What Is ANTLR?
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Derivatives of Parsing Expression Grammars
Derivatives of Parsing Expression Grammars Aaron Moss Cheriton School of Computer Science University of Waterloo Waterloo, Ontario, Canada [email protected] This paper introduces a new derivative parsing algorithm for recognition of parsing expression gram- mars. Derivative parsing is shown to have a polynomial worst-case time bound, an improvement on the exponential bound of the recursive descent algorithm. This work also introduces asymptotic analysis based on inputs with a constant bound on both grammar nesting depth and number of back- tracking choices; derivative and recursive descent parsing are shown to run in linear time and constant space on this useful class of inputs, with both the theoretical bounds and the reasonability of the in- put class validated empirically. This common-case constant memory usage of derivative parsing is an improvement on the linear space required by the packrat algorithm. 1 Introduction Parsing expression grammars (PEGs) are a parsing formalism introduced by Ford [6]. Any LR(k) lan- guage can be represented as a PEG [7], but there are some non-context-free languages that may also be represented as PEGs (e.g. anbncn [7]). Unlike context-free grammars (CFGs), PEGs are unambiguous, admitting no more than one parse tree for any grammar and input. PEGs are a formalization of recursive descent parsers allowing limited backtracking and infinite lookahead; a string in the language of a PEG can be recognized in exponential time and linear space using a recursive descent algorithm, or linear time and space using the memoized packrat algorithm [6]. PEGs are formally defined and these algo- rithms outlined in Section 3. -
Unravel Data Systems Version 4.5
UNRAVEL DATA SYSTEMS VERSION 4.5 Component name Component version name License names jQuery 1.8.2 MIT License Apache Tomcat 5.5.23 Apache License 2.0 Tachyon Project POM 0.8.2 Apache License 2.0 Apache Directory LDAP API Model 1.0.0-M20 Apache License 2.0 apache/incubator-heron 0.16.5.1 Apache License 2.0 Maven Plugin API 3.0.4 Apache License 2.0 ApacheDS Authentication Interceptor 2.0.0-M15 Apache License 2.0 Apache Directory LDAP API Extras ACI 1.0.0-M20 Apache License 2.0 Apache HttpComponents Core 4.3.3 Apache License 2.0 Spark Project Tags 2.0.0-preview Apache License 2.0 Curator Testing 3.3.0 Apache License 2.0 Apache HttpComponents Core 4.4.5 Apache License 2.0 Apache Commons Daemon 1.0.15 Apache License 2.0 classworlds 2.4 Apache License 2.0 abego TreeLayout Core 1.0.1 BSD 3-clause "New" or "Revised" License jackson-core 2.8.6 Apache License 2.0 Lucene Join 6.6.1 Apache License 2.0 Apache Commons CLI 1.3-cloudera-pre-r1439998 Apache License 2.0 hive-apache 0.5 Apache License 2.0 scala-parser-combinators 1.0.4 BSD 3-clause "New" or "Revised" License com.springsource.javax.xml.bind 2.1.7 Common Development and Distribution License 1.0 SnakeYAML 1.15 Apache License 2.0 JUnit 4.12 Common Public License 1.0 ApacheDS Protocol Kerberos 2.0.0-M12 Apache License 2.0 Apache Groovy 2.4.6 Apache License 2.0 JGraphT - Core 1.2.0 (GNU Lesser General Public License v2.1 or later AND Eclipse Public License 1.0) chill-java 0.5.0 Apache License 2.0 Apache Commons Logging 1.2 Apache License 2.0 OpenCensus 0.12.3 Apache License 2.0 ApacheDS Protocol -

Adaptive LL(*) Parsing: the Power of Dynamic Analysis
Adaptive LL(*) Parsing: The Power of Dynamic Analysis Terence Parr Sam Harwell Kathleen Fisher University of San Francisco University of Texas at Austin Tufts University [email protected] [email protected] kfi[email protected] Abstract PEGs are unambiguous by definition but have a quirk where Despite the advances made by modern parsing strategies such rule A ! a j ab (meaning “A matches either a or ab”) can never as PEG, LL(*), GLR, and GLL, parsing is not a solved prob- match ab since PEGs choose the first alternative that matches lem. Existing approaches suffer from a number of weaknesses, a prefix of the remaining input. Nested backtracking makes de- including difficulties supporting side-effecting embedded ac- bugging PEGs difficult. tions, slow and/or unpredictable performance, and counter- Second, side-effecting programmer-supplied actions (muta- intuitive matching strategies. This paper introduces the ALL(*) tors) like print statements should be avoided in any strategy that parsing strategy that combines the simplicity, efficiency, and continuously speculates (PEG) or supports multiple interpreta- predictability of conventional top-down LL(k) parsers with the tions of the input (GLL and GLR) because such actions may power of a GLR-like mechanism to make parsing decisions. never really take place [17]. (Though DParser [24] supports The critical innovation is to move grammar analysis to parse- “final” actions when the programmer is certain a reduction is time, which lets ALL(*) handle any non-left-recursive context- part of an unambiguous final parse.) Without side effects, ac- free grammar. ALL(*) is O(n4) in theory but consistently per- tions must buffer data for all interpretations in immutable data forms linearly on grammars used in practice, outperforming structures or provide undo actions. -

Abstract Syntax Trees & Top-Down Parsing
Abstract Syntax Trees & Top-Down Parsing Review of Parsing • Given a language L(G), a parser consumes a sequence of tokens s and produces a parse tree • Issues: – How do we recognize that s ∈ L(G) ? – A parse tree of s describes how s ∈ L(G) – Ambiguity: more than one parse tree (possible interpretation) for some string s – Error: no parse tree for some string s – How do we construct the parse tree? Compiler Design 1 (2011) 2 Abstract Syntax Trees • So far, a parser traces the derivation of a sequence of tokens • The rest of the compiler needs a structural representation of the program • Abstract syntax trees – Like parse trees but ignore some details – Abbreviated as AST Compiler Design 1 (2011) 3 Abstract Syntax Trees (Cont.) • Consider the grammar E → int | ( E ) | E + E • And the string 5 + (2 + 3) • After lexical analysis (a list of tokens) int5 ‘+’ ‘(‘ int2 ‘+’ int3 ‘)’ • During parsing we build a parse tree … Compiler Design 1 (2011) 4 Example of Parse Tree E • Traces the operation of the parser E + E • Captures the nesting structure • But too much info int5 ( E ) – Parentheses – Single-successor nodes + E E int 2 int3 Compiler Design 1 (2011) 5 Example of Abstract Syntax Tree PLUS PLUS 5 2 3 • Also captures the nesting structure • But abstracts from the concrete syntax a more compact and easier to use • An important data structure in a compiler Compiler Design 1 (2011) 6 Semantic Actions • This is what we’ll use to construct ASTs • Each grammar symbol may have attributes – An attribute is a property of a programming language construct -

Lexing and Parsing with ANTLR4
Lab 2 Lexing and Parsing with ANTLR4 Objective • Understand the software architecture of ANTLR4. • Be able to write simple grammars and correct grammar issues in ANTLR4. EXERCISE #1 Lab preparation Ï In the cap-labs directory: git pull will provide you all the necessary files for this lab in TP02. You also have to install ANTLR4. 2.1 User install for ANTLR4 and ANTLR4 Python runtime User installation steps: mkdir ~/lib cd ~/lib wget http://www.antlr.org/download/antlr-4.7-complete.jar pip3 install antlr4-python3-runtime --user Then in your .bashrc: export CLASSPATH=".:$HOME/lib/antlr-4.7-complete.jar:$CLASSPATH" export ANTLR4="java -jar $HOME/lib/antlr-4.7-complete.jar" alias antlr4="java -jar $HOME/lib/antlr-4.7-complete.jar" alias grun='java org.antlr.v4.gui.TestRig' Then source your .bashrc: source ~/.bashrc 2.2 Structure of a .g4 file and compilation Links to a bit of ANTLR4 syntax : • Lexical rules (extended regular expressions): https://github.com/antlr/antlr4/blob/4.7/doc/ lexer-rules.md • Parser rules (grammars) https://github.com/antlr/antlr4/blob/4.7/doc/parser-rules.md The compilation of a given .g4 (for the PYTHON back-end) is done by the following command line: java -jar ~/lib/antlr-4.7-complete.jar -Dlanguage=Python3 filename.g4 or if you modified your .bashrc properly: antlr4 -Dlanguage=Python3 filename.g4 2.3 Simple examples with ANTLR4 EXERCISE #2 Demo files Ï Work your way through the five examples in the directory demo_files: Aurore Alcolei, Laure Gonnord, Valentin Lorentz. 1/4 ENS de Lyon, Département Informatique, M1 CAP Lab #2 – Automne 2017 ex1 with ANTLR4 + Java : A very simple lexical analysis1 for simple arithmetic expressions of the form x+3. -

Creating Custom DSL Editor for Eclipse Ian Graham Markit Risk Analytics
Speaking Your Language Creating a custom DSL editor for Eclipse Ian Graham 1 Speaking Your Language | © 2012 Ian Graham Background highlights 2D graphics, Fortran, Pascal, C Unix device drivers/handlers – trackball, display devices Smalltalk Simulation Sensor “data fusion” electronic warfare test-bed for army CASE tools for telecommunications Java Interactive visual tools for QC of seismic processing Seismic processing DSL development tools Defining parameter constraints and doc of each seismic process in XML Automating help generation (plain text and HTML) Smart editor that leverages DSL definition Now at Markit using custom language for financial risk analysis Speaking Your Language | © 2012 Ian Graham Overview Introduction: Speaking Your Language What is a DSL? What is Eclipse? Demo: Java Editor Eclipse architecture Implementing an editor Implementing a simple editor Demo Adding language awareness to your editor Demo Learning from Eclipse examples Resources Speaking Your Language | © 2012 Ian Graham Introduction: Speaking Your Language Goal illustrate power of Eclipse platform Context widening use of Domain Specific Languages Focus editing support for custom languages in Eclipse Speaking Your Language | © 2012 Ian Graham Recipe Editor 5 Text Editor Recipes | © 2006 IBM | Made available under the EPL v1.0 What is a DSL? Domain Specific Language - a simplified language for specific problem domain Specialized programming language E.g. Excel formula, SQL, seismic processing script Specification language -

Conflict Resolution in a Recursive Descent Compiler Generator
LL(1) Conflict Resolution in a Recursive Descent Compiler Generator Albrecht Wöß, Markus Löberbauer, Hanspeter Mössenböck Johannes Kepler University Linz, Institute of Practical Computer Science, Altenbergerstr. 69, 4040 Linz, Austria {woess,loeberbauer,moessenboeck}@ssw.uni-linz.ac.at Abstract. Recursive descent parsing is restricted to languages whose grammars are LL(1), i.e., which can be parsed top-down with a single lookahead symbol. Unfortunately, many languages such as Java, C++, or C# are not LL(1). There- fore recursive descent parsing cannot be used or the parser has to make its deci- sions based on semantic information or a multi-symbol lookahead. In this paper we suggest a systematic technique for resolving LL(1) conflicts in recursive descent parsing and show how to integrate it into a compiler gen- erator (Coco/R). The idea is to evaluate user-defined boolean expressions, in order to allow the parser to make its parsing decisions where a one symbol loo- kahead does not suffice. Using our extended compiler generator we implemented a compiler front end for C# that can be used as a framework for implementing a variety of tools. 1 Introduction Recursive descent parsing [16] is a popular top-down parsing technique that is sim- ple, efficient, and convenient for integrating semantic processing. However, it re- quires the grammar of the parsed language to be LL(1), which means that the parser must always be able to select between alternatives with a single symbol lookahead. Unfortunately, many languages such as Java, C++ or C# are not LL(1) so that one either has to resort to bottom-up LALR(1) parsing [5, 1], which is more powerful but less convenient for semantic processing, or the parser has to resolve the LL(1) con- flicts using semantic information or a multi-symbol lookahead. -

A Simple, Possibly Correct LR Parser for C11 Jacques-Henri Jourdan, François Pottier
A Simple, Possibly Correct LR Parser for C11 Jacques-Henri Jourdan, François Pottier To cite this version: Jacques-Henri Jourdan, François Pottier. A Simple, Possibly Correct LR Parser for C11. ACM Transactions on Programming Languages and Systems (TOPLAS), ACM, 2017, 39 (4), pp.1 - 36. 10.1145/3064848. hal-01633123 HAL Id: hal-01633123 https://hal.archives-ouvertes.fr/hal-01633123 Submitted on 11 Nov 2017 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. 14 A simple, possibly correct LR parser for C11 Jacques-Henri Jourdan, Inria Paris, MPI-SWS François Pottier, Inria Paris The syntax of the C programming language is described in the C11 standard by an ambiguous context-free grammar, accompanied with English prose that describes the concept of “scope” and indicates how certain ambiguous code fragments should be interpreted. Based on these elements, the problem of implementing a compliant C11 parser is not entirely trivial. We review the main sources of difficulty and describe a relatively simple solution to the problem. Our solution employs the well-known technique of combining an LALR(1) parser with a “lexical feedback” mechanism. It draws on folklore knowledge and adds several original as- pects, including: a twist on lexical feedback that allows a smooth interaction with lookahead; a simplified and powerful treatment of scopes; and a few amendments in the grammar. -

AST Indexing: a Near-Constant Time Solution to the Get-Descendants-By-Type Problem Samuel Livingston Kelly Dickinson College
Dickinson College Dickinson Scholar Student Honors Theses By Year Student Honors Theses 5-18-2014 AST Indexing: A Near-Constant Time Solution to the Get-Descendants-by-Type Problem Samuel Livingston Kelly Dickinson College Follow this and additional works at: http://scholar.dickinson.edu/student_honors Part of the Software Engineering Commons Recommended Citation Kelly, Samuel Livingston, "AST Indexing: A Near-Constant Time Solution to the Get-Descendants-by-Type Problem" (2014). Dickinson College Honors Theses. Paper 147. This Honors Thesis is brought to you for free and open access by Dickinson Scholar. It has been accepted for inclusion by an authorized administrator. For more information, please contact [email protected]. AST Indexing: A Near-Constant Time Solution to the Get-Descendants-by-Type Problem by Sam Kelly Submitted in partial fulfillment of Honors Requirements for the Computer Science Major Dickinson College, 2014 Associate Professor Tim Wahls, Supervisor Associate Professor John MacCormick, Reader Part-Time Instructor Rebecca Wells, Reader April 22, 2014 The Department of Mathematics and Computer Science at Dickinson College hereby accepts this senior honors thesis by Sam Kelly, and awards departmental honors in Computer Science. Tim Wahls (Advisor) Date John MacCormick (Committee Member) Date Rebecca Wells (Committee Member) Date Richard Forrester (Department Chair) Date Department of Mathematics and Computer Science Dickinson College April 2014 ii Abstract AST Indexing: A Near-Constant Time Solution to the Get- Descendants-by-Type Problem by Sam Kelly In this paper we present two novel abstract syntax tree (AST) indexing algorithms that solve the get-descendants-by-type problem in near constant time. -
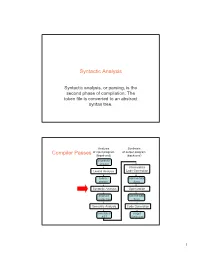
Syntactic Analysis, Or Parsing, Is the Second Phase of Compilation: the Token File Is Converted to an Abstract Syntax Tree
Syntactic Analysis Syntactic analysis, or parsing, is the second phase of compilation: The token file is converted to an abstract syntax tree. Analysis Synthesis Compiler Passes of input program of output program (front -end) (back -end) character stream Intermediate Lexical Analysis Code Generation token intermediate stream form Syntactic Analysis Optimization abstract intermediate syntax tree form Semantic Analysis Code Generation annotated target AST language 1 Syntactic Analysis / Parsing • Goal: Convert token stream to abstract syntax tree • Abstract syntax tree (AST): – Captures the structural features of the program – Primary data structure for remainder of analysis • Three Part Plan – Study how context-free grammars specify syntax – Study algorithms for parsing / building ASTs – Study the miniJava Implementation Context-free Grammars • Compromise between – REs, which can’t nest or specify recursive structure – General grammars, too powerful, undecidable • Context-free grammars are a sweet spot – Powerful enough to describe nesting, recursion – Easy to parse; but also allow restrictions for speed • Not perfect – Cannot capture semantics, as in, “variable must be declared,” requiring later semantic pass – Can be ambiguous • EBNF, Extended Backus Naur Form, is popular notation 2 CFG Terminology • Terminals -- alphabet of language defined by CFG • Nonterminals -- symbols defined in terms of terminals and nonterminals • Productions -- rules for how a nonterminal (lhs) is defined in terms of a (possibly empty) sequence of terminals -

Lecture 3: Recursive Descent Limitations, Precedence Climbing
Lecture 3: Recursive descent limitations, precedence climbing David Hovemeyer September 9, 2020 601.428/628 Compilers and Interpreters Today I Limitations of recursive descent I Precedence climbing I Abstract syntax trees I Supporting parenthesized expressions Before we begin... Assume a context-free struct Node *Parser::parse_A() { grammar has the struct Node *next_tok = lexer_peek(m_lexer); following productions on if (!next_tok) { the nonterminal A: error("Unexpected end of input"); } A → b C A → d E struct Node *a = node_build0(NODE_A); int tag = node_get_tag(next_tok); (A, C, E are if (tag == TOK_b) { nonterminals; b, d are node_add_kid(a, expect(TOK_b)); node_add_kid(a, parse_C()); terminals) } else if (tag == TOK_d) { What is the problem node_add_kid(a, expect(TOK_d)); node_add_kid(a, parse_E()); with the parse function } shown on the right? return a; } Limitations of recursive descent Recall: a better infix expression grammar Grammar (start symbol is A): A → i = A T → T*F A → E T → T/F E → E + T T → F E → E-T F → i E → T F → n Precedence levels: Nonterminal Precedence Meaning Operators Associativity A lowest Assignment = right E Expression + - left T Term * / left F highest Factor No Parsing infix expressions Can we write a recursive descent parser for infix expressions using this grammar? Parsing infix expressions Can we write a recursive descent parser for infix expressions using this grammar? No Left recursion Left-associative operators want to have left-recursive productions, but recursive descent parsers can’t handle left recursion -

Understanding Source Code Evolution Using Abstract Syntax Tree Matching
Understanding Source Code Evolution Using Abstract Syntax Tree Matching Iulian Neamtiu Jeffrey S. Foster Michael Hicks [email protected] [email protected] [email protected] Department of Computer Science University of Maryland at College Park ABSTRACT so understanding how the type structure of real programs Mining software repositories at the source code level can pro- changes over time can be invaluable for weighing the merits vide a greater understanding of how software evolves. We of DSU implementation choices. Second, we are interested in present a tool for quickly comparing the source code of dif- a kind of “release digest” for explaining changes in a software ferent versions of a C program. The approach is based on release: what functions or variables have changed, where the partial abstract syntax tree matching, and can track sim- hot spots are, whether or not the changes affect certain com- ple changes to global variables, types and functions. These ponents, etc. Typical release notes can be too high level for changes can characterize aspects of software evolution use- developers, and output from diff can be too low level. ful for answering higher level questions. In particular, we To answer these and other software evolution questions, consider how they could be used to inform the design of a we have developed a tool that can quickly tabulate and sum- dynamic software updating system. We report results based marize simple changes to successive versions of C programs on measurements of various versions of popular open source by partially matching their abstract syntax trees. The tool programs, including BIND, OpenSSH, Apache, Vsftpd and identifies the changes, additions, and deletions of global vari- the Linux kernel.