Critical Evaluation of the 'Matura' Test: CEFR Alignment Project for the Austrian National Examination in English (B2 Level)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Get Ready— TASC Test Readiness Assessment
Get Ready— TASC Test Readiness Assessment Prepare Learners with the TASC Test Readiness Assessment Content Areas The TASC Test Readiness Assessment is structured around the five content areas assessed by the TASC test: Reading, Writing, Mathematics, Science, and Social Studies. Like the TASC test, content is aligned to the College and Career Readiness Standards, Next Generation Science Standards, and National Curriculum Standards for Social Studies. The Readiness Assessment questions mirror those on the TASC test, so examinees can get an accurate prediction of their expected performance on the actual test. Designed to mimic the TASC test, the Readiness Assessment What is the TASC Test? contains the same types of question formats that The TASC Test Assessing Secondary Completion™ are used on the official TASC test. All subtests are is a state-of-the-art, affordable national high school composed primarily of multiple-choice questions, equivalency assessment that assesses five subject the mathematics test includes gridded response questions, areas: Reading, Writing, Mathematics, Science, and the Writing test contains a written essay question and Social Studies. It measures examinees’ levels of that requires examinees to write a persuasive essay achievement relative to that of graduating high school after reading two informational passages. seniors, and readiness for college and the workforce, • Like the TASC test, the multiple-choice questions as outlined by the College and Career Readiness on the Readiness Assessment require examinees to Standards. select the best answer from among four possible answer choices. Why take the Readiness Assessment? • The gridded-response questions require examinees By completing the Readiness Assessment, examinees to calculate a numerical response to the question receive a percentage score that indicates the likelihood and record it in a gridded-response area. -

Test Scores Explanation for Parents and Teachers: Youtube Video Script by Lara Langelett July 2019 1
Test Scores Explanation for Parents and Teachers: YouTube Video Script By Lara Langelett July 2019 1 Introduction: Hello Families and Teachers. My name is Lara Langelett and I would like to teach you about how to read your child’s or student’s test scores. The purpose of this video message is to give you a better understanding of standardized test scores and to be able to apply it to all normed assessment tools. First I will give a definition of what the bell curve is by using a familiar example. Then I will explain the difference between a percentile rank and percentage. Next, I will explain Normed-Referenced Standard test scores. In addition, the MAPs percentile rank and the RIT scores will be explained. Finally, I will explain IQ scores on the bell curve. 2 Slide 1: Let’s get started: here is a bell curve; it is shaped like a bell. 3 Slide 2: To understand the Bell Curve, we will look at a familiar example of basketball players in the U.S.A. Everyone, on this day, who plays basketball fits into this bell curve around the United States. I’m going to emphasis “on this day” as this is important piece information of for explaining standardized scores. 4 Slide 3: On the right side of the bell curve we can section off a part of the bell curve (2.1 % blue area). Inside this section are people who play basketball at the highest skill level, like the U.S. Olympic basketball team. These athletes are skilled athletes who have played basketball all their life, practice on a daily basis, have extensive knowledge of the game, and are at a caliber that the rest of the basketball population have not achieved. -

INTERNATIONAL MEDICAL ADMISSIONS TEST (IMAT) Frequently Asked Questions (Faqs) 2019
INTERNATIONAL MEDICAL ADMISSIONS TEST (IMAT) Frequently asked questions (FAQs) 2019 General information Q: How do I make a test booking? A: Candidates register via the UniversItaly website and then book the test through our payment system. Find out more on our web page How to register. Q: When do I register? A: Registration opens on 17 June 2019 and closes on 09 July 2019 at 3pm (Italian time). Q: What does the test involve? A: Details of the test can be found on our web page About IMAT. Q: How many universities can I select? A: You must select a first-choice university. For information about selecting further universities, visit the UniversItaly website How to modify your first choice of university, or where you wish to take the test: - If you have not yet paid the registration fee, you need to click on the "Delete IMAT registration" button. Immediately after this you will be able to change your first choice. You may do this until 09 July 2019 at 3pm (Italian time). - If you have already paid the registration fee, you need to click on the "Delete IMAT registration" button and wait for the confirmation that the refund is being processed. We will attempt to do this as quickly as possible but this may take several working hours. Once this has happened, you will be able to re-book. Because you need to have this process completed by 09 July (3pm Italian time), we recommend you do not start the cancellation and rebooking process after 10am on that day. For information about cancelling your booking, please visit our support site. -

Assessment Integrity Guide
Assessment Integrity Guide MICHIGAN DEPARTMENT OF EDUCATION OFFICE OF EDUCATIONAL ASSESSMENT AND ACCOUNTABILITY Michigan Standards for Professional and Ethical Conduct in Test Administration and Reporting 2021-22 MICHIGAN DEPARTMENT OF EDUCATION Office of Educational Assessment and Accountability The Michigan State Board of Education approved this guide on April 12, 2016 with updates on 7/28/20. This document pertains to the expected professional and ethical conduct of all assessment programs administered by the Michigan Department of Education (MDE), Office of Educational Assessment and Accountability (OEAA). This includes all Michigan summative, interim, and formative assessments. If you have questions or wish to report suspected test administration irregularities on any statewide educational assessments or accountability issues in Michigan, contact: Michigan Department of Education Office Educational Assessment and Accountability 608 West Allegan Street PO Box 30008 Lansing, MI 48915 toll-free phone: 877-560-8378 email: [email protected] fax: 517-335-1186 Copies of this guide may be obtained on the Assessment Integrity and Security web page ASSESSMENT INTEGRITY GUIDE (https://www.michigan.gov/ mde/0,1607,7-140-22709---,00.html). STATE BOARD OF EDUCATION Michael F. Rice, Ph.D., State Superintendent Jason Strayhorn • Tom McMillin Judith Pritchett • Pamela Pugh Ellen Cogen Lipton • Nikki Snyder Tiffany D. Tilley • Dr. Casandra E. Ulbrich 2 3 Table of Contents Introduction. 4 Case Review .................................27 Importance of Assessment Security ................5 Monitoring. 27 Assessment Security Goals for the State of Michigan District and School Internal Assessment Monitoring .....27 Assessment System ...............................6 OEAA Assessment Monitoring ...................28 Common Assessment Irregularities ...................6 OEAA Targeted and Random Assessment Monitoring 28 Communication Protocol .........................8 Targeted Assessment Monitoring . -

DEFENSE Test and Evaluation
TREATIES AND OTHER INTERNATIONAL ACTS SERIES 06-1107.1 ________________________________________________________________________ DEFENSE Test and Evaluation Memorandum of Understanding Between the UNITED STATES OF AMERICA and the UNITED KINGDOM OF GREAT BRITAIN AND NORTHERN IRELAND Signed at Washington and London October 18 and November 7, 2006 with Annexes NOTE BY THE DEPARTMENT OF STATE Pursuant to Public Law 89—497, approved July 8, 1966 (80 Stat. 271; 1 U.S.C. 113)— “. .the Treaties and Other International Acts Series issued under the authority of the Secretary of State shall be competent evidence . of the treaties, international agreements other than treaties, and proclamations by the President of such treaties and international agreements other than treaties, as the case may be, therein contained, in all the courts of law and equity and of maritime jurisdiction, and in all the tribunals and public offices of the United States, and of the several States, without any further proof or authentication thereof.” UNITED KINGDOM OF GREAT BRITAIN AND NORTHERN IRELAND Defense: Test and Evaluation Memorandum of understanding signed at Washington and London October 18 and November 7, 2006; Entered into force November 7, 2006. With annexes. MEMORANDUM OF UNDERSTANDING BETWEEN THE DEPARTMENT OF DEFENSE OF THE UNITED STATES OF AMERICA AND THE SECRETARY OF STATE FOR DEFENCE OF THE UNITED KINGDOM OF GREAT BRITAIN AND NORTHERN IRELAND FOR TEST AND EVALUATION PROGRAM (TEP COOPERATION (SHORT TITLE: TEP MOU) DATE: October 16, 2006 THIS DOCUMENT IS CERTIFIED -

The Rules of Entry to Hungary *
The rules of entry to Hungary* Only Hungarian citizens are permitted to enter Hungary, following the checking of their travel document and medical screening. They are then obliged to enter authority home quarantine for 10 days from the date of entry. The same rules apply to the following persons as well: Foreigners entitled to permanent residence in Hungary, and their family members, Foreigners who have a valid Hungarian residence permit for a period exceeding 90 days, issued by the authority for aliens policing. Hungarian citizens may return home from abroad without restrictions if the reason for the trip from Hungary was a business or 10 nap economic activity which the Hungarian citizen is able to credibly attest, upon return to Hungary. Non-Hungarian citizens may not enter the territory of Hungary in passenger traffic, with the exceptions specified in the relevant acts or government decrees. In the case of border crossings at Budapest Airport, the Budapest District XVIII Police Command may grant an exemption from the travel restrictions, upon request. Leniency applications can only be submitted electronically, in Hungarian or English language, at the website https://ugyintezes.police.hu/hu/meltanyossagi-kerelem or by scanning this QR code. Foreign citizens authorized to enter are obliged to enter authority home quarantine for 10 days from the date of entry. The citizens of the Czech Republic, the Republic of Poland and the Slovak Republic may enter Hungary if they attest that they have a booking for at least one day at an accommodation facility in Hungary until 31 October 2020 at the latest, the booking was made prior to 6 October 2020 and they attest with a Hungarian or English language document containing the results of one SARS-CoV-2 test made within 5 days prior to entry that the SARS-CoV-2 coronavirus was not detected in their body at the time of the test. -

PISA 2012 Results, Visit
UNITED KINGDOM Key findings • The United Kingdom performs around the average in mathematics and reading and above average in science, compared with the 34 OECD countries that participated in the 2012 PISA assessment of 15-year-olds. • When compared with PISA 2006 and PISA 2009, there has been no change in performance in any of the subjects tested. (The PISA 2000 and 2003 samples for the United Kingdom did not meet the PISA response-rate standards, so the observed higher performance in 2000 should not be used for comparisons.) • The United Kingdom is listed 26th in mathematics performance, but because results are based on a sample, its relative position could be between 23rd and 31st. Its performance is similar to Czech Republic, Denmark, France, Iceland, Republic of Ireland, Latvia, Luxembourg, New Zealand, Norway and Portugal. • The United Kingdom has a higher GDP and spends more on education than the average in OECD countries, as well as higher levels of tertiary education and a lower share of the most socio-economically deprived groups. However, these comparative advantages do not have a clear relationship with educational outcomes. • As in many other countries, socio-economically disadvantaged students in the United Kingdom are less likely to succeed at school than their more advantaged peers. However, some countries are more successful than the United Kingdom in reducing the influence of socio-economic status on student performance. • On the other hand, students from an immigrant background (first or second generation) in the United Kingdom perform as well in mathematics as other students. This is in contrast to the situation observed in many other OECD countries, where students from an immigrant background score significantly lower. -
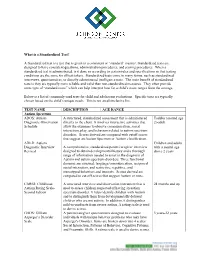
What Is a Standardized Test?
What is a Standardized Test? A Standardized test is a test that is given in a consistent or “standard” manner. Standardized tests are designed to have consistent questions, administration procedures, and scoring procedures. When a standardized test is administrated, is it done so according to certain rules and specifications so that testing conditions are the same for all test takers. Standardized tests come in many forms, such as standardized interviews, questionnaires, or directly administered intelligence tests. The main benefit of standardized tests is they are typically more reliable and valid than non-standardized measures. They often provide some type of “standard score” which can help interpret how far a child’s score ranges from the average. Below is a list of commonly used tests for child and adolescent evaluations. Specific tests are typically chosen based on the child’s unique needs. This is not an all-inclusive list. TEST NAME DESCRIPTION AGE RANGE Autism Spectrum ADOS: Autism A structured, standardized assessment that is administered Toddler (around age Diagnostic Observation directly to the client. It involves interactive activities that 2)-adult Schedule allow the examiner to observe communication, social interaction, play, and behaviors related to autism spectrum disorders. Scores derived are compared with cutoff scores that suggest an Autism Spectrum or Autism classification. ADI-R: Autism Children and adults Diagnostic Interview A comprehensive, standardized parent/caregiver interview with a mental age Revised designed to obtain developmental history and a thorough above 2 years range of information needed to assist in the diagnosis of Autism and autism spectrum disorders. Three functional domains are assessed: language/communication, reciprocal social interaction, and restrictive, repetitive, and stereotyped behaviors and interests. -

Inspection and Test Procedures for Individual Vehicle Approval (IVA)
Inspection and Test Procedures for Individual Vehicle Approval (IVA) Page 1 of 157 IVA rev.1 Table of Contents Page Page No. No. Foreword 3 29. Reversing lamps 78 Non-European and Other Acceptable 4 30. Parking lamps 78 Standards 1. Sound Levels 8 31. Seat belts and Restraint Systems 88 2. Emissions 9 32. Forward vision 91 3. Fuel tanks and rear protective devices 11 33. Identification of controls 92 4. Rear registration plate space 14 34. Defrost / Demist 95 5. Steering effort 15 35. Wash / wipe 96 6. Door latches and hinges 16 36. Heating systems 97 7. Audible warning 17 37. Wheel guards 101 8. Indirect Vision 18 38. Head restraints 104 9. Braking 28 39. CO2 emissions / fuel consumption 105 10. Suppression (radio) EMC 39 40. Engine power 106 11.Diesel smoke 40 41. Diesel emissions 107 12. Interior fittings 41 42. Lateral protection 108 13. Anti-theft and immobiliser 42 43. Spray-suppression systems 111 14. Protective steering 46 44. Masses and dimensions (cars) 120 15. Seat Strength 50 45. Safety glass 121 16. Exterior projections 53 46. Tyres 122 17. Speedometer and reverse gear 63 47. Speed limiters 125 18. Plates (statutory) 64 48. Masses and dimensions (other than vehicles 126 referred to in item 44) 19. Seat belt anchorages 65 49. External projections of cabs 132 20. Installation of lighting and light 78 50. Couplings 136 signalling devices 21. Retro reflectors 78 51. Flammability 139 22. End-outline, front-position (side), rear- 78 52. Buses and coaches 140 position (side), stop, side marker, daytime running lamps 23. -

Driver Licensing in Ireland a GUIDE
National Driver Licence Service Driver Licence National Driver Licensing in Ireland A GUIDE National Driver Licence Service | Road Safety Authority Primrose Hill, Dublin Road, Ballina, Co. Mayo An tSeirhbís Náisiúnta um Cheadúnais Tiomána | Údarás Um Shábháilteacht Ar Bhóithre Cnoc an tSabhaircín, Bóthar Bhaile Átha Cliath, Béal an Átha, Co. Mhaigh Eo. 096-25051 | www.ndls.ie Driver Licensing in Ireland A GUIDE An tSeirbhís Náisiúnta um Cheadúnais Tiomána National Driver Licence Service About this booklet If you want to drive, you have to have a valid driving licence or a learner permit. The National Driver Licence Service (NDLS) is responsible for processing applications for driver licences and learner permits. (Until recently, these functions were carried out by Motor Tax Offices.) There are 15 different categories of driving licence and learner permit for different types of vehicle, and all of these have different rules and regulations. There are rules ... ... about how old you must be before you can drive different categories of vehicle ... about how much formal training or how many lessons you have to take ... about penalty points ... about who has to submit a medical report with an application ... about who does and who does not need CPC ... and so on. Many of these rules and regulations will seem obvious. Others less so. All of them, however, are in place for good reason and they fit with the RSA’s mission to improve road safety and to ensure that drivers are well-trained, safe and competent. The purpose of this booklet is to outline how to apply for and maintain a driving licence or learner permit and to describe the regulations that relate to both. -

An Analysis of the State Matura Exam in Kosovo Vjolla Gashi [email protected]
Rochester Institute of Technology RIT Scholar Works Theses Thesis/Dissertation Collections 7-1-2018 An Analysis of the State Matura Exam in Kosovo Vjolla Gashi [email protected] Follow this and additional works at: http://scholarworks.rit.edu/theses Recommended Citation Gashi, Vjolla, "An Analysis of the State Matura Exam in Kosovo" (2018). Thesis. Rochester Institute of Technology. Accessed from This Senior Project is brought to you for free and open access by the Thesis/Dissertation Collections at RIT Scholar Works. It has been accepted for inclusion in Theses by an authorized administrator of RIT Scholar Works. For more information, please contact [email protected]. www.kosovo.rit.edu RIT KOSOVO An Analysis of the State Matura Exam in Kosovo Vjolla Gashi 7/1/2018 Advisor: Venera Demukaj, PhD Submitted to RIT Kosovo as part of requirement for education An Honors Society Project Presented to the Academic Faculty By Vjolla Gashi In Partial Fulfillment of the Requirements for Membership in the Honors Society of RIT Kosovo www.kosovo.rit.edu Abstract This paper’s aim is to analyze the State Matura Exam. The focus of the analysis is in particular on the administration process of the exam. The analysis is conducted by relying on both primary and secondary research. The research discusses the issues with the administration process of the test, whereby it identifies organized cheating as one of the most problematic issues. It also identifies methods of cheating by relying on primary research e.g. surveys and focus groups. Thus, the study analyzes whether the State Matura Exam fulfills the criteria needed to be considered a standardized test. -

Gottfried Wilhelm Leibnitz (Or Leibniz) Was Born at Leipzig on June 21 (O.S.), 1646, and Died in Hanover on November 14, 1716. H
Gottfried Wilhelm Leibnitz (or Leibniz) was born at Leipzig on June 21 (O.S.), 1646, and died in Hanover on November 14, 1716. His father died before he was six, and the teaching at the school to which he was then sent was inefficient, but his industry triumphed over all difficulties; by the time he was twelve he had taught himself to read Latin easily, and had begun Greek; and before he was twenty he had mastered the ordinary text-books on mathematics, philosophy, theology and law. Refused the degree of doctor of laws at Leipzig by those who were jealous of his youth and learning, he moved to Nuremberg. An essay which there wrote on the study of law was dedicated to the Elector of Mainz, and led to his appointment by the elector on a commission for the revision of some statutes, from which he was subsequently promoted to the diplomatic service. In the latter capacity he supported (unsuccessfully) the claims of the German candidate for the crown of Poland. The violent seizure of various small places in Alsace in 1670 excited universal alarm in Germany as to the designs of Louis XIV.; and Leibnitz drew up a scheme by which it was proposed to offer German co-operation, if France liked to take Egypt, and use the possessions of that country as a basis for attack against Holland in Asia, provided France would agree to leave Germany undisturbed. This bears a curious resemblance to the similar plan by which Napoleon I. proposed to attack England. In 1672 Leibnitz went to Paris on the invitation of the French government to explain the details of the scheme, but nothing came of it.