Downloaded from Internet
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Programming Java for OS X
Programming Java for OS X hat’s so different about Java on a Mac? Pure Java applica- tions run on any operating system that supports Java. W Popular Java tools run on OS X. From the developer’s point of view, Java is Java, no matter where it runs. Users do not agree. To an OS X user, pure Java applications that ignore the feel and features of OS X are less desirable, meaning the customers will take their money elsewhere. Fewer sales translates into unhappy managers and all the awkwardness that follows. In this book, I show how to build GUIs that feel and behave like OS X users expect them to behave. I explain development tools and libraries found on the Mac. I explore bundling of Java applications for deployment on OS X. I also discuss interfacing Java with other languages commonly used on the Mac. This chapter is about the background and basics of Java develop- ment on OS X. I explain the history of Java development. I show you around Apple’s developer Web site. Finally, I go over the IDEs commonly used for Java development on the Mac. In This Chapter Reviewing Apple Java History Exploring the history of Apple embraced Java technologies long before the first version of Java on Apple computers OS X graced a blue and white Mac tower. Refugees from the old Installing developer tan Macs of the 1990s may vaguely remember using what was tools on OS X called the MRJ when their PC counterparts were busy using JVMs. Looking at the MRJ stands for Mac OS Runtime for Java. -

Eclipse Project Briefing Materials
[________________________] Eclipse project briefing materials. Copyright (c) 2002, 2003 IBM Corporation and others. All rights reserved. This content is made available to you by Eclipse.org under the terms and conditions of the Common Public License Version 1.0 ("CPL"), a copy of which is available at http://www.eclipse.org/legal/cpl-v10.html The most up-to-date briefing materials on the Eclipse project are found on the eclipse.org website at http://eclipse.org/eclipse/ 200303331 1 EclipseEclipse ProjectProject 200303331 3 Eclipse Project Aims ■ Provide open platform for application development tools – Run on a wide range of operating systems – GUI and non-GUI ■ Language-neutral – Permit unrestricted content types – HTML, Java, C, JSP, EJB, XML, GIF, … ■ Facilitate seamless tool integration – At UI and deeper – Add new tools to existing installed products ■ Attract community of tool developers – Including independent software vendors (ISVs) – Capitalize on popularity of Java for writing tools 200303331 4 Eclipse Overview Another Eclipse Platform Tool Java Workbench Help Development Tools JFace (JDT) SWT Team Your Tool Plug-in Workspace Development Debug Environment (PDE) Their Platform Runtime Tool Eclipse Project 200303331 5 Eclipse Origins ■ Eclipse created by OTI and IBM teams responsible for IDE products – IBM VisualAge/Smalltalk (Smalltalk IDE) – IBM VisualAge/Java (Java IDE) – IBM VisualAge/Micro Edition (Java IDE) ■ Initially staffed with 40 full-time developers ■ Geographically dispersed development teams – OTI Ottawa, OTI Minneapolis, -

Language Interoperability in Control Network Programming
International Journal of Science and Engineering Investigations vol. 7, issue 78, July 2018 ISSN: 2251-8843 Language Interoperability in Control Network Programming Kostadin Kratchanov1, Efe Ergün2 1,2Yaşar University, Izmir, Turkey ([email protected], [email protected]) Abstract - Control Network Programming (CNP) is a There is a number of reasons why language interoperability programming paradigm which is being described with the is highly desirable. For example, if a programmer has to maxim “Primitives + Control Network = Control Network implement a specific feature that has been already implemented program”. It is a type of graphic programming. The Control in another language the corresponding program component can Network is a recursive system of graphs; it can be a purely simply be reused. Some languages are especially fit and descriptive specification of the problem being solved. Clearly, effective in implementing specific features and often have ‘drawing’ the control network does not include any emerged to target particular problem domains. Rich third-party programming. The Primitives are elementary, easily packages for certain languages are available. Also, every understandable and clearly specified actions. Ultimately, they programmer usually has a preferred language in which their have to be programmed. Historically, they are usually coded in expertise and efficiency is better. There are hundreds of Free Pascal. The actual code of the primitives has never been programming languages used and constantly being developed considered important. The essence of an “algorithm” is thus making language interoperability a necessity. represented by its control network. CNP was always meant to Programmers with experience and preferences in different be an easy and fast approach for software application programming languages can easier team up for solving development that actually involves very little real complex tasks. -

Using the Java Bridge
Using the Java Bridge In the worlds of Mac OS X, Yellow Box for Windows, and WebObjects programming, there are two languages in common use: Java and Objective-C. This document describes the Java bridge, a technology from Apple that makes communication between these two languages possible. The first section, ÒIntroduction,Ó gives a brief overview of the bridgeÕs capabilities. For a technical overview of the bridge, see ÒHow the Bridge WorksÓ (page 2). To learn how to expose your Objective-C code to Java, see ÒWrapping Objective-C FrameworksÓ (page 9). If you want to write Java code that references Objective-C classes, see ÒUsing Java-Wrapped Objective-C ClassesÓ (page 6). If you are writing Objective-C code that references Java classes, read ÒUsing Java from Objective-CÓ (page 5). Introduction The original OpenStep system developed by NeXT Software contained a number of object-oriented frameworks written in the Objective-C language. Most developers who used these frameworks wrote their code in Objective-C. In recent years, the number of developers writing Java code has increased dramatically. For the benefit of these programmers, Apple Computer has provided Java APIs for these frameworks: Foundation Kit, AppKit, WebObjects, and Enterprise Objects. They were made possible by using techniques described later in Introduction 1 Using the Java Bridge this document. You can use these same techniques to expose your own Objective-C frameworks to Java code. Java and Objective-C are both object-oriented languages, and they have enough similarities that communication between the two is possible. However, there are some differences between the two languages that you need to be aware of in order to use the bridge effectively. -

Oracle® Fusion Middleware 1 Oracle Jdeveloper System Requirements
Oracle® Fusion Middleware Installation Guide for Oracle JDeveloper 11g Release 1 (11.1.1) E13666-08 January 2011 This document provides information on: ■ Section 1, "Oracle JDeveloper System Requirements" ■ Section 2, "Installing the Oracle JDeveloper Studio Edition" ■ Section 3, "Installing the Oracle JDeveloper Java Edition" ■ Section 4, "Using Oracle JDeveloper on Windows" ■ Section 5, "Using Oracle JDeveloper on Linux and UNIX Systems" ■ Section 6, "Using Oracle JDeveloper on Mac OS X Platforms" ■ Section 7, "Migrating from a Previous Version" ■ Section 8, "Enabling Oracle JDeveloper Extensions" ■ Section 9, "Installing Additional Oracle Fusion Middleware Design Time Components" ■ Section 10, "Setting the User Home Directory" ■ Section 11, "Using Oracle JDeveloper in a Multiuser Environment" ■ Section 12, "Using Oracle WebLogic Server with Oracle JDeveloper" ■ Section 13, "Oracle JDeveloper Certification Information" ■ Section 14, "Oracle JDeveloper Accessibility Information" ■ Section 15, "Uninstalling Oracle JDeveloper" ■ Section 16, "Oracle on the Web" ■ Section 17, "Documentation Accessibility" 1 Oracle JDeveloper System Requirements This release of Oracle JDeveloper is tested and supported on the specific versions Windows, Linux, and Mac OS X, as listed in Section 1.1, "Recommended CPU, Memory, Display, and Hard Drive Configurations". In addition, it is supported on any operating system that supports Sun Java SE Development Kit (JDK) 6 Update 21 or later. ORACLE CONFIDENTIAL. 1.1 Recommended CPU, Memory, Display, and Hard Drive -

Xcode Chapter.Indd
Chapter 1 Xcode Many computer books use Chapter 1 to cover introductory material. Xcode Tools Sensei is not one of those books. I want you to start learning immediately. After reading this chapter you’ll know how to create a project, add files to your project, edit source code, model data, read developer documentation, configure the compiler, and build your project into a working Mac OS X program. Creating a Project Every program you write with Xcode requires a project, no matter how small the program is. An Xcode project contains your program’s source code files and other files Xcode needs to build a working program, such as Interface Builder nib files. To create an Xcode project, choose File > New Project, and the Project Assistant window opens. Xcode has the following project categories: n Action n Application n Audio Units n Bundle n Command-Line Utility n Dynamic Library n External Build System n Framework n J2EE n Java n Kernel Extension n Standard Apple Plug-Ins n Static Library I will go into greater detail on the types of projects shortly, but most of you will be making application projects. After choosing the type of project you want to make, click the Next button. Tell Xcode the name of your project and where you want to store it, then click the Finish button. Congratulations! You’ve created an Xcode project. What Xcode includes in a project depends on the type of project you create. Xcode includes the following files for a Cocoa application: n An Objective C source code file, main.m. -
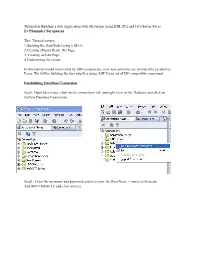
Tutorial on Building a Web Application with Jdeveloper Using EJB, JPA and Java Server Faces by Phaninder Surapaneni
Tutorial on Building a web Application with Jdeveloper using EJB, JPA and Java Server Faces By Phaninder Surapaneni This Tutorial covers: 1.Building the DataModel using EJB3.0. 2.Creating aMasterDetail JSF Page. 3. Creating an Edit Page. 4.Customizing the layout. In this tutorial model is provided by EJB components, view and controller are provided by JavaServer Faces. We will be building the user interface using ADF Faces set of JSF compatible component. Establishing DataBase Connection Step1: Open Jdeveloper ,click on the connections tab and right click on the Database and click on theNew Database Connection. Step2 : Enter the username and password and then enter the Host Name = oracle.cis.ksu.edu And SID = ORACLE and click on next. After the connection is established , test whether the connection works or not and click on finsih. Building a Data Model with EJB 3.0 Step1: Click on the Applications tab and right click on the applications and select New Application. Then a create Application dialog box will appear. Enter the Application name as Ejbapp and enter oracle as Application Package info and select Web Application [JSF, EJB]. Now click on Manage Templates. Step2 : In the Application templates select the view and controller in web Application [JSF, EJB] and in the view and controller pane enter the project name to UserInterface.jpr Step3 : In the Application templates select the Data Model in web Application [JSF, EJB] and in the Data Model Pane enter the project name to EJBModel.jpr. Then click on ok. Creating the Persistence Model Step 1: In the Application Navigator, right click on the EJBModel node and select new Step 2: In the New Gallery dialog box, in the Business Tier, Click on the EJB node then, select Entities from Tables (JPA/EJB 3.0) and click on next. -

Xcode Setup Department of Computer Science & Electrical Engineering
Xcode Setup Department of Computer Science & Electrical Engineering Xcode is an Integrated Development Environment (IDE) provided for free by Apple Inc. to develop Apple Macintosh and Apple iOS applications. While it is optimized for those scenarios, it works well for the types of projects we do in the Computer Science program. An IDE is a development tool consisting of three components: Editor. An editor is a tool designed to help the user create and make changes to a document. A code editor is specifically designed to facilitate writing code. Other common code editors include emacs and vi. Compiler. A compiler translates source code (such as Java or C++) into machine language (such as an .exe or a.out). We use g++ as the compiler in CS 124 and CS 165. Debugger. A debugger is a program that allows the developer to pause execution of program while it is running to see what is going on inside. A debugger enables the developer to look at local variables, see which functions were called (called the “call stack”), peek at memory, and even make changes to the data of the program while it is running. Xcode is an IDE designed to support a wide variety of languages. The “first class” languages include Objective C, C++, and Java. Setup In order to get up-and-running with Xcode, you will need to copy your code to your Mac, install Xcode on your Mac, create a project, link relevant libraries, and run. 1. Copy your files The easiest way to copy your Linux program files to your Mac is with a thumb drive. -

Java (Software Platform) from Wikipedia, the Free Encyclopedia Not to Be Confused with Javascript
Java (software platform) From Wikipedia, the free encyclopedia Not to be confused with JavaScript. This article may require copy editing for grammar, style, cohesion, tone , or spelling. You can assist by editing it. (February 2016) Java (software platform) Dukesource125.gif The Java technology logo Original author(s) James Gosling, Sun Microsystems Developer(s) Oracle Corporation Initial release 23 January 1996; 20 years ago[1][2] Stable release 8 Update 73 (1.8.0_73) (February 5, 2016; 34 days ago) [±][3] Preview release 9 Build b90 (November 2, 2015; 4 months ago) [±][4] Written in Java, C++[5] Operating system Windows, Solaris, Linux, OS X[6] Platform Cross-platform Available in 30+ languages List of languages [show] Type Software platform License Freeware, mostly open-source,[8] with a few proprietary[9] compo nents[10] Website www.java.com Java is a set of computer software and specifications developed by Sun Microsyst ems, later acquired by Oracle Corporation, that provides a system for developing application software and deploying it in a cross-platform computing environment . Java is used in a wide variety of computing platforms from embedded devices an d mobile phones to enterprise servers and supercomputers. While less common, Jav a applets run in secure, sandboxed environments to provide many features of nati ve applications and can be embedded in HTML pages. Writing in the Java programming language is the primary way to produce code that will be deployed as byte code in a Java Virtual Machine (JVM); byte code compil ers are also available for other languages, including Ada, JavaScript, Python, a nd Ruby. -

Visual Studio Code
Visual Studio Code Tips & Tricks Vol. 1 1st Edition – March 2016, Revision 1 (April 2016) © Microsoft 2016 All rights reserved. This document is for informational purposes only. Microsoft Deutschland GmbH · Konrad-Zuse-Str. 1 · D-85716 Unterschleißheim Tel. +49 (0)89 31760 · www.microsoft.com · www.techwiese.de Authors: Tobias Kahlert and Kay Giza · Microsoft Germany Editor: Mathias Schiffer Localization: textoso · www.textoso.com Page 1 of 26 This book expresses the authors’ views and opinions. This document always up-to-date at: http://aka.ms/VSCodeTipsTricks Contents Visual Studio Code? ................................................................................................................................. 4 Preface ..................................................................................................................................................... 5 What is Visual Studio Code? .................................................................................................................... 6 Tip 1 – Getting the Latest and Greatest as a VS Code Insider ................................................................. 6 Tip 2 – Multiple Cursors .......................................................................................................................... 8 Tip 3 – Using the Command Palette to Control VS Code ........................................................................ 8 Tip 4 – Selecting a Language for a File ................................................................................................... -

Using Free Pascal to Create Android Applications
Using Free Pascal to create Android applications Michaël Van Canneyt January 19, 2015 Abstract Since several years, Free pascal can be used to create Android applications. There are a number of ways to do this, each with it’s advantages and disadvantages. In this article, one of the ways to program for Android is explored. 1 Introduction Programming for Android using Free Pascal and Lazarus has been possible since many years, long before Delphi unveiled its Android module. However, it is not as simple a process as creating a traditional Desktop application, and to complicate matters, there are several ways to do it: 1. Using the Android NDK. Google makes the NDK available for tasks that are CPU- intensive (a typical example are opengl apps), but warns that this should not be the standard way of developing Android apps. This is the way Delphi made it’s Android port: Using Firemonkey – which uses OpenGL to draw controls – this is the easiest approach. There is a Lazarus project that aims to do things in a similar manner (using the native-drawn widget set approach). 2. Using the Android SDK: a Java SDK. This is the Google recommended way to create Android applications. This article shows how to create an Android application using the Java SDK. 2 FPC : A Java bytecode compiler The Android SDK is a Java SDK: Android applications are usually written in Java. How- ever, the Free Pascal compiler can compile a pascal program to Java Bytecode. This is done with the help of the JVM cross-compiler. Free Pascal does not distribute this cross-compiler by default (yet), so it must be built from sources. -

Modern Object Pascal Introduction for Programmers
Modern Object Pascal Introduction for Programmers Michalis Kamburelis Table of Contents 1. Why ....................................................................................................................... 3 2. Basics .................................................................................................................... 3 2.1. "Hello world" program ................................................................................. 3 2.2. Functions, procedures, primitive types ....................................................... 4 2.3. Testing (if) ................................................................................................... 6 2.4. Logical, relational and bit-wise operators ................................................... 8 2.5. Testing single expression for multiple values (case) ................................... 9 2.6. Enumerated and ordinal types and sets and constant-length arrays ......... 10 2.7. Loops (for, while, repeat, for .. in) ............................................................ 11 2.8. Output, logging ......................................................................................... 14 2.9. Converting to a string ............................................................................... 15 3. Units .................................................................................................................... 16 3.1. Units using each other .............................................................................. 18 3.2. Qualifying identifiers with