! ! Visual Sensory Substitution: Initial Testing of a Custom Built Visual to Tactile Device Dustin Wayne Venini Bachelor of Science
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

THE 11TH WORLD CONGRESS on the Relationship Between Neurobiology and Nano-Electronics Focusing on Artificial Vision
THE 11TH WORLD CONGRESS On the Relationship Between Neurobiology and Nano-Electronics Focusing on Artificial Vision November 10-12, 2019 The Henry, An Autograph Collection Hotel DEPARTMENT OF OPHTHALMOLOGY Detroit Institute of Ophthalmology Thank you to Friends of Vision for your support of the Bartimaeus Dinner The Eye and The Chip 2 DEPARTMENT OF OPHTHALMOLOGY Detroit Institute of Ophthalmology TABLE OF CONTENTS WELCOME LETTER—PAUL A. EDWARDS. M.D. ....................................................... WELCOME LETTER—PHILIP C. HESSBURG, M.D. ..................................................... DETROIT INSTITUTE OF OPHTHALMOLOGY ......................................................... ORGANIZING COMMITTEE/ACCREDITATION STATEMENT ............................................... CONGRESS 3-DAY SCHEDULE ................................................................... PLATFORM SPEAKER LIST ...................................................................... SPEAKER ABSTRACTS .......................................................................... POSTER PRESENTERS’ LIST ..................................................................... POSTER ABSTRACTS ........................................................................... BARTIMAEUS AWARD—PREVIOUS RECIPIENTS ...................................................... SUPPORTING SPONSORS . Audio-Visual Services Provided by Dynasty Media Network http://dynastymedianetwork.com/ The Eye and The Chip Welcome On behalf of the Henry Ford Health System and the Department of Ophthalmology, -

Electronic Approaches to Restoration of Sight
Home Search Collections Journals About Contact us My IOPscience Electronic approaches to restoration of sight This content has been downloaded from IOPscience. Please scroll down to see the full text. 2016 Rep. Prog. Phys. 79 096701 (http://iopscience.iop.org/0034-4885/79/9/096701) View the table of contents for this issue, or go to the journal homepage for more Download details: IP Address: 171.64.108.170 This content was downloaded on 09/08/2016 at 17:30 Please note that terms and conditions apply. IOP Reports on Progress in Physics Reports on Progress in Physics Rep. Prog. Phys. Rep. Prog. Phys. 79 (2016) 096701 (29pp) doi:10.1088/0034-4885/79/9/096701 79 Review 2016 Electronic approaches to restoration of sight © 2016 IOP Publishing Ltd G A Goetz1,2 and D V Palanker1,3 RPPHAG 1 Hansen Experimental Physics Laboratory, Stanford University, Stanford, CA 94305, USA 2 Neurosurgery, Stanford University, Stanford, CA 94305, USA 096701 3 Ophthalmology, Stanford University, Stanford, CA 94305, USA E-mail: [email protected] and [email protected] G A Goetz and D V Palanker Received 11 November 2014, revised 11 April 2016 Accepted for publication 23 May 2016 Electronic approaches to restoration of sight Published 9 August 2016 Abstract Printed in the UK Retinal prostheses are a promising means for restoring sight to patients blinded by the gradual atrophy of photoreceptors due to retinal degeneration. They are designed to reintroduce ROP information into the visual system by electrically stimulating surviving neurons in the retina. This review outlines the concepts and technologies behind two major approaches to retinal prosthetics: epiretinal and subretinal. -

James Phillips CV
Curriculum Vitae James Otho Phillips, Ph.D. Personal Data Place of Birth Portland, Oregon Citizenship USA Education: Pomona College, B.A. 1977 Claremont, CA English literature University of Washington Ph.D. 1993 Seattle, WA Psychology and Physiology > separate qualifying and general examinations in each discipline, doctoral committee from Arts and Sciences and from School of Medicine, and two-part dissertation containing behavioral and neurophysiological studies > Psychology specialization in neuropsychology of memory and learning > Physiology specialization in oculomotor and vestibular neurophysiology Postgraduate Training: Post-doctoral and Senior Fellowships 1993-1997 Department of Physiology and Biophysics University of Washington, Seattle, WA Faculty Positions Held: Research Asst. Professor 1998-2002 Department of Otolaryngology - HNS University of Washington, Seattle, WA Research Asst. Professor 1998-2002 Division of Ophthalmology, Department of Surgery Children’s Hospital and Regional Medical Center Seattle, WA Research Assoc. Professor 2003-2016 Department of Otolaryngology - HNS University of Washington, Seattle, WA Research Assoc. Professor 2003-2016 Division of Ophthalmology, Department of Surgery Children’s Hospital and Regional Medical Center Seattle, WA Adjunct Research Associate Professor 2016 Speech and Hearing Sciences University of Washington, Seattle, WA Phillips, J.O. 2 Hospital Positions Held: Vestibular-Oculomotor Physiologist, Medical Staff, Consulting 2000-2016 Division of Ophthalmology, Department of Surgery, -

Connecting Brain Computer Interface Technology with Ubiquitous Complex Event Processing
Connecting Brain Computer Interface Technology with Ubiquitous Complex Event Processing – Aspects of New Applications in the Fields of Biology, Brain Research and Medicine Extended Abstract Yuri Danilov Kurt Kaczmarek Mitchell Tyler TCNL, room M1012, 1550 University Ave, Biomedical Engineering Department, UW- Madison, USA [email protected] , … Rainer von Ammon CITT GmbH, Konrad-Adenauerallee 30, D-93051 Regensburg, Germany [email protected] Outline (to be replaced by abstract in the final paper, Springer style) 1. Why connecting BCI with U-CEP? 2. BCI as interface to and from the brain 3. The role of U-CEP 4. Infrastructure for connecting BCI and U-CEP: Body Area Networks and Wearable Technologies 5. The appropriate computing power - cognitive computing chips, combining digital ‘neurons’ and ‘synapses’ 5. New applications based on connecting BCI and U-CEP 6. BrainPort technology 7. CN-NINM technology 8. Example “Depression (or another example)”: Defining biomarkers, event modelling of biosensors as event sources and process modelling for influencing the protein-machinery Why connecting BCI with U-CEP? The edBPM/U-CEP workshop series has so far focused on the topics of connecting Internet of Services and Things with the management of business processes and the Future and Emerging Technologies as addressed by the ISTAG Recommendations of the European FET-F 2020 and Beyond Initiative [1]. Such FET challenges are not longer limited to business processes, but focus on new ideas in order to connect processes on the basis of CEP with disciplines of Cell Biology, Epigenetics, Brain Research, Robotics, Emergency Management, SocioGeonomics, Bio- and Quantum Computing – summarized under the concept of U-CEP [2]. -

MTAA Submission to the Inquiry Into Approval Processes for New Drugs and Novel Medical Technologies in Australia November 2020
MTAA Submission to the Inquiry into approval processes for new drugs and novel medical technologies in Australia November 2020 0 Medical Technology Association of Australia The Medical Technology Association of Australia (MTAA) is the national association representing companies in the MedTech industry. MTAA aims to ensure the benefits of modern, innovative and reliable medical technology are delivered effectively to provide better health outcomes to the Australian community. MTAA represents manufacturers and suppliers of MedTech used in the diagnosis, prevention, MedTech helps more than treatment and management of disease and disability. The range of MedTech is diverse with products 2.5 million patients per year. ranging from everyday items such as syringes, In 2019 over 3 million through to high technology implanted devices such as pacemakers, and orthopaedic implants. Products also medical devices were used include hospital and diagnostic imaging equipment just to treat Australians with such as ultrasounds and MRI machines. private health insurance. MTAA members distribute the majority of products used in the diagnosis and treatment of disease and disability in Australia. Our member companies also play a vital role in providing healthcare professionals with essential education and training to ensure the safe and effective use of MedTech. MedTech The MedTech industry is one of the most dynamic manufacturing sectors in Australia and has the potential to provide substantial health gains and highly skilled employment opportunities to Australians and add to Australia's export industry. There are 91 ASX-listed MedTech and pharmaceutical companies in Australia, with a market capitalisation of $94 billion. The MedTech industry in Australia is a substantial employer. -

GIVE-ME: Gamification in Virtual Environments for Multimodal Evaluation- a Framework
GIVE-ME: Gamification In Virtual Environments for Multimodal Evaluation - A Framework Wai Lun Khoo A dissertation submitted to the Graduate Faculty in Computer Science in partial fulfillment of the requirements for the degree of Doctor of Philosophy, The City University of New York. Committee Members: Professor Zhigang Zhu Professor Tony Ro Professor Yingli Tian Dr. Aries Arditi August 30, 2016 c 2016 Wai Lun Khoo All Rights Reserved GIVE-ME: Gamification In Virtual Environments for Multimodal Evaluation - A Framework by Wai Lun Khoo This manuscript has been read and accepted for the Graduate Faculty in Computer Science in satisfaction of the dissertation requirement for the degree of Doctor of Philosophy. Date Professor Zhigang Zhu Chair of Examining Committee Date Professor Robert Haralick Executive Officer Supervisory Committee Professor Zhigang Zhu Professor Tony Ro Professor Yingli Tian Dr. Aries Arditi The City University of New York Abstract GIVE-ME: Gamification In Virtual Environments for Multimodal Evaluation - A Framework by Wai Lun Khoo Advisor: Professor Zhigang Zhu In the last few decades, a variety of assistive technologies (AT) have been developed to im- prove the quality of life of visually impaired people. These include providing an independent means of travel and thus better access to education and places of work. There is, however, no metric for comparing and benchmarking these technologies, especially multimodal sys- tems. In this dissertation, we propose GIVE-ME: Gamification In Virtual Environments for Multimodal Evaluation, a framework which allows for developers and consumers to assess their technologies in a functional and objective manner. This framework is based on three foundations: multimodality, gamification, and virtual reality. -
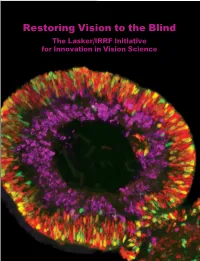
Restoring Vision to the Blind the Lasker/IRRF Initiative for Innovation in Vision Science
Restoring Vision to the Blind The Lasker/IRRF Initiative for Innovation in Vision Science About the Albert and Mary Lasker Foundation: Founded in 1942, the Albert and Mary Lasker Foundation envisions a healthier world through sustained support for basic and clinical medical research. The Foundation works to accomplish its mission through education and advocacy and, most notably, through a prestigious annual awards program, now in its 70th year. Lasker Award winners are selected by their peers, who, like themselves, include the world’s most accomplished and well-respected Cover: Optic vesicle-like structures derived from human induced pluripotent stem cells can self medical research scientists, and thus the award represents a special honor. The Foundation’s education assemble into rudimentary retinal laminae, and following 50 days of differentiation, form an outer and advocacy missions focus on engaging the public and policymakers on the importance of robust neuroblastic layer of proliferating progenitor cells (identified by immunolabeling with the retinal medical research programs and the funding to make them possible. The Lasker Foundation is also progenitor marker VSX2, in red, and the mitotic cell marker Ki67, in green) and an inner layer dedicated to supporting and inspiring the next generation of research scientists. For more information of putative retinal ganglion cells (immunolabeled with HuCD, a marker for post-mitotic neurons, about the Lasker Foundation and its programs, visit http://www.laskerfoundation.org. in purple). Image produced by the Gamm Laboratory, University of Wisconsin School of Medicine and Public Health. Reprinted from: Wright LS, Phillips MJ, Pinilla I, Hei D, Gamm D. Induced pluripotent stem cells as custom therapeutics for retinal repair: Progress and rationale. -

MTAA Submission to the Inquiry Into Approval Processes for New Drugs and Novel Medical Technologies in Australia November 2020
MTAA Submission to the Inquiry into approval processes for new drugs and novel medical technologies in Australia November 2020 0 Medical Technology Association of Australia The Medical Technology Association of Australia (MTAA) is the national association representing companies in the MedTech industry. MTAA aims to ensure the benefits of modern, innovative and reliable medical technology are delivered effectively to provide better health outcomes to the Australian community. MTAA represents manufacturers and suppliers of MedTech used in the diagnosis, prevention, MedTech helps more than treatment and management of disease and disability. The range of MedTech is diverse with products 2.5 million patients per year. ranging from everyday items such as syringes, In 2019 over 3 million through to high technology implanted devices such as pacemakers, and orthopaedic implants. Products also medical devices were used include hospital and diagnostic imaging equipment just to treat Australians with such as ultrasounds and MRI machines. private health insurance. MTAA members distribute the majority of products used in the diagnosis and treatment of disease and disability in Australia. Our member companies also play a vital role in providing healthcare professionals with essential education and training to ensure the safe and effective use of MedTech. MedTech The MedTech industry is one of the most dynamic manufacturing sectors in Australia and has the potential to provide substantial health gains and highly skilled employment opportunities to Australians and add to Australia's export industry. There are 91 ASX-listed MedTech and pharmaceutical companies in Australia, with a market capitalisation of $94 billion. The MedTech industry in Australia is a substantial employer. -
ENGINIUM - the PULSE of SET Is Rightly Called So As It Involves the Blood and Sweat of More Than 100 Members Working Towards Creating This Publication
ENGINIUM - THE PULSE OF SET is rightly called so as it involves the blood and sweat of more than 100 members working towards creating this publication. It is the amalgamation of the literary and artistic segment of the university. Team Enginium work to bring out the annual official student publication of Mody University of Science and Technology. Every year our team of writers, designers, artists, photographers and correspondents strive to generate the most creative content with their grit, determination and hard work. The magazine is a fruit borne out of the year-round work by the team members to write and create articles, stories, poetry, art and photographs. Apart from this, Enginium also organises events, workshops, photography exhibitions, stalls in college fests, collects funds for the magazines and manages other tasks like designing of the team T-shirts, certificates, badges, posters etc. The team is the largest one in the college with right sub-teams, each adding its own flavour and contribution. As a whole, the team is a blend of art, creativity, photography, technical, marketing, journalism and writing prowess. The eight teams are: ● ART TEAM is a group of talented and creative individuals bringing to the magazine a whole lot of sketches, paintings and cartoons. ● CREATIVE TEAM gives the complete look and feel to each and every page of the magazine. From the cover to the last page, how everything looks is taken care of by these people. ● ENGLISH TEAM writes articles, poems and stories. It gives an escape into a world of words. ● HINDI TEAM is to bring back the old times and savour our mother tongue. -
Brain Port Device Will Be Introduced in 2006
BRAINPORT VISION DEVICE By D.SWATHI, Final Year Computer Science And Engineerng, Sri Venkateshwara Engineering College, Contact [email protected] CONTENTS Statistics on the Blind: 37 million: People in the world are blind India (9 million), Africa (7 million) and China (6 million) Every 5 seconds: One person in our world goes blind 75 million: People will be blind by 2020 (if trends continue) Cybernetics Cybernetics is about having a goal and taking action to achieve that goal. "Cybernetics" comes from a Greek word meaning "the art of steering“. Ironically but logically, AI and cybernetics have each gone in and out in the search for machine intelligence So “I Can Read” can be termed as a “Cybernetics System For Disabled (blind)” DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING,SVEC,Suryapet 3 What is Brainport Vision Device? "BrainPort device" is a technology developed in US, which is making the world visible to the ones who lose their sight due to some accidental incidents. Neuroscientists at Wicab, Inc. has developed the BrainPort Vision Device that allows the blinds to “see” using their tougues. Craig Lundberg, 24, is the first British soldier to test the BrainPort system, which is billed as the next best thing to sight. The technology has made the dark-dependent world come alive and independent to Craig Lundberg who completely lost his sight after a grenade attack in Iraq, as he is now able to sense the visuals with his tongue. The soldier admits that his world has been transformed because of the technology. The device which sends visual input through tongue in much the same way that seeing individuals receive visual input through the eyes is called the “Brainport Vision Device”. -

Low Vision and Plasticity: Implications for Rehabilitation Gordon E
VS02CH15-Legge ARI 8 September 2016 17:17 ANNUAL REVIEWS Further Click here to view this article's online features: • Download figures as PPT slides • Navigate linked references • Download citations Low Vision and Plasticity: • Explore related articles • Search keywords Implications for Rehabilitation Gordon E. Legge1 and Susana T.L. Chung2 1Department of Psychology, University of Minnesota, Minneapolis, Minnesota 55455; email: [email protected] 2School of Optometry, University of California, Berkeley, California 94720; email: [email protected] Annu. Rev. Vis. Sci. 2016. 2:321–43 Keywords First published online as a Review in Advance on visual impairment, critical period, visual deprivation, visual acuity, visual July 25, 2016 field, contrast sensitivity, retina, visual cortex The Annual Review of Vision Science is online at vision.annualreviews.org Abstract This article’s doi: Low vision is any type of visual impairment that affects activities of daily 10.1146/annurev-vision-111815-114344 living. In the context of low vision, we define plasticity as changes in brain Annu. Rev. Vis. Sci. 2016.2:321-343. Downloaded from www.annualreviews.org Copyright c 2016 by Annual Reviews. or perceptual behavior that follow the onset of visual impairment and that All rights reserved are not directly due to the underlying pathology. An important goal of low- vision research is to determine how plasticity affects visual performance of everyday activities. In this review, we consider the levels of the visual sys- Access provided by University of Minnesota - Twin Cities Walter Library on 01/07/19. For personal use only. tem at which plasticity occurs, the impact of age and visual experience on plasticity, and whether plastic changes are spontaneous or require explicit training. -

Multimodal Navigation Systems for Users with Visual Impairments—A Review and Analysis
Multimodal Technologies and Interaction Review Multimodal Navigation Systems for Users with Visual Impairments—A Review and Analysis Bineeth Kuriakose ∗ , Raju Shrestha and Frode Eika Sandnes Department of Computer Science, Oslo Metropolitan University, 0167 Oslo, Norway; [email protected] (R.S.); [email protected] (F.E.S.) * Correspondence: [email protected] Received: 27 August 2020; Accepted: 12 October 2020; Published: 16 October 2020 Abstract: Multimodal interaction refers to situations where users are provided with multiple modes for interacting with systems. Researchers are working on multimodality solutions in several domains. The focus of this paper is within the domain of navigation systems for supporting users with visual impairments. Although several literature reviews have covered this domain, none have gone through the research synthesis of multimodal navigation systems. This paper provides a review and analysis of multimodal navigation solutions aimed at people with visual impairments. This review also puts forward recommendations for effective multimodal navigation systems. Moreover, this review also presents the challenges faced during the design, implementation and use of multimodal navigation systems. We call for more research to better understand the users’ evolving modality preferences during navigation. Keywords: navigation; multimodal; blind; visual impairments; accessibility 1. Introduction Navigation is an essential activity in human life. Montello [1] describes navigation as "coordinated and goal-directed movement through the environment by a living entity or intelligent machines." Navigation requires both planning and execution of movements. Several works [2–5], divide navigation into two components: orientation and mobility. Orientation refers to the process of keeping track of position and wayfinding, while mobility refers to obstacle detection and avoidance.