Creating a Gstreamer Plugin for Low Latency Distribution of Multimedia Content Master Thesis
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

106 INKSCAPE – FREE VECTOR GRAPHICS EDITOR Grabareva A
INKSCAPE – FREE VECTOR GRAPHICS EDITOR Grabareva A. Supervisor: Voevodina M. E-mail: [email protected], [email protected] Kharkiv, О.М. Beketov National University of Urban Economy in Kharkiv Inkscape is a cross-platform, powerful enough and in many ways competitive free vector graphics editor with open source code, and in which the SVG format is used as the main standard for work. It is convenient for creating both artistic and technical illustrations. Inkscape is an analogue of such graphic editors as Corel Draw, Adobe Illustrator, Xara X and Freehand. Intended use: - illustrations for office circulars, presentations, creation of logos, business cards, posters; - technical illustrations (diagrams, graphics, etc.); - vector graphics for high-quality printing (with preliminary import of SVG into Scribus); - web graphics – from banners to site layouts, icons for applications and website buttons, - graphics for games. Main characteristics of Inkscape: - the program is free and distributed under the GNU General Public License; - cross-platform; - the program supports the following document formats: import – almost all popular and frequently used formats: SVG, JPEG, GIF, BMP, EPS, PDF, PNG, ICO, and many additional ones, such as SVGZ, EMF, PostScript, AI, Dia, Sketch, TIFF, XPM, WMF, WPG, GGR, ANI, CUR, PCX, PNM, RAS, TGA, WBMP, XBM, XPM; export – the main formats are PNG and SVG and many additional EPS, PostScript, PDF, Dia, AI, Sketch, POV-Ray, LaTeX, OpenDocument Draw, GPL, EMF, POV, DXF; - there is support for layers; - -

Release Notes for Fedora 15
Fedora 15 Release Notes Release Notes for Fedora 15 Edited by The Fedora Docs Team Copyright © 2011 Red Hat, Inc. and others. The text of and illustrations in this document are licensed by Red Hat under a Creative Commons Attribution–Share Alike 3.0 Unported license ("CC-BY-SA"). An explanation of CC-BY-SA is available at http://creativecommons.org/licenses/by-sa/3.0/. The original authors of this document, and Red Hat, designate the Fedora Project as the "Attribution Party" for purposes of CC-BY-SA. In accordance with CC-BY-SA, if you distribute this document or an adaptation of it, you must provide the URL for the original version. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. Red Hat, Red Hat Enterprise Linux, the Shadowman logo, JBoss, MetaMatrix, Fedora, the Infinity Logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries. For guidelines on the permitted uses of the Fedora trademarks, refer to https:// fedoraproject.org/wiki/Legal:Trademark_guidelines. Linux® is the registered trademark of Linus Torvalds in the United States and other countries. Java® is a registered trademark of Oracle and/or its affiliates. XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries. MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries. All other trademarks are the property of their respective owners. -

Guile-Gnome-Gstreamer.Pdf
Guile-GNOME: GStreamer version 0.9.92, updated 10 November 2007 Wim Taymans many others This manual is for (gnome gstreamer) (version 0.9.92, updated 10 November 2007) Copyright 2000-2007 Wim Taymans and others Permission is granted to copy, distribute and/or modify this document under the terms of the GNU General Public License, Version 2 or any later version published by the Free Software Foundation. i Short Contents 1 Overview :::::::::::::::::::::::::::::::::::::::::::: 1 2 GstBin :::::::::::::::::::::::::::::::::::::::::::::: 2 3 GstBuffer:::::::::::::::::::::::::::::::::::::::::::: 8 4 GstBus::::::::::::::::::::::::::::::::::::::::::::: 13 5 GstCaps:::::::::::::::::::::::::::::::::::::::::::: 18 6 GstChildProxy :::::::::::::::::::::::::::::::::::::: 24 7 GstClock ::::::::::::::::::::::::::::::::::::::::::: 26 8 gstconfig ::::::::::::::::::::::::::::::::::::::::::: 33 9 GstElementFactory ::::::::::::::::::::::::::::::::::: 34 10 GstElement ::::::::::::::::::::::::::::::::::::::::: 37 11 GstGError :::::::::::::::::::::::::::::::::::::::::: 53 12 GstEvent ::::::::::::::::::::::::::::::::::::::::::: 55 13 GstFilter ::::::::::::::::::::::::::::::::::::::::::: 63 14 GstFormat :::::::::::::::::::::::::::::::::::::::::: 64 15 GstGhostPad:::::::::::::::::::::::::::::::::::::::: 66 16 GstImplementsInterface ::::::::::::::::::::::::::::::: 68 17 GstIndexFactory ::::::::::::::::::::::::::::::::::::: 69 18 GstIndex ::::::::::::::::::::::::::::::::::::::::::: 70 19 GstInfo :::::::::::::::::::::::::::::::::::::::::::: 74 20 GstIterator ::::::::::::::::::::::::::::::::::::::::: -

Oracle® Secure Global Desktop Platform Support and Release Notes for Release 5.2
Oracle® Secure Global Desktop Platform Support and Release Notes for Release 5.2 April 2015 E51729-03 Oracle Legal Notices Copyright © 2015, Oracle and/or its affiliates. All rights reserved. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, delivered to U.S. Government end users are "commercial computer software" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, use, duplication, disclosure, modification, and adaptation of the programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, shall be subject to license terms and license restrictions applicable to the programs. No other rights are granted to the U.S. -

Gstreamer & Rust
GStreamer & Rust Fast, safe and productive multimedia software FOSDEM 2018 – Rust devroom 4 February, Brussels Sebastian Dröge < [email protected] > Introduction Who? What? + What is GStreamer? https://gstreamer.freedesktop.org for more details GStreamer Pipeline-based, cross-platform multimedia framework Media Pipelines Philosophy Toolbox for higher-level multimedia processing Batteries included … … and usable from many languages But not … Media player or playback library Codec and protocol library Transcoding tool Streaming server … can be used to build all that! GStreamer ❤ Rust Why Rust? Memory-safety, fearless concurrency & modern language and tooling Why Rust? No runtime, no GC & zero-cost abstractions Why Rust? Ownership model maps perfectly to GStreamer's Using GStreamer from Rust Applications Safe, idiomatic bindings to the GStreamer C API https://github.com/sdroege/gstreamer- rs Examples: gstreamer-rs/examples Tutorials: gstreamer-rs/tutorials Plugins Safe, plain Rust infrastructure for writing plugins https://github.com/sdroege/gst-plugin- rs Contains various examples Tutorials being written right now The Future Write more Rust & write less C more plugins (rust-av!), more useful applications This is where you can get involved! We're not going to rewrite GStreamer (yet) It's the perfect time for writing your next GStreamer application or plugin in Rust Rust experience so far Don't be afraid of unsafe code if needed … … but wrap in safe abstractions Don't be afraid of other people's code Adding dependencies is easy, and -

D3 Intelligent Camera Platform
Easy! D3 Intelligent Camera Platform Intelligent Cameras | Framegrabbers | Made in Germany WWW.STEMMER-IMAGING.COM Ease of Use The D3 Intelligent Camera New Intelligent Camera Platform The D3 is the latest, most advanced intelligent camera generation by VRmagic. The D3 platform was designed with usability, flexibility, and performance in mind. Excellent Usability The D3 platform runs a wide range of embedded software and libraries, such as Common Vision Blox Embedded, EyeVision, or HALCON Embedded. This way you can easily take advantage of the latest, state- of-the-art machine vision algorithms. Additionally, the new Mono compatible .NET interface makes applica- tion development with the VRmagic SDK much easier. Software development for the D3 intelligent camera platform – that’s ease of use. Built-In Flexibility The D3‘s embedded system provides users with a high level of flexibility by supporting a multitude of interfaces, such as Ethernet, USB, and GPIOs. Choose either a standard OEM interface board for compact systems integration or an interface evaluation board for convenient test and development. A version for industrial environments is also available. Depending on the business case, a custom interface board may also be a viable option. High Performance The D3 intelligent camera platform features a 1 GHz ARM® Cortex™-A8 Core with floating point unit (FPU) running Linux. A 700 MHz C674x™ DSP with FPU is at your disposal for computationally intensive algo- The D3 Industrial Camera has a rigid aluminum rithms. 2 GB DDR3-800 RAM with 6103 MB/s band- body and industry-standard interfaces such as width and a Gigabit Ethernet interface ensure rapid 24 V power supply and Power over Ethernet. -

Camcorder Multimedia Framework with Linux and Gstreamer
Camcorder multimedia framework with Linux and GStreamer W. H. Lee, E. K. Kim, J. J. Lee , S. H. Kim, S. S. Park SWL, Samsung Electronics [email protected] Abstract Application Applications Layer Along with recent rapid technical advances, user expec- Multimedia Middleware Sequencer Graphics UI Connectivity DVD FS tations for multimedia devices have been changed from Layer basic functions to many intelligent features. In order to GStreamer meet such requirements, the product requires not only a OSAL HAL OS Layer powerful hardware platform, but also a software frame- Device Software Linux Kernel work based on appropriate OS, such as Linux, support- Drivers codecs Hardware Camcorder hardware platform ing many rich development features. Layer In this paper, a camcorder framework is introduced that is designed and implemented by making use of open Figure 1: Architecture diagram of camcorder multime- source middleware in Linux. Many potential develop- dia framework ers can be referred to this multimedia framework for camcorder and other similar product development. The The three software layers on any hardware platform are overall framework architecture as well as communica- application, middleware, and OS. The architecture and tion mechanisms are described in detail. Furthermore, functional operation of each layer is discussed. Addi- many methods implemented to improve the system per- tionally, some design and implementation issues are ad- formance are addressed as well. dressed from the perspective of system performance. The overall software architecture of a multimedia 1 Introduction framework is described in Section 2. The framework design and its operation are introduced in detail in Sec- It has recently become very popular to use the internet to tion 3. -

1. Mengapa GIMP & Inkscape Tidak Punya Warna
Paten Software Merugikan Komunitas Free Software Bismillahirrahmanirrahim. Copyright © 2016 Ade Malsasa Akbar <[email protected]> Tulisan ini berbicara mengenai bahaya paten software yang mengakibatkan banyak Free Software mengalami kekurangan fitur dibanding software proprietari komersial. Tulisan ini awalnya berjudul Mengapa Free Software Mengalami Kekurangan Fitur? tetapi diubah pada 16 Maret 2016 menjadi berjudul yang sekarang. Tulisan ini diharapkan membangkitkan kesadaran setiap orang terhadap perlunya Free Software. Tulisan ini disusun dalam format tanya jawab atau FAQ supaya tepat sasaran dan mudah dimengerti. Saya bukan hanya menulis ini untuk mereka yang bertanya-tanya kenapa Free Software seperti LibreOffice, GIMP, Inkscape, ODF, dan OGG Vorbis mengalami kekurangan fitur. Namun juga saya meniatkan tulisan ini sebagai pengantar buat siapa saja yang hendak menggunakan Free Software, baik pengguna baru maupun yang sudah lama. 1. Mengapa GIMP & Inkscape tidak punya warna Pantone? Karena Pantone Color Matching telah dipatenkan1. Hanya pemilik paten tersebut yang berhak membuat implementasi Pantone di dalam software. Konsekuensinya, GIMP (dan free software lainnya) dilarang membuat fitur Pantone ke dalam software. 2. Mengapa Linux Mint menyediakan versi no-codec? Karena versi no-codec2 dibuat untuk negara Jepang yang di sana MP3 dipatenkan. Pada dasarnya tidak boleh mendistribusikan codec MP3 di Jepang kecuali pemegang asli paten MP3. Berlaku juga untuk negara Amerika Serikat dan Uni Eropa. 3. Mengapa Linux Mint menyertakan codec? Karena versi Linux Mint yang menyertakan codec itu ditujukan untuk semua negara yang di sana codec MP3 tidak dipatenkan. Linux Mint (yang memuat codec) tidak didistribusikan di negara Jepang, Amerika Serikat, dan Uni Eropa3 karena di sana MP3 telah dipatenkan. Kenyataan ini yang tidak banyak diketahui. -
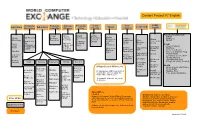
Content Project V7 English
Content Project V7 English Public Computer Entrepre- Climate Program- Solar Water Tech Leadership Agriculture Recycling Education neurship Change ming Energy Literacy Health Potential and Growth CD3W Videos BFOIT CD3W IEARN We Recycle Business Lessons Introduction Resources CD3W CD3W Resources Getting Where GirlRising Resources Resources Readings to on Solar Started with Class UNGEI How to Set Computer Energy on Water There Is No and Ubuntu Manage- Doctor Peace Up Nat’l Geo Program- 10.04 ment STEM Computer a Climate.gov ming Sanitation Corps UNESCO Khan Academy Books Refurbishing CLEAN Getting Empowering Center and more UN Lesson HIV/AIDS WikiSlice Plans on Started with Girls Library Ck-12 Textbooks Adrodok Water OpenOffice Intro to Computer Prog Empowering Medline Thinkersmith Vegetable How to Girls-School Computer Sci in a Box Garden Assemble a Computer Ubuntu Manual Life Skills Childhood LibreOffice Guides Healthy Illness Harvest Math Science Reference Writing Soc.Sci. Promoting Comp. for Class. Guidesl Powerful Health for People Health Wikipedia and Wikibooks Children Hesperian Health Guides Khan Video BlueMall Medline Learning Volunteer- Teach AIDS Khan Video Lessons Basic 20 Gigabytes with thousands of Health Medline Plus Lessons Spelling Center ism Activities for Language searchable articles using the Pop. Council Activities Ck-12 Kiwix offline wiki-reader Primary Gr. Ck-12 Textbooks Dictionary Common World Map Textbooks Sense Project HIV Toolkit Wiki HowTo Thousands of books for youth WikiSlice Compositio of all ages Unesco -Animals -

The Gnome Desktop Comes to Hp-Ux
GNOME on HP-UX Stormy Peters Hewlett-Packard Company 970-898-7277 [email protected] THE GNOME DESKTOP COMES TO HP-UX by Stormy Peters, Jim Leth, and Aaron Weber At the Linux World Expo in San Jose last August, a consortium of companies, including Hewlett-Packard, inaugurated the GNOME Foundation to further the goals of the GNOME project. An organization of open-source software developers, the GNOME project is the major force behind the GNOME desktop: a powerful, open-source desktop environment with an intuitive user interface, a component-based architecture, and an outstanding set of applications for both developers and users. The GNOME Foundation will provide resources to coordinate releases, determine future project directions, and promote GNOME through communication and press releases. At the same conference in San Jose, Hewlett-Packard also announced that GNOME would become the default HP-UX desktop environment. This will enhance the user experience on HP-UX, providing a full feature set and access to new applications, and also will allow commonality of desktops across different vendors' implementations of UNIX and Linux. HP will provide transition tools for migrating users from CDE to GNOME, and support for GNOME will be available from HP. Those users who wish to remain with CDE will continue to be supported. Hewlett-Packard, working with Ximian, Inc. (formerly known as Helix Code), will be providing the GNOME desktop on HP-UX. Ximian is an open-source desktop company that currently employs many of the original and current developers of GNOME, including Miguel de Icaza. They have developed and contributed applications such as Evolution and Red Carpet to GNOME. -

Example in English
Means of (re)production: GStreamer Outline GStreamer: Multimedia for all @fluendo.com: What we're up to GStreamer What is GStreamer? * A multimedia library and set of plugins * Modular building blocks for media applications Brief example v4l2src ! ffmpegcolorspace ! ximagesink GStreamer history * 0.0.9 October 1999 * 0.1.0 January 2001 * 0.3.0 December 2001 * 0.4.0 July 2002 * 0.6.0 February 2003 * API Stable * 0.8.0 March 2004 * 0.10.0 December 2005 GStreamer history No one can accuse us of version number inflation :) Next incompatible break will be the last: 1.0 An application-based introduction A tour through GStreamer Players Historically the first applications built on GStreamer Surprisingly difficult Players: solutions How do applications interact with a playing media pipeline? * Generic core API to create and interact with pipeline * Media pipeline runs in threads * Messages posted both synchronously and asynchronously from pipeline Players: solutions Synchronization between audio and video * Threads Players: solutions Autoplugging: play any format * Registry of "typefinders" * Registry of capabilities that plugins can handle * Elements that perform autoplugging for you Transcoding / capture E.g. thoggen DVD ripper, radio production apps, flumotion Transcoding / capture: solutions Robustness * long-running pipelines * high load * large number of different codecs Transcoding / capture: solutions Features * language bindings * many capture sources * v4l, firewire, ... * network data flow over tcp * network clock synchronization "Embedded" -

This Is a Free, User-Editable, Open Source Software Manual. Table of Contents About Inkscape
This is a free, user-editable, open source software manual. Table of Contents About Inkscape....................................................................................................................................................1 About SVG...........................................................................................................................................................2 Objectives of the SVG Format.................................................................................................................2 The Current State of SVG Software........................................................................................................2 Inkscape Interface...............................................................................................................................................3 The Menu.................................................................................................................................................3 The Commands Bar.................................................................................................................................3 The Toolbox and Tool Controls Bar........................................................................................................4 The Canvas...............................................................................................................................................4 Rulers......................................................................................................................................................5