Genetic Diversity and Population Structure Analysis of Kala Bhat
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Directory Establishment
DIRECTORY ESTABLISHMENT SECTOR :URBAN STATE : UTTARANCHAL DISTRICT : Almora Year of start of Employment Sl No Name of Establishment Address / Telephone / Fax / E-mail Operation Class (1) (2) (3) (4) (5) NIC 2004 : 0121-Farming of cattle, sheep, goats, horses, asses, mules and hinnies; dairy farming [includes stud farming and the provision of feed lot services for such animals] 1 MILITARY DAIRY FARM RANIKHET ALMORA , PIN CODE: 263645, STD CODE: 05966, TEL NO: 222296, FAX NO: NA, E-MAIL : N.A. 1962 10 - 50 NIC 2004 : 1520-Manufacture of dairy product 2 DUGDH FAICTORY PATAL DEVI ALMORA , PIN CODE: 263601, STD CODE: NA , TEL NO: NA , FAX NO: NA, E-MAIL 1985 10 - 50 : N.A. NIC 2004 : 1549-Manufacture of other food products n.e.c. 3 KENDRYA SCHOOL RANIKHE KENDRYA SCHOOL RANIKHET ALMORA , PIN CODE: 263645, STD CODE: 05966, TEL NO: 1980 51 - 100 220667, FAX NO: NA, E-MAIL : N.A. NIC 2004 : 1711-Preparation and spinning of textile fiber including weaving of textiles (excluding khadi/handloom) 4 SPORTS OFFICE ALMORA , PIN CODE: 263601, STD CODE: 05962, TEL NO: 232177, FAX NO: NA, E-MAIL : N.A. 1975 10 - 50 NIC 2004 : 1725-Manufacture of blankets, shawls, carpets, rugs and other similar textile products by hand 5 PANCHACHULI HATHKARGHA FAICTORY DHAR KI TUNI ALMORA , PIN CODE: 263601, STD CODE: NA , TEL NO: NA , FAX NO: NA, 1992 101 - 500 E-MAIL : N.A. NIC 2004 : 1730-Manufacture of knitted and crocheted fabrics and articles 6 HIMALAYA WOLLENS FACTORY NEAR DEODAR INN ALMORA , PIN CODE: 203601, STD CODE: NA , TEL NO: NA , FAX NO: NA, 1972 10 - 50 E-MAIL : N.A. -

Binsar Diary
1 Binsar diary Anil K Rajvanshi [email protected] 1. Binsar is a beautiful hill station in Almora district in State of Uttarakhand. It is inside a forest sanctuary and at an elevation of 2400 m above sea level. It is one of the highest hill stations in Kumaon region. From Almora it is about 35 kms distance and takes almost 1.5 hours to reach through winding narrow mountain roads. 2. We had gone to this place in October 2009. The route we took was from Bareilly to Binsar via Bhowali. I had to deliver a couple of lectures at Bareilly in Invertis Business School and thought would take this opportunity to visit the abode of lord Shiva. 3. I chose Binsar because one can see a huge range of Himalayas when there are no clouds. Obviously lord Shiva smiled on us and we were blessed with a clear view of the Himalayas during our stay. 4. The best place in Binsar to get a fantastic view of the Himalayan range is from the KMVN rest house situated at the end of the road inside the Binsar wildlife sanctuary. The terrace of this rest house provides an excellent view of Trishul, Nanda Devi (the 4th highest peak in the world) and Panchchuli peaks - an expanse of about 300-500 km of Himalayan range. The sky was absolutely clear and blue with hardly any trace of dust or haziness and the weather was pretty cold with temperature touching 6-70C in early morning. 5. The view from the KMVN rest house is fantastic and one gets a feeling that these beautiful snow clad peaks are just a few km away. -
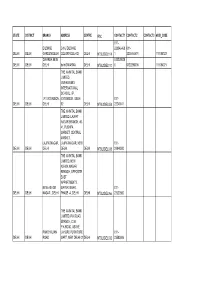
State District Branch Address Centre Ifsc
STATE DISTRICT BRANCH ADDRESS CENTRE IFSC CONTACT1 CONTACT2 CONTACT3 MICR_CODE 011- DILSHAD C-16, DILSHAD 223546460 011- DELHI DELHI GARDEN DELHI COLONY DELHIQ DELHI NTBL0DEL114 1 2235464601 110184023 DWARKA NEW 512228030 DELHI DELHI DELHI delhi DWARKA DELHI NTBL0DEL110 0 5122280300 110184021 THE NAINITAL BANK LIMITED, VIVEKANAND INTERNATIONAL SCHOOL, I.P. I.P. EXTENSION, EXTENSION, DELHI 011- DELHI DELHI DELHI 92 DELHI NTBL0DEL053 22240041 THE NAINITAL BANK LIMITED, LAJPAT NAGAR BRANCH, 40- 41, PUSHPA MARKET, CENTRAL MARKET, LAJPATNAGAR, LAJPATNAGAR, NEW 011- DELHI DELHI DELHI DELHI DELHI NTBL0DEL038 29848500 THE NAINITAL BANK LIMITED, NEW ASHOK NAGAR BRANCH, OPPOSITE EAST APPARTMENTS, NEW ASHOK MAYUR VIHAR, 011- DELHI DELHI NAGAR , DELHI PHASE -A, DELHI DELHI NTBL0DEL066 22622800 THE NAINITAL BANK LIMITED, P.K.ROAD BRANCH, C-36, P.K.ROAD, ABOVE PANCHKUIAN LAHORE FURNITURE 011- DELHI DELHI ROAD MART, NEW DELHI 01 DELHI NTBL0DEL032 23583606 THE NAINITAL BANK LIMITED, PAPPANKALAN BRANCH, 29/2, VIJAY ENCLAVE, PALAM PAPPANKALAN( DABRI ROAD, KAPAS 011- DELHI DELHI DWARKA) DWARKA, DELHI HERA NTBL0DEL059 25055006 THE NAINITAL BANK LIMITED, PATPARGANJ BRANCH, P-37, PANDAV NAGAR, 011- DELHI DELHI PATPARGANJ PATPARGANJ, DELHI DELHI NTBL0DEL047 22750529 THE NAINITAL BANK LIMITED, PITAMPURA BRANCH, SATABDI HOUSE, PLOTNO. 3, COMMERCIAL COMPLEX, ROHIT KUNJ, WEST PITAMPURA , PITAMPURA 110034, 011- DELHI DELHI DELHI DELHI DELHI NTBL0DEL049 27353273 THE NAINITAL BANK LIMITED, ROHINI BRANCH, E-4, SECTOR 16, JAIN BHARTI MODEL, PUBLIC SCHOOL, ROHINI, ROHINI, -

List of Judicial Officers Whose Transfers Are Due
LIST OF TRANSFERS FOR ANNUAL YEAR - 2015 (A). H.J.S. OFFICERS (DISTRICT JUDGES & ADDITIONAL DISTRICT JUDGES) Sl. Name & designation Place of Posting No. 1. Sri K.D. Bhatt Chairman, Commercial Tax Tribunal, Dehradun Principal Secretary, Law-cum-L.R. Government of Uttarakhand, Dehradun 2. Sri Ram Singh Principal Secretary, Law-cum-L.R. District Judge, Dehradun Government of Uttarakhand, Dehradun 3. Ms. Kumkum Rani District Judge, Nainital District Judge, Hardwar 4. Sri R.D. Paliwal District Judge, Dehradun Chairman, Commercial Tax Tribunal, Dehradun 5 Sri N.S. Dhanik District Judge, Hardwar District Judge, Nainital 6. Smt. Meena Tiwari District Judge, Tehri Garhwal Director, Uttarakhand Judicial & Legal Academy, Bhowali, District Nainital 7. Sri Alok Kumar Verma District Judge, Chamoli Presiding Officer, Labour Court, Hardwar 8. Sri Uttam Singh Nabiyal Presiding Officer, Industrial Tribunal, Haldwani, District Judge, District Nainital Chamoli 9. Sri C.P. Bijalwan Presiding Officer Labour Court, Dehradun District Judge, Pithoragarh 10. Sri Sikand Kumar Tyagi District Judge, Pithoragarh District Judge, Tehri Garhwal 11. Sri Pradeep Pant Director, Uttarakhand Judicial & Legal Academy, Bhowali, Member Secretary, District Nainital Uttarakhand State Legal Services Authority, Nainital 12. Sri Hira Singh Bonal Presiding Officer, Food Safety Appellate Tribunal, Judge, Family Court, Dehradun Pauri Garhwal 13. Sri Rajendra Joshi Presiding Officer, Food Safety Appellate Tribunal, Judge, Family Court, Haldwani, District Nainital Udham Singh Nagar 14. Sri Prashant Joshi Member Secretary, Uttarakhand State Legal Services 1st Additional District Judge, Authority, Nainital Dehradun 15. Sri Prem Singh Khimal Presiding Officer, Labour Court, Hardwar Judge, Family Court, Hardwar 16. Ms. Kahkasha Khan Additional Secretary-cum-Additional L.R., Additional District Judge, Government of Uttarakhand, Dehradun Ranikhet, District Almora 17. -

City Development Plan: Nainital Revised
Urban Development Department Government of Uttarakhand City Development Plan: Nainital Revised Under Jawaharlal Nehru National Urban Renewal Mission (JNNURM) May 2007 GHK International, UK in association with Infrastructure Professionals Enterprise ENC Consulting Engineers Ver 308 Preface The City Development Plan (CDP) of Nainital is prepared as a part of the initiative of Government of Uttarakhand to access funds under the Jawaharlal Nehru National Urban Renewal Mission (JNNURM). CDP is one of the pre-requisites for accessing funds under the scheme. This CDP focuses on the municipal area of Nainital. At the same time it takes into consideration the future urban growth of Nainital city which is likely to grow beyond the present municipal boundary. The likely urban growth in the nearby municipal areas of Nainital and Bhimtal, Naukuchiatal, Sattal, Khurpatal and areas falling under 220 yards on both sides of the roads connecting these lakes has been kept in view while formulating the City Development Plan. The suggestions and recommendations contained in the Stakeholder meetings and workshops have also been taken into consideration for Institutional Development as well as identified works proposed in the City Investment Plan. The CDP was first prepared in August 2006. The CDP was adopted by the State Level Nodal Agency and forwarded to Ministry of Urban Development, Government of India. The CDP was subsequently appraised by the National Institute of Urban Affairs (NIUA). The comments and observations of NIUA have been duly incorporated -

Bhowali Travel Guide - Page 1
Bhowali Travel Guide - http://www.ixigo.com/travel-guide/bhowali page 1 Famous For : City Cold weather. Carry Heavy woollen, umbrella. Bhowali When To Max: 15.7°C Min: 12.4°C Rain: 255.0mm Sep VISIT Cold weather. Carry Heavy woollen, umbrella. Max: 13.8°C Min: 10.6°C Rain: 144.0mm http://www.ixigo.com/weather-in-bhowali-lp-1043541 Oct Jan Cold weather. Carry Heavy woollen. Very cold weather. Carry Heavy woollen. Max: 17.0°C Min: 11.5°C Rain: 6.0mm Max: 8.1°C Min: 1.1°C Rain: 15.0mm Nov Feb Very cold weather. Carry Heavy woollen. Very cold weather. Carry Heavy woollen. Max: 13.5°C Min: 6.3°C Rain: 0.0mm Max: 9.9°C Min: 6.0°C Rain: 0.0mm Dec Mar Very cold weather. Carry Heavy woollen. Very cold weather. Carry Heavy woollen, Max: 12.4°C Min: 5.2°C Rain: 6.0mm umbrella. Max: 11.3°C Min: 2.6°C Rain: 96.0mm Apr What To Very cold weather. Carry Heavy woollen. Max: 16.2°C Min: 5.7°C Rain: 6.0mm SEE May 1 Sights Cold weather. Carry Heavy woollen. http://www.ixigo.com/places-to-visit-see-in-bhowali-lp-1043541 Max: 22.0°C Min: 10.8°C Rain: 3.0mm 1 Kainchi Dham Jun Cold weather. Carry Heavy woollen, umbrella. Max: 15.2°C Min: 9.4°C Rain: 81.0mm Jul Cold weather. Carry Heavy woollen, This Pdf and its contents are copyright © 2013,ixigo.com, all rights reserved. -

Uttarakhand(70
Details in subsequent pages are as on 01/04/12 For information only. In case of any discrepancy, the official records prevail. DETAILS OF THE DEALERSHIP OF HPCL Zone:NORTH CENTRAL ZONE STATE:UTTARANCHAL SR. No. Regional State Name of dealership Dealership address (incl. Name(s) of Proprietor/Partner(s) Outlet Telephone No. Office location, Dist, State, PIN) 1DEHRADUNUTTARANC BEHL SERVICE CENTRE HP DEALER, NAINITAL ROAD, APJIT SINGH & KARANPAL SINGH 9897063536 HAL RUDRAPUR, U.S. NAGAR, UTTARAKHAND-263153 2DEHRADUNUTTARANC HAMARA PUMP - SSDN KHAI KHERA, KASHIPUR-DADHYAL SANJAY SINDHWANI 9012100006 HAL ROAD, U.S. NAGAR, UTTARAKHAND- 244713 3DEHRADUNUTTARANC HEMKUND FUELS GADARPUR-BILASPUR ROAD, AMARPREET KAUR 9917090089 HAL RATANPURA, U.S. NAGAR, UTTARAKHAND-263152 4DEHRADUNUTTARANC KISAN SERVICE CENTRE SATHUIA, KITCHA, U.S. NAGAR, AJAI KUMAR AGARWAL 9412290172 HAL UTTARAKHAND-263148 5DEHRADUNUTTARANC SIDHARTH FILLING STATION SUAR ROAD, DORAHA, U.S. NAGAR , ANITA DEVI 9415821491 HAL UTTARAKHAND-262401 6DEHRADUNUTTARANC CENTRE FORWARD PETROLEUM KISHANPUR, JASPUR, U.S. NAGAR, URVASHI CHAHUAN 8923850211 HAL UTTARAKHAND-244712 7DEHRADUNUTTARANC CHAWLA AGRO CENTRE JAFARPUR, KHANPUR, RUDRAPUR, BALBIR SINGH CHAWLA 9917611000 HAL U.S. NAGAR, UTTARAKHAND-263153 8DEHRADUNUTTARANC GURU KRIPA FILLING STATION KASHIPUR ROAD, JASPUR, U.S. JASVIR SINGH 9837177999 HAL NAGAR, UTTARAKHAND-264712 9DEHRADUNUTTARANC GURU NANAK FUELS STATION NEAR PRIMARY SCHOOL, DARAU, SUNITA 9412020619 HAL KICHHA, U.S. NAGAR, UTTARAKHAND-263158 10 DEHRADUN UTTARANC HAMARA PUMP NADEHI JASPUR-THAKURDWARA ROAD, GURDEEP SINGH & KIRTI RANI 9412404000 HAL NADEHI, JASPUR, U.S. NAGAR, UTTARAKHAND-264712 11 DEHRADUN UTTARANC HAMARA PUMP -PAIGA KASHIPUR-ALIGANJ ROAD, PAIGA, BALVINDER SINGH 9927008339 HAL KASHIPUR, U.S. NAGAR, UTTARAKHAND-244713 12 DEHRADUN UTTARANC K BINDRA FILLING STATION KITCHA BYEPASS, HALDWANI- KULPREET SINGH BINDRA & DALPAT 9412290205 HAL BAREILLY ROAD, U.S. -

The Almora Thrust (Heim & Gansser 1939) in Kumaon Himalaya Separates the Underlying Younger Rocks of Krol Nappe from Those O
ON THE NATURE OF THE RAMGARH THRUST IN KUMAON HIMALAYAS S. S. MERH, N. M. VASHl AND J. P. PATEL Department of Geology, M. S. University, Baroda The Almora Thrust (Heim & Gansser 1939) in Kumaon Himalaya separates the underlying younger rocks of Krol nappe from those of Almora nappe above it. South of Someswar-Dwarahat, this thrust is seen synformally folded, and its northern flank has been termed as North Almora thrust; its southern flank is somewhat controversial. The town of Bhowali is situated on an anticline which perhaps is complementary to the above mentioned synform to the north. Between Bhowali and Ranikhet-Almora, most workers have shown two thrusts dipping due NE, one is ideally seen near Ramgarh and the other is observed on the Ranikhet road near Upradi (Vashi & Merh 1965). Heim and Gansser have joined up the Ramgarh Thrust with North Almora thrust, though they have shown the thrust at Upradi as South Almora thrust. Gansser (1964) too has considered the Ramgarh thrust as the southern limb of the synformally folded Almora thrust. He has not given any name to the thrust at Upradi. Vashi & Merh (1965) have however suggested that the Upradi thrust is in fact the southern limb of the folded Almora thrust. Merh (1968) does not believe that the thrust at Ramgarh is the southern extension of Almora thrust, forming, a nappe of Chandpur rocks (Ramgarh nappe). According to Heim & Gansser (1939, p. 28) the region between Bhowali and Upradi Thrust ( = South Almora thrust) comprises a recumbent syncline overturned to the sw. There are however few field data to support the existence of such folded structure as visualised by Heim & Gansser, in the Ramgarh area. -

Uttarakhand Covid-19 Telephone/Mobile Directory Fueu
fnukad& 27-04-2021 le; 7%00 lka; rd v|ru Uttarakhand Covid-19 Telephone/Mobile Directory Note: ,slk laHko gS fd bl Mk;jsDVjh dks rS;kj djrs le; dfri; =qfV;ka@dfe;k¡ jg xà gks]a ;fn dksà =qfV fdlh ds laKku esa vkrh gS rks —i;k bl Ãesy ij lwfpr djus dk d"V djsa rkfd mls nwj fd;k tk ldsA& [email protected] bl Mk;jsDVjh dks yxkrkj v|ru fd;k tk jgk gS] uohure çfr Mkmuyksm djus ds fy, bl Çyd dks fDyd djsa & https://health.uk.gov.in/files/Covid-19-Directory.pdf fuEu tkudkjh ds fy, fn;s x;s fyad ij fDyd djsa& Sample Collection Centres https://covid19.uk.gov.in/map/sccLocation.aspx Availability of Beds https://covid19.uk.gov.in/bedssummary.aspx Covid-19 Vaccination Sites www.cowin.gov.in RT – PCR Testing Report www.covid19.uk.gov.in To get Medical assistant and http://www.esanjeevaniopd.in/Register Doctor's consultation: Download app: Free Consultation from https://play.google.com/store/apps/details?id=in.hi Esanjeevani ed.esanjeevaniopd&hl=en_US Or call: 9412080703, 9412080622, 9412080686 Home Isolation Registration https://dsclservices.org.in/self-isolation.php Vaccination (Self Registration) www.cowin.gov.in https://selfregistration.cowin.gov.in/ Any other Help Call 104 (24X7) / 0135-2609500/ District Control Room for any other help and assistance. Daily Bulletin https://health.uk.gov.in/pages/display/140-novel- corona-virus-guidelines-and-advisory- Travelling to/from https://dsclservices.org.in/apply.php Uttarakhand Registration for any queries and [email protected] suggestions 104/0135 2609500 1 tuinksa ls lacafèkr tkudkjh ds fy, tuinksa ds uke ij fDyd djsa 1. -

In the High Court of Uttarakhand at Nainital
IN THE HIGH COURT OF UTTARAKHAND AT NAINITAL THE HON’BLE THE CHIEF JUSTICE SRI RAGHVENDRA SINGH CHAUHAN AND THE HON’BLE SRI JUSTICE ALOK KUMAR VERMA Writ Petition (PIL) No. 58 of 2020 Writ Petition (PIL) No. 97 of 2019 Writ Petition (PIL) No. 50 of 2020 Writ Petition (PIL) No. 51 of 2020 Writ Petition (PIL) No. 67 of 2020 Writ Petition (PIL) No. 70 of 2020 20TH MAY, 2021 Mr. Shiv Bhatt, the learned counsel for the petitioner in WPPIL No. 58 of 2020. Mr. Dushyant Mainali, the learned counsel for the petitioner in WPPIL No. 50 of 2020. Mr. Abhijay Negi, the learned counsel for the petitioner in WPPIL No.97 of 2019. Mr. S.N. Babulkar, the learned Advocate General assisted by Mr. C.S. Rawat, the learned Chief Standing Counsel for the State of Uttarakhand. Mr. Rakesh Thapliyal, the learned Assistant Solicitor General for the Union of India. COMMON ORDER:(per Hon’ble The Chief Justice Sri Raghvendra Singh Chauhan) In compliance of the order dated 10.05.2021, Mr. Om Prakash, the learned Chief Secretary, Mr. Amit Negi, the learned Secretary, Medical Health and Family Welfare, Mr. Dilip Jawalkar, the learned Secretary, Uttarakhand Tourism and, Mr. Vedprakash Mishra, Director, Department of Pharmaceuticals, are present before this Court today through video conferencing. 2. Mr. Amit Negi, the learned Secretary, Medical Health and Family Welfare and, Mr. Amit Sinha, the Inspector General/Nodal Officer, Police Headquarter, have filed their respective affidavits. The same shall be taken on record. 3. On the other hand, Mr. Rakesh Thapliyal, the learned Assistant Solicitor General appearing for the Union of India, has submitted a series of documents along with miscellaneous application No.9013 of 2021. -

Copy of UTTARAKHAND Annex H2 FINAL.Xlsx
Sl. No Name of location Type of Estimat Category Finance to be Mode of Fixed Fee Security RO ed Minimum Dimension (in arranged by the Selection / Deposit Type of Revenue District monthly M.)/Area of the site (in Sq. applicant Minimu Site* Sales M.). * m Bid Potentia amount l # 1 2 3 4 5 6 7 8 9a 9b 10 11 12 Regular / MS+HSD SC Estimate Estimate Draw of Lots / Rural in Kls SC CC-1 d d fund Bidding SC CC-2 working required SC PH capital for ST requirem develop ST CC-1 ent for ment of ST CC-2 operatio infrastru ST PH n of RO cture at OBC CC / DC / RO Frontage Depth Area OBC CC-1 CFS OBC CC-2 OBC PH OPEN OPEN CC-1 OPEN CC-2 OPEN PH HALDWANI WML , ON HALDWANI TO BAREILLY 1 NAINITAL REGULAR 100 Open DC 20 20 400 25 45 DRAW OF LOTS 15 5 ROAD BETWEEB KM STONE NO 140 AND 142, ON NH 09, 2 CHAMPAWAT REGULAR 150 OBC DC 20 20 400 25 75 DRAW OF LOTS 15 4 TANAKPUR TO PITHORAGARH ROAD 3 LOHAGHAT, WML CHAMPAWAT REGULAR 100 SC CFS 20 20 400 25 0 DRAW OF LOTS 0 3 WITHIN 4 KM FROM CENTRAL HOSPITAL, ON GAS 4 NAINITAL REGULAR 100 Open DC 20 20 400 25 45 DRAW OF LOTS 15 5 GODOWN ROAD TO PANCHAYAT GHAR, HALDWANI BETWEEN KM STONE NO 19 AND 22, ON NH 121 , 5 NAINITAL REGULAR 150 Open DC 35 45 1575 25 75 DRAW OF LOTS 15 5 KASHIPUR TO RAMNAGAR ROAD BETWEEN KM STONE NO 124 AND 127 ,ON NH 109, 6 ALMORA REGULAR 150 OBC DC 20 20 400 25 75 DRAW OF LOTS 15 4 RANIKHET TO DWRAHAT ROAD BETWEEN KM STONE NO. -

Situation Assessment Report
Situation Assessment Report Faecal Sludge and Septage Management Uttarakhand State April, 2019 This is a Situation Assessment Report of Uttarakhand State with regards to Wastewater & Faecal Sludge Management based on qualitative assessment of five towns in the state representing the diverse conditions. It has state level and city level assessment with respect to wastewater and faecal sludge management. The findings of the study will be used for the preparation of contextualised training material for capacity building of concerned stakeholders like decision makers, engineers from para statals and ULBs, elected representatives, private sector etc. in Uttarakhand State. March 2019 © Ecosan Services Foundation, 2019 Drafted by: Mr. Abhishek Sakpal, Project Associate Mr. Saurabh Kale, Sr. Project Manager Mr. Dhawal Patil, General Manager – Operations Organization details: First Floor, 24, Prashant Nagar, 721/1, Sadashiv Peth, L.B.S. Road, Pune 411030, Maharashtra, India. In Association with: Contents Table of Figures ........................................................................................................................ I List of Tables ........................................................................................................................... V Glossary ................................................................................................................................ VII 1 Uttarakhand State Profile ............................................................................................... 1