Early Output Quasi-Delay-Insensitive Array Multipliers
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

TX517EVM Users Manual . (Rev. B)
TX517 Dual Channel, 17-Level With RTZ, Integrated Ultrasound Transmitter User's Guide Literature Number: SLOU317B August 2011–Revised December 2011 2 SLOU317B–August 2011–Revised December 2011 Submit Documentation Feedback Copyright © 2011, Texas Instruments Incorporated Contents 1 Default Configuration .......................................................................................................... 9 2 Buttons ............................................................................................................................ 10 3 SYNC Trigger .................................................................................................................... 11 4 Power up TX517 ................................................................................................................ 12 5 Power Supplies for Output Waveform .................................................................................. 13 5.1 Input/Output Pattern ................................................................................................... 14 6 Board Configuration .......................................................................................................... 20 7 EVM Schematics ............................................................................................................... 21 8 Bill of Materials ................................................................................................................. 28 9 PCB Layouts .................................................................................................................... -

STANDARD FREQUENCIES and TIME SIGNALS (Question ITU-R 106/7) (1992-1994-1995) Rec
Rec. ITU-R TF.768-2 1 SYSTEMS FOR DISSEMINATION AND COMPARISON RECOMMENDATION ITU-R TF.768-2 STANDARD FREQUENCIES AND TIME SIGNALS (Question ITU-R 106/7) (1992-1994-1995) Rec. ITU-R TF.768-2 The ITU Radiocommunication Assembly, considering a) the continuing need in all parts of the world for readily available standard frequency and time reference signals that are internationally coordinated; b) the advantages offered by radio broadcasts of standard time and frequency signals in terms of wide coverage, ease and reliability of reception, achievable level of accuracy as received, and the wide availability of relatively inexpensive receiving equipment; c) that Article 33 of the Radio Regulations (RR) is considering the coordination of the establishment and operation of services of standard-frequency and time-signal dissemination on a worldwide basis; d) that a number of stations are now regularly emitting standard frequencies and time signals in the bands allocated by this Conference and that additional stations provide similar services using other frequency bands; e) that these services operate in accordance with Recommendation ITU-R TF.460 which establishes the internationally coordinated UTC time system; f) that other broadcasts exist which, although designed primarily for other functions such as navigation or communications, emit highly stabilized carrier frequencies and/or precise time signals that can be very useful in time and frequency applications, recommends 1 that, for applications requiring stable and accurate time and frequency reference signals that are traceable to the internationally coordinated UTC system, serious consideration be given to the use of one or more of the broadcast services listed and described in Annex 1; 2 that administrations responsible for the various broadcast services included in Annex 2 make every effort to update the information given whenever changes occur. -

The New Digital Multimeters How to Make the Right Buying Judgments
Popular Electronics WORLD'S LARGEST SELLING ELECTRONICS MAGAZINE FEBRUARY 1980 95C Audio Noise Source For Testing Hi -Fi How a Car "Econometer" Can Save Gas A Mastermind Controller for Photo Labs The New Digital Multimeters How to Make the Right Buying Judgments 94LII AN VIS N019ri1N1'4 t 1S ND19NN0) Lc. t) IH)37H) 2100 FM Tuner o9VIY 0111 960)LE00 0 3I) 956095 >00 Speaker System i =i iumnos PRO -20 Dynamic Processor 14024 14278 Issue Ki up Popular Electronics www.americanradiohistory.comAmericanRadioHistory.Com en qua i y counts Do not be fooled by the low prices, the brand Quality metal cases with machine screws and heavy new lab quality frequency counters have inportart guage black anodized aluminum provide RF shield - advantages over instruments costing much more. ing ,light weight and are rugged and attractive - not The models 7010 and 8010 we not old counters repack- economical plastic. aged but 100% new designs using the latest LSI For improved resolution there are 3 gate times state-of -tie -art circuitry. With only 4 IC's, our new "010 on the 7010 and 8 gate times on the 8010 with rapid offers a host of features including 10 Hz to 600 MHz display update. For example, the 10 second gate time operation, ç on digit display, 3 gate times and more. either model will update the continuous display every This outperrorms units using 10-15 IC's at several 10.2 seconds. Some competitive counters offering a times the size and power consumption. The older 10 second gate time may require 20 designs using seconds many more parts increase the possiblity between display updates. -

Time and Frequency Users Manual
A 11 10 3 07512T o NBS SPECIAL PUBLICATION 559 J U.S. DEPARTMENT OF COMMERCE / National Bureau of Standards Time and Frequency Users' Manual NATIONAL BUREAU OF STANDARDS The National Bureau of Standards' was established by an act of Congress on March 3, 1901. The Bureau's overall goal is to strengthen and advance the Nation's science and technology and facilitate their effective application for public benefit. To this end, the Bureau conducts research and provides: (1) a basis for the Nation's physical measurement system, (2) scientific and technological services for industry and government, (3) a technical basis for equity in trade, and (4) technical services to promote public safety. The Bureau's technical work is per- formed by the National Measurement Laboratory, the National Engineering Laboratory, and the Institute for Computer Sciences and Technology THE NATIONAL MEASUREMENT LABORATORY provides the national system of physical and chemical and materials measurement; coordinates the system with measurement systems of other nations and furnishes essential services leading to accurate and uniform physical and chemical measurement throughout the Nation's scientific community, industry, and commerce; conducts materials research leading to improved methods of measurement, standards, and data on the properties of materials needed by industry, commerce, educational institutions, and Government; provides advisory and research services to other Government agencies; develops, produces, and distributes Standard Reference Materials; and provides -

Synchronizing Time with Dcf77 and Msf60
SYNCHRONIZING TIME WITH DCF77 AND MSF60 In many of the applications that use the H0420 and Starling programmable audio controllers/players, clock synchronization is a requirement. This is especially the case with the H0420, because it lacks a battery backup for its internal real-time clock —hence, when there is a power drop-out (even for less than a second), the H0420 resets to 1 January 1970 at 00:00 hours. Even with a backup battery for the real-time clock, when the device is used outdoor, you may observe the clock on the H0420 or Starling to deviate from the true time. The reason is that the crystals used for timekeeping are calibrated for use at room temperature. The time that the device resets to after power-up, of 1 January 1970 at 00:00 hours, is the "start of the Unix era". This is a commonly used basis for time keeping in operating systems and embedded devices; see the Wikipedia article in the references. For keeping the time of the H0420/Starling accurate, there are two options: get the time from the network (a typical option for the Starling, as it has a network port), or get the time from some other source, such as a radio signal. This latter option is suitable when no network is available at the location, which is common in outdoor use. This article specifically discusses how to pick up the current "time of the day" from DCF77 signal, but also discusses MSF60. A particular advantages of synchronizing on a time signal radio station is that "daylight saving time" is automatically handled. -

Service Manual
ZQ375 Checkweigher Service Manual AWT35-500813 Issue AB © Avery Weigh-Tronix, LLC 2012. All rights reserved. No part of this publication may be reproduced, stored in an electronic retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording or otherwise without the prior written consent of the copyright owner, or as permitted by law or under license. Full acknowledgment of the source must be given. Avery Weigh-Tronix is a registered trade mark of the Avery Weigh-Tronix, LLC. This publication was correct at the time of going to print however, Avery Weigh-Tronix, LLC reserves the right to alter without notice the specification, design, price or conditions of supply of any product or service at any time. All third party brands and product names used within this document are trademarks or registered trademarks of their respective holders. ZQ375_s_en_500813.book Table of Contents page Chapter 1 General information and warnings ......................................................................................... 9 About this manual ..............................................................................................................9 Text conventions ......................................................................................................... 9 Special messages ....................................................................................................... 9 Installation ....................................................................................................................... -

Time Signal Stations of the World
TIME SIGNAL STATIONS OF THE WORLD (SORTED BY FREQUENCY ORDER) Version 1.2 Last updated 10th of June 2020 Complied by Alan Gale, G4TMV NOTES: #1: The Country Identifiers used in this list are taken from the NDB List Country Code List which is available from the NDB List website at: https://ndblist.info/ndbinfo/countrylist.pdf #2 : This list is aimed only at radio enthusiasts, and it goes without saying that it should not be used for any other purposes. The data can’t yet be confirmed as being 100% accurate and up to date, so any updates or corrections would be greatly appreciated. #3 : This list is was put together from various sources mainly to have a starting place to look for these signals, though it is quite possible that many of them are now inactive or closed, so any reports of loggings would be very helpful in checking its accuracy. Details can be sent via the address shown below, and any updates or details of verifications received would be greatly appreciated. #4 : More information about Datamodes and the decoders that are available to receive them can be found at the following webpage: https://ndblist.info/datamodes.htm There is now a specialist group called the ‘DGPS List’ which also covers this mode, to find out more visit: https://groups.io/g/dgpslist/ Updates for this list can be sent to: <TSSupdates at ndblist.info> (replace the ‘at’ with @) © A. Gale/DGPS List 2020 1 TIME SIGNAL STATIONS OF THE WORLD – SORTED BY FREQUENCY ORDER: NOTE: #1 Many of the Stations listed below are marked as ‘active’ when this has been confirmed, but some of the others may or may not be on air at this time, so any confirmations of their current status would be greatly appreciated. -

RTZ 1.1 Guidelines Ver. 1.8
RTZ 1.1 Guidelines ver. 1.8 Guidelines for STM 1. General Comments The base RTZ format was contemplated as flexible and easily expandable. That is why the minimum requirements set for it are not burdensome: it is only necessary to provide a route with the route name (routeName in the routeInfo) and a set of (at least two) waypoints (in the waypoints container element). Each waypoint should necessarily be provided with at least geographic coordinates (position). The rest is optional in the RTZ. For STM validation we have extra requirements and following fields became mandatory: vesselVoyage in the routeInfo element routeStatusEnum in the routeInfoEx extension of the routeInfo element. It means that routeInfoEx extension element became mandatory for STM usage as well. The vessel voyage ID is the Unique Identity of a Voyage and should be used exactly specified in the STM MRN format in the RTZ vesselVoyage field, for example for the org name ‘acme’: vesselVoyage="urn:mrn:stm:voyage:id:acme:b6d7b492-ab3c-42f2-8afd-116c3d872f0c" Service providers shall not change UVID of each route received from a ship. IF it is brand new route that Service Provider is going to send to a ship, then UVID field must be filled in, because the UVID field CANNOT be empty. 2. Route Geometry Each route leg is formed as the shortest of all the possible segments within the framework of the set geometry (Great Circle or Rhumb Line) on the terrestrial ellipsoid. The following multiplicities may arise in the process: 1. The GC or RL geometry type, and the ends of the segment are on the opposite poles. -

MPC5645S/SC667108 Microcontroller Data Sheet
Freescale Semiconductor Document Number: PXD20 Data Sheet: Advance Information Rev. 2, 04/2012 PXD20 416 TEPBGA 208 LQFP 27 mm x 27 mm 28 mm x 28 mm PXD20 Microcontroller Data 176 LQFP Sheet 24 mm x 24 mm The PXD20 represents a new generation of 32-bit 1 Overview . 2 microcontrollers targeting single-chip industrial HMI 1.1 Device comparison. 2 applications. PXD20 devices are part of the PX family of 1.2 Block diagram. 4 ® 1.3 Feature list . 5 Power Architecture -based devices. This family has been 1.4 Feature details . 7 designed with an emphasis on providing cost-effective and 2 Pinout and signal descriptions . 24 high quality graphics capabilities. 2.1 176 LQFP package pinout . 24 2.2 208 LQFP package pinout . 25 PXD20 devices contain 2 MB internal flash memory. Serial 2.3 416 TEPBGA package pinout–40 to 105°C . 26 flash memory and DRAM interfaces are provided to allow 2.4 Signal description . 27 even greater system flexibility. 3 System design information. 60 3.1 Power-up sequencing . 60 The PXD20: 4 Electrical characteristics. 62 • Includes 2 MB internal flash memory, 1 MB internal 4.1 Introduction. 62 4.2 Parameter classification . 62 graphics SRAM, and 64 KB system SRAM 4.3 Absolute maximum ratings . 63 • Offers high processing performance operating at 4.4 Recommended operating conditions . 64 speeds up to 125 MHz 4.5 Thermal characteristics . 66 4.6 EMI (electromagnetic interference) characteristics . 70 • Is optimized for low power consumption 4.7 Power management . 70 The PXD20 is designed to reduce development and 4.8 DC electrical specifications . -

Of the Police Forces,Centralapecurity Breast by a Ribbon 35 Millimetres In
NOTIFICATIONS New Delhi, the 23rd February 1962 No.29-Pres./62 - The President is pleased to institute an award for the members of throughoutt ons of part cular Union to recognise service under cond toimake, and severe climate and in t is behalf, hardship the following statutes governing the ordainaward whichand establish shall be deemed to have effect from thelirsti of Januarys 1959.' - medal Firstly -The awarotshall be in the form of a MEDAL', ,POLICE (SPECIAL DUTY) and styled and designated the ' • (hereinafter referred to asthe medal). : Secondly - The medal shall- be circular.in shape, ' made of cupro-nic.ke1,38 millimetres in diameter, fitted to a 38 millimetres long horizontal bar with the inscription POLICE (SPECIAL DUTY)",.with.deCorative. standard fitting4' 'It, shall have embossed on the obverse the State Emblem encircled by a decorative lotus wreath. On the reverse, it shall have emossacAn,qutline of Gangotri in the centre . izir t.i4tia . , n.along the mpper and the words “VIti 4 '. a below the Outline.' . -- - rim and liGangotri . _ .. _ -aW;arded to ttl.se members Thirdly -she medal stall be erzahisations Who have .of the Police forces,CentralApecurity performed service in such conditions and for such geriods as may be recognsed from time to time by the Gove'rnment of India for the pur2oses Of this'award. -Awards may be Mnde posthumously. individual qualifying for the medal Fourthly An for the first time shall be a-derided the medal and on all suOse(luent occasions when qualifying shall be awarded only a bar to the medal. Fifthly - The medal shnll be suspended from the ..left - There ribonb shall by a ribbon 35 millimetres in width. -

STANDARD FREQUENCY and TIME SIGNAL STATIONS on LF and HF Originally Published Between October 1997 and July 1998
WUN ARCHIVE STANDARD FREQUENCY AND TIME SIGNAL STATIONS ON LF AND HF Originally published between October 1997 and July 1998 Standard frequency and time signal stations on LF and HF, pt.1 Welcome to the first part of a series about Time and Frequency Stations on LF and HF. This month you'll find a frequency list and a general introduction to these stations. During the next few months, we will highlight a bunch of the stations. Special thanks to Klaus Betke for his research, Stan Skalsky, Kevin Carey, Terry Krey, and Dave Mills. Also thanks to the Institute of Meteorology for Time and Space (Russia), BIPM Bureau International des Poids et Mesures (France) and NIST National Institute of Standards and Technology (USA) for their time, help and the huge amount of info. Introduction Exact time intervals are needed for navigation and surveying, in science and engineering. In the past, HF radio signals were often the only way to calibrate a clock onboard a ship or a frequency standard in a laboratory. In the age of GPS satellites and portable atomic clocks, however, time and frequency distribution via HF has become largely obsolete. New applications like network synchronization require an accuracy that cannot be met by HF signals. Moreover, the transmission scheme of most stations and the peculiarity of shortwave propagation make these signals less suitable for automatic, unattended reception. Consequently, many time signal stations have disappeared. In former times, coastal radio stations also transmitted time signals on their CW frequencies. Although numerous of these services to mariners are still listed in, you will hardly find an active one. -
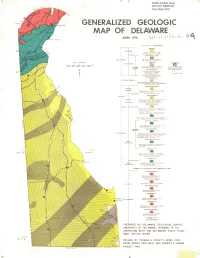
SP9 Generalized Geologic Map of Delaware
;- T Public Access Copy DO NOT REMOVE from Room208 GENERALIZED GEOLOGIC MAP OF NEW CASTLE DELAWARE APRil 1976 S ~ " I ., \ II) .. L1(( " l;v~ O S A LON G OflA.""A Rf 1'1 I\/'E 1'1 , BA YS A ND ATLANTIC OCEA I\l STAVT~LE \JfIlIT SC ALf OF' WILE S o MOTT LED GRAY "'",0 BROWfl\l --=- 10 su T AND CUV[ y SANO = OMARr.. ~ COLJiigAflll N 1Na R8EDO EDGRAY TO DA RI( GRAY QUA Rtz SAND AN D Si l TS YE llOw AND REDD'SH BEAVERDAM f ill BROW flo' aUA RTZ SA ND II"RESf Polf!~SO UTHfll"" SUSSE. WIT H SOM E GRAVEL COU l'rolTv ~, TEl ... ...",,0 1 t FAIA l Y WEL L SORTE D Il,lE= EL BAYN MAWR FM AGE Uf,jDETERMI NEO aeo AND BROW"" QUt:BARTZ SAND WI TH SitT. CL AY AN D F INE GRAVEL UN PIEDMONT! ~E"''''EG'au.- PllOfEr-fllE l ® ~ ' OCk-EN £ BLUI SH GRAY su r WIT H OUA.RT Z SA"'O ~ "''''0 SOI,lESHfllBfDS ~ ............. ........ TfRTlARY I vw.cENTaOWN FM OCE1NE J G REEN. G RAY "''''0 RE DD ISH BROWN FI NE TO COA RS E, HIGlil Y QUARTZOSE PAlEOCL-ENf GLAUCONITIC SAND WITH SO¥E SIL T l HO fl NERS TOWN f M fiB GflHN, GflAY AND REDDISh ! RO WN FINE TO MED ' UM. SILTY. HIGHLYGLAUCONIT'C SAND AfIo'o SANOY SILT IilIIOl.JfIl T LAUREL f M - MONMOUTH f ... GRAY. GREEN AND RfD BROWN . GLAUCON.TIC FINE TO MEO'UM. QUARTZ :'ANO WIT H SOME SILT MA RSHAllTOWtoI FM DM.