Application Binary Interface Compatibility Through a Customizable Language
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

GNU MP the GNU Multiple Precision Arithmetic Library Edition 6.2.1 14 November 2020
GNU MP The GNU Multiple Precision Arithmetic Library Edition 6.2.1 14 November 2020 by Torbj¨ornGranlund and the GMP development team This manual describes how to install and use the GNU multiple precision arithmetic library, version 6.2.1. Copyright 1991, 1993-2016, 2018-2020 Free Software Foundation, Inc. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.3 or any later version published by the Free Software Foundation; with no Invariant Sections, with the Front-Cover Texts being \A GNU Manual", and with the Back-Cover Texts being \You have freedom to copy and modify this GNU Manual, like GNU software". A copy of the license is included in Appendix C [GNU Free Documentation License], page 132. i Table of Contents GNU MP Copying Conditions :::::::::::::::::::::::::::::::::::: 1 1 Introduction to GNU MP ::::::::::::::::::::::::::::::::::::: 2 1.1 How to use this Manual :::::::::::::::::::::::::::::::::::::::::::::::::::::::::::: 2 2 Installing GMP ::::::::::::::::::::::::::::::::::::::::::::::::: 3 2.1 Build Options:::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::: 3 2.2 ABI and ISA :::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::: 8 2.3 Notes for Package Builds:::::::::::::::::::::::::::::::::::::::::::::::::::::::::: 11 2.4 Notes for Particular Systems :::::::::::::::::::::::::::::::::::::::::::::::::::::: 12 2.5 Known Build Problems ::::::::::::::::::::::::::::::::::::::::::::::::::::::::::: 14 2.6 Performance -

Comparative Studies of 10 Programming Languages Within 10 Diverse Criteria
Department of Computer Science and Software Engineering Comparative Studies of 10 Programming Languages within 10 Diverse Criteria Jiang Li Sleiman Rabah Concordia University Concordia University Montreal, Quebec, Concordia Montreal, Quebec, Concordia [email protected] [email protected] Mingzhi Liu Yuanwei Lai Concordia University Concordia University Montreal, Quebec, Concordia Montreal, Quebec, Concordia [email protected] [email protected] COMP 6411 - A Comparative studies of programming languages 1/139 Sleiman Rabah, Jiang Li, Mingzhi Liu, Yuanwei Lai This page was intentionally left blank COMP 6411 - A Comparative studies of programming languages 2/139 Sleiman Rabah, Jiang Li, Mingzhi Liu, Yuanwei Lai Abstract There are many programming languages in the world today.Each language has their advantage and disavantage. In this paper, we will discuss ten programming languages: C++, C#, Java, Groovy, JavaScript, PHP, Schalar, Scheme, Haskell and AspectJ. We summarize and compare these ten languages on ten different criterion. For example, Default more secure programming practices, Web applications development, OO-based abstraction and etc. At the end, we will give our conclusion that which languages are suitable and which are not for using in some cases. We will also provide evidence and our analysis on why some language are better than other or have advantages over the other on some criterion. 1 Introduction Since there are hundreds of programming languages existing nowadays, it is impossible and inefficient -

Application Binary Interface Compatability Through A
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by The University of Utah: J. Willard Marriott Digital Library APPLICATION BINARY INTERFACE COMPATIBILITY THROUGH A CUSTOMIZABLE LANGUAGE by Kevin Jay Atkinson A dissertation submitted to the faculty of The University of Utah in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Computer Science School of Computing The University of Utah December 2011 Copyright c Kevin Jay Atkinson 2011 All Rights Reserved The University of Utah Graduate School STATEMENT OF DISSERTATION APPROVAL The dissertation of Kevin Jay Atkinson has been approved by the following supervisory committee members: Matthew Flatt , Chair 11/3/2011 Date Approved Gary Lindstrom , Member 11/17/2011 Date Approved Eric Eide , Member 11/3/2011 Date Approved Robert Kessler , Member 11/3/2011 Date Approved Olin Shivers , Member 11/29/2011 Date Approved and by Al Davis , Chair of the Department of School of Computing and by Charles A. Wight, Dean of The Graduate School. ABSTRACT ZL is a C++-compatible language in which high-level constructs, such as classes, are defined using macros over a C-like core language. This approach is similar in spirit to Scheme and makes many parts of the language easily customizable. For example, since the class construct can be defined using macros, a programmer can have complete control over the memory layout of objects. Using this capability, a programmer can mitigate certain problems in software evolution such as fragile ABIs (Application Binary Interfaces) due to software changes and incompatible ABIs due to compiler changes. -

GNU/Linux AI & Alife HOWTO
GNU/Linux AI & Alife HOWTO GNU/Linux AI & Alife HOWTO Table of Contents GNU/Linux AI & Alife HOWTO......................................................................................................................1 by John Eikenberry..................................................................................................................................1 1. Introduction..........................................................................................................................................1 2. Traditional Artificial Intelligence........................................................................................................1 3. Connectionism.....................................................................................................................................1 4. Evolutionary Computing......................................................................................................................1 5. Alife & Complex Systems...................................................................................................................1 6. Agents & Robotics...............................................................................................................................1 7. Programming languages.......................................................................................................................2 8. Missing & Dead...................................................................................................................................2 1. Introduction.........................................................................................................................................2 -

Kawa - Compiling Dynamic Languages to the Java VM
Kawa - Compiling Dynamic Languages to the Java VM Per Bothner Cygnus Solutions 1325 Chesapeake Terrace Sunnyvale CA 94089, USA <[email protected]> Abstract: in a project in conjunction with Java. A language im- plemented on top of Java gives programmers many of Many are interested in Java for its portable bytecodes the extra-linguistic benefits of Java, including libraries, and extensive libraries, but prefer a different language, portable bytecodes, web applets, and the existing efforts especially for scripting. People have implemented other to improve Java implementations and tools. languages using an interpreter (which is slow), or by translating into Java source (with poor responsiveness The Kawa toolkit supports compiling and running vari- for eval). Kawa uses an interpreter only for “simple” ous languages on the Java Virtual Machine. Currently, expressions; all non-trivial expressions (such as function Scheme is fully supported (except for a few difficult fea- definitions) are compiled into Java bytecodes, which are tures discussed later). An implementation of ECMA- emitted into an in-memory byte array. This can be saved Script is coming along, but at the time of writing it is for later, or quickly loaded using the Java ClassLoader. not usable. Kawa is intended to be a framework that supports mul- Scheme [R RS] is a simple yet powerful language. It tiple source languages. Currently, it only supports is a non-pure functional language (i.e. it has first-class Scheme, which is a lexically-scoped language in the Lisp functions, lexical scoping, non-lazy evaluation, and side family. The Kawa dialect of Scheme implements almost effects). -

HE ANDOVER TOWNSMAN Ing How in Get the M Ost out of Life
ANDOVER. MASS • he ndover ownsman A Andover everywhere nnd alwnyi, first, Inat—the mnnly. •»r«l*h*forward. sober, patriotic NewT England Town — PHILLIPS BROOKS ONE YEAR $2.00—SINGLE COPY 5 CENTS ANDOVER, MASSACHUSETTS, NOVEMBER 10, 1933 VOLUME XLVII NUMBER 5 Local Woman Killed Actress of Note at LOCAL NEWS NOTES School Board in Expert Pleads for Academy Tonight Mr. and Mrs. Charles T. Dole have been Regular Meeting on a trip to New York City. by Car on By-Pass Citizens of Andover are cordially invited Mr. and Mrs. (\ Carlcton Kimball have The school committee met Tuesday eve Educational Growth by Phillips academy to be present at a pro- been stopping in New York City. ning in its regular m onthly session to transact j gram of original dramatic sketches to be routine business. The matter of the new Miss Margaret Reid of Dufton road school rame up only incidentally, since the Mrs. Peter J. Dugan Fatally Injured When Returning j SA ,™ . ^ 3 . visited friends in New Jersey last week. committee is waiting until next W ednesday Dr. Payson Smith, Head of Massachusetts Department Home from North Andover Last Saturday Eve | ing Room of Cieorgc W ashington hall this Frederick Keuhner of the local post office when the final definite figures will be pre of Education, in Address Here Asks That Educa ning-Operator of Car Held evening, at 8.15. There will be no charge for has resumed his duties after a two weeks’ sented on the cost of the building. A letter tional System Be Not Crippled by Depression a d m is s io n . -

Effective Inhibitors of L{Emagglutination by Influenza Virus Synthesized Ftom Polymers Having Active Ester Groups
Reodnted from Journal of Mediciaal Chemistry' 1995'38' Cop''righr @1995 by rh" A;;;;; til;i.J3*i"ii-..a-np.i"t"a by iermidion of the cop5night owner. 4179 Effective Inhibitors of l{emagglutination by Influenza virus synthesized ftom Polymers Having Active Ester Groups. Insight into Mechanism of Inhibition Mathai Ma:nmen, Georg Dahnann, and George M. Whitesides* Departmentof Cfumistry,Harvard lJnioersity,12 Orford.Street, Cambridge, Mossothusetts 02138 ReceiuedJune 23, 19956 Highly effective sialic acid-containing inhibitors of influettzavirus X-31 were synthesized using p.f"vflf-t"cryoyloxy)succinimiael (pNfu), a polyper preactivatedby incorporation of active ester gt;;;r.' poiymers containing two and threL different componentswere prepared by sequential i"actioo of pNAS with twJ and three amines, respectively. This preparation of co- and terpolymers was synthetically more efficient than rnethods involvin_g_copolymerization of different monomersand gave polymers that were more easily comparedthal tlosgsgnerat-ed of pNAS) had a by copolymerization. Poiymeir i" this study (pre_pat"-atory a_sin-gleb-atct-r .onrturf degreeof polymerization (DP * 2000) indprobably h-ada distribution of comp_onents that was more random than analogous polymets prepared by copolym-erization. Use of g-jtycosides of sialic acid made it poisiblsto investigate inhibition by diffeplt polymers at without artifacts due to the actioll-of temperatures ranging from 4 to'gg "C oC_hydrolytic neuiaminidase. The inhibitors were, in general, more effective at 36 than at 4 "C. The hemagglutination (HAI) assaywas used to measure the value of the inhibition constant d{AI eachpolymer. The value of^(H for the two-componentpolymer containi,ng2|% sialic acid on p"fv.."ylamide backboneui 4 'C was 4 nM (in terms of the sialic acid moieties present in "solution) and was approximately 50-fold more effective than the best inhibitors previously described and 2b-fold^*or. -
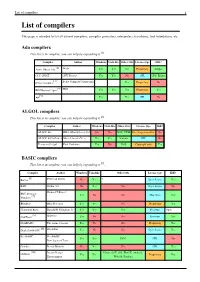
List of Compilers 1 List of Compilers
List of compilers 1 List of compilers This page is intended to list all current compilers, compiler generators, interpreters, translators, tool foundations, etc. Ada compilers This list is incomplete; you can help by expanding it [1]. Compiler Author Windows Unix-like Other OSs License type IDE? [2] Aonix Object Ada Atego Yes Yes Yes Proprietary Eclipse GCC GNAT GNU Project Yes Yes No GPL GPS, Eclipse [3] Irvine Compiler Irvine Compiler Corporation Yes Proprietary No [4] IBM Rational Apex IBM Yes Yes Yes Proprietary Yes [5] A# Yes Yes GPL No ALGOL compilers This list is incomplete; you can help by expanding it [1]. Compiler Author Windows Unix-like Other OSs License type IDE? ALGOL 60 RHA (Minisystems) Ltd No No DOS, CP/M Free for personal use No ALGOL 68G (Genie) Marcel van der Veer Yes Yes Various GPL No Persistent S-algol Paul Cockshott Yes No DOS Copyright only Yes BASIC compilers This list is incomplete; you can help by expanding it [1]. Compiler Author Windows Unix-like Other OSs License type IDE? [6] BaCon Peter van Eerten No Yes ? Open Source Yes BAIL Studio 403 No Yes No Open Source No BBC Basic for Richard T Russel [7] Yes No No Shareware Yes Windows BlitzMax Blitz Research Yes Yes No Proprietary Yes Chipmunk Basic Ronald H. Nicholson, Jr. Yes Yes Yes Freeware Open [8] CoolBasic Spywave Yes No No Freeware Yes DarkBASIC The Game Creators Yes No No Proprietary Yes [9] DoyleSoft BASIC DoyleSoft Yes No No Open Source Yes FreeBASIC FreeBASIC Yes Yes DOS GPL No Development Team Gambas Benoît Minisini No Yes No GPL Yes [10] Dream Design Linux, OSX, iOS, WinCE, Android, GLBasic Yes Yes Proprietary Yes Entertainment WebOS, Pandora List of compilers 2 [11] Just BASIC Shoptalk Systems Yes No No Freeware Yes [12] KBasic KBasic Software Yes Yes No Open source Yes Liberty BASIC Shoptalk Systems Yes No No Proprietary Yes [13] [14] Creative Maximite MMBasic Geoff Graham Yes No Maximite,PIC32 Commons EDIT [15] NBasic SylvaWare Yes No No Freeware No PowerBASIC PowerBASIC, Inc. -
Technical Report
Technical Report Proceedings of the 2020 Scheme and Functional Programming Workshop Edited by Baptiste Saleil and Michael D. Adams arXiv:2101.06759v1 [cs.PL] 17 Jan 2021 January 2021 Computer Science and Engineering technical reports published by University of Michigan are available at: https:// cse.engin.umich.edu/ research/ technical-reports-publications/ Preface This report aggregates the papers presented at the twenty-first annual Scheme and Func- tional Programming Workshop, hosted on August 28th, 2020, online and co-located with the twenty-fifth International Conference on Functional Programming. The Scheme and Func- tional Programming Workshop is held every year to provide an opportunity for researchers and practitioners using Scheme and related functional programming languages like Racket, Clojure, and Lisp, to share research findings and discuss the future of the Scheme program- ming language. Seven papers and three lightning talks were submitted to the workshop, and each submission was reviewed by three members of the program committee. After deliber- ation, four papers and three lightning talks were accepted to the workshop. In addition to the four papers and three lightning talks presented, • Martin Henz and Tobias Wrigstad gave an invited keynote speech entitled SICP JS: Ketchup on Caviar? • Bohdan Khomtchouk and Jonah Fleishhacker gave an invited keynote speech entitled 21st Century Lisp in Academic Research and Pedagogy. Thank you to all the presenters, panelists, participants, and members of the program com- mittee. Program -

CPAO Life Certificate
qTiil Yw-or< GOVERNMENT OFIND!A ft-a rr;araq. arq fuirrr M:NiSTRY OF F:NANCE DEPARTMENT OF EXPENDITURE ddlq {"rq iq orqlaq CCNTRAC PENS10N ACCOUNT:NG OFFiCE Bqa.tt rfl-o.r$ 6rrfl r+{r TR:K00■ H,BHIKA」 iCAMA PLACE, r{ ffi-rroooo NEW D〔 LHI‐ 110066 stl : 26174s9G, 261744s6,2617449a PHONES:26174596,26174450,26174438 CPAO/1F&Tcch/1ife Certincatc/2V()卜 V/201920/ノタ 13112019 ` OFFICE MEMORANDUM SubiCCt:‐ Submission of`Life Ccrtincate' It has bccn obscrvcd that Authorizcd 13anks arc not adhering to the cxtant rules regarding submission of hfe certincate issucd vidc OM No CPAO/Tech/Life Certincate/2014-15/31‐ 72 dated-3001 2015 and subscqucnt OM No CPAO/Tcch/1.ife certiicatc/2 Vol‐ V/2017‐ 18/178 datcd-08012018,OM No CPAO/′ IcCh/1・ ifC・ Ccrtincate/2 Vol― V/2017‐ 18/147 dated-23102018 and OM No CPAO/′ I` CCh/1′ ifC Ccrtincatc/2 Vol― V/2017-18/64 dated 26 07 2019(COpies Enclosed) 2. 'l'his office is receiving numbcr of gricvances from pensioners that Banks are insisting on submission of lifc ccrtificatc online and not acccpting thc life ccrtificate submitted in physical form. 3. It is rciteratcd that at prcscnt, thc following three options are available with pensioner/ family pensioner to authenticatc his/hcr li[r:: [. I]y prcscnting himself/hcrsclf to thc authorised bank officcr to rccord the life certificate. II. According to Para 15.2 of the "Schcme for Paymcnt of pension to Central Civil Pensioner" which states that "[n casc a pcnsioncr is unable to obtain a life certificate from an authorised Ilank officer on account of scrious illncss/ incapacitation etc., an intimation to this cffect supported by a medical ccrtificatc from a registcrcd medical practitioner about his inability to appcar in porson may bc scnt to officcr-in-charge of the paying branch so that the latter may nominatc an officcr to visit thc pcnsioner at his/her residence/hospital for the purpose of rccording the life ccrtificato". -

An Introduction to Scheme and Its Implementation - Table of Contents
An Introduction to Scheme and its Implementation - Table of Contents An Introduction to Scheme and its Implementation ● Overview ❍ Scheme: A Small But Powerful Language ❍ Who Is this Book For? ❍ Why Scheme? ❍ Why Scheme Now? ❍ What this Book Is Not ❍ Structure of this Book ● Introduction ❍ What is Scheme? (Hunk A) ❍ Basic Scheme Features ■ Code Consists of Expressions ■ Parenthesized Prefix Expressions ■ Expressions Return Values, But May Have Side-Effects ■ Defining Variables and Procedures ■ Most Operators are Procedures ■ Definitions vs. Assignments ■ Special Forms ■ Control Structures are Expressions ■ The Boolean Values #t and #f ■ Some Other Control-Flow Constructs: cond, and, and or ■ cond ■ and and or ■ not is just a procedure ■ Comments (Hunk C) ■ A Note about Parentheses and Indenting ■ Let Your Editor Help You ■ Indenting Procedure Calls and Simple Control Constructs ■ Indenting cond ■ Indenting Procedure Definitions ■ All Values are Pointers to Objects ■ All Values are Pointers ■ Most Implementations Optimize Away Many Pointers ■ Objects on the Heap http://www.federated.com/~jim/schintro-v14/schintro_toc.html (1 of 9)11/3/2006 8:45:57 PM An Introduction to Scheme and its Implementation - Table of Contents ■ Scheme Reclaims Memory Automatically ■ Objects Have Types, Variables Don't ■ Dynamic typing ■ The Empty List (Hunk E) ❍ Pairs and Lists ■ cdr-linked lists ■ Lists and Quoting ■ Where the Empty List Got its Name ■ Some Handy Procedures that Operate on Lists ■ length ■ list ■ append ■ reverse ■ member ❍ Recursion Over Lists -

Secure Content Distribution Using Untrusted Servers Kevin Fu
Secure content distribution using untrusted servers Kevin Fu MIT Computer Science and Artificial Intelligence Lab in collaboration with M. Frans Kaashoek (MIT), Mahesh Kallahalla (DoCoMo Labs), Seny Kamara (JHU), Yoshi Kohno (UCSD), David Mazières (NYU), Raj Rajagopalan (HP Labs), Ron Rivest (MIT), Ram Swaminathan (HP Labs) For Peter Szolovits slide #1 January-April 2005 How do we distribute content? For Peter Szolovits slide #2 January-April 2005 We pay services For Peter Szolovits slide #3 January-April 2005 We coerce friends For Peter Szolovits slide #4 January-April 2005 We coerce friends For Peter Szolovits slide #4 January-April 2005 We enlist volunteers For Peter Szolovits slide #5 January-April 2005 Fast content distribution, so what’s left? • Clients want ◦ Authenticated content ◦ Example: software updates, virus scanners • Publishers want ◦ Access control ◦ Example: online newspapers But what if • Servers are untrusted • Malicious parties control the network For Peter Szolovits slide #6 January-April 2005 Taxonomy of content Content Many-writer Single-writer General purpose file systems Many-reader Single-reader Content distribution Personal storage Public Private For Peter Szolovits slide #7 January-April 2005 Framework • Publishers write➜ content, manage keys • Clients read/verify➜ content, trust publisher • Untrusted servers replicate➜ content • File system protects➜ data and metadata For Peter Szolovits slide #8 January-April 2005 Contributions • Authenticated content distribution SFSRO➜ ◦ Self-certifying File System Read-Only