Magma: a Ground-Truth Fuzzing Benchmark
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Software Testing
Software Testing PURPOSE OF TESTING CONTENTS I. Software Testing Background II. Software Error Case Studies 1. Disney Lion King 2. Intel Pentium Floating Point Division Bug 3. NASA Mars Polar Lander 4. Patriot Missile Defense System 5. Y2K Bug III. What is Bug? 1. Terms for Software Failure 2. Software Bug: A Formal Definition 3. Why do Bugs occur? and cost of bug. 4. What exactly does a Software Tester do? 5. What makes a good Software Tester? IV. Software Development Process 1. Product Components 2. What Effort Goes into a Software Product? 3. What parts make up a Software Product? 4. Software Project Staff V. Software Development Lifecycle Models 1. Big Bang Model 2. Code and Fix Model 3. Waterfall Model 4. Spiral Model VI. The Realities of Software Testing VII. Software Testing Terms and Definition 1. Precision and Accuracy 2. Verification and Validation 3. Quality Assurance and Quality Control Anuradha Bhatia Software Testing I. Software Testing Background 1. Software is a set of instructions to perform some task. 2. Software is used in many applications of the real world. 3. Some of the examples are Application software, such as word processors, firmware in an embedded system, middleware, which controls and co-ordinates distributed systems, system software such as operating systems, video games, and websites. 4. All of these applications need to run without any error and provide a quality service to the user of the application. 5. The software has to be tested for its accurate and correct working. Software Testing: Testing can be defined in simple words as “Performing Verification and Validation of the Software Product” for its correctness and accuracy of working. -

Managing Defects in an Agile Environment
Managing Defects in an Agile environment Auteur Ron Eringa Managing Defects in an Agile environment Introduction Injecting passion, Agility Teams often struggle with answering the following and quality into your question: “How to manage our Defects in an organisation. Agile environment?”. They start using Scrum as a framework for developing their software and while implementing, they experience trouble on how to deal with the Defects they find/cause along the way. Scrum is a framework that does not explicitly tell you how to handle Defects. The strait forward answer is to treat your Defects as Product Backlog Items that should be added to the Product Backlog. When the priority is set high enough by the Product Owner, they will be picked up by the Development Team in the next Sprint. The application of this is a little bit more difficult and hence should be explained in more detail. RON ERINGA 1. What is a defect? AGILE COACH Wikipedia: “A software bug (or defect) is an error, flaw, After being graduated from the Fontys failure, or fault in a computer program or system that University in Eindhoven, I worked as a Software produces an incorrect or unexpected result, or causes Engineer/Designer for ten years. Although I it to behave in unintended ways. Most bugs arise have always enjoyed technics, helping people from mistakes and errors made by people in either a and organizations are my passion. Especially program’s source code or its design, or in frameworks to deliver better quality together. When people and operating systems used by such programs, and focus towards a common goal, interaction is a few are caused by compilers producing incorrect increasing and energy is released. -

A Study of Static Bug Detectors
How Many of All Bugs Do We Find? A Study of Static Bug Detectors Andrew Habib Michael Pradel [email protected] [email protected] Department of Computer Science Department of Computer Science TU Darmstadt TU Darmstadt Germany Germany ABSTRACT International Conference on Automated Software Engineering (ASE ’18), Sep- Static bug detectors are becoming increasingly popular and are tember 3–7, 2018, Montpellier, France. ACM, New York, NY, USA, 12 pages. widely used by professional software developers. While most work https://doi.org/10.1145/3238147.3238213 on bug detectors focuses on whether they find bugs at all, and on how many false positives they report in addition to legitimate 1 INTRODUCTION warnings, the inverse question is often neglected: How many of all Finding software bugs is an important but difficult task. For average real-world bugs do static bug detectors find? This paper addresses industry code, the number of bugs per 1,000 lines of code has been this question by studying the results of applying three widely used estimated to range between 0.5 and 25 [21]. Even after years of static bug detectors to an extended version of the Defects4J dataset deployment, software still contains unnoticed bugs. For example, that consists of 15 Java projects with 594 known bugs. To decide studies of the Linux kernel show that the average bug remains in which of these bugs the tools detect, we use a novel methodology the kernel for a surprisingly long period of 1.5 to 1.8 years [8, 24]. that combines an automatic analysis of warnings and bugs with a Unfortunately, a single bug can cause serious harm, even if it has manual validation of each candidate of a detected bug. -

Bug Detection, Debugging, and Isolation Middlebox for Software-Defined Network Controllers
BuDDI: Bug Detection, Debugging, and Isolation Middlebox for Software-Defined Network Controllers Rohit Abhishek1, Shuai Zhao1, Sejun Song1, Baek-Young Choi1, Henry Zhu2, Deep Medhi1 1University of Missouri-Kansas City, 2Cisco Systems frabhishek, shuai.zhao, songsej, choiby, dmedhi)@umkc.edu, [email protected] Abstract—Despite tremendous software quality assurance ef- forts made by network vendors, chastising software bugs is a difficult problem especially, for the network systems in operation. Recent trends towards softwarization and opensourcing of net- work functions, protocols, controls, and applications tend to cause more software bug problems and pose many critical challenges to handle them. Although many traditional redundancy recovery mechanisms are adopted to the softwarized systems, software bugs cannot be resolved with them due to unexpected failure behavior. Furthermore, they are often bounded by common mode failure and common dependencies (CMFD). In this paper, we propose an online software bug detection, debugging, and iso- lation (BuDDI) middlebox architecture for software-defined net- work controllers. The BuDDI architecture consists of a shadow- controller based online debugging facility and a CMFD mitigation module in support of a seamless heterogeneous controller failover. Our proof-of-concept implementation of BuDDI is on the top of OpenVirtex by using Ryu and Pox controllers and verifies that the heterogeneous controller switchover does not cause any Fig. 1. BuDDI N + 2 Reliability additional performance overhead. I. INTRODUCTION mechanisms alone as software bugs can cause unexpected root Software faults in the operating network systems can cause cause failures, baffle failure detections, and hinder recovery not only critical system failures [5] but also various unexpected mechanisms. -

Software Development a Practical Approach!
Software Development A Practical Approach! Hans-Petter Halvorsen https://www.halvorsen.blog https://halvorsen.blog Software Development A Practical Approach! Hans-Petter Halvorsen Software Development A Practical Approach! Hans-Petter Halvorsen Copyright © 2020 ISBN: 978-82-691106-0-9 Publisher Identifier: 978-82-691106 https://halvorsen.blog ii Preface The main goal with this document: • To give you an overview of what software engineering is • To take you beyond programming to engineering software What is Software Development? It is a complex process to develop modern and professional software today. This document tries to give a brief overview of Software Development. This document tries to focus on a practical approach regarding Software Development. So why do we need System Engineering? Here are some key factors: • Understand Customer Requirements o What does the customer needs (because they may not know it!) o Transform Customer requirements into working software • Planning o How do we reach our goals? o Will we finish within deadline? o Resources o What can go wrong? • Implementation o What kind of platforms and architecture should be used? o Split your work into manageable pieces iii • Quality and Performance o Make sure the software fulfills the customers’ needs We will learn how to build good (i.e. high quality) software, which includes: • Requirements Specification • Technical Design • Good User Experience (UX) • Improved Code Quality and Implementation • Testing • System Documentation • User Documentation • etc. You will find additional resources on this web page: http://www.halvorsen.blog/documents/programming/software_engineering/ iv Information about the author: Hans-Petter Halvorsen The author currently works at the University of South-Eastern Norway. -

A Survey on Bug-Report Analysis.Scichinainfsci,2015,58: 021101(24), Doi: 10.1007/S11432-014-5241-2
SCIENCE CHINA Information Sciences . REVIEW . February 2015, Vol. 58 021101:1–021101:24 doi: 10.1007/s11432-014-5241-2 Asurveyonbug-reportanalysis ZHANG Jie1 , WANG XiaoYin2 ,HAODan1*, XIE Bing1,ZHANGLu1 * &MEIHong1 1Key Laboratory of High Confidence Software Technologies (Peking University), Ministry of Education, Beijing 100871,China; 2Department of Computer Science, University of Texas at San Antonio, San Antonio, USA Received April 10, 2014; accepted September 12, 2014 Abstract Bug reports are essential software artifacts that describe software bugs, especially in open-source software. Lately, due to the availability of a large number ofbugreports,aconsiderableamountofresearchhas been carried out on bug-report analysis, such as automatically checking duplication of bug reports and localizing bugs based on bug reports. To review the work on bug-report analysis, this paper presents an exhaustive survey on the existing work on bug-report analysis. In particular, this paper first presents some background for bug reports and gives a small empirical study on the bug reports onBugzillatomotivatethenecessityforworkon bug-report analysis. Then this paper summaries the existingworkonbug-reportanalysisandpointsoutsome possible problems in working with bug-report analysis. Keywords survey, bug report, bug-report analysis, bug-report triage, bug localization, bug fixing Citation Zhang J, Wang X Y, Hao D, et al. A survey on bug-report analysis.SciChinaInfSci,2015,58: 021101(24), doi: 10.1007/s11432-014-5241-2 1Introduction As programmers can hardly write programs without any bugs, it is inevitable to find bugs and fix bugs in software development. Moreover, it is costly and time-consuming to find and fix bugs in software development. Software testing and debugging is estimated to consume more than one third of the total cost of software development [1,2]. -

SICX1020 THEORY of ROBOTICS and AUTOMATION (Common to EIE, E&C, ECE, ETCE, EEE & BIOMED)
SICX1020 THEORY OF ROBOTICS AND AUTOMATION (Common to EIE, E&C, ECE, ETCE, EEE & BIOMED) UNIT I BASIC CONCEPTS: History of Robot (Origin): 1968 Shakev, first mobile robot with vision capacity made at SRI. 1970 The Stanford Arm designed eith electrical actuators and controlled by a computer 1973 Cincinnati Milacron‘s (T3) electrically actuated mini computer controlled by industrial robot. 1976 Viking II lands on Mars and an arm scoops Martian soil for analysis. 1978 Unimation Inc. develops the PUMA robot- even now seen in university labs 1981 Robot Manipulators by R. Paul, one of the first textbooks on robotics. 1982 First educational robots by Microbot and Rhino. 1983 Adept Technology, maker of SCARA robot, started. 1995 Intuitive Surgical formed to design and market surgical robots. 1997 Sojourner robot sends back pictures of Mars; the Honda P3 humanoid robot, started in unveiled 2000 Honda demonstrates Asimo humanoid robot capable of walking. 2001 Sony releases second generation Aibo robot dog. 2004 Spirit and Opportunity explore Mars surface and detect evidence of past existence of water. 2007 Humanoid robot Aiko capable of ―feeling‖ pain. 2009 Micro-robots and emerging field of nano-robots marrying biology with engineering. An advance in robotics has closely followed the explosive development of computers and electronics. Initial robot usage was primarily in industrial application such as part/material handling, welding and painting and few in handling of hazardous material. Most initial robots operated in teach-playback mode, and replaced ‗repetitive‘ and ‗back-breaking‘ tasks. Growth and usage of robots slowed significantly in late 1980‘s and early 1990‘s due to ―lack of intelligence‖ and ―ability to adapt‖ to changing environment – Robots were essentially blind, deaf and dumb!.Last 15 years or so, sophisticated sensors and programming allow robots to act much more intelligently, autonomously and react to changes in environments faster. -

Issues, Challenges and Best Practices of Software Testing Activity
Issues, Challenges and Best Practices of Software Testing Activity ZULKEFLI MANSOR Research Center for Software Technology and Management Faculty of Information Science and Technology Universiti Kebangsaan Malaysia 43000 Bangi, Selangor Darul Ehsan MALAYSIA [email protected] http://www.ftsm.ukm.my/kefflee ENEBELI E.NDUDI Faculty of Computer Science and Information Technology Universiti Selangor Jln Timur Tambahan, 45700 Bestari Jaya, Selangor Darul Ehsan MALAYSIA [email protected] Abstract: - Software testing activity is a huge challenge in software development project today due to end user needs. The end users need the project to be completed in short time with zero defect and high quality of product. Therefore, the testing activity should be started as earlier as possible because it will helps in fixing enormous errors in early stages of software development and reduces the rework of tracking bugs in the later stages. In addition, a clear understanding on the objective of testing and the planning on how, where, and what the system should be tested for is also challenges to the testing team. These issue makes software testing time consuming process coupled with various challenges erupting from inability of software testers to perform their task effectively. Hence, this paper investigated the issues, challenges and best practices of software testing activity. The document analysis was carried out in order to analyze the information. The findings reveals that 9 main issues and challenges in software testing activities. 9 best practices also discover from the survey. The findings will help software community especially testing team to aware the issues and challenges could be faced and how to perform testing activities in best way. -
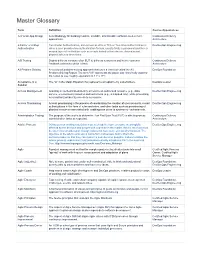
Master Glossary
Master Glossary Term Definition Course Appearances 12-Factor App Design A methodology for building modern, scalable, maintainable software-as-a-service Continuous Delivery applications. Architecture 2-Factor or 2-Step Two-Factor Authentication, also known as 2FA or TFA or Two-Step Authentication is DevSecOps Engineering Authentication when a user provides two authentication factors; usually firstly a password and then a second layer of verification such as a code texted to their device, shared secret, physical token or biometrics. A/B Testing Deploy different versions of an EUT to different customers and let the customer Continuous Delivery feedback determine which is best. Architecture A3 Problem Solving A structured problem-solving approach that uses a lean tool called the A3 DevOps Foundation Problem-Solving Report. The term "A3" represents the paper size historically used for the report (a size roughly equivalent to 11" x 17"). Acceptance of a The "A" in the Magic Equation that represents acceptance by stakeholders. DevOps Leader Solution Access Management Granting an authenticated identity access to an authorized resource (e.g., data, DevSecOps Engineering service, environment) based on defined criteria (e.g., a mapped role), while preventing an unauthorized identity access to a resource. Access Provisioning Access provisioning is the process of coordinating the creation of user accounts, e-mail DevSecOps Engineering authorizations in the form of rules and roles, and other tasks such as provisioning of physical resources associated with enabling new users to systems or environments. Administration Testing The purpose of the test is to determine if an End User Test (EUT) is able to process Continuous Delivery administration tasks as expected. -

Beginners Guide to Software Testing
Beginners Guide To Software Testing Beginners Guide To Software Testing - Padmini C Page 1 Beginners Guide To Software Testing Table of Contents: 1. Overview ........................................................................................................ 5 The Big Picture ............................................................................................... 5 What is software? Why should it be tested? ................................................. 6 What is Quality? How important is it? ........................................................... 6 What exactly does a software tester do? ...................................................... 7 What makes a good tester? ........................................................................... 8 Guidelines for new testers ............................................................................. 9 2. Introduction .................................................................................................. 11 Software Life Cycle ....................................................................................... 11 Various Life Cycle Models ............................................................................ 12 Software Testing Life Cycle .......................................................................... 13 What is a bug? Why do bugs occur? ............................................................ 15 Bug Life Cycle ............................................................................................... 16 Cost of fixing bugs ....................................................................................... -

Identifying Software and Protocol Vulnerabilities in WPA2 Implementations Through Fuzzing
POLITECNICO DI TORINO Master Degree in Computer Engineering Master Thesis Identifying Software and Protocol Vulnerabilities in WPA2 Implementations through Fuzzing Supervisors Prof. Antonio Lioy Dr. Jan Tobias M¨uehlberg Dr. Mathy Vanhoef Candidate Graziano Marallo Academic Year 2018-2019 Dedicated to my parents Summary Nowadays many activities of our daily lives are essentially based on the Internet. Information and services are available at every moment and they are just a click away. Wireless connections, in fact, have made these kinds of activities faster and easier. Nevertheless, security remains a problem to be addressed. If it is compro- mised, you can face severe consequences. When connecting to a protected Wi-Fi network a handshake is executed that provides both mutual authentication and ses- sion key negotiation. A recent discovery proves that this handshake is vulnerable to key reinstallation attacks. In response, vendors patched their implementations to prevent key reinstallations (KRACKs). However, these patches are non-trivial, and hard to get correct. Therefore it is essential that someone audits these patches to assure that key reinstallation attacks are indeed prevented. More precisely, the state machine behind the handshake can be fairly complex. On top of that, some implementations contain extra code to deal with Access Points that do not properly follow the 802.11 standard. This further complicates an implementation of the handshake. All combined, this makes it difficult to reason about the correctness of a patch. This means some patches may be flawed in practice. There are several possible techniques that can be used to accomplish this kind of analysis such as: formal verification, fuzzing, code audits, etc. -

The Software Testing Techniques
INTERNATIONAL JOURNAL OF RESEARCH ISSN NO : 2236-6124 THE SOFTWARE TESTING TECHNIQUES Bomma RamaKrishna1,A.Abbash2 1 Assistant Professor,A.K.R.G College of Engineering and Technology,Nallajerla,A.P [email protected] 2 Professor, Aaligarh Muslim University,CSEDepartment [email protected] ABSTRACT Testing is defined as a process of evaluation that either the specific system meets its Software testing is an investigation originally specified requirements or not. It is conducted to provide stakeholders with mainly a process encompassing validation information about the quality of and verification process that whether the the software product or service under test. developed system meets the requirements Software testing can also provide an defined by user. Therefore, this activity objective, independent view of the software results in a difference between actual and to allow the business to appreciate and expected result. Software Testing refers to understand the risks of software finding bugs, errors or missing requirements implementation. Test techniques include the in the developed system or software. So, this process of executing a program or is an investigation that provides the application with the intent of stakeholders with the exact knowledge about finding software bugs (errors or other the quality of the product. defects), and verifying that the software Software Testing can also be considered as a product is fit for use. Software testing risk-based activity. The important thing involves the execution of a software during testing process the software testers component or system component to evaluate must understand that how to minimize a one or more properties of interest. This large number of tests into manageable tests paper aims to discuss the existing as well as set, and make wise decisions about the risks improved testing techniques for the better that are important to test or what are not [1].