Nobs Calculus for Calculus 1, 2, and 3
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Notes on Calculus II Integral Calculus Miguel A. Lerma
Notes on Calculus II Integral Calculus Miguel A. Lerma November 22, 2002 Contents Introduction 5 Chapter 1. Integrals 6 1.1. Areas and Distances. The Definite Integral 6 1.2. The Evaluation Theorem 11 1.3. The Fundamental Theorem of Calculus 14 1.4. The Substitution Rule 16 1.5. Integration by Parts 21 1.6. Trigonometric Integrals and Trigonometric Substitutions 26 1.7. Partial Fractions 32 1.8. Integration using Tables and CAS 39 1.9. Numerical Integration 41 1.10. Improper Integrals 46 Chapter 2. Applications of Integration 50 2.1. More about Areas 50 2.2. Volumes 52 2.3. Arc Length, Parametric Curves 57 2.4. Average Value of a Function (Mean Value Theorem) 61 2.5. Applications to Physics and Engineering 63 2.6. Probability 69 Chapter 3. Differential Equations 74 3.1. Differential Equations and Separable Equations 74 3.2. Directional Fields and Euler’s Method 78 3.3. Exponential Growth and Decay 80 Chapter 4. Infinite Sequences and Series 83 4.1. Sequences 83 4.2. Series 88 4.3. The Integral and Comparison Tests 92 4.4. Other Convergence Tests 96 4.5. Power Series 98 4.6. Representation of Functions as Power Series 100 4.7. Taylor and MacLaurin Series 103 3 CONTENTS 4 4.8. Applications of Taylor Polynomials 109 Appendix A. Hyperbolic Functions 113 A.1. Hyperbolic Functions 113 Appendix B. Various Formulas 118 B.1. Summation Formulas 118 Appendix C. Table of Integrals 119 Introduction These notes are intended to be a summary of the main ideas in course MATH 214-2: Integral Calculus. -

Lesson 21 –Resultants
Lesson 21 –Resultants Elimination theory may be considered the origin of algebraic geometry; its history can be traced back to Newton (for special equations) and to Euler and Bezout. The classical method for computing varieties has been through the use of resultants, the focus of today’s discussion. The alternative of using Groebner bases is more recent, becoming fashionable with the onset of computers. Calculations with Groebner bases may reach their limitations quite quickly, however, so resultants remain useful in elimination theory. The proof of the Extension Theorem provided in the textbook (see pages 164-165) also makes good use of resultants. I. The Resultant Let be a UFD and let be the polynomials . The definition and motivation for the resultant of lies in the following very simple exercise. Exercise 1 Show that two polynomials and in have a nonconstant common divisor in if and only if there exist nonzero polynomials u, v such that where and . The equation can be turned into a numerical criterion for and to have a common factor. Actually, we use the equation instead, because the criterion turns out to be a little cleaner (as there are fewer negative signs). Observe that iff so has a solution iff has a solution . Exercise 2 (to be done outside of class) Given polynomials of positive degree, say , define where the l + m coefficients , ,…, , , ,…, are treated as unknowns. Substitute the formulas for f, g, u and v into the equation and compare coefficients of powers of x to produce the following system of linear equations with unknowns ci, di and coefficients ai, bj, in R. -

Line Integrals for Work, Circulation, and Plane Flux
Classroom Tips and Techniques: Line Integrals for Work, Circulation, and Plane Flux Robert J. Lopez Emeritus Professor of Mathematics and Maple Fellow © Maplesoft, a division of Waterloo Maple Inc., 2005 Introduction In our last column, we discussed how to address the iterated integral in Maple 9.5. This month, we will continue discussing integrals that arise in the subject area of vector calculus. In particular, we will discuss line integrals of the tangential and normal components of a vector field. The line integral of the tangential component of a force field produces the work done by the force on a particle of unit mass, as the mass moves along a specified curve. For the tangential component of the velocity field of a planar fluid flow, the line integral around a closed curve - typically a circle - is the circulation of the flow. The line integral of the normal component of a vector field is the flux of the field through the curve, and is a measure of the net "flow" of the field in the direction of the normal. If F = i + j represents the vector field in Cartesian coordinates, and is a planar curve parametrized by the equations then work (or circulation), the line integral of the tangential component of F along , is given by + or Flux, the line integral of the normal component of F along , is given by or (The mnemonic I always provided my students for the flux integral in the plane is that the form starts and ends with the same letters as the word "flux" and has a minus sign in the middle, thus determining where the letters and must go.) All of these physically meaningful quantities can be computed with the LineInt command in Maple's VectorCalculus package. -

Algorithmic Factorization of Polynomials Over Number Fields
Rose-Hulman Institute of Technology Rose-Hulman Scholar Mathematical Sciences Technical Reports (MSTR) Mathematics 5-18-2017 Algorithmic Factorization of Polynomials over Number Fields Christian Schulz Rose-Hulman Institute of Technology Follow this and additional works at: https://scholar.rose-hulman.edu/math_mstr Part of the Number Theory Commons, and the Theory and Algorithms Commons Recommended Citation Schulz, Christian, "Algorithmic Factorization of Polynomials over Number Fields" (2017). Mathematical Sciences Technical Reports (MSTR). 163. https://scholar.rose-hulman.edu/math_mstr/163 This Dissertation is brought to you for free and open access by the Mathematics at Rose-Hulman Scholar. It has been accepted for inclusion in Mathematical Sciences Technical Reports (MSTR) by an authorized administrator of Rose-Hulman Scholar. For more information, please contact [email protected]. Algorithmic Factorization of Polynomials over Number Fields Christian Schulz May 18, 2017 Abstract The problem of exact polynomial factorization, in other words expressing a poly- nomial as a product of irreducible polynomials over some field, has applications in algebraic number theory. Although some algorithms for factorization over algebraic number fields are known, few are taught such general algorithms, as their use is mainly as part of the code of various computer algebra systems. This thesis provides a summary of one such algorithm, which the author has also fully implemented at https://github.com/Whirligig231/number-field-factorization, along with an analysis of the runtime of this algorithm. Let k be the product of the degrees of the adjoined elements used to form the algebraic number field in question, let s be the sum of the squares of these degrees, and let d be the degree of the polynomial to be factored; then the runtime of this algorithm is found to be O(d4sk2 + 2dd3). -

Mathematics 1
Mathematics 1 MATH 1141 Calculus I for Chemistry, Engineering, and Physics MATHEMATICS Majors 4 Credits Prerequisite: Precalculus. This course covers analytic geometry, continuous functions, derivatives Courses of algebraic and trigonometric functions, product and chain rules, implicit functions, extrema and curve sketching, indefinite and definite integrals, MATH 1011 Precalculus 3 Credits applications of derivatives and integrals, exponential, logarithmic and Topics in this course include: algebra; linear, rational, exponential, inverse trig functions, hyperbolic trig functions, and their derivatives and logarithmic and trigonometric functions from a descriptive, algebraic, integrals. It is recommended that students not enroll in this course unless numerical and graphical point of view; limits and continuity. Primary they have a solid background in high school algebra and precalculus. emphasis is on techniques needed for calculus. This course does not Previously MA 0145. count toward the mathematics core requirement, and is meant to be MATH 1142 Calculus II for Chemistry, Engineering, and Physics taken only by students who are required to take MATH 1121, MATH 1141, Majors 4 Credits or MATH 1171 for their majors, but who do not have a strong enough Prerequisite: MATH 1141 or MATH 1171. mathematics background. Previously MA 0011. This course covers applications of the integral to area, arc length, MATH 1015 Mathematics: An Exploration 3 Credits and volumes of revolution; integration by substitution and by parts; This course introduces various ideas in mathematics at an elementary indeterminate forms and improper integrals: Infinite sequences and level. It is meant for the student who would like to fulfill a core infinite series, tests for convergence, power series, and Taylor series; mathematics requirement, but who does not need to take mathematics geometry in three-space. -

Problem Set 1
Mathematics 41C - 43C Mathematics Department Phillips Exeter Academy Exeter, NH August 2019 Table of Contents 41C Laboratory 0: Graphing . 6 Problem Set 1 . 9 Laboratory 1: Differences . 13 Problem Set 2 . .15 Laboratory 2: Functions and Rate of Change Graphs . 19 Problem Set 3 . .21 Laboratory 3: Approximating Instantaneous Rate of Change . 28 Problem Set 4 . .29 Laboratory 4: Linear Approximation . 34 Problem Set 5 . .36 Laboratory 5: Transformations and Derivatives . 41 Problem Set 6 . .43 Laboratory 6: Addition Rule and Product Rule for Derivatives . 47 Problem Set 7 . .49 Laboratory 7: Graphs and the Derivative . .53 Problem Set 8 . .54 Laboratory 8: The Most Exciting Moment on the Tilt-a-Whirl . 58 42C Laboratory 9: Graphs and the Second Derivative . 62 Problem Set 10 . .63 Laboratory 10: The Chain Rule for Derivatives . 66 Problem Set 11 . .69 Laboratory 11: Discovering Differential Equations . 74 Problem Set 12 . .76 Laboratory 12: Projectile Motion . .80 Problem Set 13 . .81 Laboratory 13: Introducing Slope Fields . .84 Problem Set 14 . .86 Laboratory 14: Introducing Euler's Method . 89 Problem Set 15 . .91 Laboratory 15: Skydiving . 95 Problem Set 16 . .97 43C Problem Set 17 . 102 Laboratory 17: The Gini Index . .107 Problem Set 18 . 111 Laboratory 18: Integration as Accumulation . .115 Problem Set 19 . 117 Laboratory 19: Geometric Probability . 120 Problem Set 20 . 121 August 2019 3 Phillips Exeter Academy Table of Contents Laboratory 20: The Normal Curve . 124 Problem Set 21 . 126 Laboratory 21: The Exponential Distribution . 129 Problem Set 22 . 131 Laboratory 22: Calculus and Data Analysis . 134 Problem Set 23 . 138 Laboratory 23: Predator/Prey Model . -

Arxiv:2004.03341V1
RESULTANTS OVER PRINCIPAL ARTINIAN RINGS CLAUS FIEKER, TOMMY HOFMANN, AND CARLO SIRCANA Abstract. The resultant of two univariate polynomials is an invariant of great impor- tance in commutative algebra and vastly used in computer algebra systems. Here we present an algorithm to compute it over Artinian principal rings with a modified version of the Euclidean algorithm. Using the same strategy, we show how the reduced resultant and a pair of B´ezout coefficient can be computed. Particular attention is devoted to the special case of Z/nZ, where we perform a detailed analysis of the asymptotic cost of the algorithm. Finally, we illustrate how the algorithms can be exploited to improve ideal arithmetic in number fields and polynomial arithmetic over p-adic fields. 1. Introduction The computation of the resultant of two univariate polynomials is an important task in computer algebra and it is used for various purposes in algebraic number theory and commutative algebra. It is well-known that, over an effective field F, the resultant of two polynomials of degree at most d can be computed in O(M(d) log d) ([vzGG03, Section 11.2]), where M(d) is the number of operations required for the multiplication of poly- nomials of degree at most d. Whenever the coefficient ring is not a field (or an integral domain), the method to compute the resultant is given directly by the definition, via the determinant of the Sylvester matrix of the polynomials; thus the problem of determining the resultant reduces to a problem of linear algebra, which has a worse complexity. -

Hk Hk38 21 56 + + + Y Xyx X 8 40
New York City College of Technology [MODULE 5: FACTORING. SOLVE QUADRATIC EQUATIONS BY FACTORING] MAT 1175 PLTL Workshops Name: ___________________________________ Points: ______ 1. The Greatest Common Factor The greatest common factor (GCF) for a polynomial is the largest monomial that divides each term of the polynomial. GCF contains the GCF of the numerical coefficients and each variable raised to the smallest exponent that appear. a. Factor 8x4 4x3 16x2 4x 24 b. Factor 9 ba 43 3 ba 32 6ab 2 2. Factoring by Grouping a. Factor 56 21k 8h 3hk b. Factor 5x2 40x xy 8y 3. Factoring Trinomials with Lead Coefficients of 1 Steps to factoring trinomials with lead coefficient of 1 1. Write the trinomial in descending powers. 2. List the factorizations of the third term of the trinomial. 3. Pick the factorization where the sum of the factors is the coefficient of the middle term. 4. Check by multiplying the binomials. a. Factor x2 8x 12 b. Factor y 2 9y 36 1 Prepared by Profs. Ghezzi, Han, and Liou-Mark Supported by BMI, NSF STEP #0622493, and Perkins New York City College of Technology [MODULE 5: FACTORING. SOLVE QUADRATIC EQUATIONS BY FACTORING] MAT 1175 PLTL Workshops c. Factor a2 7ab 8b2 d. Factor x2 9xy 18y 2 e. Factor x3214 x 45 x f. Factor 2xx2 24 90 4. Factoring Trinomials with Lead Coefficients other than 1 Method: Trial-and-error 1. Multiply the resultant binomials. 2. Check the sum of the inner and the outer terms is the original middle term bx . a. Factor 2h2 5h 12 b. -
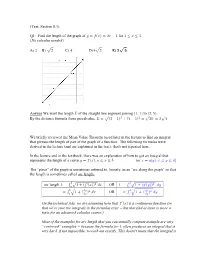
Lecture 19, March 1
(Text, Section 8.1) Q1: Find the length of the graph of for No calculus needed A) B) C) D) E) Answer We want the length of the straight line segment joining to By the distance formula from precalculus, We briefly reviewed the Mean Value Theorem (used later in the lecture to find an integral that givesus the length of part of the graph of a function. The following formulas were derived in the lecture (and are explained in the text): that's not repeated here. In the lecture and in the textbook, there was an explanation of how to get an integral that represents the length of a curve , (or The “piece” of the graph is sometimes referred to, loosely, as an “arc along the graph” so that the length is sometimes called arc length. arc length OR OR On the technical side, we are assuming here that is a continuous function (so that we're sure the integrals in the formulas exist but that find of issue is more a topic for an advanced calculus course.) Most of the examples for arc length that you can actually compute example are very “contrived” examples because the formula for often produces an integral that is very hard, if not impossible, to work out exactly. This doesn't mean that the integral is useless, however. Apart from certain theoretical uses, you can always write down the integral for any arc length and then use the Midpoint Rule, or some more sophisticated approximation rule, to approximate the value of the integral. For the Midpoint Rule, just pick as large an as you can tolerate working with, subdivide the interval into equal parts of length = , and plug into the formula for We can verify that these formulas do work in the simplest case (a straight line segment) which we did in Q1 without any calculus at all. -

Math 125: Calculus II - Dr
Math 125: Calculus II - Dr. Loveless Essential Course Info My Course Website: math.washington.edu/~aloveles/ Homework Log-In (use UWNetID): webassign.net/washington/login.html Directions for Webassign code purchase: math.washington.edu/webassign Math Department 125 Course Page: math.washington.edu/~m125/ First week to do list 1. Read 4.9, 5.1, 5.2, and 5.3 of the book. Start attempting HW. 2. Print off the “worksheets” and bring them to quiz sections. Today 1st HW assignments Syllabus/Intro Closing time is always 11pm. Section 4.9 - HW1A,1B,1C close Oct 4 - antiderivatives (Wed) (covers 4.9, 5.1, and 5.2) Expect 6-8 hrs of work, start today! What we will do in this course: 4. Ch. 8-9 – More Applications We learn the basic tools of integral - Arc Length, Center of Mass calculus which provide the essential - Differential Equations language for engineering, science and economics. Specifically, 5. Practicing Algebra, Trig and Precalc Students often say: The hardest part 1. Ch. 5 – Defining the Integral of calculus is you have to know all - Definition and basic techniques your precalculus, and they are right. 2. Ch. 6 – Basic Integral Applications Improving your algebra, trig and - Areas, Volumes precalculus skills will be one of the - Average Value best benefits you will gain from this - Measuring Work course (arguably as valuable as the course content itself). You will use 3. Ch. 7 – Integration Techniques these skills often in your other - by parts, trig, trig sub, partial courses at UW. frac Entry Task: Differentiate 7 1. 퐹(푥) = − 5√푥3 + 4ln (푥) 푥10 6푥 2. -

Effective Noether Irreducibility Forms and Applications*
Appears in Journal of Computer and System Sciences, 50/2 pp. 274{295 (1995). Effective Noether Irreducibility Forms and Applications* Erich Kaltofen Department of Computer Science, Rensselaer Polytechnic Institute Troy, New York 12180-3590; Inter-Net: [email protected] Abstract. Using recent absolute irreducibility testing algorithms, we derive new irreducibility forms. These are integer polynomials in variables which are the generic coefficients of a multivariate polynomial of a given degree. A (multivariate) polynomial over a specific field is said to be absolutely irreducible if it is irreducible over the algebraic closure of its coefficient field. A specific polynomial of a certain degree is absolutely irreducible, if and only if all the corresponding irreducibility forms vanish when evaluated at the coefficients of the specific polynomial. Our forms have much smaller degrees and coefficients than the forms derived originally by Emmy Noether. We can also apply our estimates to derive more effective versions of irreducibility theorems by Ostrowski and Deuring, and of the Hilbert irreducibility theorem. We also give an effective estimate on the diameter of the neighborhood of an absolutely irreducible polynomial with respect to the coefficient space in which absolute irreducibility is preserved. Furthermore, we can apply the effective estimates to derive several factorization results in parallel computational complexity theory: we show how to compute arbitrary high precision approximations of the complex factors of a multivariate integral polynomial, and how to count the number of absolutely irreducible factors of a multivariate polynomial with coefficients in a rational function field, both in the complexity class . The factorization results also extend to the case where the coefficient field is a function field. -

Notes Chapter 4(Integration) Definition of an Antiderivative
1 Notes Chapter 4(Integration) Definition of an Antiderivative: A function F is an antiderivative of f on an interval I if for all x in I. Representation of Antiderivatives: If F is an antiderivative of f on an interval I, then G is an antiderivative of f on the interval I if and only if G is of the form G(x) = F(x) + C, for all x in I where C is a constant. Sigma Notation: The sum of n terms a1,a2,a3,…,an is written as where I is the index of summation, ai is the ith term of the sum, and the upper and lower bounds of summation are n and 1. Summation Formulas: 1. 2. 3. 4. Limits of the Lower and Upper Sums: Let f be continuous and nonnegative on the interval [a,b]. The limits as n of both the lower and upper sums exist and are equal to each other. That is, where are the minimum and maximum values of f on the subinterval. Definition of the Area of a Region in the Plane: Let f be continuous and nonnegative on the interval [a,b]. The area if a region bounded by the graph of f, the x-axis and the vertical lines x=a and x=b is Area = where . Definition of a Riemann Sum: Let f be defined on the closed interval [a,b], and let be a partition of [a,b] given by a =x0<x1<x2<…<xn-1<xn=b where xi is the width of the ith subinterval.