Using Web Honeypots to Study the Attackers Behavior
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

NEWS: Fake Whatsapp App May Have Been Built to Spy on Iphone Users – What You Need to Know a Fake Version of the Whatsapp Mess
NEWS: Fake WhatsApp app may have been built to spy on iPhone users – what you need to know A fake version of the WhatsApp messaging app is suspected of being created by an Italian spyware company to snoop upon individuals and steal sensitive data. The bogus app, uncovered by cybersecurity researchers at Citizen Lab and journalists at Motherboard, appears to be linked to an Italian firm called Cy4gate which develops “lawful interception” technology. https://hotforsecurity.bitdefender.com/blog/fake-whatsapp-app-may-have-been-built-to-spy-on-iphone- users-what-you-need-to-know-25270.html SOC teams spend nearly a quarter of their day handling suspicious emails Security professionals know that responding to relentless, incoming streams of suspicious emails can be a labor-intensive task, but a new study shared exclusively with SC Media in advance indicates just how time- consuming it actually is. Researchers at email security firm Avanan claim to have authored the “first comprehensive research study” that quantifies the amount of time security operations center (SOC) employees spend preventing, responding to, and investigating emails that successfully bypassed default security and are flagged by end users or other reporting mechanisms. https://www.scmagazine.com/home/email-security/soc-teams-spend-nearly-a-quarter-of-their-day- handling-suspicious-emails/ How to motivate employees to take cybersecurity seriously How can we push employees / users to take cybersecurity to heart? Dr. Maria Bada, external behavioral scientist at AwareGO, has been working on the answer for years. After studying media psychology, focusing her Ph.D. on behavior change, and working towards the treatment of excessive internet use in children and adolescents, nearly ten years ago she opted to join Oxford University as a postdoctoral researcher on cyberculture and online behavior. -

Web Shell 101 Joe Schottman Infosecon 2018 Oct
Web Shell 101 Joe Schottman InfoSeCon 2018 Oct. 26, 2018 About Me Senior Security Analyst for BB&T Legal Stuff 2 How To Reach Me @JoeSchottman on Twitter [email protected] www.joeschottman.com Add me on LinkedIn Find me on local Slacks 3 Agenda What is a Web Shell? How do Web Shells work? How can you detect them? Not going to cover how to use them 4 Definitions for this talk 5 If you’re playing security conference bingo 6 First, a diversion Equifax hack ▪ ▪ ▪ 8 Equifax hack 9 Equifax hack 10 Equifax hack 11 “ 12 “ 13 What is a Web Shell? 14 A subset of malware that runs on web servers 15 Used by APT groups 16 But also script kiddies 17 Someone else’s code ▪ PHP ▪ JSP ▪ Perl ▪ Ruby ▪ Python ▪ Shell Scripts ▪ ASP 18 Mostly scripting languages 19 Designed to control your server via HTTP 20 Imagine an evil web application 21 Executes just like your web applications 22 Unless the attacker takes steps to avoid it... 23 Used for different purposes 24 Hidden in different ways 25 How do they get on systems? 26 Web Shells are not the initial attack 27 Why at least two problems? ▪ ▪ ▪ 28 Let’s consider where in the attack Web Shells are used ▪ ▪ 29 Cyber Kill Chain 30 ATT&CK Discovery Lateral movement Collection Exfiltration Command and control 31 ATT&CK 32 Time to engage incident response ▪ ▪ ▪ 33 A funny aside 34 Metasploit makes some Web Shells easy 35 Detecting Web Shells Strategies 38 39 You do get permission before doing research, right? VirusTotal 41 File integrity monitoring 42 In an ideal world.. -

" Detecting Malicious Code in a Web Server "
UNIVERSITY OF PIRAEUS DEPARTMENT OF DIGITAL SYSTEMS Postgraduate Programme "TECHNO-ECONOMIC MANAGEMENT & SECURITY OF DIGITAL SYSTEMS" " Detecting malicious code in a web server " Thesis of Soleas Agisilaos Α.Μ. : MTE14024 Supervisor Professor: Dr. Christoforos Ntantogian Athens, 2016 Table of Contents Abstract ....................................................................................................................................................... 3 1.Introduction .............................................................................................................................................. 4 2.What is a web shell .................................................................................................................................. 5 2.1.Web shell examples ................................................................................................................... 6 2.2.Web shell prevention .............................................................................................................. 24 2.3.What is a backdoor ................................................................................................................. 26 2.4.Known backdoors .................................................................................................................... 31 2.5.Prevent from backdoors ......................................................................................................... 32 3. NeoPi analysis ........................................................................................................................................ -

Mitigating Webshell Attacks Through Machine Learning Techniques
future internet Article Mitigating Webshell Attacks through Machine Learning Techniques You Guo 1, Hector Marco-Gisbert 2,* and Paul Keir 2 1 School of Computing Science and Engineering, Xi’an Technological University, Xi’an 710021, China 2 School of Computing, Engineering and Physical Sciences, University of the West of Scotland, High Street, Paisley PA1 2BE, UK * Correspondence: [email protected]; Tel.:+44-141-849-4418 Received: 10 December 2019; Accepted: 2 January 2020; Published: 14 January 2020 Abstract: A webshell is a command execution environment in the form of web pages. It is often used by attackers as a backdoor tool for web server operations. Accurately detecting webshells is of great significance to web server protection. Most security products detect webshells based on feature-matching methods—matching input scripts against pre-built malicious code collections. The feature-matching method has a low detection rate for obfuscated webshells. However, with the help of machine learning algorithms, webshells can be detected more efficiently and accurately. In this paper, we propose a new PHP webshell detection model, the NB-Opcode (naïve Bayes and opcode sequence) model, which is a combination of naïve Bayes classifiers and opcode sequences. Through experiments and analysis on a large number of samples, the experimental results show that the proposed method could effectively detect a range of webshells. Compared with the traditional webshell detection methods, this method improves the efficiency and accuracy of webshell detection. Keywords: webshell attacks; machine learning; naïve Bayes; opcode sequence 1. Introduction With the development of web technology and the explosive growth of information, web security becomes more and more important. -
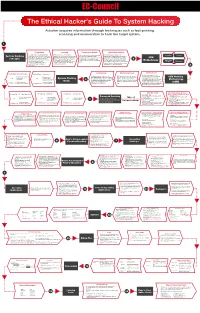
Download the Ethical Hacker's Guide to System Hacking
The Ethical Hacker's Guide To System Hacking Attacker acquires information through techniques such as foot printing, scanning and enumeration to hack the target system. 1 Footprinting Scanning Enumeration Module Vulnerability Analysis It is the process of accumulating data Vulnerability Assessment is an This is a procedure for identifying This is a method of intrusive probing, Footprinting Scanning System Hacking regarding a specific network environment. active hosts, open ports, and unnecessary through which attackers gather examination of the ability of a system or In this phase, the attacker creates a profile services enabled on ports. Attackers use information such as network user lists, application, including current security CEH concepts of the target organization, obtaining different types of scanning, such as port routing tables, security flaws, and procedures, and controls to with stand 2 information such as its IP address range, scanning network scanning, and simple network protocol data (SNMP) assault. Attackers perform this analysis Methodology Vulnerability namespace and employees. Enumeration vulnerability, scanning of target networks data. to identify security loopholes, in the target Analysis Footprinting eases the process of or systems which help in identifying organization’s network, communication system hacking by revealing its possible vulnerabilities. infrastructure, and end systems. vulnerabilities 3 Clearing Logs Maintaining Access Gaining Access Hacking Stage Escalating Privileges Hacking Stage Gaining Access It involves gaining access to To maintain future system access, After gaining access to the target low-privileged user accounts by To acquire the rights of To bypass access CEH Hacking attackers attempt to avoid recognition system, attackers work to maintain cracking passwords through Goal another user or Goal controls to gain System Hacking by legitimate system users. -

Web Shells in PHP, ASP, JSP, Perl, and Coldfusion
Web Shells In PHP, ASP, JSP, Perl, And ColdFusion by Joseph Giron 2009 [email protected] Web shells come in many shapes and sizes. From the most complex of shells such as r57 and c99 to something you came up with while toying around with variables and functions. This paper is to discuss ways of uploading and executing web shells on web servers. We will discuss web shells for: PHP, ASP, Java, Perl, and ColdfFusion. A lot of these sections look the same because they are essentially the same. In a broad generalization of things, exploiting java is no different from exploiting Perl - we're watching certain variables and functions. The main emphasis of this paper however will be on ASP and PHP as they are the most common languages used in web applications today. We will also discuss how I've been able to place web shells on web servers in each language, as well as provide vulnerable code to look for to aid on placing a web shell on the box. With that said, lets get this show on the road! Sections: $ Intro to PHP Web Shells $ RFI's in PHP $ LFI's in PHP $ File Upload Vulnerabilities (covers all languages) $ Web Shells in ASP $ Command Execution Vulnerabilities in ASP $ Web Shells in Perl $ Command Execution Vulnerabilities in Perl $ Web Shells in JSP $ Command Execution Vulnerabilities in JSP $ Web Shells in Cold Fusion $ Command Execution Vulnerabilities in Cold Fusion ############################ Intro to PHP Web Shells ############################ PHP web shells are vital to us hackers if we want to elevate our access or even retain it. -

APT34 Web Shell Attack Targeting UAE Entities
APT34 Web Shell Attack Targeting UAE Entities Security Advisory ADV-19-08 Criticality Critical Advisory Released On 4 April 2019 Impact Uploading a web shell on a victim’s server may allow the attacker to remotely bypass security and gain access to the system. Solution Refer to the solution section. Affected Platforms Web Servers. Summary As the leading trusted secure cyber coordination center in the region, aeCERT has researched and discovered a web shell attack targeting multiple UAE governmental entities. A web shell can allow an attacker to gain privileged access to a system and execute further attacking techniques on the affected server. Threat Details aeCERT has received reports from its intelligence sources indicating that APT34/OilRig has conducted a web shell based attack on multiple UAE government entities. A follow-up advisory containing a technical report of the attack will be provided on a later-date. A web shell script can be uploaded to a web server allowing the attackers to gain remote administration of the machine. A web shell can be uploaded to servers either Internet-facing or internal to the network, afterwards the web shell can be utilized to pivot further towards internal hosts. An attacker can use network scanning/reconnaissance tools to find vulnerabilities in the web server software or the web server itself to upload a web shell. If the attacker successfully uploads the web shell, he can utilize it to leverage other attack methods in order to acquire administrative privileges and issue commands remotely. This grants the attacker the ability to modify, create, delete and launch files as well as granting him the ability to run more scripts, executables or shell commands. -

Detecting and Responding to Advanced Threats Within Exchange Environments
#RSAC SESSION ID: HTA-F02 Detecting and Responding to Advanced Threats within Exchange Environments Steven Adair President Volexity, Inc. @stevenadair #RSAC About Me Founder & President at Volexity Former Director of Cyber Intelligence at Verizon Terremark Previously stood-up and ran NASA’s Cyber Threat Analysis Program (CTAP) Longtime Shadowserver member Co-author of the book Malware Analyst’s Cookbook Assist organizations with combating cyber espionage, suppressing attacks, and eradicating threats from their networks. 2 #RSAC Agenda Why Exchange? What Attackers are Doing with Exchange Easy Mode (Phishing) Advanced Mode ([Web] Shells) Expert Mode (Digital Surveillance, Exfiltration, PowerShell) Detection and Defense Get back in the driver’s seat 3 #RSAC Applying Knowledge from Today’s Presentation By the end of this session.. You should have a firm understanding of how and why Exchange is such a large target and how it is being abused Immediately following this presentation you will be given: A URL with a cheat sheet of all the commands we show in the slides (no need to rush to write them down) My contact information if you have any questions or follow up In the weeks and months to follow you should: Be able to search for signs of compromise on your Exchange server in a going forward basis Tighten security settings to make it more difficult for an intruder to compromise your environment or at least go undetected 4 #RSAC Microsoft Exchange A Critical Target? #RSAC Why Exchange? Absolutely critical infrastructure for most organizations -

Security Operations and Incident Management Knowledge Area (Draft for Comment)
SECURITY OPERATIONS AND INCIDENT MANAGEMENT KNOWLEDGE AREA (DRAFT FOR COMMENT) AUTHOR: Hervé Debar – Telecom SudParis EDITOR: Howard Chivers – University of York REVIEWERS: Douglas Weimer – RHEA Group Magnus Almgren – Chalmers University of Technology Marc Dacier – EURECOM Sushil Jajodia – George Mason University © Crown Copyright, The National Cyber Security Centre 2018. Security Operations and Incident Management Hervé Debar September 2018 INTRODUCTION The roots of Security Operations and Incident Management (SOIM) can be traced to the original report by James Anderson [5] in 1981. This report theorises that full protection of the information and communication infrastructure is impossible. From a technical perspective, it would require complete and ubiquitous control and certification, which would block or limit usefulness and usability. From an economic perspective, the cost of protection measures and the loss related to limited use effectively require an equilibrium between openness and protection, generally in favour of openness. From there on, the report promotes the use of detection techniques to complement protection. The first ten years afterwards saw the development of the original theory of intrusion detection by Denning [18], which still forms the theoretical basis of most of the work detailed in this ka. Security Operations and Incident Management can be seen as an application and automation of the Monitor Analyze Plan Execute - Knowledge (MAPE-K) autonomic computing loop to cybersecu- rity [30], even if this loop was defined later than the initial developments of SOIM. Autonomic com- puting aims to adapt ICT systems to changing operating conditions. The loop, described in figure 1, is driven by events that provide information about the current behaviour of the system. -

Monarx Security Technical Overview Prevent Web Shells Before They Cause Damage
Monarx Security Technical Overview Prevent Web Shells Before They Cause Damage Monarx, Inc. HQ 8 E Broadway Salt Lake City, UT [email protected] 2 Table of Contents Executive Summary 3 Product Overview 4 Architecture and Deployment 9 Protect Feature Spotlight 11 Product Benefits 12 Complimentary Proof of Value 13 Conclusion 13 3 Executive Summary secured, these sites have a vast and diverse attack surface due to the broad and dynamic The Application and Cybersecurity community is set of poorly maintained plugins, themes, and focused on the symptoms of web server malware, extensions that are available. The very thing that not the source. attracts users to open source CMS also creates its largest security problem. The frequency and Internet-facing websites are a prime target for impact of successful attacks continues to rise to attackers to monetize and launch attacks. Web extraordinary levels. Furthermore, 71% of these Application Firewalls, Patching, and Malware attacks use a PHP-based backdoor/web shell Scanning solutions don’t solve the problem. after successful exploitation. When activated, the Despite the best efforts of Hosting Providers shells are used to modify source files, replicate and Enterprises, websites continue to be malicious code, deliver malware to website compromised by hackers. visitors, send spam, mine cryptocurrency, or participate in larger bot activities. Unfortunately, 38.11% of the internet’s websites run a PHP- these types of attacks are also the hardest to based open source CMS, and they are a prime diagnose and clean up. target for attackers. In addition to being poorly Webshell attacks typically have four stages: 1. -

Introduction: Penetration Testing & Ethical Hacking
Penetration Testing 1.0.1 Introduction: Penetration Testing & Ethical Hacking CIRCL TLP:WHITE [email protected] Edition 2021 Overview 0. Setup your personal Penetration-Lab 1. Physical access 2. Introduction into Pentesting 3. Reconnaissance / Information Gathering 4. Scanning 5. Exploiting 6. Password Cracking 7. Web Hacking 8. Post Exploitation 9. Supporting Tools and Techniques 2 of 153 0. Setup your personal Penetration-Lab 3 of 153 0.1 Penetration-Lab considerations Virtual environment advantages: ◦ Cheap and flexible ◦ Portable Why "Host-only" network: • Don't want to expose vulnerable systems • Typos happen during the tests Attacking system: Kali Linux Target systems: Metasploitable 2 WinXP or Windows 7 Linux server Example: VirtualBox 4 of 153 0.2 Prepare a virtual network - VirtualBox Example - Create a "Host-only" network: 1. In VirtualBox select 'File/Host Network Manager... ' to open the preferences window 2. Create a new 'Host Network' 3. Set network parameter which don't conflict with you real networks and press 'Apply' 5 of 153 0.3 Get your attacking system ready Get Installer and Live image of: Kali Linux ! https://www.kali.org/downloads/ $ t r e e ./2021 CIRCL PenLab / +−− k a l i / +−− hdd/ +−− i s o / +−− k a l i −l i n u x −2021.1− i n s t a l l e r −i 3 8 6 . i s o +−− k a l i −l i n u x −2021.1− l i v e −i 3 8 6 . i s o Create your virtual attacking system 6 of 153 0.3 Get your attacking system ready Connect the network adapter to the "Host-only" network Connect the optical drive to the Kali iso image file 7 of 153 0.3 Get your attacking system ready Boot the virtual PC and install Kali linux Optimize the installation options for your needs 8 of 153 0.3 Get your attacking system ready The attacking system should now be part of the 'Host-only' network For Internet (Updates/Tools/Exercises) temporary enable a NAT adapter 9 of 153 0.4 Target system: MSF Download and unpack: Metasploitable 2 ! https://www.kali.org/downloads/ $ t r e e ./2021 CIRCL PenLab / +−− metasploitable −l i n u x −2.0.0. -

Detecting & Defeating the China Chopper Web Shell | Fireeye
REPORT THE LITTLE MALWARE THAT COULD: Detecting and Defeating the China Chopper Web Shell FireEye Labs Authors: Tony Lee, Ian Ahl and Dennis Hanzlik SECURITY REIMAGINED The Little Malware That Could: Detecting and Defeating the China Chopper Web Shell CONTENTS Introduction ............................................................................................................................................................................................................................................................................................................................................... 3 Components ............................................................................................................................................................................................................................................................................................................................................... 3 Capabilities ................................................................................................................................................................................................................................................................................................................................................... 8 Payload Attributes ............................................................................................................................................................................................................................................................................................................