Cray System Monitoring: Successes, Requirements, and Priorities
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

An Operational Perspective on a Hybrid and Heterogeneous Cray XC50 System
An Operational Perspective on a Hybrid and Heterogeneous Cray XC50 System Sadaf Alam, Nicola Bianchi, Nicholas Cardo, Matteo Chesi, Miguel Gila, Stefano Gorini, Mark Klein, Colin McMurtrie, Marco Passerini, Carmelo Ponti, Fabio Verzelloni CSCS – Swiss National Supercomputing Centre Lugano, Switzerland Email: {sadaf.alam, nicola.bianchi, nicholas.cardo, matteo.chesi, miguel.gila, stefano.gorini, mark.klein, colin.mcmurtrie, marco.passerini, carmelo.ponti, fabio.verzelloni}@cscs.ch Abstract—The Swiss National Supercomputing Centre added depth provides the necessary space for full-sized PCI- (CSCS) upgraded its flagship system called Piz Daint in Q4 e daughter cards to be used in the compute nodes. The use 2016 in order to support a wider range of services. The of a standard PCI-e interface was done to provide additional upgraded system is a heterogeneous Cray XC50 and XC40 system with Nvidia GPU accelerated (Pascal) devices as well as choice and allow the systems to evolve over time[1]. multi-core nodes with diverse memory configurations. Despite Figure 1 clearly shows the visible increase in length of the state-of-the-art hardware and the design complexity, the 37cm between an XC40 compute module (front) and an system was built in a matter of weeks and was returned to XC50 compute module (rear). fully operational service for CSCS user communities in less than two months, while at the same time providing significant improvements in energy efficiency. This paper focuses on the innovative features of the Piz Daint system that not only resulted in an adaptive, scalable and stable platform but also offers a very high level of operational robustness for a complex ecosystem. -

New CSC Computing Resources
New CSC computing resources Atte Sillanpää, Nino Runeberg CSC – IT Center for Science Ltd. Outline CSC at a glance New Kajaani Data Centre Finland’s new supercomputers – Sisu (Cray XC30) – Taito (HP cluster) CSC resources available for researchers CSC presentation 2 CSC’s Services Funet Services Computing Services Universities Application Services Polytechnics Ministries Data Services for Science and Culture Public sector Information Research centers Management Services Companies FUNET FUNET and Data services – Connections to all higher education institutions in Finland and for 37 state research institutes and other organizations – Network Services and Light paths – Network Security – Funet CERT – eduroam – wireless network roaming – Haka-identity Management – Campus Support – The NORDUnet network Data services – Digital Preservation and Data for Research Data for Research (TTA), National Digital Library (KDK) International collaboration via EU projects (EUDAT, APARSEN, ODE, SIM4RDM) – Database and information services Paituli: GIS service Nic.funet.fi – freely distributable files with FTP since 1990 CSC Stream Database administration services – Memory organizations (Finnish university and polytechnics libraries, Finnish National Audiovisual Archive, Finnish National Archives, Finnish National Gallery) 4 Current HPC System Environment Name Louhi Vuori Type Cray XT4/5 HP Cluster DOB 2007 2010 Nodes 1864 304 CPU Cores 10864 3648 Performance ~110 TFlop/s 34 TF Total memory ~11 TB 5 TB Interconnect Cray QDR IB SeaStar Fat tree 3D Torus CSC -

A Scheduling Policy to Improve 10% of Communication Time in Parallel FFT
A scheduling policy to improve 10% of communication time in parallel FFT Samar A. Aseeri Anando Gopal Chatterjee Mahendra K. Verma David E. Keyes ECRC, KAUST CC, IIT Kanpur Dept. of Physics, IIT Kanpur ECRC, KAUST Thuwal, Saudi Arabia Kanpur, India Kanpur, India Thuwal, Saudi Arabia [email protected] [email protected] [email protected] [email protected] Abstract—The fast Fourier transform (FFT) has applications A. FFT Algorithm in almost every frequency related studies, e.g. in image and signal Forward Fourier transform is given by the following equa- processing, and radio astronomy. It is also used to solve partial differential equations used in fluid flows, density functional tion. 3 theory, many-body theory, and others. Three-dimensional N X (−ikxx) (−iky y) (−ikz z) 3 f^(k) = f(x; y; z)e e e (1) FFT has large time complexity O(N log2 N). Hence, parallel algorithms are made to compute such FFTs. Popular libraries kx;ky ;kz 3 perform slab division or pencil decomposition of N data. None The beauty of this sum is that k ; k ; and k can be summed of the existing libraries have achieved perfect inverse scaling x y z of time with (T −1 ≈ n) cores because FFT requires all-to-all independent of each other. These sums are done at different communication and clusters hitherto do not have physical all- to-all connections. With advances in switches and topologies, we now have Dragonfly topology, which physically connects various units in an all-to-all fashion. -

HP/NVIDIA Solutions for HPC Compute and Visualization
HP Update Bill Mannel VP/GM HPC & Big Data Business Unit Apollo Servers © Copyright 2015 Hewlett-Packard Development Company, L.P. The information contained herein is subject to change without notice. The most exciting shifts of our time are underway Security Mobility Cloud Big Data Time to revenue is critical Decisions Making IT critical Business needs must be rapid to business success happen anywhere Change is constant …for billion By 2020 billion 30 devices 8 people trillion GB million 40 data 10 mobile apps 2 © Copyright 2015 Hewlett-Packard Development Company, L.P. The information contained herein is subject to change without notice. HP’s compute portfolio for better IT service delivery Software-defined and cloud-ready API HP OneView HP Helion OpenStack RESTful APIs WorkloadWorkload-optimized Optimized Mission-critical Virtualized &cloud Core business Big Data, HPC, SP environments workloads applications & web scalability Workloads HP HP HP Apollo HP HP ProLiant HP Integrity HP Integrity HP BladeSystem HP HP HP ProLiant SL Moonshot Family Cloudline scale-up blades & Superdome NonStop MicroServer ProLiant ML ProLiant DL Density and efficiency Lowest Cost Convergence Intelligence Availability to scale rapidly built to Scale for continuous business to accelerate IT service delivery to increase productivity Converged Converged network Converged management Converged storage Common modular HP Networking HP OneView HP StoreVirtual VSA architecture Global support and services | Best-in-class partnerships | ConvergedSystem 3 © Copyright 2015 Hewlett-Packard Development Company, L.P. The information contained herein is subject to change without notice. Hyperscale compute grows 10X faster than the total market HPC is a strategic growth market for HP Traditional Private Cloud HPC Service Provider $50 $40 36% $30 50+% $B $20 $10 $0 2013 2014 2015 2016 2017 4 © Copyright 2015 Hewlett-Packard Development Company, L.P. -

CRAY-2 Design Allows Many Types of Users to Solve Problems That Cannot Be Solved with Any Other Computers
Cray Research's mission is to lead in the development and marketingof high-performancesystems that make a unique contribution to the markets they serve. For close toa decade, Cray Research has been the industry leader in large-scale computer systems. Today, the majority of supercomputers installed worldwide are Cray systems. These systems are used In advanced research laboratories around the world and have gained strong acceptance in diverse industrial environments. No other manufacturer has Cray Research's breadth of success and experience in supercomputer development. The company's initial product, the GRAY-1 Computer System, was first installed in 1978. The CRAY-1 quickly established itself as the standard of value for large-scale computers and was soon recognized as the first commercially successful vector processor. For some time previously, the potential advantagee af vector processing had been understood, but effective Dractical imolementation had eluded com~uterarchitects. The CRAY-1 broke that barrier, and today vect~rization'techni~uesare used commonly by scientists and engineers in a widevariety of disciplines. With its significant innovations in architecture and technology, the GRAY-2 Computer System sets the standard for the next generation of supercomputers. The CRAY-2 design allows many types of users to solve problems that cannot be solved with any other computers. The GRAY-2 provides an order of magnitude increase in performanceaver the CRAY-1 at an attractive price/performance ratio. Introducing the CRAY-2 Computer System The CRAY-2 Computer System sets the standard for the next generation of supercomputers. It is characterized by a large Common Memory (256 million 64-bit words), four Background Processors, a clock cycle of 4.1 nanoseconds (4.1 billionths of a second) and liquid immersion cooling. -

Revolution: Greatest Hits
REVOLUTION: GREATEST HITS SHORT ON TIME? VISIT THESE OBJECTS INSIDE THE REVOLUTION EXHIBITION FOR A QUICK OVERVIEW REVOLUTION: PUNCHED CARDS REVOLUTION: BIRTH OF THE COMPUTER REVOLUTION: BIRTH OF THE COMPUTER REVOLUTION: REAL-TIME COMPUTING Hollerith Electric ENIAC, 1946 ENIGMA, ca. 1935 Raytheon Apollo Guidance Tabulating System, 1890 Used in World War II to calculate Few technologies were as Computer, 1966 This device helped the US gun trajectories, only a few piec- decisive in World War II as the This 70 lb. box, built using the government complete the 1890 es remain of this groundbreaking top-secret German encryption new technology of Integrated census in record time and, in American computing system. machine known as ENIGMA. Circuits (ICs), guided Apollo 11 the process, launched the use of ENIAC used 18,000 vacuum Breaking its code was a full-time astronauts to the Moon and back in July of 1969, the first manned punched cards in business. IBM tubes and took several days task for Allied code breakers who moon landing in human history. used the Hollerith system as the to program. invented remarkable comput- The AGC was a lifeline for the basis of its business machines. ing machines to help solve the astronauts throughout the eight ENIGMA riddle. day mission. REVOLUTION: MEMORY & STORAGE REVOLUTION: SUPERCOMPUTERS REVOLUTION: MINICOMPUTERS REVOLUTION: AI & ROBOTICS IBM RAMAC Disk Drive, 1956 Cray-1 Supercomputer, 1976 Kitchen Computer, 1969 SRI Shakey the Robot, 1969 Seeking a faster method of The stunning Cray-1 was the Made by Honeywell and sold by Shakey was the first robot that processing data than using fastest computer in the world. -

Supercomputing
DepartmentDepartment ofof DefenseDefense HighHigh PerformancePerformance ComputingComputing ModernizationModernization ProgramProgram Supercomputing:Supercomputing: CrayCray Henry,Henry, DirectorDirector HPCMP,HPCMP, PerformancePerformance44 May MayMeasuresMeasures 20042004 andand OpportunitiesOpportunities CrayCray J.J. HenryHenry AugustAugust 20042004 http://http://www.hpcmo.hpc.milwww.hpcmo.hpc.mil 20042004 HPECHPEC ConferenceConference PresentationPresentation OutlineOutline zz WhatWhat’sWhat’’ss NewNew inin thethe HPCMPHPCMP 00NewNew hardwarehardware 00HPCHPC SoftwareSoftware ApplicationApplication InstitutesInstitutes 00CapabilityCapability AllocationsAllocations 00OpenOpen ResearchResearch SystemsSystems 00OnOn-demand-demand ComputingComputing zz PerformancePerformance MeasuresMeasures -- HPCMPHPCMPHPCMP zz PerformancePerformance MeasuresMeasures –– ChallengesChallengesChallenges && OpportunitiesOpportunities HPCMPHPCMP CentersCenters 19931993 20042004 Legend MSRCs ADCs and DDCs TotalTotal HPCMHPCMPP EndEnd-of-Year-of-Year ComputationalComputational CapabilitiesCapabilities 80 MSRCs ADCs 120,000 70 13.1 MSRCs DCs 100,000 60 23,327 80,000 Over 400X Growth 50 s F Us 60,000 40 eak G HAB 12.1 P 21,759 30 59.3 40,000 77,676 5,86 0 20,000 4,393 30,770 20 2.6 21,946 1, 2 76 3,171 26.6 18 9 3 6 0 688 1, 16 8 2,280 8,03212 , 0 14 2.7 18 1 47 10 0 1,944 3,477 10 15.7 0 50 400 1,200 10.6 3 4 5 6 7 8 9 0 1 2 3 4 0 199 199 199 199 199 199 199 200 200 200 200 200 FY 01 FY 02 FY 03 FY 04 Year Fiscal Year (TI-XX) HPCMPHPCMP SystemsSystems (MSRCs)(MSRCs)20042004 -

View Annual Report
Fellow Shareholders, Headlined by strong growth in revenue and profitability, we had one of our best years ever in 2015, executing across each of our major focus areas and positioning our company for continued growth into the future. We achieved another year of record revenue, growing by nearly 30 percent compared to 2014. In fact, our revenue in 2015 was more than three times higher than just four years prior — driven by growth in both our addressable market and market share. Over the last five years, we have transformed from a company solely focused on the high-end of the supercomputing market — where we are now the clear market leader — to a company with multiple product lines serving multiple markets. We provide our customers with powerful computing, storage and analytics solutions that give them the tools to advance their businesses in ways never before possible. During 2015, we installed supercomputing and storage solutions at a number of customers around the world. In the U.S., we completed the first phase of the massive new “Trinity” system at Los Alamos National Laboratory. This Cray XC40 supercomputer with Sonexion storage serves as the National Nuclear Security Administration’s flagship supercomputer, supporting all three of the NNSA’s national laboratories. We installed the first petaflop supercomputer in India at the Indian Institute of Science. In Europe, we installed numerous XC and storage solutions, including a significant expansion of the existing XC40 supercomputer at the University of Stuttgart in Germany. This new system nearly doubles their computing capacity and is currently the fastest supercomputer in Germany. -
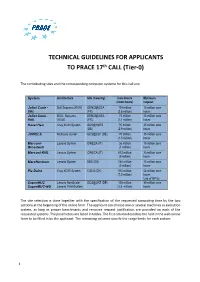
TECHNICAL GUIDELINES for APPLICANTS to PRACE 17Th CALL
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 17th CALL (T ier-0) The contributing sites and the corresponding computer systems for this call are: System Architecture Site (Country) Core Hours Minimum (node hours) request Joliot Curie - Bull Sequana X1000 GENCI@CEA 134 million 15 million core SKL (FR) (2.8 million) hours Joliot Curie - BULL Sequana GENCI@CEA 72 million 15 million core KNL X1000 (FR) (1,1 million) hours Hazel Hen Cray XC40 System GCS@HLRS 70 million 35 million core (DE) (2.9 million) hours JUWELS Multicore cluster GCS@JSC (DE) 70 million 35 million core (1.5 million) hours Marconi- Lenovo System CINECA (IT) 36 million 15 million core Broadwell (1 million) hours Marconi-KNL Lenovo System CINECA (IT) 612 million 30 million core (9 million) hours MareNostrum Lenovo System BSC (ES) 240 million 15 million core (5 million) hours Piz Daint Cray XC50 System CSCS (CH) 510 million 68 million core (7.5 million) hours Use of GPUs SuperMUC Lenovo NextScale/ GCS@LRZ (DE) 105 million 35 million core SuperMUC-NG Lenovo ThinkSystem (3.8 million) hours The site selection is done together with the specification of the requested computing time by the two sections at the beginning of the online form. The applicant can choose one or several machines as execution system, as long as proper benchmarks and resource request justification are provided on each of the requested systems. The parameters are listed in tables. The first column describes the field in the web online form to be filled in by the applicant. The remaining columns specify the range limits for each system. -

NQE Release Overview RO–5237 3.3
NQE Release Overview RO–5237 3.3 Document Number 007–3795–001 Copyright © 1998 Silicon Graphics, Inc. and Cray Research, Inc. All Rights Reserved. This manual or parts thereof may not be reproduced in any form unless permitted by contract or by written permission of Silicon Graphics, Inc. or Cray Research, Inc. RESTRICTED RIGHTS LEGEND Use, duplication, or disclosure of the technical data contained in this document by the Government is subject to restrictions as set forth in subdivision (c) (1) (ii) of the Rights in Technical Data and Computer Software clause at DFARS 52.227-7013 and/or in similar or successor clauses in the FAR, or in the DOD or NASA FAR Supplement. Unpublished rights reserved under the Copyright Laws of the United States. Contractor/manufacturer is Silicon Graphics, Inc., 2011 N. Shoreline Blvd., Mountain View, CA 94043-1389. Autotasking, CF77, CRAY, Cray Ada, CraySoft, CRAY Y-MP, CRAY-1, CRInform, CRI/TurboKiva, HSX, LibSci, MPP Apprentice, SSD, SUPERCLUSTER, UNICOS, and X-MP EA are federally registered trademarks and Because no workstation is an island, CCI, CCMT, CF90, CFT, CFT2, CFT77, ConCurrent Maintenance Tools, COS, Cray Animation Theater, CRAY APP, CRAY C90, CRAY C90D, Cray C++ Compiling System, CrayDoc, CRAY EL, CRAY J90, CRAY J90se, CrayLink, Cray NQS, Cray/REELlibrarian, CRAY S-MP, CRAY SSD-T90, CRAY T90, CRAY T3D, CRAY T3E, CrayTutor, CRAY X-MP, CRAY XMS, CRAY-2, CSIM, CVT, Delivering the power . ., DGauss, Docview, EMDS, GigaRing, HEXAR, IOS, ND Series Network Disk Array, Network Queuing Environment, Network Queuing Tools, OLNET, RQS, SEGLDR, SMARTE, SUPERLINK, System Maintenance and Remote Testing Environment, Trusted UNICOS, UNICOS MAX, and UNICOS/mk are trademarks of Cray Research, Inc. -

CXML Reference Guide Is the Complete Reference Manual for CXML
Compaq Extended Math Library Reference Guide January 2001 This document describes the Compaq® Extended Math Library (CXML). CXML is a set of high-performance mathematical routines designed for use in numerically intensive scientific and engineering applications. This document is a guide to using CXML and provides reference information about CXML routines. Revision/Update Information: This document has been revised for this release of CXML. Compaq Computer Corporation Houston, Texas © 2001 Compaq Computer Corporation Compaq, the COMPAQ logo, DEC, DIGITAL, VAX, and VMS are registered in the U.S. Patent and Trademark Office. Alpha, Tru64, DEC Fortran, OpenVMS, and VAX FORTRAN are trademarks of Compaq Information Technologies, L.P. in the United States and other countries. Adobe, Adobe Acrobat, and POSTSCRIPT are registered trademarks of Adobe Systems Incorporated. CRAY is a registered trademark of Cray Research, Incorporated. IBM is a registered trademark of International Business Machines Corporation. IEEE is a registered trademark of the Institute of Electrical and Electronics Engineers Inc. IMSL and Visual Numerics are registered trademarks of Visual Numerics, Inc. Intel and Pentium are trademarks of Intel Corporation. KAP is a registered trademark of Kuck and Associates, Inc. Linux is a registered trademark of Linus Torvalds. Microsoft, Windows, and Windows NT are either trademarks or registered trademarks of Microsoft Corporation in the United States and other countries. OpenMP and the OpenMP logo are trademarks of OpenMP Architecture Review Board. SUN, SUN Microsystems, and Java are registered trademarks of Sun Microsystems, Inc. UNIX, Motif, OSF, OSF/1, OSF/Motif, and The Open Group are trademarks of The Open Group. All other trademarks and registered trademarks are the property of their respective holders. -

Cray XC40 Power Monitoring and Control for Knights Landing
Cray XC40 Power Monitoring and Control for Knights Landing Steven J. Martin, David Rush Matthew Kappel, Michael Sandstedt, Joshua Williams Cray Inc. Cray Inc. Chippewa Falls, WI USA St. Paul, MN USA {stevem,rushd}@cray.com {mkappel,msandste,jw}@cray.com Abstract—This paper details the Cray XC40 power monitor- This paper is organized as follows: In section II, we ing and control capabilities for Intel Knights Landing (KNL) detail blade-level Hardware Supervisory System (HSS) ar- based systems. The Cray XC40 hardware blade design for Intel chitecture changes introduced to enable improved telemetry KNL processors is the first in the XC family to incorporate enhancements directly related to power monitoring feedback gathering capabilities on Cray XC40 blades with Intel KNL driven by customers and the HPC community. This paper fo- processors. Section III provides information on updates to cuses on power monitoring and control directly related to Cray interfaces available for power monitoring and control that blades with Intel KNL processors and the interfaces available are new for Cray XC40 systems and the software released to users, system administrators, and workload managers to to support blades with Intel KNL processors. Section IV access power management features. shows monitoring and control examples. Keywords-Power monitoring; power capping; RAPL; energy efficiency; power measurement; Cray XC40; Intel Knights II. ENHANCED HSS BLADE-LEVEL MONITORING Landing The XC40 KNL blade incorporates a number of en- hancements over previous XC blade types that enable the I. INTRODUCTION collection of power telemetry in greater detail and with Cray has provided advanced power monitoring and control improved accuracy.