Photo Tourism: Exploring Photo Collections in 3D
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

ACM Student Membership
student membership application and order form INSTRUCTIONS Name Please print clearly Member Number Carefully complete this application and Mailing Address return with payment by mail or fax to ACM. You must be a full-time student City/State/Province Postal Code/Zip to qualify for student rates. Country q Please do not release my postal address to third parties Area Code & Daytime Phone CONTACT ACM Email Address q Yes, please send me ACM Announcements via email q No, please do not send me ACM Announcements via email phone: 1-800-342-6626 (US & Canada) +1-212-626-0500 (Global) MEMBERSHIP OPTIONS AND ADD-ONS Check the appropriate box(es) hours: 8:30AM - 4:30PM (US EST) fax: +1-212-944-1318 q ACM Student Membership: $19 USD email: [email protected] q ACM Student Membership PLUS ACM Digital Library: $42 USD mail: ACM, Member Services q ACM Student Membership PLUS Print CACM Magazine: $42 USD General Post Offi ce q ACM Student Membership with ACM Digital Library PLUS Print CACM Magazine: $62 USD P.O. Box 30777 MEMBERSHIP ADD-ONS: New York, NY 10087-0777 q ACM Books Subscription: $10 USD USA q Additional Print Publications and/or Special Interest Groups For immediate processing, FAX this application to +1-212-944-1318. PUBLICATIONS Check the appropriate box and calculate amount due on reverse. PLEASE CHECK ONE WHAT’S NEW Issues per year Code Member Rate Air Rate * • ACM Inroads 4 178 $41 q $69 q ACM Learning Webinars keep you at the • Communications of the ACM 12 101 $50 q $69 q q q cutting edge of the latest technical and • Computing Reviews 12 104 $80 $46 • Computing Surveys 4 103 $61 q $39 q technological developments. -

ACM the Ultimate Online Resource for Computing Professionals
Association for Computing Machinery (ACM) The ACM is the world’s leading publisher of scientific and technical information and conference organizer in the field of Computing ©2016 Association for Computing Machinery ACM • The world’s leading professional member organization in Computing • Comprised of over 118,000 Academics, Practitioners, and Students from over 100 countries around the world • The world’s leading conference organizer in Computing with over 275 events annually, contributing over 500 volumes of content to the ACM DL each year • Active in Public Policy and Educational Curriculum Development • Organizers and Sponsors of pre-eminent computing professional awards & academic honors, such as the “Nobel Prize” in Computing….the A.M. Turing Award, funded by Google & Intel Corporations (http://www.vimeo.com) • Publishers of the computing world’s most respected publication program and most used publication platform dedicated to the field of Computing ©2016 Association for Computing Machinery ACM Publications Program • ACM has one of the oldest and most established publication programs in the field, consisting of a wide variety of publication types. • ACM’s publications are highly ranked by the Thomson Reuters Journal Citation Reports and are generally considered the premier publications by the leaders of the computer science community. • Some of the most highly respected titles are the Journal of the ACM, Communications of the ACM, ACM Computing Surveys, ACM Transactions on Graphics, and the SIGGRAPH Conference Proceedings. • Today, the program consists of 61 high impact peer reviewed journals and technology including a collection of hosted full-text publications from select publishers. • Access to 3,000+ ACM conference proceedings volumes, 500+ Volumes of the ACM International Conference Proceedings Series, 30,000+ articles from ACMs Special Interest Group technical newsletters, and over 6,500 (video and audio) multimedia files. -

Department of Computer Science and Engineering
Department of Computer Science and Engineering Journals SJR Title ISSN SJR Quartile Country Molecular Systems Biology ISSN 17444292 8.87 Q1 United Kingdom IEEE Transactions on Pattern Analysis and Machine Intelligence ISSN 01628828 7.653 Q1 United States MIS Quarterly: Management Information Systems ISSN 02767783 6.984 Q1 United States Wiley Interdisciplinary Reviews: Computational Molecular Science ISSN 17590884, 17590876 6.715 Q1 United States Foundations and Trends in Machine Learning ISSN 19358237 6.194 Q1 United States IEEE Transactions on Fuzzy Systems ISSN 10636706 5.8 Q1 United States International Journal of Computer Vision ISSN 09205691 5.633 Q1 Netherlands Journal of Supply Chain Management ISSN 15232409 5.343 Q1 United Kingdom Journal of Operations Management ISSN 02726963 5.052 Q1 Netherlands IEEE Transactions on Smart Grid ISSN 19493053 4.784 Q1 United States Bioinformatics ISSN 13674811, 13674803 4.643 Q1 United Kingdom Information Systems Research ISSN 15265536, 10477047 4.397 Q1 United States IEEE Transactions on Evolutionary Computation ISSN 1089778X 4.308 Q1 United States IEEE Transactions on Automatic Control ISSN 00189286 4.238 Q1 United States International Journal of Robotics Research ISSN 02783649 4.184 Q1 United States Briefings in Bioinformatics ISSN 14774054, 14675463 4.086 Q1 United Kingdom SIAM Journal on Optimization ISSN 10526234, 10957189 3.943 Q1 United States IEEE Transactions on Systems, Man and Cybernetics Part B: Cybernetics ISSN 10834419 3.921 Q1 United States Internet and Higher Education ISSN 10967516 -

Membership Application and Order Form
membership application and order form INSTRUCTIONS Name Please print clearly Member Number Carefully complete this application and Mailing Address return with payment by mail or fax to ACM. You must be an ACM member to City/State/Province Postal Code/Zip add the Digtal Library or ACM Books. Country q Please do not release my postal address to third parties Area Code & Daytime Phone CONTACT ACM Email Address q Yes, please send me ACM Announcements via email q No, please do not send me ACM Announcements via email phone: 1-800-342-6626 (US & Canada) +1-212-626-0500 (Global) MEMBERSHIP TYPES AND ADD-ONS Check the appropriate box(es) hours: 8:30AM - 4:30PM (US EST) q ACM Professional Membership: $99 USD fax: +1-212-944-1318 q ACM Professional Membership plus ACM Digital Library: $198 USD email: [email protected] MEMBERSHIP ADD-ONS: mail: ACM, Member Services q ACM Digital Library: $99 USD General Post Offi ce P.O. Box 30777 q ACM Books Subscription: $29 USD New York, NY 10087-0777 q Additional print publications and/or Special Interest Groups USA PUBLICATIONS Check the appropriate box and calculate amount due on reverse. PLEASE CHECK ONE For immediate processing, FAX this application to +1-212-944-1318. Issues per year Code Member Rate Air Rate * • ACM Inroads 4 178 $64 q $69 q WHAT’S NEW • Communications of the ACM 12 101 $75 q $69 q • Computing Reviews 12 104 $89 q $46 q ACM Learning Webinars keep you at the • Computing Surveys 4 103 $66 q $39 q cutting edge of the latest technical and • interactions (included in SIGCHI membership) 6 123 $84 q $42 q • Int’l Journal on Very Large Databases 6 148 $113 q $37 q technological developments. -

Top Peer Reviewed Journals – Computer Science
Top Peer Reviewed Journals – Computer Science Presented to Iowa State University Presented by Thomson Reuters Computer Science The subject discipline for Computer Science is made of 9 narrow subject categories from the Web of Science. The 9 categories that make up Computer Science are: 1. Computer Science, Artificial Intelligence 2. Computer Science, Cybernetics 3. Computer Science, Hardware & Architecture 4. Computer Science, Information Systems 5. Computer Science, Interdisciplinary Applications 6. Computer Science, Software Engineering 7. Computer Science, Theory & Methods 8. Imaging Science & Photographic Technology 9. Telecommunications The chart below provides an ordered view of the top peer reviewed journals within the 1st quartile for Computer Science based on Impact Factors (IF), three year averages and their quartile ranking. Journal 2009 IF 2010 IF 2011 IF Average IF BRIEFINGS IN BIOINFORMATICS 7.32 9.28 5.2 7.27 ACM COMPUTING SURVEYS 7.66 8 4.52 6.73 BIOINFORMATICS 4.92 4.87 5.46 5.08 IEEE Communications Surveys and Tutorials 3.69 6.31 5.00 SIAM Journal on Imaging Sciences 4.5 4.65 4.58 MEDICAL IMAGE ANALYSIS 3.09 4.36 4.42 3.96 HUMAN-COMPUTER INTERACTION 6.19 4 1.47 3.89 IBM JOURNAL OF RESEARCH AND 2.51 5.21 3.86 DEVELOPMENT IEEE JOURNAL ON SELECTED AREAS IN 3.75 4.23 3.41 3.80 COMMUNICATIONS ACM TRANSACTIONS ON GRAPHICS 3.61 3.63 3.48 3.57 Journal of Informetrics 3.37 3.11 4.22 3.57 Enterprise Information Systems 2.8 3.68 3.24 INTERNATIONAL JOURNAL OF INFORMATION TECHNOLOGY & 3.13 3.13 DECISION MAKING Journal of Web Semantics -
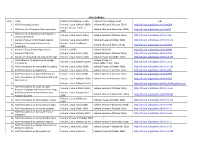
ACM JOURNALS S.No. TITLE PUBLICATION RANGE :STARTS PUBLICATION RANGE: LATEST URL 1. ACM Computing Surveys Volume 1 Issue 1
ACM JOURNALS S.No. TITLE PUBLICATION RANGE :STARTS PUBLICATION RANGE: LATEST URL 1. ACM Computing Surveys Volume 1 Issue 1 (March 1969) Volume 49 Issue 3 (October 2016) http://dl.acm.org/citation.cfm?id=J204 Volume 24 Issue 1 (Feb. 1, 2. ACM Journal of Computer Documentation Volume 26 Issue 4 (November 2002) http://dl.acm.org/citation.cfm?id=J24 2000) ACM Journal on Emerging Technologies in 3. Volume 1 Issue 1 (April 2005) Volume 13 Issue 2 (October 2016) http://dl.acm.org/citation.cfm?id=J967 Computing Systems 4. Journal of Data and Information Quality Volume 1 Issue 1 (June 2009) Volume 8 Issue 1 (October 2016) http://dl.acm.org/citation.cfm?id=J1191 Journal on Educational Resources in Volume 1 Issue 1es (March 5. Volume 16 Issue 2 (March 2016) http://dl.acm.org/citation.cfm?id=J814 Computing 2001) 6. Journal of Experimental Algorithmics Volume 1 (1996) Volume 21 (2016) http://dl.acm.org/citation.cfm?id=J430 7. Journal of the ACM Volume 1 Issue 1 (Jan. 1954) Volume 63 Issue 4 (October 2016) http://dl.acm.org/citation.cfm?id=J401 8. Journal on Computing and Cultural Heritage Volume 1 Issue 1 (June 2008) Volume 9 Issue 3 (October 2016) http://dl.acm.org/citation.cfm?id=J1157 ACM Letters on Programming Languages Volume 2 Issue 1-4 9. Volume 1 Issue 1 (March 1992) http://dl.acm.org/citation.cfm?id=J513 and Systems (March–Dec. 1993) 10. ACM Transactions on Accessible Computing Volume 1 Issue 1 (May 2008) Volume 9 Issue 1 (October 2016) http://dl.acm.org/citation.cfm?id=J1156 11. -

1 Acmsmall Author Submission Guide: Setting up Your Latex2ε Files
1 acmsmall Author Submission Guide: Setting Up Your LATEX2ε Files DONALD E. KNUTH, Stanford University LESLIE LAMPORT, Microsoft Corporation A The LTEX 2ε acmsmall document class formats articles in the style of the ACM small size journals and A transactions. Users who have prepared their document with LTEX 2ε can, with very little effort, produce camera-ready copy for these journals. Categories and Subject Descriptors: D.2.7 [Software Engineering]: Distribution and Maintenance—doc- umentation; H.4.0 [Information Systems Applications]: General; I.7.2 [Text Processing]: Document Preparation—languages; photocomposition General Terms: Documentation, Languages Additional Key Words and Phrases: Document preparation, publications, typesetting ACM Reference Format: Donald E. Knuth and Leslie Lamport. 2010. acmsmall Author submission guide: setting up your LATEX 2ε files. ACM Comput. Surv. 2, 3, Article 1 (July 2010), 14 pages. DOI:http://dx.doi.org/10.1145/0000000.0000000 1. INTRODUCTION This article is a description of the LATEX 2ε acmsmall document class for typesetting articles in the format of the ACM small size transactions and journals—Transactions on Programming Languages and Systems, Journal of the ACM, etc. It has, of course, been typeset using this document class, so it is a self-illustrating article. The reader is assumed to be familiar with LATEX, as described by Lamport [1986]. This document also describes the acmsmall bibliography style. LATEX 2ε is a document preparation system implemented as a macro package in Don- ald Knuth’s TEX typesetting system [Knuth 1984]. It is based upon the premise that the user should describe the logical structure of his document and not how the docu- ment is to be formatted. -

Using History to Teach Computer Science and Related Disciplines
Computing Research Association Using History T o T eachComputer Science and Related Disciplines Using History To Teach Computer Science and Related Disciplines Edited by Atsushi Akera 1100 17th Street, NW, Suite 507 Rensselaer Polytechnic Institute Washington, DC 20036-4632 E-mail: [email protected] William Aspray Tel: 202-234-2111 Indiana University—Bloomington Fax: 202-667-1066 URL: http://www.cra.org The workshops and this report were made possible by the generous support of the Computer and Information Science and Engineering Directorate of the National Science Foundation (Award DUE- 0111938, Principal Investigator William Aspray). Requests for copies can be made by e-mailing [email protected]. Copyright 2004 by the Computing Research Association. Permission is granted to reproduce the con- tents, provided that such reproduction is not for profit and credit is given to the source. Table of Contents I. Introduction ………………………………………………………………………………. 1 1. Using History to Teach Computer Science and Related Disciplines ............................ 1 William Aspray and Atsushi Akera 2. The History of Computing: An Introduction for the Computer Scientist ……………….. 5 Thomas Haigh II. Curricular Issues and Strategies …………………………………………………… 27 3. The Challenge of Introducing History into a Computer Science Curriculum ………... 27 Paul E. Ceruzzi 4. History in the Computer Science Curriculum …………………………………………… 33 J.A.N. Lee 5. Using History in a Social Informatics Curriculum ....................................................... 39 William Aspray 6. Introducing Humanistic Content to Information Technology Students ……………….. 61 Atsushi Akera and Kim Fortun 7. The Synergy between Mathematical History and Education …………………………. 85 Thomas Drucker 8. Computing for the Humanities and Social Sciences …………………………………... 89 Nathan L. Ensmenger III. Specific Courses and Syllabi ………………………………………....................... 95 Course Descriptions & Syllabi 9. -

Ac 2007-687: Ranking Scholarly Outlets for Information Technology
AC 2007-687: RANKING SCHOLARLY OUTLETS FOR INFORMATION TECHNOLOGY Barry Lunt, Brigham Young University Dr. Barry M. Lunt is a professor of Information Technology at Brigham Young University, Utah, where he has taught for over 14 years. He has also taught at Utah State University (Logan, UT) and Snow College (Ephraim, UT). Before entering academia, he was a design engineer for IBM in Tucson, AZ. His research interests presently include engineering and technology education and long-term digital data storage. Michael Bailey, Brigham Young University Joseph Ekstrom, Brigham Young University C. Richard G. Helps, Brigham Young University David Wood, Indiana University David is a Ph.D. student in accounting. He has published papers in accounting, one on the topic of the ranking of scholarly outlets for accounting. He holds a BS and an MS in Accounting from Brigham Young University, Provo, UT. Page 12.1216.1 Page © American Society for Engineering Education, 2007 Ranking Scholarly Outlets for Information Technology Abstract Many well-established disciplines have a number of outlets for scholarly work, including archival journals, conference proceedings, periodicals, and others. These outlets are commonly known within the discipline, and many have an established reputation and even ranking. Faculty seeking to publish in one of these disciplines, and seeking to advance in rank and tenure status, are well served by knowing the most common scholarly outlets and their rankings. The relatively new discipline of Information Technology does not yet have a well established ranking of scholarly outlets. This paper presents the findings of a survey conducted among the members of the IT community about their perceptions of the quality of various journals and conference proceedings. -

Subscriber Renewal Guide
Advancing Computing as a Science & Profession Subscriber Renewal Guide www.acm.org Dear Subscriber: Your subscription(s) will expire shortly. We urge you to renew quickly to assure continuous service. Please contact us if you have any questions. Adding Service(s): Just list the service(s) you wish to add on the front of your invoice. Be sure to include the appropriate rate(s). Indicate your new Total Amount. ACM offers Expedited Air Service—a partial air service for residents outside of North America. Publications will be delivered within 7 to 14 days. For complete publication information: www.acm.org/publications For non-member subscription information: www.acm.org/publications/alacarte How to Contact ACM Hours: 8:30a.m. to 4:30p.m. Mail: ACM Member Services Dept. (US Eastern Time) General Post Office Phone: 1-800-342-6626 (US & Canada) P.O. Box 30777 +1-212-626-0500 (Global) New York, NY 10087-0777 USA Fax: +1-212-944-1318 Email: [email protected] www.acm.org 07ACM124356 Applications and Research Based Publications Individual Pricing * Institutional Pricing † Magazines and Journals: Issues Per Print Online Print+Online Print Online Print+Online Air Year Collective Intelligence 12 Price ** GOLD OPEN ACCESS ** ** GOLD OPEN ACCESS ** Offer Code Communications of the ACM 12 Price $319 $255 $383 $1,266 $1,014 $1,521 $76 Offer Code 101 201 301 101L 201L 301L Computing Reviews 12 Price $340 $272 n/a $1,036 n/a n/a $50 Offer Code 104 204 104L Computing Surveys 4 Price $305 $244 $366 $887 $711 $1,070 $43 Offer Code 103 203 303 103L 203L 303L Digital -

ACM Student Membership Application and Order Form
student membership application and order form INSTRUCTIONS Name Please print clearly Member Number Carefully complete this PDF applica - tion and return with payment by mail Address or fax to ACM. You must be a full-time student to qualify for student rates. City State/Province Postal code/Zip Ë CONTACT ACM Country Please do not release my postal address to third parties Area code & Daytime phone Email address Ë Yes, please send me ACM Announcements via email Ë No, please do not send me ACM Announcements via email phone: 1-800-342-6626 (US & Canada) +1-212-626-0500 MEMBERSHIP OPTIONS & ADD ONS (Global) MEMBERSHIP OPTIONS: hours: 8:30am - 4:30pm US Eastern Time Ë Student Membership: $19 (USD) fax: +1-212-944-1318 Ë Student Membership PLUS Digital Library: $42 (USD) [email protected] email: Ë Student Membership PLUS Print CACM Magazine: $42 (USD) mail: ACM, Member Services Ë General Post Office Student Membership w/Digital Library PLUS Print CACM Magazine: $62 (USD) P.O. Box 30777 MEMBERSHIP ADD ONS: NY, NY 10087-0777, USA Ë ACM Books Subscription: $10 (USD) For immediate processing, Ë FAX this application to Additional Print Publications and/or Special Interest Groups +1-212-944-1318. PUBLICATIONS Please check one WHAT’S NEW Check the appropriate box and calculate Issues amount due on reverse. per year Code Member Rate Air Rate* ACM Learning Webinars keep you at the • ACM Inroads 4 178 $41 Ë $69 Ë Ë Ë cutting edge of the latest technical and tech - • Communications of the ACM 12 101 $50 $69 • Computers in Entertainment (online only) 4 247 $48 Ë N/A nological developments. -

The ACM Digital Library
The ACM Digital Library Presented By- AJITESH MOY GHOSH Contents Overview History of ACM Digital Library Products/Contents enhancement ACM Publications in Digital Library ACM Digital Library Platform Full Text Content in ACM Digital Library ACM Magazines Included in Digital Library Pricing Overview All of the ACM journals and proceedings online Constantly growing and expanding content Searching and browsing is free to the world See it at: http://www.acm.org/dl History of ACM Digital Library Began creating electronic files in January 1997. Launched a demo version in July 1997 that was free to the world, including unlimited downloading of full text. Went “live” on 1 January 1998 (for pay) Originally contained 120K pages of full text from 1991 to 1997. Products/Contents enhancement ACM journals going back to 1947 All proceedings going back to 1947 All Newsletters (34) to 1977 Usage Stats are available ACM Publications in Digital Library The Premier Publisher of Scholarly Information in the field of Computing 7- Journals - High Impact Titles according to ISI / Web of Science 10 Magazines - Including Flagship Communications of the ACM 25+ Transactions 270+ Proceedings Titles - Archive contains over 2,000 annual volumes ACM Publications in Digital Library 58 Newsletters – Published by ACM & various ACM Special Interest Groups 43 Special Interest Groups contributing content to ACM Digital Library 24 Publications from Affiliate Publishers included in ACM Digital Library 800 videos, animations, movies, etc. 12 Oral History Interviews The Guide