Content Adaptation for Context-Aware Service
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

PRESS RELEASE Nokia Reports Fourth Quarter 2005 Net Sales Of
PRESS RELEASE 1 (24) January 26, 2006 Nokia reports fourth quarter 2005 net sales of EUR 10.3 billion, EPS of EUR 0.25 Nokia reports 2005 net sales of EUR 34.2 billion, EPS of EUR 0.83 Device market share gains in Q4 and 2005 drive 16% annual sales growth and 20% EPS growth Nokia’s Board of Directors will propose a dividend of EUR 0.37 per share for 2005 (EUR 0.33 per share for 2004) NOKIA Q4 and 2005 EUR million Q4/2005 Q4/2004 Change 2005 2004 Change (*revised) (%) (*revised) (%) Net sales 10 333 9 456 9 34 191 29 371 16 Mobile Phones 6 217 5 871 6 20 811 18 521 12 Multimedia 2 024 1 272 59 5 981 3 676 63 Enterprise Solutions 153 295 -48 861 839 3 Networks 1 951 2 031 -4 6 557 6 431 2 Operating profit 1 368 1 450 -6 4 639 4 326 7 Mobile Phones 1 060 1 107 -4 3 598 3 786 -5 Multimedia 310 168 85 836 175 Enterprise Solutions -136 -44 -258 -210 Networks 268 306 -12 855 884 -3 Common Group Expenses -134 -87 -392 -309 Operating margin (%) 13.2 15.3 13.6 14.7 Mobile Phones (%) 17.1 18.9 17.3 20.4 Multimedia (%) 15.3 13.2 14.0 4.8 Enterprise Solutions (%) -88.9 -14.9 -30.0 -25.0 Networks (%) 13.7 15.1 13.0 13.7 Financial income and expenses 78 116 -33 322 405 -20 Profit before tax and minority interests 1 453 1 556 -7 4 971 4 705 6 Net profit 1 073 1 083 -1 3 616 3 192 13 EPS, EUR Basic 0.25 0.24 4 0.83 0.69 20 Diluted 0.25 0.24 4 0.83 0.69 20 All reported Q4 and 2005 figures can be found in the tables on pages (10-13) and (19-23) SPECIAL ITEMS Fourth quarter 2005 special items - EUR 29 million charge for Enterprise Solutions restructuring -

Digital Mobile Telephones and Interference of Ophthalmic Equipment
Eye (2007) 21, 29–32 & 2007 Nature Publishing Group All rights reserved 0950-222X/07 $30.00 www.nature.com/eye 1 1 1 1 2 Digital mobile GS Ang , P Lian ,WSNg, I Whyte and JM Ong CLINICAL STUDY telephones and interference of ophthalmic equipment Abstract Keywords: mobile telephone; cell phone; electromagnetic interference Aim To assess the effect of mobile telephone electromagnetic interference on electronic ophthalmic equipment. Methods Prospective audit with mobile Introduction telephones placed at distances of 3 m, 1 m, and 30 cm from, and in contact with, electronic Mobile telephone bans are widespread in ophthalmic equipment. Any interruption or hospitals in the United Kingdom. Apart from cessation of the function of the ophthalmic being a potential source of irritation, there is a device was assessed with the mobile widely perceived assumption that telephones in standby, and in dialling or electromagnetic interference (EMI) from mobile receiving modes. Any alterations of displayed telephones will affect the function of electronic digital figures or numbers were also assessed. equipment, particularly in the intensive care 1Department of Results A total of 23 electronic ophthalmic setting. However, a systematic review reveals Ophthalmology, Raigmore devices in two hospital ophthalmology very little evidence to suggest that this EMI Hospital, Inverness, UK outpatient departments were evaluated. All six affects most electronic equipment, and even for 2Department of mobile telephones used, and 22 (95.7%) of the the equipment that is affected, interference only Ophthalmology, Norfolk and 1 23 ophthalmic equipment evaluated had the occurs at a distance of less than 1 m. Norwich University Hospital, Conformite´ Europe´ene (CE) mark. -

Cell Phones and Pdas
eCycle Group - Check Prices Page 1 of 19 Track Your Shipment *** Introductory Print Cartridge Version Not Accepted February 4, 2010, 2:18 pm Print Check List *** We pay .10 cents for all cell phones NOT on the list *** To receive the most for your phones, they must include the battery and back cover. Model Price Apple Apple iPhone (16GB) $50.00 Apple iPhone (16GB) 3G $75.00 Apple iPhone (32GB) 3G $75.00 Apple iPhone (4GB) $20.00 Apple iPhone (8GB) $40.00 Apple iPhone (8GB) 3G $75.00 Audiovox Audiovox CDM-8930 $2.00 Audiovox PPC-6600KIT $1.00 Audiovox PPC-6601 $1.00 Audiovox PPC-6601KIT $1.00 Audiovox PPC-6700 $2.00 Audiovox PPC-XV6700 $5.00 Audiovox SMT-5500 $1.00 Audiovox SMT-5600 $1.00 Audiovox XV-6600WOC $2.00 Audiovox XV-6700 $3.00 Blackberry Blackberry 5790 $1.00 Blackberry 7100G $1.00 Blackberry 7100T $1.00 Blackberry 7105T $1.00 Blackberry 7130C $2.00 http://www.ecyclegroup.com/checkprices.php?content=cell 2/4/2010 eCycle Group - Check Prices Page 2 of 19 Search for Pricing Blackberry 7130G $2.50 Blackberry 7290 $3.00 Blackberry 8100 $19.00 Blackberry 8110 $18.00 Blackberry 8120 $19.00 Blackberry 8130 $2.50 Blackberry 8130C $6.00 Blackberry 8220 $22.00 Blackberry 8230 $15.00 Blackberry 8300 $23.00 Blackberry 8310 $23.00 Blackberry 8320 $28.00 Blackberry 8330 $5.00 Blackberry 8350 $20.00 Blackberry 8350i $45.00 Blackberry 8520 $35.00 Blackberry 8700C $6.50 Blackberry 8700G $8.50 Blackberry 8700R $7.50 Blackberry 8700V $6.00 Blackberry 8703 $1.00 Blackberry 8703E $1.50 Blackberry 8705G $1.00 Blackberry 8707G $5.00 Blackberry 8707V -
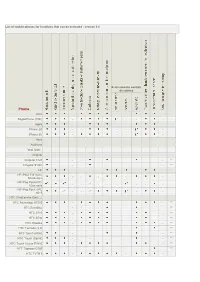
List of Mobile Phones for Functions That Can Be Activated - Version 5.4
List of mobile phones for functions that can be activated - version 5.4 Scaricamento contatti da rubrica Phone Amoi SkypePhone (TRE) - - - - Apple iPhone 2G - - - - - iPhone 3G - - - - Asus Audiovox Vedi Qtek... Cingular Cingular 8125 - - - ** Cingular SYNC - - - ** HP HP iPAQ 514 Voice - - - - - Messenger HP iPaq Pocket PC - - -* - - - - - - 63xx serie HP iPaq Pocket PC -* - - -* - - 6515 HTC (Vedi anche Qtek....) HTC Advantage X7500 - - ** HTC Excalibur - - - ** HTC S710 - - ** HTC S730 - - ** HTC Shadow - - ** HTC Tornado (2.0) ** HTC Touch (Alltel) - - - ** HTC Touch (Sprint) - - - - ** HTC Touch Cruise P3650 - - ** HTC Typhoon C500 ** HTC TyTN II - - - HTC Wizard ** Qteck/HTC P3300 - - - - - - - Qteck/HTC Touch Diamond - - - i-Mate Vedi Qtek LG LG CU500 - - ** LG KE850 - - - - - - - - LG KE850 Prada - - - ** LG KG800 (Chocolate) - - - - - - - - ** LG KS20 - - ** LG KU990 - - - ** LG KU800 - - - - - - - - - ** LG Shine (CU720) N N N ** LG Trax (CU575) N N N N N N ** LG U8550 - - - - -* LG U880 - - - - - - - - LG U900 - - - - - - - - Motorola Motorola A830/ - - - - A835 Motorola A1000 - - - - -* - Motorola A1200 Ming N ** Motorola E1000 - Motorola E398 - - - Motorola i615 N ** Motorola i880 N ** Motorola KRZR K1 - Motorola MPX220 - - - - - - Motorola RAZR2V9/ KRZR K3/ RAZR V3xx/ RAZR - MaxxV6 Motorola RAZR V3i/V3r ** Motorola RAZR V3t ** Motorola RAZR V6 Maxx ** Motorola RIZR Z3 - Motorola ROKR E6 N N ** Motorola Sidekick Slide N N N N ** Motorola SLVR L6 - Motorola SLVR L7 - Motorola U9 N N ** Motorola RAZR V3 - - Motorola V8 - - Motorola -

Nokia UG 6230
Uitgebreide gebruikershandleiding 9310209 Uitgave 4 CONFORMITEITSVERKLARING NOKIA CORPORATION verklaart op eigen verantwoordelijkheid dat het product RH-12 conform is aan de bepalingen van de volgende Richtlijn van de Raad: 1999/5/EG. Een kopie van de conformiteitsverklaring kunt u vinden op de volgende website: http://www.nokia.com/phones/declaration_of_conformity/. Copyright © 2004 Nokia. Alle rechten voorbehouden. Onrechtmatige reproductie, overdracht, distributie of opslag van dit document of een gedeelte ervan in enige vorm zonder voorafgaande geschreven toestemming van Nokia is verboden. Nokia, Nokia Connecting People en Xpress–on en Pop–Port zijn handelsmerken of gedeponeerde handelsmerken van Nokia Corporation. Namen van andere producten en bedrijven kunnen handelsmerken of handelsnamen van de respectievelijke eigenaren zijn. Nokia tune is een geluidsmerk van Nokia Corporation. US Patent No 5818437 and other pending patents. T9 text input software Copyright (C) 1997-2004. Tegic Communications, Inc. All rights reserved. Bluetooth is a registered trademark of Bluetooth SIG, Inc. Includes RSA BSAFE cryptographic or security protocol software from RSA Security. Java is a trademark of Sun Microsystems, Inc. GEBRUIK VAN DIT PRODUCT OP ENIGE WIJZE DAT OVEREENSTEMT MET DE VISUELE NORM MPEG–4 IS VERBODEN, BEHALVE VOOR GEBRUIK DAT RECHTSTREEKS BETREKKING HEEFT OP (A) GEGEVENS OF INFORMATIE (i) GEGENEREERD DOOR EN KOSTENLOOS VERKREGEN VAN EEN KLANT BUITEN HET KADER VAN ENIGE BEDRIJFSACTIVITEIT, EN (ii) UITSLUITEND BESTEMD VOOR PERSOONLIJK GEBRUIK; EN (B) ANDER GEBRUIK DAT SPECIFIEK EN AFZONDERLIJK ONDER LICENTIE IS TOEGESTAAN DOOR MPEG LA, L.L.C. USE OF THIS PRODUCT IN ANY MANNER THAT COMPLIES WITH THE MPEG-4 VISUAL STANDARD IS PROHIBITED, EXCEPT FOR USE DIRECTLY RELATED TO (A) DATA OR INFORMATION (i) GENERATED BY AND OBTAINED WITHOUT CHARGE FROM A CONSUMER NOT THEREBY ENGAGED IN A BUSINESS ENTERPRISE, AND (ii) FOR PERSONAL USE ONLY; AND (B) OTHER USES SPECIFICALLY AND SEPARATELY LICENSED BY MPEG LA, L.L.C. -
Sample Chapter
02Yuan.qrk 11/18/04 8:14 PM Page 22 2 Chapter 02Yuan.qrk 11/18/04 8:14 PM Page 23 Introducing Nokia Developer Platforms The Nokia Developer Platforms allow developers to write scalable applications across a range of Nokia devices. 23 02Yuan.qrk 11/18/04 8:14 PM Page 24 24 Chapter 2 Introducing Nokia Developer Platforms The mobile handset industry has seen fast-paced innovation in the last several years. Nokia alone has been announcing more than a dozen new devices every year. That is great news for consumers, since Nokia offers choices. But for mobile application developers, it is tough to make sure that applications work correctly on all handsets. The Nokia Developer Platforms aim to solve this problem by standardizing developer APIs among Nokia phones. Each Developer Platform supports a standard set of technologies on a series of Nokia devices. In 2004, more than 100 million Developer Platform devices will be sold worldwide. Key technologies supported on Nokia Developer Platforms are open industry standards. In particular, Java technology plays a crucial role. Client-side and server-side Java technologies can be used to develop applications for all Developer Platform devices. That helps 3 million existing Java developers to enter this exciting new market. In this chapter, we discuss the big pictures and architectures behind the Nokia Developer Platforms as well as the technical specifications of the most popular Series 40 and 60 Developer Platforms. From a Java developer’s perspective, we cover the four technology pillars on the Series 40 and 60 Developer Platforms: Wireless Markup Language (WML), and Extensible Hypertext Markup Language (XHTML) browsers, Multimedia Message Services (MMS), Java 2 Micro Edition (J2ME), and Symbian C++. -

Push to Talk)
Temen-temen, coba sekarang liat hape masing-masing. Dan cari aplikasi PTP (push to talk). Apakah itu..?? ko kayanya aplikasi terinstal tapi ga bisa digunakan ya?? nah dari tulisan ini semoga saja temen-temen bisa menggunakan aplikasi tersebut, biar ga gaptek dan mubazir (padahal gw jg termasuk salah satunya sih.hehehe..). silahkan dibaca dan cermati..selamat mencoba..!!! okey..sebelumnya, tulisan dibawah ini saya ambil dari sini. TEKNOLOGI PUSH TO TALK (TWO WAY RADIO) Handphone pada masa sekarang ini telah banyak memberikan tekonologi yang baru, satu diantaranya adalah teknologi Push To Talk. Namun di Indonesia, teknologi ini belum banyak diadaptasi. Bisa dibilang teknologi ini tidak dipakai. Push to talk adalah teknologi yang ada di dalam handphone beroperasi layaknya walkie- talkie dan berada di dalam jaringan seluler. Komunikasi yang terjalin 2 arah, terjadi pada waktu real-time, bersifat one-to-one atau one-to many komunikator. Komunikasinya bersifat half-duplex, layaknya walkie talkie, seorang pengguna tidak dapat berbicara dan mendengar (mengirim atau menerima informasi) percakapan, apabila lawan bicaranya sedang mengirim informasi atau berbicara. Hal ini berarti kedua belah pihak tidak dapat berbicara di waktu yang bersamaan (yang satu berbicara dan yang lainnya mendengarkan). Maka dari itu, push to talk juga disebut two-way-radio karena beroperasi seperti radio walkie-talkie. Fitur ini tidak seperti sistem full-duplex yang ada di dalam komunikasi seluler GSM, dimana kedua pembicara atau banyak pembicara dapat berbicara secara bersamaan. Sinyal suara percakapan pengguna dikirimkan sebagai packet data melalui jaringan GPRS (IP). Sehingga IP digunakan sebagai data carrier atau alat transport dari komunikasi ini. Karena sekarang ini sudah ada fitur 3G dan 3,5G, maka pengiriman data bisa dilakukan lebih cepat dan efisien. -

Guide to Setting up and Using Bluetooth®
The New ŠkodaSuperb Guide to setting up and using Bluetooth® For the first time in Škoda, Bluetooth® is available either as standard (Elegance) or as an option (S and SE). Below is an easy to follow guide to setting up Bluetooth® on your Superb. This will enable you to make and receive calls without touching the handset. Functions such as using your phone book are all accessible via the steering wheel and maxi dot (and stereo or satellite navigation unit) system. Step 1 - Turn on and activate Bluetooth® On your mobile phone, use the Bluetooth® settings menu to activate Bluetooth®. Step 2 - Pair your mobile phone with your New Superb New Superb needs to communicate (Pair) with your mobile phone. This can be done by using the controls on the steering wheel. • Click once on the arrow button on the right hand • Using the Scroll wheel on the steering wheel scroll down to ‘Phone’ and click. side of the steering wheel to access Main Menu. • Scroll to ‘Device search’ and click the scroll wheel. The Bluetooth® on Superb will now search for your mobile phone. • Once the system has found your mobile phone, • Follow the prompts on your phone and enter the • Your mobile phone will ask you if you wish to pair, it will prompt you to enter a 16 digit password. 16 digit password as it appears on the screen click ‘Accept’ *. If your phone needs a pin entering e.g. 5555666677778888. when you turn it on, you will need to enter this pin here (on the Superb maxi dot display). -

EDGE Sisus 2403
Make more profi ts now with the Nokia end-to-end EDGE solution Your 3G opportunity in GSM bands EDGE is vital to the long term prosperity of GSM/GPRS GSM, as an open standard, is by far Since the first days of these services, Bringing EDGE into your network allows you the world’s most successful mobile operators have seen many excellent results to give users the speed they need to make technology having today over 1 Billion – T-mobile reported early success with the most of the advanced services they subscribers. It continues to increase its 390,000 Java games downloads every want to use. Typically, adding EDGE brings global market share, with the recent month, while J-Phone quickly saw video three times the performance of GPRS, adoption of GSM in the Americas. mail users bring in 91% more ARPU than achieving an average data rate of 80 to 160 Furthermore, the expanding range non-video mail users. kbps per user with 2–4 timeslot mobiles. of new data services will further increase its market share. It is clear First experiences with commercial EDGE Consider this example: order one video clip that GSM/GPRS/EDGE networks will be networks have proven that EDGE can over MMS via GPRS and EDGE radio networks. around for decades to come. increase the use of mobile multimedia as With EDGE, the dial up time is shorter, WAP well as operator ARPU. According to CSL browsing for the video clip is faster and the Mobile data services are attracting more Hong Kong, after the first two months of actual MMS video clip is delivered more subscribers and many GSM/GPRS operators commercial EDGE use, MMS traffic increased quickly. -

Talkative User Manual
Talkative - Table of Contents Talkative - Table of Contents .................................................................... 1 1. Introduction to Talkative ...................................................................... 5 1.1 What is Talkative? ........................................................................ 5 1.2 Age appropriate content ................................................................ 6 2. Installing Talkative .............................................................................. 7 2.1 Installing Talkative from a CD ............................................................. 7 3 User Settings ...................................................................................... 8 3.1 Duplicate a user and opening user settings ............................................. 8 3.2 Input Method ................................................................................. 9 3.3 Visibility ...................................................................................... 9 3.4 Speech settings ............................................................................ 10 3.5 Workspace Settings ....................................................................... 11 3.5.1 Web browser ...................................................................... 11 3.5.2 Email ............................................................................... 11 3.5.3 Mobile phone ..................................................................... 11 4. Using Talkative ............................................................................... -
Nokia's Form 20-F 2003
NOKIA FORM 20–F 2003 As filed with the Securities and Exchange Commission on February 6, 2004. SECURITIES AND EXCHANGE COMMISSION Washington, D.C. 20549 FORM 20-F ANNUAL REPORT PURSUANT TO SECTION 13 OR 15(D) OF THE SECURITIES EXCHANGE ACT OF 1934 For the fiscal year ended December 31, 2003 Commission file number 1-13202 Nokia Corporation (Exact name of Registrant as specified in its charter) Republic of Finland (Jurisdiction of incorporation) Keilalahdentie 4, P.O. Box 226, FIN-00045 NOKIA GROUP, Espoo, Finland (Address of principal executive offices) Securities registered pursuant to Section 12(b) of the Act: Name of each exchange Title of each class on which registered American Depositary Shares New York Stock Exchange Shares, par value EUR 0.06 New York Stock Exchange(1) (1) Not for trading, but only in connection with the registration of American Depositary Shares representing these shares, pursuant to the requirements of the Securities and Exchange Commission. Securities registered pursuant to Section 12(g) of the Act: None Securities for which there is a reporting obligation pursuant to Section 15(d) of the Act: None Indicate the number of outstanding shares of each of the registrant’s classes of capital or common stock as of the close of the period covered by the annual report. Shares, par value EUR 0.06: 4 796 292 460 Indicate by check mark whether the registrant: (1) has filed all reports required to be filed by Section 13 or 15(d) of the Securities Exchange Act of 1934 during the preceding 12 months (or for such shorter period that the registrant was required to file such reports), and (2) has been subject to such filing requirements for the past 90 days. -
CK5050(P) Matrix
Bluetooth firmware Version 1.60 yes = Feature is supported and confirmed. n o = Feature is not supported by the Kenwood Bluetooth Module. n /a = Feature is not supported by the Phone. Phone connection Pick-up Reject Phonebook SIM contacts Call register Pick-up second Refuse second Switch call in Hang-up active Display Enable to use Enable to Enable to Dial Private Display Phonebook Enable to use Enable to Notify about Phone to KENWOOD and Hang- Redial incoming automatic automatic automatic call in three call in three three way call in three network AVRCP Target read SMS read SMS Phone number mode battery level transfer A2DP profile send SMS new SMS Bluetooth Model up a call call synchronisation synchronisation synchronisation way calling way calling calling way calling level profile from SIM card from phone Apple iPhone 1.1.4 (4A102) yes yes yes yes yes yes yes n/a yes yes yes yes yes yes yes n/a n/a n/a n/a n/a n/a n/a Apple iPhone 1.1.4 (4A102) Apple iPhone AT&T 1.0.2 (1C28) yes yes yes yes yes yes yes n/a yes yes yes yes yes yes yes n/a n/a n/a n/a n/a n/a n/a Apple iPhone AT&T 1.0.2 (1C28) AU W54S yes yes yes yes yes yes n/a n/a n/a no n/a no no yes yes yes no no n/a n/a n/a n/a AU W54S BenQ-Siemens CL71 1.16 yes yes yes yes no no n/a n/a n/a no n/a n/a n/a n/a n/a yes n/a n/a n/a n/a n/a n/a BenQ-Siemens CL71 1.16 BenQ-Siemens EF61 1 yes yes yes yes yes no no no no yes yes yes yes n/a n/a no n/a n/a n/a n/a n/a n/a BenQ-Siemens EF61 1 Blackberry 7105t V4.0.2.49 no yes yes yes yes yes no no n/a yes yes no no yes yes n/a n/a n/a n/a