy Silver 040 Acer Liquid Z500 Aquamarine Green 041 Acer Liquid Z500 Titanium Black 042 Acer Iconia Tab 7 (A1-713) 043 Acer Iconia Tab 7 (A1-713HD) 044 Acer Liquid E700 Burgundy Red 045 Acer Liquid E700 Titan Black 046 Acer Iconia Tab 8 047 Acer Liquid X1 Graphite Black 048 Acer Liquid X1 Wine Red 049 Acer Iconia Tab 8 W 050 Acer -

How to Choose the Right Smartphone Within Your Budget
SHOOTOUT HOW TO CHOOSE THE RIghT SMARTPHONE WITHIN YOUR BUDGET The smartphone industry has developed and progressed dramatically since the days when the display in your mobile phone was required only to show the number of the person calling. Let’s look at the latest developments and the key parameters to keep in mind while choosing a smartphone these days — Anuj Sharma ith the progression of the smartphone industry, gradually Display Quality more features are continuously being added/upgraded The display of a smart phone is one of the most important aspect Wto do multilple tasks, such as to view emails, click and to consider when buying a new device because it’s the part where record photos and videos, etc. And with added features there you’ll spend the most time directly interacting with the phone. The is always a question as to which smart phone should one buy smartphone industry rotates around various names to describe the and for what price. There are several aspects to consider while viewing experience on your smartphone screen viz. IPS, LCD, LED, choosing a smart phone. Here’s what you should look out for, Retina, AMOLED etc. Let’s find out what is meant by each of these based on our experience of reviewing phones over the past six terms and how they are different from others. months or so. Also do check for protective coating on screens like Gorilla Glass that prevents breaking your smartphone screen from accidental The Ideal Screen Size drops or Anti-Scratch Resistant/Fingerprint coating that protects Nowadays mostly all manufacturers are targeting bigger screen the screen from scratches or fingerprint smudges. -

Why It Takes So Long to Connect to a Wifi Access Point
Why it Takes so Long to Connect to a WiFi Access Point Changhua Pei, Zhi Wang, Youjian Zhao, Zihan Wang, Yuanquan Peng, Wenliang Tang, Yuan Meng, Dan Pei Xiaodong Qu INFOCOM 2017 2 Measurement Correlation Motivation Modeling Results Analysis 3 Measurement Correlation Motivation Modeling Results Analysis 4 WiFi is indispensable in our daily lives Source: Cisco VNI Mobile, 2017 97.4 (49% of overall traffic) 3X 5X 454 30.8 94 2005 2020 2006 2020 Overall WiFi Traffic Growth Hotspots (Exabytes) (Millions) 5 Experience of WiFi Network Remote Services Mobile Device AP Throughput Downloading 6 Experience of WiFi Network Remote Services Mobile Device AP WiFi Hop Latency Online Gaming 7 Experience of WiFi Network Remote Services Mobile Device AP 8 Experience of WiFi Network Mobile Device AP I want to connect to the AP! Connection set-up process Now I can talk to Connection time cost the Internet ^^ Urgent need to study the connection set-up time 9 Mobile Device AP Suranga [WiNTECH’13] is the first work focus on WiFi connection time cost : • The connection set-up process in the wild is unknown • Lack thorough investigation in a larger scale. I want to access theWe AP!focus on: Connection set-up procedure • How about the connection time cost in the wild? Now• WhatI canistalkthetoculprit of theConnectionhigh connectiontime costtime cost? the• WhatInternetcan ^^I do to reduce the connection time cost? 10 Measurement Correlation Motivation Modeling Results Analysis 11 DATASET • WiFi Manager of Tencent Technology • Provide Free WiFi service • Top in the Android/iOS App market (China) • About 50K downloads every day • Continuously collect one week data from May 3 to May 9. -

Alcatel One Touch Go Play 7048 Alcatel One Touch
Acer Liquid Jade S Alcatel Idol 3 4,7" Alcatel Idol 3 5,5" Alcatel One Touch Go Play 7048 Alcatel One Touch Pop C3/C2 Alcatel One Touch POP C7 Alcatel Pixi 4 4” Alcatel Pixi 4 5” (5045x) Alcatel Pixi First Alcatel Pop 3 5” (5065x) Alcatel Pop 4 Lte Alcatel Pop 4 plus Alcatel Pop 4S Alcatel Pop C5 Alcatel Pop C9 Allview C6 Quad Apple Iphone 4 / 4s Apple Iphone 5 / 5s / SE Apple Iphone 5c Apple Iphone 6/6s 4,7" Apple Iphone 6 plus / 6s plus Apple Iphone 7 Apple Iphone 7 plus Apple Iphone 8 Apple Iphone 8 plus Apple Iphone X HTC 8S HTC Desire 320 HTC Desire 620 HTC Desire 626 HTC Desire 650 HTC Desire 820 HTC Desire 825 HTC 10 One M10 HTC One A9 HTC One M7 HTC One M8 HTC One M8s HTC One M9 HTC U11 Huawei Ascend G620s Huawei Ascend G730 Huawei Ascend Mate 7 Huawei Ascend P7 Huawei Ascend Y530 Huawei Ascend Y540 Huawei Ascend Y600 Huawei G8 Huawei Honor 5x Huawei Honor 7 Huawei Honor 8 Huawei Honor 9 Huawei Mate S Huawei Nexus 6p Huawei P10 Lite Huawei P8 Huawei P8 Lite Huawei P9 Huawei P9 Lite Huawei P9 Lite Mini Huawei ShotX Huawei Y3 / Y360 Huawei Y3 II Huawei Y5 / Y541 Huawei Y5 / Y560 Huawei Y5 2017 Huawei Y5 II Huawei Y550 Huawei Y6 Huawei Y6 2017 Huawei Y6 II / 5A Huawei Y6 II Compact Huawei Y6 pro Huawei Y635 Huawei Y7 2017 Lenovo Moto G4 Plus Lenovo Moto Z Lenovo Moto Z Play Lenovo Vibe C2 Lenovo Vibe K5 LG F70 LG G Pro Lite LG G2 LG G2 mini D620 LG G3 LG G3 s LG G4 LG G4c H525 / G4 mini LG G5 / H830 LG K10 / K10 Lte LG K10 2017 / K10 dual 2017 LG K3 LG K4 LG K4 2017 LG K7 LG K8 LG K8 2017 / K8 dual 2017 LG L Fino LG L5 II LG L7 LG -

ETUI W Kolorze Czarnym ALCATEL A3
ETUI w kolorze czarnym ALCATEL A3 5.0'' CZARNY ALCATEL PIXI 4 4.0'' 4034A CZARNY ALCATEL PIXI 4 5.0'' 5045X CZARNY ALCATEL POP C3 4033A CZARNY ALCATEL POP C5 5036A CZARNY ALCATEL POP C7 7041X CZARNY ALCATEL POP C9 7047D CZARNY ALCATEL U5 5044D 5044Y CZARNY HTC 10 CZARNY HTC DESIRE 310 CZARNY HTC DESIRE 500 CZARNY HTC DESIRE 516 CZARNY HTC DESIRE 610 CZARNY HTC DESIRE 616 CZARNY HTC DESIRE 626 CZARNY HTC DESIRE 650 CZARNY HTC DESIRE 816 CZARNY HTC ONE A9 CZARNY HTC ONE A9s CZARNY HTC ONE M9 CZARNY HTC U11 CZARNY HUAWEI ASCEND G510 CZARNY HUAWEI ASCEND Y530 CZARNY HUAWEI ASCEND Y600 CZARNY HUAWEI G8 GX8 CZARNY HUAWEI HONOR 4C CZARNY HUAWEI HONOR 6X CZARNY HUAWEI HONOR 7 LITE 5C CZARNY HUAWEI HONOR 8 CZARNY HUAWEI HONOR 9 CZARNY HUAWEI MATE 10 CZARNY HUAWEI MATE 10 LITE CZARNY HUAWEI MATE 10 PRO CZARNY HUAWEI MATE S CZARNY HUAWEI P10 CZARNY HUAWEI P10 LITE CZARNY HUAWEI P10 PLUS CZARNY HUAWEI P8 CZARNY HUAWEI P8 LITE 2017 CZARNY HUAWEI P8 LITE CZARNY HUAWEI P9 CZARNY HUAWEI P9 LITE CZARNY HUAWEI P9 LITE MINI CZARNY HUAWEI Y3 2017 CZARNY HUAWEI Y3 II CZARNY HUAWEI Y5 2017 Y6 2017 CZARNY HUAWEI Y5 Y560 CZARNY HUAWEI Y520 Y540 CZARNY HUAWEI Y541 CZARNY HUAWEI Y6 II CZARNY HUAWEI Y625 CZARNY HUAWEI Y7 CZARNY iPHONE 5C CZARNY iPHONE 5G CZARNY iPHONE 6 4.7'' CZARNY iPHONE 7 4.7'' 8 4.7'' CZARNY iPHONE 7 PLUS 5.5'' 8 PLUS CZARNY iPHONE X A1865 A1901 CZARNY LENOVO K6 NOTE CZARNY LENOVO MOTO C CZARNY LENOVO MOTO C PLUS CZARNY LENOVO MOTO E4 CZARNY LENOVO MOTO E4 PLUS CZARNY LENOVO MOTO G4 XT1622 CZARNY LENOVO VIBE C2 CZARNY LENOVO VIBE K5 CZARNY -

Destekleyen Telefon Listesini Görmek İçin Tıklayınız
Sayfa1 Görüntü Marka Model Ürün Ses Aktarımı Aktarımı 360 360 Hayır Hayır Acer S510 Acer Liquid S1 Evet Evet alps Q1 alps Q1 Evet Evet alps N5 Amazon alps N5 Evet Evet Amazon KFSAWI KFSAWI Hayır Evet Android ARCHOST552 101 ARCHOSHuawei T552 101 Evet Evet Archos Xenon Lite AsusXenon PadFone Lite Hayır Evet Asus PadFone T004 AsusInfinity fonepad 2 Evet Evet Asus K01Q Asus7 LTE ZenFone Evet Evet Asus Asus Asus_Z00AD 2 ZE551ML Evet Evet ZENFONEAsus ZenFone 2 Asus Asus_T00J LASERAsus5 ZenFone Evet Evet Asus Asus_T00G ZE601KL6 Evet Evet Asus Asus_Z011D AsusZ011D MeMO Evet Evet Asus Asus K01A PAD Evet Evet ZENFONE 2 Asus Asus_Z00LD LASERAsus Google Hayır Evet Asus Nexus 7 ZE601KLNexus 7 Hayır Evet Asus Asus_Z011D Z011D Hayır Evet BBK vivo Xshot vivo Xshot Evet Evet BBK vivo X5L vivo X5 Evet Evet BBK BLUvivo X710LSTUDIO BLUvivo XshotSTUDIO Hayır Evet BLU 7.0 LTE 7.0 LTE Evet Evet Foxconn BOWAY Pro InternationalBOWAY BOWAY_V95 ERENEBENV95 Evet Evet HoldingsERENEBEN EBEN M2 EBEN M2 Hayır Evet Limited InFocus M320 FUJITSUInFocus M320 Hayır Evet FUJITSU RM02 Gionee GN500arrows M02 Evet Evet GiONEE GN5001 1 Evet Evet GiONEE F103 GiONEEGionee F103 M5 Evet Evet GiONEE GN8001 GioneePlus TD-LTE Evet Evet GiONEE GN5001S GiONEE F103GN5001S Evet Evet GiONEE F103L L Hayır Evet GuangXin KINGSUN-F4 KINGSUN F4 Hayır Evet GUOMI GUOMI A9 HTCGUOMI Desire A9 Hayır Evet HTC HTCHTC_D728x One_M8 HTC728 dual ONE sim M8 Evet Evet HTC HTCdual simOne DUAL SIM Evet Evet HTC E9PLUSNexus 9 dual HTC OneNexus M9 9 Evet Evet HTC sim PLUS Evet Evet HTC HTCHTC_M10h Desire HTC -
Barometer of Mobile Internet Connections in Poland
Barometer of Mobile Internet Connections in Poland Publication of July 21, 2020 First half 2020 nPerf is a trademark owned by nPerf SAS, 87 rue de Sèze 69006 LYON – France. Contents 1 Summary of results ...................................................................................................................... 2 1.1 nPerf score, all technologies combined ............................................................................... 2 1.2 Our analysis ........................................................................................................................... 3 2 Overall results 2G/3G/4G ............................................................................................................. 3 2.1 Data amount and distribution ............................................................................................... 3 2.2 Success rate 2G/3G/4G ........................................................................................................ 4 2.3 Download speed 2G/3G/4G .................................................................................................. 4 2.4 Upload speed 2G/3G/4G ....................................................................................................... 5 2.5 Latency 2G/3G/4G ................................................................................................................ 5 2.6 Browsing test 2G/3G/4G....................................................................................................... 6 2.7 Streaming test 2G/3G/4G .................................................................................................... -

Barometer of Mobile Internet Connections in Indonesia Publication of July 23, 2018
Barometer of mobile Internet connections in Indonesia Publication of July 23, 2018 First half of 2018 nPerf is a trademark owned by nPerf SAS, 87 rue de Sèze 69006 LYON – France. Contents 1 Summary ...................................................................................................................................... 2 1.1 2G/3G/4G nPerf Score .......................................................................................................... 2 1.2 Our analysis ........................................................................................................................... 2 2 Overall results 2G/3G/4G ............................................................................................................. 3 2.1 Data amount and distribution ............................................................................................... 3 2.2 Success rate 2G/3G/4G ........................................................................................................ 4 2.3 Download speed 2G/3G/4G .................................................................................................. 5 2.4 Upload speed 2G/3G/4G ....................................................................................................... 6 2.5 Latency 2G/3G/4G ................................................................................................................ 7 2.6 Browsing test 2G/3G/4G....................................................................................................... 8 2.7 Streaming test -

Meizu Veut Une Place Dans Le Segment “Haut De Gamme Low Cost”
A la une / Tic Un nouveau fabricant chinois de smartphones en Algérie Meizu veut une place dans le segment “haut de gamme low cost” ©D. R. Pour son arrivée officielle en Algérie, le fabricant chinois de produits électroniques Meizu a lancé une série de terminaux mobiles destinés à des amateurs de smartphones haut de gamme à des prix serrés. Depuis sa création en 2003, l’entreprise chinoise Meizu est passée de la fabrication des lecteurs MP3 et MP4 à celle des smartphones. En Algérie, la marque arrive avec focus sur ses plus récents modèles : Pro5, MX5 et M2 Note. Encouragé par l’engouement des utilisateurs algériens envers les terminaux portables chinois, Oualid Zaïm, premier responsable marketing de la société Matos Import, a indiqué lors d’une rencontre avec la presse nationale, qu’il a fallu trois années de discussion pour arracher, à la maison mère, le statut de distributeur exclusif de la marque chinoise en Algérie. “Nous sommes très confiants quant au succès de nos produits en Algérie. Notre ambition est d’arriver à vendre cent mille unités par an. Un marketing local, une commercialisation ciblée et un service après-vente à la hauteur des attentes des consommateurs, seront nos activités les plus importantes” a-t-il dit. Le dernier né des smartphones haut de gamme de la société Meizu a été dévoilé par son représentant algérien. Il s’agit du Meizu Pro 5, le terminal intelligeant le plus fin au monde grâce à son boîtier de 7.5 millimètres d’épaisseur. Il est doté d’un écran XXL Amoled de 5.7 pouces qui affiche une définition Full HD (1920 x 1080 pixels) pour une densité de 386 pixels par pouce et comporte une vaste gamme de composants et fonctionnalités intéressantes. -

Тотальный Trade-In (Гаджет По Обмену)» (Далее По Тексту – «Правила»)
ПРАВИЛА Акции «Тотальный Trade-In (Гаджет по обмену)» (далее по тексту – «Правила») 1. Общие положения. 1.1. Акция – рекламное мероприятие, проводимое Организатором в соответствии с настоящими Правилами. Акция не является стимулирующим мероприятием, подпадающего под действие ст.9 ФЗ «О рекламе». 1.2. Организатор – юридическое лицо, указанное в соответствии с настоящими Правилами как Организатор Акции. 1.3. Программа Трейд-ин – постоянная услуга, которая включает процесс сдачи покупателем Бывшего в употреблении Товара с одновременным приобретением Нового Товара. 1.4. Белмонт – ООО «БЕЛМОНТ», ОГРН: 5167746493547, 115035, г. Москва, Овчинниковская набережная, д. 20, стр. 2, ком. 23, являющееся авторизованным партнером компании Apple, организующее на территории РФ Программу Трейд-ин. 1.5. Смарт-Базар - ООО «Цифровые девайсы», ОГРН: 1197746757944, 127006, г. Москва, переулок Оружейный, д.41, ЭТАЖ 6 ОФИС 6.18, организующее на территории РФ Программу Трейд-ин. 1.6. Потребитель – дееспособное физическое лицо, достигшее возраста 18-ти лет (либо не достигшее 18 лет, но приобретшее дееспособность в полном объёме в порядке, предусмотренном действующим законодательством РФ), владеющее на праве собственности Бывшим в употреблении Товаром. 1.7. Участник – Потребитель, получивший статус Участника в соответствии с настоящими Правилами. 1.8. Салоны сети Организатора – салоны связи, работающие под товарным знаком «Связной», «Связной3» и/или «Евросеть» и перечисленные на сайте Организатора. 1.9. Бывший в употреблении Товар (далее также Б/у Товар) – смартфоны и планшеты под товарными знаками Apple, Samsung, Huawei, LG и Sony, перечисленные в Приложении № 1 к настоящим Правилам, принадлежащие Потребителям на праве собственности, который Потребитель вправе сдать Белмонту или Смарт-Базару, получив за него Выкупную цену, с учётом ограничений и требований, указанных в Приложении № 2 к настоящим Правилам.