Mastering Software Testing with Junit 5: Comprehensive Guide to Develop
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Information Needs for Software Development Analytics
Information Needs for Software Development Analytics Raymond P.L. Buse Thomas Zimmermann The University of Virginia, USA Microsoft Research [email protected] [email protected] Abstract—Software development is a data rich activity with decision making will likely only become more difficult. many sophisticated metrics. Yet engineers often lack the tools Analytics describes application of analysis, data, and sys- and techniques necessary to leverage these potentially powerful tematic reasoning to make decisions. Analytics is especially information resources toward decision making. In this paper, we present the data and analysis needs of professional software useful for helping users move from only answering questions engineers, which we identified among 110 developers and of information like “What happened?” to also answering managers in a survey. We asked about their decision making questions of insight like “How did it happen and why?” process, their needs for artifacts and indicators, and scenarios Instead of just considering data or metrics directly, one can in which they would use analytics. gather more complete insights by layering different kinds of The survey responses lead us to propose several guidelines for analytics tools in software development including: Engi- analyses that allow for summarizing, filtering, modeling, and neers do not necessarily have much expertise in data analysis; experimenting; typically with the help of automated tools. thus tools should be easy to use, fast, and produce concise The key to applying analytics to a new domain is under- output. Engineers have diverse analysis needs and consider most standing the link between available data and the information indicators to be important; thus tools should at the same time needed to make good decisions, as well as the analyses support many different types of artifacts and many indicators. -

Software Analytics for Incident Management of Online Services: An
Software Analytics for Incident Management of Online Services: An Experience Report Jian-Guang Lou, Qingwei Lin, Rui Ding, Tao Xie Qiang Fu, Dongmei Zhang University of Illinois at Urbana-Champaign Microsoft Research Asia, Beijing, P. R. China Urbana, IL, USA {jlou, qlin, juding, qifu, dongmeiz}@microsoft.com [email protected] Abstract—As online services become more and more popular, incident management needs to be efficient and effective in incident management has become a critical task that aims to order to ensure high availability and reliability of the services. minimize the service downtime and to ensure high quality of the A typical procedure of incident management in practice provided services. In practice, incident management is conducted (e.g., at Microsoft and other service-provider companies) goes through analyzing a huge amount of monitoring data collected at as follow. When the service monitoring system detects a ser- runtime of a service. Such data-driven incident management faces several significant challenges such as the large data scale, vice violation, the system automatically sends out an alert and complex problem space, and incomplete knowledge. To address makes a phone call to a set of On-Call Engineers (OCEs) to these challenges, we carried out two-year software-analytics trigger the investigation on the incident in order to restore the research where we designed a set of novel data-driven techniques service as soon as possible. Given an incident, OCEs need to and developed an industrial system called the Service Analysis understand what the problem is and how to resolve it. In ideal Studio (SAS) targeting real scenarios in a large-scale online cases, OCEs can identify the root cause of the incident and fix service of Microsoft. -
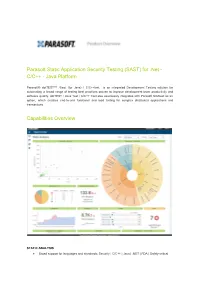
Parasoft Static Application Security Testing (SAST) for .Net - C/C++ - Java Platform
Parasoft Static Application Security Testing (SAST) for .Net - C/C++ - Java Platform Parasoft® dotTEST™ /Jtest (for Java) / C/C++test is an integrated Development Testing solution for automating a broad range of testing best practices proven to improve development team productivity and software quality. dotTEST / Java Test / C/C++ Test also seamlessly integrates with Parasoft SOAtest as an option, which enables end-to-end functional and load testing for complex distributed applications and transactions. Capabilities Overview STATIC ANALYSIS ● Broad support for languages and standards: Security | C/C++ | Java | .NET | FDA | Safety-critical ● Static analysis tool industry leader since 1994 ● Simple out-of-the-box integration into your SDLC ● Prevent and expose defects via multiple analysis techniques ● Find and fix issues rapidly, with minimal disruption ● Integrated with Parasoft's suite of development testing capabilities, including unit testing, code coverage analysis, and code review CODE COVERAGE ANALYSIS ● Track coverage during unit test execution and the data merge with coverage captured during functional and manual testing in Parasoft Development Testing Platform to measure true test coverage. ● Integrate with coverage data with static analysis violations, unit testing results, and other testing practices in Parasoft Development Testing Platform for a complete view of the risk associated with your application ● Achieve test traceability to understand the impact of change, focus testing activities based on risk, and meet compliance -

Email: [email protected] Website
Email: [email protected] Website: http://chrismatech.com Experienced software and systems engineer who has successfully deployed custom & industry-standard embedded, desktop and networked systems for commercial and DoD customers. Delivered systems operate on airborne, terrestrial, maritime, and space based vehicles and platforms. Expert in performing all phases of the software and system development life-cycle including: Creating requirements and design specifications. Model-driven software development, code implementation, and unit test. System integration. Requirements-based system verification with structural coverage at the system and module levels. Formal qualification/certification test. Final product packaging, delivery, and site installation. Post-delivery maintenance and customer support. Requirements management and end-to-end traceability. Configuration management. Review & control of change requests and defect reports. Quality assurance. Peer reviews/Fagan inspections, TIMs, PDRs and CDRs. Management and project planning proficiencies include: Supervising, coordinating, and mentoring engineering staff members. Creating project Software Development Plans (SDPs). Establishing system architectures, baseline designs, and technical direction. Creating & tracking project task and resource scheduling, costs, resource utilization, and metrics (e.g., Earned Value Analysis). Preparing proposals in response to RFPs and SOWs. Project Management • Microsoft Project, Excel, Word, PowerPoint, Visio & Documentation: • Adobe Acrobat Professional -

Survey of Verification and Validation Techniques for Small Satellite Software Development
Survey of Verification and Validation Techniques for Small Satellite Software Development Stephen A. Jacklin NASA Ames Research Center Presented at the 2015 Space Tech Expo Conference May 19-21, Long Beach, CA Summary The purpose of this paper is to provide an overview of the current trends and practices in small-satellite software verification and validation. This document is not intended to promote a specific software assurance method. Rather, it seeks to present an unbiased survey of software assurance methods used to verify and validate small satellite software and to make mention of the benefits and value of each approach. These methods include simulation and testing, verification and validation with model-based design, formal methods, and fault-tolerant software design with run-time monitoring. Although the literature reveals that simulation and testing has by far the longest legacy, model-based design methods are proving to be useful for software verification and validation. Some work in formal methods, though not widely used for any satellites, may offer new ways to improve small satellite software verification and validation. These methods need to be further advanced to deal with the state explosion problem and to make them more usable by small-satellite software engineers to be regularly applied to software verification. Last, it is explained how run-time monitoring, combined with fault-tolerant software design methods, provides an important means to detect and correct software errors that escape the verification process or those errors that are produced after launch through the effects of ionizing radiation. Introduction While the space industry has developed very good methods for verifying and validating software for large communication satellites over the last 50 years, such methods are also very expensive and require large development budgets. -

An Eclipse Plug-In for Testing and Debugging
GZoltar: An Eclipse Plug-In for Testing and Debugging José Campos André Riboira Alexandre Perez Rui Abreu Department of Informatics Engineering Faculty of Engineering, University of Porto Portugal {jose.carlos.campos, andre.riboira, alexandre.perez}@fe.up.pt; [email protected] ABSTRACT coverage). Several debugging tools exist which are based on Testing and debugging is the most expensive, error-prone stepping through the execution of the program (e.g., GDB phase in the software development life cycle. Automated and DDD). These traditional, manual fault localization ap- testing and diagnosis of software faults can drastically proaches have a number of important limitations. The place- improve the efficiency of this phase, this way improving ment of print statements as well as the inspection of their the overall quality of the software. In this paper we output are unstructured and ad-hoc, and are typically based present a toolset for automatic testing and fault localiza- on the developer's intuition. In addition, developers tend to use only test cases that reveal the failure, and therefore do tion, dubbed GZoltar, which hosts techniques for (regres- sion) test suite minimization and automatic fault diagno- not use valuable information from (the typically available) sis (namely, spectrum-based fault localization). The toolset passing test cases. provides the infrastructure to automatically instrument the Aimed at drastic cost reduction, much research has been source code of software programs to produce runtime data. performed in developing automatic testing and fault local- Subsequently the data was analyzed to both minimize the ization techniques and tools. As far as testing is concerned, test suite and return a ranked list of diagnosis candidates. -

Patterns for Implementing Software Analytics in Development Teams
Patterns for Implementing Software Analytics in Development Teams JOELMA CHOMA, National Institute for Space Research - INPE EDUARDO MARTINS GUERRA, National Institute for Space Research - INPE TIAGO SILVA DA SILVA, Federal University of São Paulo - UNIFESP The software development activities typically produce a large amount of data. Using a data-driven approach to decision making – such as Software Analytics – the software practitioners can achieve higher development process productivity and improve many aspects of the software quality based on the insightful and actionable information. This paper presents a set of patterns describing steps to encourage the integration of the analytics activities by development teams in order to support them to make better decisions, promoting the continuous improvement of software and its development process. Before any procedure to extract data for software analytics, the team needs to define, first of all, their questions about what will need to be measured, assess and monitored throughout the development process. Once defined the key issues which will be tracked, the team may select the most appropriate means for extracting data from software artifacts that will be useful in decision-making. The tasks to set up the development environment for software analytics should be added to the project planning along with the regular tasks. The software analytics activities should be distributed throughout the project in order to add information about the system in small portions. By defining reachable goals from the software analytics findings, the team turns insights from software analytics into actions to improve incrementally the software characteristics and/or its development process. Categories and Subject Descriptors: D.2.8 [Software and its engineering]: Software creation and management—Metrics General Terms: Software Analytics Additional Key Words and Phrases: Software Analytics, Decision Making, Agile Software Development, Patterns, Software Measurement, Development Teams. -

Eclipse Project Briefing Materials
[________________________] Eclipse project briefing materials. Copyright (c) 2002, 2003 IBM Corporation and others. All rights reserved. This content is made available to you by Eclipse.org under the terms and conditions of the Common Public License Version 1.0 ("CPL"), a copy of which is available at http://www.eclipse.org/legal/cpl-v10.html The most up-to-date briefing materials on the Eclipse project are found on the eclipse.org website at http://eclipse.org/eclipse/ 200303331 1 EclipseEclipse ProjectProject 200303331 3 Eclipse Project Aims ■ Provide open platform for application development tools – Run on a wide range of operating systems – GUI and non-GUI ■ Language-neutral – Permit unrestricted content types – HTML, Java, C, JSP, EJB, XML, GIF, … ■ Facilitate seamless tool integration – At UI and deeper – Add new tools to existing installed products ■ Attract community of tool developers – Including independent software vendors (ISVs) – Capitalize on popularity of Java for writing tools 200303331 4 Eclipse Overview Another Eclipse Platform Tool Java Workbench Help Development Tools JFace (JDT) SWT Team Your Tool Plug-in Workspace Development Debug Environment (PDE) Their Platform Runtime Tool Eclipse Project 200303331 5 Eclipse Origins ■ Eclipse created by OTI and IBM teams responsible for IDE products – IBM VisualAge/Smalltalk (Smalltalk IDE) – IBM VisualAge/Java (Java IDE) – IBM VisualAge/Micro Edition (Java IDE) ■ Initially staffed with 40 full-time developers ■ Geographically dispersed development teams – OTI Ottawa, OTI Minneapolis, -
A Brief History of Parasoft Jtest
A Brief History of Parasoft Jtest The static analysis technology for Jtest is invented The test generation technology for Jtest is invented The patent for Jtest’s test generation technology is First public release filed The patent for Jtest’s static analysis technology is filed Jtest patents awarded Jtest TM awarded Jtest introduces security rule set Jtest wins Best in Show at DevCon Jtest wins Software Magazine’s Productivity award Jtest nominated for JavaWorld Editors’ Choice awards Jtest becomes first product to use Design by Contract (Jcontract) comments to verify Java Automated JUnit test case generation is introduced classes/components at the system level Jtest wins Jolt Product Excellence Award Jtest wins Writer’s Choice Award from Java Report Jtest Tracer becomes the first tool to generate Jtest wins Software Business Magazines’s Best functional unit test cases as the user exercises the Development Tool Award working application Jtest wins Software and Information Industry Association’s Codie award for Best Software Testing Jtest wins JDJ Editors’ Choice Award Product or Service Jtest wins Software Development Magazines’s Jtest receives “Excellent” rating from Information World Productivity Award Jtest security edition released Flow-based static analysis is introduced Automated peer code review is introduced Cactus test generation is introduced Jtest is integrated into Development Testing Platform Jtest wins InfoWorld’s Technology of the Year award (DTP) Jtest wins Codie award for Best Software Testing DTP static analysis components -

Evaluating and Improving Software Quality Using Text Analysis Techniques - a Mapping Study
Evaluating and Improving Software Quality Using Text Analysis Techniques - A Mapping Study Faiz Shah, Dietmar Pfahl Institute of Computer Science, University of Tartu J. Liivi 2, Tartu 50490, Estonia {shah, dietmar.pfahl}@ut.ee Abstract: Improvement and evaluation of software quality is a recurring and crucial activ- ity in the software development life-cycle. During software development, soft- ware artifacts such as requirement documents, comments in source code, design documents, and change requests are created containing natural language text. For analyzing natural text, specialized text analysis techniques are available. However, a consolidated body of knowledge about research using text analysis techniques to improve and evaluate software quality still needs to be estab- lished. To contribute to the establishment of such a body of knowledge, we aimed at extracting relevant information from the scientific literature about data sources, research contributions, and the usage of text analysis techniques for the im- provement and evaluation of software quality. We conducted a mapping study by performing the following steps: define re- search questions, prepare search string and find relevant literature, apply screening process, classify, and extract data. Bug classification and bug severity assignment activities within defect manage- ment are frequently improved using the text analysis techniques of classifica- tion and concept extraction. Non-functional requirements elicitation activity of requirements engineering is mostly improved using the technique of concept extraction. The quality characteristic which is frequently evaluated for the prod- uct quality model is operability. The most commonly used data sources are: bug report, requirement documents, and software reviews. The dominant type of re- search contributions are solution proposals and validation research. -

Taming Functional Web Testing with Spock and Geb
Taming Functional Web Testing with Spock and Geb Peter Niederwieser, Gradleware Creator, Spock Contributor, Geb The Actors Spock, Geb, Page Objects Spock “Spock is a testing and specification framework for Java and Groovy applications. What makes it stand out from the crowd is its beautiful and highly expressive specification language. Thanks to its JUnit runner, Spock is compatible with most IDEs, build tools, and continuous integration servers. Spock is inspired from JUnit, RSpec, jMock, Mockito, Groovy, Scala, Vulcans, and other fascinating life forms. Spock (ctd.) http://spockframework.org ASL2 licence Serving mankind since 2008 Latest releases: 0.7, 1.0-SNAPSHOT Java + Groovy JUnit compatible Loves Geb Geb “Geb is a browser automation solution. It brings together the power of WebDriver, the elegance of jQuery content selection, the robustness of Page Object modelling and the expressiveness of the Groovy language. It can be used for scripting, scraping and general automation — or equally as a functional/web/acceptance testing solution via integration with testing frameworks such as Spock, JUnit & TestNG. Geb (ctd.) http://gebish.org ASL2 license Serving mankind since 2009 Latest releases: 0.7.2, 1.0-SNAPSHOT Java + Groovy Use with any test framework Loves Spock First-class page objects Page Objects “The Page Object pattern represents the screens of your web app as a series of objects. Within your web app's UI, there are areas that your tests interact with. A Page Object simply models these as objects within the test code. This reduces the amount of duplicated code and means that if the UI changes, the fix need only be applied in one place. -

Pragmatic Unit Testingin Java 8 with Junit
www.it-ebooks.info www.it-ebooks.info Early praise for Pragmatic Unit Testing in Java 8 with JUnit Langr, Hunt, and Thomas demonstrate, with abundant detailed examples, how unit testing with JUnit works in the real world. Beyond just showing simple iso- lated examples, they address the hard issues–things like mock objects, databases, multithreading, and getting started with automated unit testing. Buy this book and keep it on your desk, as you’ll want to refer to it often. ➤ Mike Cohn Author of Succeeding with Agile, Agile Estimating and Planning, and User Stories Applied Working from a realistic application, Jeff gives us the reasons behind unit testing, the basics of using JUnit, and how to organize your tests. This is a super upgrade to an already good book. If you have the original, you’ll find valuable new ideas in this one. And if you don’t have the original, what’s holding you back? ➤ Ron Jeffries www.ronjeffries.com Rational, balanced, and devoid of any of the typical religious wars surrounding unit testing. Top-drawer stuff from Jeff Langr. ➤ Sam Rose This book is an excellent resource for those new to the unit testing game. Experi- enced developers should also at the very least get familiar with the very helpful acronyms. ➤ Colin Yates Principal Architect, QFI Consulting, LLP www.it-ebooks.info We've left this page blank to make the page numbers the same in the electronic and paper books. We tried just leaving it out, but then people wrote us to ask about the missing pages.