Genome-Wide Association Studies Identifying Functionally Related Genes and Intragenic Regions in Small Sample Studies Knut M
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Chr21 Protein-Protein Interactions: Enrichment in Products Involved in Intellectual Disabilities, Autism and Late Onset Alzheimer Disease
bioRxiv preprint doi: https://doi.org/10.1101/2019.12.11.872606; this version posted December 12, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Chr21 protein-protein interactions: enrichment in products involved in intellectual disabilities, autism and Late Onset Alzheimer Disease Julia Viard1,2*, Yann Loe-Mie1*, Rachel Daudin1, Malik Khelfaoui1, Christine Plancon2, Anne Boland2, Francisco Tejedor3, Richard L. Huganir4, Eunjoon Kim5, Makoto Kinoshita6, Guofa Liu7, Volker Haucke8, Thomas Moncion9, Eugene Yu10, Valérie Hindie9, Henri Bléhaut11, Clotilde Mircher12, Yann Herault13,14,15,16,17, Jean-François Deleuze2, Jean- Christophe Rain9, Michel Simonneau1, 18, 19, 20** and Aude-Marie Lepagnol- Bestel1** 1 Centre Psychiatrie & Neurosciences, INSERM U894, 75014 Paris, France 2 Laboratoire de génomique fonctionnelle, CNG, CEA, Evry 3 Instituto de Neurociencias CSIC-UMH, Universidad Miguel Hernandez-Campus de San Juan 03550 San Juan (Alicante), Spain 4 Department of Neuroscience, The Johns Hopkins University School of Medicine, Baltimore, MD 21205 USA 5 Center for Synaptic Brain Dysfunctions, Institute for Basic Science, Daejeon 34141, Republic of Korea 6 Department of Molecular Biology, Division of Biological Science, Nagoya University Graduate School of Science, Furo, Chikusa, Nagoya, Japan 7 Department of Biological Sciences, University of Toledo, Toledo, OH, 43606, USA 8 Leibniz Forschungsinstitut für Molekulare Pharmakologie -

Neural Stem Cell-Derived Exosomes Revert HFD-Dependent Memory Impairment Via CREB-BDNF Signalling
International Journal of Molecular Sciences Article Neural Stem Cell-Derived Exosomes Revert HFD-Dependent Memory Impairment via CREB-BDNF Signalling Matteo Spinelli 1, Francesca Natale 1,2, Marco Rinaudo 1, Lucia Leone 1,2, Daniele Mezzogori 1, Salvatore Fusco 1,2,* and Claudio Grassi 1,2 1 Department of Neuroscience, Università Cattolica del Sacro Cuore, 00168 Rome, Italy; [email protected] (M.S.); [email protected] (F.N.); [email protected] (M.R.); [email protected] (L.L.); [email protected] (D.M.); [email protected] (C.G.) 2 Fondazione Policlinico Universitario Agostino Gemelli IRCCS, 00168 Rome, Italy * Correspondence: [email protected] Received: 6 October 2020; Accepted: 25 November 2020; Published: 26 November 2020 Abstract: Overnutrition and metabolic disorders impair cognitive functions through molecular mechanisms still poorly understood. In mice fed with a high fat diet (HFD) we analysed the expression of synaptic plasticity-related genes and the activation of cAMP response element-binding protein (CREB)-brain-derived neurotrophic factor (BDNF)-tropomyosin receptor kinase B (TrkB) signalling. We found that a HFD inhibited both CREB phosphorylation and the expression of a set of CREB target genes in the hippocampus. The intranasal administration of neural stem cell (NSC)-derived exosomes (exo-NSC) epigenetically restored the transcription of Bdnf, nNOS, Sirt1, Egr3, and RelA genes by inducing the recruitment of CREB on their regulatory sequences. Finally, exo-NSC administration rescued both BDNF signalling and memory in HFD mice. Collectively, our findings highlight novel mechanisms underlying HFD-related memory impairment and provide evidence of the potential therapeutic effect of exo-NSC against metabolic disease-related cognitive decline. -

Analysis of BMP4 and BMP7 Signaling in Breast Cancer Cells Unveils Time
Rodriguez-Martinez et al. BMC Medical Genomics 2011, 4:80 http://www.biomedcentral.com/1755-8794/4/80 RESEARCHARTICLE Open Access Analysis of BMP4 and BMP7 signaling in breast cancer cells unveils time-dependent transcription patterns and highlights a common synexpression group of genes Alejandra Rodriguez-Martinez1†, Emma-Leena Alarmo1†, Lilli Saarinen2, Johanna Ketolainen1, Kari Nousiainen2, Sampsa Hautaniemi2 and Anne Kallioniemi1* Abstract Background: Bone morphogenetic proteins (BMPs) are members of the TGF-beta superfamily of growth factors. They are known for their roles in regulation of osteogenesis and developmental processes and, in recent years, evidence has accumulated of their crucial functions in tumor biology. BMP4 and BMP7, in particular, have been implicated in breast cancer. However, little is known about BMP target genes in the context of tumor. We explored the effects of BMP4 and BMP7 treatment on global gene transcription in seven breast cancer cell lines during a 6- point time series, using a whole-genome oligo microarray. Data analysis included hierarchical clustering of differentially expressed genes, gene ontology enrichment analyses and model based clustering of temporal data. Results: Both ligands had a strong effect on gene expression, although the response to BMP4 treatment was more pronounced. The cellular functions most strongly affected by BMP signaling were regulation of transcription and development. The observed transcriptional response, as well as its functional outcome, followed a temporal sequence, with regulation of gene expression and signal transduction leading to changes in metabolism and cell proliferation. Hierarchical clustering revealed distinct differences in the response of individual cell lines to BMPs, but also highlighted a synexpression group of genes for both ligands. -

Epidermal Growth Factor Receptor (EGFR) Mutation Analysis, Gene
Peraldo-Neia et al. BMC Cancer 2011, 11:31 http://www.biomedcentral.com/1471-2407/11/31 RESEARCHARTICLE Open Access Epidermal Growth Factor Receptor (EGFR) mutation analysis, gene expression profiling and EGFR protein expression in primary prostate cancer Caterina Peraldo-Neia1,2*, Giorgia Migliardi1, Maurizia Mello-Grand2, Filippo Montemurro3, Raffaella Segir2, Ymera Pignochino1, Giuliana Cavalloni1, Bruno Torchio4, Luciano Mosso4, Giovanna Chiorino2, Massimo Aglietta1,3 Abstract Background: Activating mutations of the epidermal growth factor receptor (EGFR) confer sensitivity to the tyrosine kinase inhibitors (TKi), gefitinib and erlotinib. We analysed EGFR expression, EGFR mutation status and gene expression profiles of prostate cancer (PC) to supply a rationale for EGFR targeted therapies in this disease. Methods: Mutational analysis of EGFR TK domain (exons from 18 to 21) and immunohistochemistry for EGFR were performed on tumour tissues derived from radical prostatectomy from 100 PC patients. Gene expression profiling using oligo-microarrays was also carried out in 51 of the PC samples. Results: EGFR protein overexpression (EGFRhigh) was found in 36% of the tumour samples, and mutations were found in 13% of samples. Patients with EGFRhigh tumours experienced a significantly increased risk of biochemical relapse (hazard ratio-HR 2.52, p=0.02) compared with patients with tumours expressing low levels of EGFR (EGFRlow). Microarray analysis did not reveal any differences in gene expression between EGFRhigh and EGFRlow tumours. Conversely, in EGFRhigh tumours, we were able to identify a 79 gene signature distinguishing mutated from non-mutated tumours. Additionally, 29 genes were found to be differentially expressed between mutated/ EGFRhigh (n=3) and mutated/EGFRlow tumours (n=5). -

BDNF Integrity in Ageing and Stress
MOJ Gerontology & Geriatrics Editorial Open Access BDNF integrity in ageing and stress Editorial Volume 1 Issue 6 - 2017 Alzheimer’s disease (AD) presents a progressive, stage-dependent Trevor Archer age-related neurodegenerative disorder that is characterized by Department of Psychology, University of Gothenburg, Sweden aggregation of toxic forms of amyloid β peptide (Aβ). There is much support for the notion that that brain-derived neurotrophic factor Correspondence: Trevor Archer, Department of Psychology, (BDNF) mediates beneficial effects of exercise on neuroplasticity and University of Gothenburg, Sweden, cellular stress resistance.1‒3 BDNF is associated with neuroplasticity Email [email protected] changes promoting health and well-being whereas these influences Received: July 16, 2017 | Published: August 01, 2017 may be opposed by pro-inflammatory cytokines, key factors in neurodegenerative processes.4 Lower serum levels are linked to greater symptom, cognitive, impairment.5 Thus, interventions, as for example physical exercise, whether acute or chronic, endurance or resistance, promote the mobilization of BDNF and other neurotrophic factors6,7 increase hippocampal and other brain regional resilience8 and therewith progression under conditions of stress when confronted critical life protect against cell death by inducing cell proliferation and maturation episodes or periods, appears to be modulated by the availability and with enhanced neuronal reparation, neurogenesis and the growth and accessibility of BDNF.20‒22 Over a wide range of neurologic and functioning of neurons in neurodegenerative disorders.9,10 Sampaio et psychiatric disease states it is found that the integrity and concentrations al.11 in a review of the therapeutic applications of neurotrophic factors, of brain, serum and plasma BDNF is compromised, particularly under particularly BDNF, postulate that they are essential for survival, stressful conditions. -

Supplementary Table S4. FGA Co-Expressed Gene List in LUAD
Supplementary Table S4. FGA co-expressed gene list in LUAD tumors Symbol R Locus Description FGG 0.919 4q28 fibrinogen gamma chain FGL1 0.635 8p22 fibrinogen-like 1 SLC7A2 0.536 8p22 solute carrier family 7 (cationic amino acid transporter, y+ system), member 2 DUSP4 0.521 8p12-p11 dual specificity phosphatase 4 HAL 0.51 12q22-q24.1histidine ammonia-lyase PDE4D 0.499 5q12 phosphodiesterase 4D, cAMP-specific FURIN 0.497 15q26.1 furin (paired basic amino acid cleaving enzyme) CPS1 0.49 2q35 carbamoyl-phosphate synthase 1, mitochondrial TESC 0.478 12q24.22 tescalcin INHA 0.465 2q35 inhibin, alpha S100P 0.461 4p16 S100 calcium binding protein P VPS37A 0.447 8p22 vacuolar protein sorting 37 homolog A (S. cerevisiae) SLC16A14 0.447 2q36.3 solute carrier family 16, member 14 PPARGC1A 0.443 4p15.1 peroxisome proliferator-activated receptor gamma, coactivator 1 alpha SIK1 0.435 21q22.3 salt-inducible kinase 1 IRS2 0.434 13q34 insulin receptor substrate 2 RND1 0.433 12q12 Rho family GTPase 1 HGD 0.433 3q13.33 homogentisate 1,2-dioxygenase PTP4A1 0.432 6q12 protein tyrosine phosphatase type IVA, member 1 C8orf4 0.428 8p11.2 chromosome 8 open reading frame 4 DDC 0.427 7p12.2 dopa decarboxylase (aromatic L-amino acid decarboxylase) TACC2 0.427 10q26 transforming, acidic coiled-coil containing protein 2 MUC13 0.422 3q21.2 mucin 13, cell surface associated C5 0.412 9q33-q34 complement component 5 NR4A2 0.412 2q22-q23 nuclear receptor subfamily 4, group A, member 2 EYS 0.411 6q12 eyes shut homolog (Drosophila) GPX2 0.406 14q24.1 glutathione peroxidase -

Epithelial-To-Mesenchymal Transition Enhances Cancer Cell Sensitivity to Cytotoxic Effects of Cold Atmospheric Plasmas in Breast and Bladder Cancer Systems
cancers Article Epithelial-to-Mesenchymal Transition Enhances Cancer Cell Sensitivity to Cytotoxic Effects of Cold Atmospheric Plasmas in Breast and Bladder Cancer Systems Peiyu Wang 2,3 , Renwu Zhou 4 , Patrick Thomas 2,3,5 , Liqian Zhao 6, Rusen Zhou 4, Susmita Mandal 7, Mohit Kumar Jolly 7, Derek J. Richard 2,3, Bernd H. A. Rehm 8, Kostya (Ken) Ostrikov 9, Xiaofeng Dai 1,*, Elizabeth D. Williams 2,3,4 and Erik W. Thompson 2,3 1 Wuxi School of Medicine, Jiangnan University, Wuxi 214122, China 2 Queensland University of Technology (QUT), School of Biomedical Sciences, Brisbane 4059, Australia 3 Translational Research Institute, Woolloongabba 4102, Australia 4 School of Chemical and Biomolecular Engineering, The University of Sydney, Sydney 2006, Australia 5 Queensland Bladder Cancer Initiative (QBCI), Woolloongabba 4102, Australia 6 The First School of Clinical Medicine, Southern Medical University, Guangzhou 510515, China 7 Centre for BioSystems Science and Engineering, Indian Institute of Science, Bangalore 560012, India 8 Centre for Cell Factories and Biopolymers, Griffith Institute for Drug Discovery, Griffith University, Nathan 4111, Australia 9 School of Chemistry and Physics, Queensland University of Technology, Brisbane 4000, Australia; Citation: Wang, P.; Zhou, R.; * Correspondence: [email protected] Thomas, P.; Zhao, L.; Zhou, R.; Mandal, S.; Jolly, M.K.; Richard, D.J.; Simple Summary: Cold atmospheric plasma (CAP) and plasma-activated medium (PAM) are known Rehm, B.H.A.; Ostrikov, K.; et al. to selectively kill cancer cells, however the efficacy of CAP in cancer cells following epithelial- Epithelial-to-Mesenchymal Transition mesenchymal transition (EMT), a process which endows cancer cells with increased stemness, Enhances Cancer Cell Sensitivity to metastatic potential, and resistance to conventional therapies, has not been previously examined. -

Alzheimer's Disease
VU Research Portal Spot the difference Bossers, C.A.M. 2009 document version Publisher's PDF, also known as Version of record Link to publication in VU Research Portal citation for published version (APA) Bossers, C. A. M. (2009). Spot the difference: microarray analysis of gene expression changes in Alzheimer's and Parkinson's Disease. General rights Copyright and moral rights for the publications made accessible in the public portal are retained by the authors and/or other copyright owners and it is a condition of accessing publications that users recognise and abide by the legal requirements associated with these rights. • Users may download and print one copy of any publication from the public portal for the purpose of private study or research. • You may not further distribute the material or use it for any profit-making activity or commercial gain • You may freely distribute the URL identifying the publication in the public portal ? Take down policy If you believe that this document breaches copyright please contact us providing details, and we will remove access to the work immediately and investigate your claim. E-mail address: [email protected] Download date: 11. Oct. 2021 Spot the difference: microarray analysis of gene expression changes in Alzheimer’s and Parkinson’s Disease The research described in this thesis was conducted at the Netherlands Institute for Neuroscience, an Institute of the Royal Netherlands Academy of Arts and Sci- ences, Amsterdam, The Netherlands. The research was financially supported by a collaboration between the Netherlands Institute for Neuroscience and Solvay Phar- maceuticals. Leescommissie: dr. -
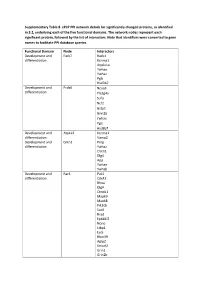
Supplementary Table 8. Cpcp PPI Network Details for Significantly Changed Proteins, As Identified in 3.2, Underlying Each of the Five Functional Domains
Supplementary Table 8. cPCP PPI network details for significantly changed proteins, as identified in 3.2, underlying each of the five functional domains. The network nodes represent each significant protein, followed by the list of interactors. Note that identifiers were converted to gene names to facilitate PPI database queries. Functional Domain Node Interactors Development and Park7 Rack1 differentiation Kcnma1 Atp6v1a Ywhae Ywhaz Pgls Hsd3b7 Development and Prdx6 Ncoa3 differentiation Pla2g4a Sufu Ncf2 Gstp1 Grin2b Ywhae Pgls Hsd3b7 Development and Atp1a2 Kcnma1 differentiation Vamp2 Development and Cntn1 Prnp differentiation Ywhaz Clstn1 Dlg4 App Ywhae Ywhab Development and Rac1 Pak1 differentiation Cdc42 Rhoa Dlg4 Ctnnb1 Mapk9 Mapk8 Pik3cb Sod1 Rrad Epb41l2 Nono Ltbp1 Evi5 Rbm39 Aplp2 Smurf2 Grin1 Grin2b Xiap Chn2 Cav1 Cybb Pgls Ywhae Development and Hbb-b1 Atp5b differentiation Hba Kcnma1 Got1 Aldoa Ywhaz Pgls Hsd3b4 Hsd3b7 Ywhae Development and Myh6 Mybpc3 differentiation Prkce Ywhae Development and Amph Capn2 differentiation Ap2a2 Dnm1 Dnm3 Dnm2 Atp6v1a Ywhab Development and Dnm3 Bin1 differentiation Amph Pacsin1 Grb2 Ywhae Bsn Development and Eef2 Ywhaz differentiation Rpgrip1l Atp6v1a Nphp1 Iqcb1 Ezh2 Ywhae Ywhab Pgls Hsd3b7 Hsd3b4 Development and Gnai1 Dlg4 differentiation Development and Gnao1 Dlg4 differentiation Vamp2 App Ywhae Ywhab Development and Psmd3 Rpgrip1l differentiation Psmd4 Hmga2 Development and Thy1 Syp differentiation Atp6v1a App Ywhae Ywhaz Ywhab Hsd3b7 Hsd3b4 Development and Tubb2a Ywhaz differentiation Nphp4 -

Invasive Bladder Cancer: Genomic Insights and Therapeutic Promise Jaegil Kim1, Rehan Akbani2, Chad J
Review Clinical Cancer Research Invasive Bladder Cancer: Genomic Insights and Therapeutic Promise Jaegil Kim1, Rehan Akbani2, Chad J. Creighton3, Seth P. Lerner3, John N. Weinstein2, Gad Getz1,4, and David J. Kwiatkowski1,5 Abstract Invasive bladder cancer, for which there have been few thera- unusually frequent in comparison with other cancers, and muta- peutic advances in the past 20 years, is a significant medical tion or amplification of transcription factors is also common. problem associated with metastatic disease and frequent mortal- Expression clustering analyses organize bladder cancers into four ity. Although previous studies had identified many genetic altera- principal groups, which can be characterized as luminal, immune tions in invasive bladder cancer, recent genome-wide studies have undifferentiated, luminal immune, and basal. The four groups provided a more comprehensive view. Here, we review those show markedly different expression patterns for urothelial differ- recent findings and suggest therapeutic strategies. Bladder cancer entiation (keratins and uroplakins) and immunity genes (CD274 has a high mutation rate, exceeded only by lung cancer and and CTLA4), among others. These observations suggest numerous melanoma. About 65% of all mutations are due to APOBEC- therapeutic opportunities, including kinase inhibitors and anti- mediated mutagenesis. There is a high frequency of mutations body therapies for genes in the canonical signaling pathways, and/or genomic amplification or deletion events that affect many histone deacetylase inhibitors and novel molecules for chromatin of the canonical signaling pathways involved in cancer develop- gene mutations, and immune therapies, which should be targeted ment: cell cycle, receptor tyrosine kinase, RAS, and PI-3-kinase/ to specific patients based on genomic profiling of their cancers. -

State-Dependent Calcium Signaling in Dendritic Spines of Striatal Medium Spiny Neurons
Neuron, Vol. 44, 483–493, October 28, 2004, Copyright 2004 by Cell Press State-Dependent Calcium Signaling in Dendritic Spines of Striatal Medium Spiny Neurons Adam G. Carter and Bernardo L. Sabatini* low- and high-threshold voltage-sensitive calcium (Ca) Department of Neurobiology channels (VSCCs), and ionotropic glutamate receptors. Harvard Medical School Multiple neuronal processes in MSNs are regulated by 220 Longwood Avenue Ca influx, including synaptic strength (Calabresi et al., Boston, Massachusetts 02115 1992; Partridge et al., 2000) and gene expression (Kon- radi et al., 1996; Liu and Graybiel, 1996; Rajadhyaksha et al., 1999). MSNs may possess routes for Ca entry not Summary found in other principal neurons, including Ca-perme- able AMPA receptors (AMPARs) (Bernard et al., 1997; Striatal medium spiny neurons (MSNs) in vivo undergo Chen et al., 1998; Stefani et al., 1998). Moreover, Ca large membrane depolarizations known as state tran- sources may be preferentially activated in the two states, sitions. Calcium (Ca) entry into MSNs triggers diverse such as T-type VSCCs capable of activating at relatively downstream cellular processes. However, little is hyperpolarized potentials (McRory et al., 2001). How- known about Ca signals in MSN dendrites and spines ever, little is known about subcellular Ca signals in MSNs and how state transitions influence these signals. and how they are influenced by state transitions. Here, we develop a novel approach, combining 2-pho- In cultured MSNs, upstate transitions are triggered by ton Ca imaging and 2-photon glutamate uncaging, to spontaneous synaptic inputs and can generate dendritic examine how voltage-sensitive Ca channels (VSCCs) Ca signals (Kerr and Plenz, 2002) that are enhanced by and ionotropic glutamate receptors contribute to Ca back-propagating APs (bAPs) (Kerr and Plenz, 2004). -

571810V1.Full.Pdf
bioRxiv preprint doi: https://doi.org/10.1101/571810; this version posted March 8, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. TITLE PAGE Title: Alternative Titles: β-Catenin tumour-suppressor activity depends on its ability to promote Pro-N-Cadherin maturation Authors: Antonio Herrera, Anghara Menendez, Blanca Torroba and Sebastian Pons* Affiliation: Instituto de Biología Molecular de Barcelona (CSIC), Parc Científic de Barcelona, Baldiri Reixac 10-12, Barcelona 08028, Spain. Tlf: 34-934031103 Present Affiliation for Blanca Torroba: Department of Physiology, Anatomy and Genetics, University of Oxford, Le Gros Clark Building, South Parks Rd, Oxford OX1 3QX (UK). Correspondence author: Sebastian Pons, Instituto de Biología Molecular de Barcelona, (CSIC), Parc Científic de Barcelona, Baldiri Reixac 10-12, Barcelona 08028, Spain. [email protected] Running Title: β-Catenin promotes N-Cadherin maturation Keywords: Pro-N-Cadherin, β-Catenin, Medulloblastoma, Neuroepithelium, Apico-basal polarity, Adherens Junctions. 1 bioRxiv preprint doi: https://doi.org/10.1101/571810; this version posted March 8, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. SUMMARY Neural stem cells (NSCs) form a pseudostratified, single-cell layered epithelium with a marked apico-basal polarity. In these cells, β-Catenin associates with classic cadherins in order to form the apical adherens junctions (AJs). We previously reported that oncogenic forms of β-Catenin (sβ-Catenin) maintain neural precursors as progenitors, while also enhancing their polarization and adhesiveness, thereby limiting their malignant potential.