Integrated File System
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The LAS File Format Contains a Header Block, Variable Length
LAS Specification Version 1.2 Approved by ASPRS Board 09/02/2008 LAS 1.2 1 LAS FORMAT VERSION 1.2: This document reflects the second revision of the LAS format specification since its initial version 1.0 release. Version 1.2 retains the same structure as version 1.1 including identical field alignment. LAS 1.1 file Input/Output (I/O) libraries will require slight modifications in order to be compliant with this revision. A LAS 1.1 Reader will read LAS 1.2 (without the new enhancements) with no modifications. A detailed change document that provides both an overview of the changes in the specification as well as the motivation behind each change is available from the ASPRS website in the LIDAR committee section. The additions of LAS 1.2 include: • GPS Absolute Time (as well as GPS Week Time) – LAS 1.0 and LAS 1.1 specified GPS “Week Time” only. This meant that GPS time stamps “rolled over” at midnight on Saturday. This makes processing of LIDAR flight lines that span the time reset difficult. LAS 1.2 allows both GPS Week Time and Absolute GPS Time (POSIX) stamps to be used. • Support for ancillary image data on a per point basis. You can now specify Red, Green, Blue image data on a point by point basis. This is encapsulated in two new point record types (type 2 and type 3). LAS FORMAT DEFINITION: The LAS file is intended to contain LIDAR point data records. The data will generally be put into this format from software (e.g. -

Configuring UNIX-Specific Settings: Creating Symbolic Links : Snap
Configuring UNIX-specific settings: Creating symbolic links Snap Creator Framework NetApp September 23, 2021 This PDF was generated from https://docs.netapp.com/us-en/snap-creator- framework/installation/task_creating_symbolic_links_for_domino_plug_in_on_linux_and_solaris_hosts.ht ml on September 23, 2021. Always check docs.netapp.com for the latest. Table of Contents Configuring UNIX-specific settings: Creating symbolic links . 1 Creating symbolic links for the Domino plug-in on Linux and Solaris hosts. 1 Creating symbolic links for the Domino plug-in on AIX hosts. 2 Configuring UNIX-specific settings: Creating symbolic links If you are going to install the Snap Creator Agent on a UNIX operating system (AIX, Linux, and Solaris), for the IBM Domino plug-in to work properly, three symbolic links (symlinks) must be created to link to Domino’s shared object files. Installation procedures vary slightly depending on the operating system. Refer to the appropriate procedure for your operating system. Domino does not support the HP-UX operating system. Creating symbolic links for the Domino plug-in on Linux and Solaris hosts You need to perform this procedure if you want to create symbolic links for the Domino plug-in on Linux and Solaris hosts. You should not copy and paste commands directly from this document; errors (such as incorrectly transferred characters caused by line breaks and hard returns) might result. Copy and paste the commands into a text editor, verify the commands, and then enter them in the CLI console. The paths provided in the following steps refer to the 32-bit systems; 64-bit systems must create simlinks to /usr/lib64 instead of /usr/lib. -

Copy — Copy file from Disk Or URL
Title stata.com copy — Copy file from disk or URL Syntax Description Options Remarks and examples Also see Syntax copy filename1 filename2 , options filename1 may be a filename or a URL. filename2 may be the name of a file or a directory. If filename2 is a directory name, filename1 will be copied to that directory. filename2 may not be a URL. Note: Double quotes may be used to enclose the filenames, and the quotes must be used if the filename contains embedded blanks. options Description public make filename2 readable by all text interpret filename1 as text file and translate to native text format replace may overwrite filename2 replace does not appear in the dialog box. Description copy copies filename1 to filename2. Options public specifies that filename2 be readable by everyone; otherwise, the file will be created according to the default permissions of your operating system. text specifies that filename1 be interpreted as a text file and be translated to the native form of text files on your computer. Computers differ on how end-of-line is recorded: Unix systems record one line-feed character, Windows computers record a carriage-return/line-feed combination, and Mac computers record just a carriage return. text specifies that filename1 be examined to determine how it has end-of-line recorded and that the line-end characters be switched to whatever is appropriate for your computer when the copy is made. There is no reason to specify text when copying a file already on your computer to a different location because the file would already be in your computer’s format. -

Key Aspects in 3D File Format Conversions
Key Aspects in 3D File Format Conversions Kenton McHenry and Peter Bajcsy Image Spatial Data Analysis Group, NCSA Presented by: Peter Bajcsy National Center for Supercomputing Applications University of Illinois at Urbana-Champaign Outline • Introduction • What do we know about 3D file formats? • Basic Archival Questions • Is there an optimal format to convert to? • Can we quantify 3D noise introduced during conversions? • NCSA Polyglot to Support Archival Processes • Automation of File Format Conversions • Quality of File Format Conversions • Scalability with Volume • Conclusions • Live demonstration Introduction Introduction to 3D File Format Reality *.k3d *.pdf (*.prc, *.u3d) *.ma, *.mb, *.mp *.w3d *.lwo *.c4d *.dwg *.blend *.iam *.max, *.3ds Introduction: Our Survey about 3D Content • Q: How Many 3D File Formats Exist? • A: We have found more than 140 3D file formats. Many are proprietary file formats. Many are extremely complex (1,200 and more pages of specifications). • Q: How Many Software Packages Support 3D File Format Import, Export and Display? • A: We have documented about 16 software packages. There are many more. Most of them are proprietary/closed source code. Many contain incomplete support of file specifications. Examples of Formats and Stored Content Format Geometry Appearance Scene Animation Faceted Parametric CSG B-Rep Color Material Texture Bump Lights Views Trans. Groups 3ds √ √ √ √ √ √ √ √ √ igs √ √ √ √ √ √ √ lwo √ √ √ √ √ √ obj √ √ √ √ √ √ √ ply √ √ √ √ √ stp √ √ √ √ √ √ wrl √ √ √ √ √ √ √ √ √ √ √ u3d √ √ √ √ √ -

AEDIT Text Editor Iii Notational Conventions This Manual Uses the Following Conventions: • Computer Input and Output Appear in This Font
Quick Contents Chapter 1. Introduction and Tutorial Chapter 2. The Editor Basics Chapter 3. Editing Commands Chapter 4. AEDIT Invocation Chapter 5. Macro Commands Chapter 6. AEDIT Variables Chapter 7. Calc Command Chapter 8. Advanced AEDIT Usage Chapter 9. Configuration Commands Appendix A. AEDIT Command Summary Appendix B. AEDIT Error Messages Appendix C. Summary of AEDIT Variables Appendix D. Configuring AEDIT for Other Terminals Appendix E. ASCII Codes Index AEDIT Text Editor iii Notational Conventions This manual uses the following conventions: • Computer input and output appear in this font. • Command names appear in this font. ✏ Note Notes indicate important information. iv Contents 1 Introduction and Tutorial AEDIT Tutorial ............................................................................................... 2 Activating the Editor ................................................................................ 2 Entering, Changing, and Deleting Text .................................................... 3 Copying Text............................................................................................ 5 Using the Other Command....................................................................... 5 Exiting the Editor ..................................................................................... 6 2 The Editor Basics Keyboard ......................................................................................................... 8 AEDIT Display Format .................................................................................. -

Attachment D to Adm. Memo No. 004 INSTRUCTIONS FOR
Attachment D to Adm. Memo No. 004 INSTRUCTIONS FOR FORMATTING A DISKETTE Formatting is the preparation of diskettes for storage of information. There are several different versions of the format command that can be used. The version that you use depends upon the type of diskette and the type of disk drive in which the diskette is being formatted. In order for us to be able to read the Tuition Grant diskettes you send, the diskettes should be properly formatted. Below is a table that identifies the more commonly used diskette types and disk drive specifications. The correct version of the format command will appear in the row for your diskette type and drive type. The format command uses the parameter “d:” to indicate the disk drive designation. For example, your 5 ¼ drive may be the “A:” drive. Instead of typing “FORMAT D:”, replace the drive designation with “A:” and type “FORMAT A:”. To verify that the disks were formatted correctly, perform the CHKDSK command on the newly formatted diskette. The format for the CHKDSK command is “CHKDSK d:”. When the command returns the disk information, compare it to the information in the fourth column of the table that corresponds to your diskette type and disk drive.. If the “total disk space” numbers are the same, the diskette is formatted correctly. DISK TYPE DRIVE TYPE FORMAT COMMAND SPACE INFO. 5 ¼” DSDD DSDD FORMAT d: 362,496 bytes total disk space 5 ¼” DSDD HD FORMAT d: /T:40 /N:9 362,496 bytes total disk space 5 ¼” HD DSDD Cannot be formatted 5 ¼” HD HD FORMAT d: 1,213,952 bytes total disk space 3 ½” DSDD DSDD FORMAT d: 730,112 bytes total disk space 3 ½” DSDD HD FORMAT d: /T:80 /N:9 730,112 bytes total disk space 3 ½” HD DSDD Cannot be formatted 3 ½” HD HD FORMAT d: 1,457,664 bytes total disk space 3 ½” DSHD FORMAT d: 1,457,664 bytes total disk space. -

COMMAND LINE CHEAT SHEET Presented by TOWER — the Most Powerful Git Client for Mac
COMMAND LINE CHEAT SHEET presented by TOWER — the most powerful Git client for Mac DIRECTORIES FILES SEARCH $ pwd $ rm <file> $ find <dir> -name "<file>" Display path of current working directory Delete <file> Find all files named <file> inside <dir> (use wildcards [*] to search for parts of $ cd <directory> $ rm -r <directory> filenames, e.g. "file.*") Change directory to <directory> Delete <directory> $ grep "<text>" <file> $ cd .. $ rm -f <file> Output all occurrences of <text> inside <file> (add -i for case-insensitivity) Navigate to parent directory Force-delete <file> (add -r to force- delete a directory) $ grep -rl "<text>" <dir> $ ls Search for all files containing <text> List directory contents $ mv <file-old> <file-new> inside <dir> Rename <file-old> to <file-new> $ ls -la List detailed directory contents, including $ mv <file> <directory> NETWORK hidden files Move <file> to <directory> (possibly overwriting an existing file) $ ping <host> $ mkdir <directory> Ping <host> and display status Create new directory named <directory> $ cp <file> <directory> Copy <file> to <directory> (possibly $ whois <domain> overwriting an existing file) OUTPUT Output whois information for <domain> $ cp -r <directory1> <directory2> $ curl -O <url/to/file> $ cat <file> Download (via HTTP[S] or FTP) Copy <directory1> and its contents to <file> Output the contents of <file> <directory2> (possibly overwriting files in an existing directory) $ ssh <username>@<host> $ less <file> Establish an SSH connection to <host> Output the contents of <file> using -

Types and Programming Languages by Benjamin C
< Free Open Study > . .Types and Programming Languages by Benjamin C. Pierce ISBN:0262162091 The MIT Press © 2002 (623 pages) This thorough type-systems reference examines theory, pragmatics, implementation, and more Table of Contents Types and Programming Languages Preface Chapter 1 - Introduction Chapter 2 - Mathematical Preliminaries Part I - Untyped Systems Chapter 3 - Untyped Arithmetic Expressions Chapter 4 - An ML Implementation of Arithmetic Expressions Chapter 5 - The Untyped Lambda-Calculus Chapter 6 - Nameless Representation of Terms Chapter 7 - An ML Implementation of the Lambda-Calculus Part II - Simple Types Chapter 8 - Typed Arithmetic Expressions Chapter 9 - Simply Typed Lambda-Calculus Chapter 10 - An ML Implementation of Simple Types Chapter 11 - Simple Extensions Chapter 12 - Normalization Chapter 13 - References Chapter 14 - Exceptions Part III - Subtyping Chapter 15 - Subtyping Chapter 16 - Metatheory of Subtyping Chapter 17 - An ML Implementation of Subtyping Chapter 18 - Case Study: Imperative Objects Chapter 19 - Case Study: Featherweight Java Part IV - Recursive Types Chapter 20 - Recursive Types Chapter 21 - Metatheory of Recursive Types Part V - Polymorphism Chapter 22 - Type Reconstruction Chapter 23 - Universal Types Chapter 24 - Existential Types Chapter 25 - An ML Implementation of System F Chapter 26 - Bounded Quantification Chapter 27 - Case Study: Imperative Objects, Redux Chapter 28 - Metatheory of Bounded Quantification Part VI - Higher-Order Systems Chapter 29 - Type Operators and Kinding Chapter 30 - Higher-Order Polymorphism Chapter 31 - Higher-Order Subtyping Chapter 32 - Case Study: Purely Functional Objects Part VII - Appendices Appendix A - Solutions to Selected Exercises Appendix B - Notational Conventions References Index List of Figures < Free Open Study > < Free Open Study > Back Cover A type system is a syntactic method for automatically checking the absence of certain erroneous behaviors by classifying program phrases according to the kinds of values they compute. -

Windows Command Prompt Cheatsheet
Windows Command Prompt Cheatsheet - Command line interface (as opposed to a GUI - graphical user interface) - Used to execute programs - Commands are small programs that do something useful - There are many commands already included with Windows, but we will use a few. - A filepath is where you are in the filesystem • C: is the C drive • C:\user\Documents is the Documents folder • C:\user\Documents\hello.c is a file in the Documents folder Command What it Does Usage dir Displays a list of a folder’s files dir (shows current folder) and subfolders dir myfolder cd Displays the name of the current cd filepath chdir directory or changes the current chdir filepath folder. cd .. (goes one directory up) md Creates a folder (directory) md folder-name mkdir mkdir folder-name rm Deletes a folder (directory) rm folder-name rmdir rmdir folder-name rm /s folder-name rmdir /s folder-name Note: if the folder isn’t empty, you must add the /s. copy Copies a file from one location to copy filepath-from filepath-to another move Moves file from one folder to move folder1\file.txt folder2\ another ren Changes the name of a file ren file1 file2 rename del Deletes one or more files del filename exit Exits batch script or current exit command control echo Used to display a message or to echo message turn off/on messages in batch scripts type Displays contents of a text file type myfile.txt fc Compares two files and displays fc file1 file2 the difference between them cls Clears the screen cls help Provides more details about help (lists all commands) DOS/Command Prompt help command commands Source: https://technet.microsoft.com/en-us/library/cc754340.aspx. -
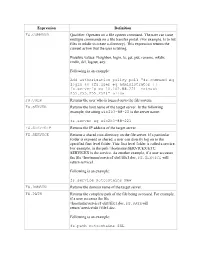
Expression Definition FS.COMMAND Qualifier. Operates on a File System Command
Expression Definition FS.COMMAND Qualifier. Operates on a file system command. The user can issue multiple commands on a file transfer portal. (For example, ls to list files or mkdir to create a directory). This expression returns the current action that the user is taking. Possible values: Neighbor, login, ls, get, put, rename, mkdir, rmdir, del, logout, any. Following is an example: Add authorization policy pol1 “fs.command eq login && (fs.user eq administrator || fs.serverip eq 10.102.88.221 –netmask 255.255.255.252)” allow FS.USER Returns the user who is logged on to the file system. FS.SERVER Returns the host name of the target server. In the following example, the string win2k3-88-22 is the server name: fs.server eq win2k3-88-221 FS.SERVERIP Returns the IP address of the target server. FS.SERVICE Returns a shared root directory on the file server. If a particular folder is exposed as shared, a user can directly log on to the specified first level folder. This first level folder is called a service. For example, in the path \\hostname\SERVICEX\ETC, SERVICEX is the service. As another example, if a user accesses the file \\hostname\service1\dir1\file1.doc, FS.SERVICE will return service1. Following is an example: fs.service notcontains New FS.DOMAIN Returns the domain name of the target server. FS.PATH Returns the complete path of the file being accessed. For example, if a user accesses the file \\hostname\service1\dir1\file1.doc, FS.PATHwill return \service\dir1\file1.doc. Following is an example: fs.path notcontains SSL Expression Definition FS.FILE Returns the name of the file being accessed. -

Enhancing the Accuracy of Synthetic File System Benchmarks Salam Farhat Nova Southeastern University, [email protected]
Nova Southeastern University NSUWorks CEC Theses and Dissertations College of Engineering and Computing 2017 Enhancing the Accuracy of Synthetic File System Benchmarks Salam Farhat Nova Southeastern University, [email protected] This document is a product of extensive research conducted at the Nova Southeastern University College of Engineering and Computing. For more information on research and degree programs at the NSU College of Engineering and Computing, please click here. Follow this and additional works at: https://nsuworks.nova.edu/gscis_etd Part of the Computer Sciences Commons Share Feedback About This Item NSUWorks Citation Salam Farhat. 2017. Enhancing the Accuracy of Synthetic File System Benchmarks. Doctoral dissertation. Nova Southeastern University. Retrieved from NSUWorks, College of Engineering and Computing. (1003) https://nsuworks.nova.edu/gscis_etd/1003. This Dissertation is brought to you by the College of Engineering and Computing at NSUWorks. It has been accepted for inclusion in CEC Theses and Dissertations by an authorized administrator of NSUWorks. For more information, please contact [email protected]. Enhancing the Accuracy of Synthetic File System Benchmarks by Salam Farhat A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor in Philosophy in Computer Science College of Engineering and Computing Nova Southeastern University 2017 We hereby certify that this dissertation, submitted by Salam Farhat, conforms to acceptable standards and is fully adequate in scope and quality to fulfill the dissertation requirements for the degree of Doctor of Philosophy. _____________________________________________ ________________ Gregory E. Simco, Ph.D. Date Chairperson of Dissertation Committee _____________________________________________ ________________ Sumitra Mukherjee, Ph.D. Date Dissertation Committee Member _____________________________________________ ________________ Francisco J. -

Dealing with Document Size Limits
Dealing with Document Size Limits Introduction The Electronic Case Filing system will not accept PDF documents larger than ten megabytes (MB). If the document size is less than 10 MB, it can be filed electronically just as it is. If it is larger than 10 MB, it will need to be divided into two or more documents, with each document being less than 10 MB. Word Processing Documents Documents created with a word processing program (such as WordPerfect or Microsoft Word) and correctly converted to PDF will generally be smaller than a scanned document. Because of variances in software, usage, and content, it is difficult to estimate the number of pages that would constitute 10 MB. (Note: See “Verifying File Size” below and for larger documents, see “Splitting PDF Documents into Multiple Documents” below.) Scanned Documents Although the judges’ Filing Preferences indicate a preference for conversion of documents rather than scanning, it will be necessary to scan some documents for filing, e.g., evidentiary attachments must be scanned. Here are some things to remember: • Documents scanned to PDF are generally much larger than those converted through a word processor. • While embedded fonts may be necessary for special situations, e.g., trademark, they will increase the file size. • If graphs or color photos are included, just a few pages can easily exceed the 10 MB limit. Here are some guidelines: • The court’s standard scanner resolution is 300 dots per inch (DPI). Avoid using higher resolutions as this will create much larger file sizes. • Normally, the output should be set to black and white.