Diss. Eth No. 22159 Disaggregating Civil Conflict
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Rapport Des Chefs De Mission Diplomatiques De L'union
Rapport des Chefs de Mission Diplomatiques de l’Union Européenne sur Jérusalem 2017 Note de synthèse Les Chefs de Mission à Jérusalem et à Ramallah soumettent par le présent document au Comité Politique et de Sécurité le rapport sur Jérusalem pour 2017 (annexe 1) et une série de recommandations pour discussion pour renforcer la politique de l’Union Européenne sur Jérusalem Est (Annexe 2). L’annexe 3 contient des faits supplémentaires et des chiffres sur Jérusalem. Les développements intervenus en 2017 ont encore accéléré les difficultés de la solution « des deux Etats » en l’absence de processus de paix significatif. Les tendances précédentes, observées et décrites par les Chefs de Mission Diplomatiques depuis plusieurs années, se sont empirées. La mise à l’écart des Palestiniens de la vie ordinaire, politique, économique et sociale de la ville sont largement inchangées. Le développement d’un nombre record de plans de colonisation s’est poursuivi, y compris dans des zones identifiées par l’Union Européenne et ses Etats membres comme clés pour une solution « des deux Etats ». En même temps, les démolitions de logements palestiniens se sont poursuivies, et plusieurs familles palestiniennes ont été expulsées de leurs logements au bénéfice de colons. Les tensions autour du Dôme du Rocher / Mont du Temple continuent. Au cours de cette année, plusieurs projets de lois à la Knesset ont poursuivi leur avancée législative, qui, s’ils étaient adoptés, apporteraient des changements unilatéraux au statut et aux frontières de Jérusalem, en violation du droit international. En fin d’année, les Etats Unis ont annoncé leur reconnaissance de Jérusalem comme capitale d’Israël. -

Planning and Injustice in Tel-Aviv/Jaffa Urban Segregation in Tel-Aviv’S First Decades
Planning and Injustice in Tel-Aviv/Jaffa Urban Segregation in Tel-Aviv’s First Decades Rotem Erez June 7th, 2016 Supervisor: Dr. Stefan Kipfer A Major Paper submitted to the Faculty of Environmental Studies in partial fulfillment of the requirements for the degree of Master in Environmental Studies, York University, Toronto, Ontario, Canada Student Signature: _____________________ Supervisor Signature:_____________________ Contents Contents .................................................................................................................................................... 1 Table of Figures ......................................................................................................................................... 3 Abstract .............................................................................................................................................4 Foreword ...........................................................................................................................................6 Introduction ......................................................................................................................................9 Chapter 1: A Comparative Study of the Early Years of Colonial Casablanca and Tel-Aviv ..................... 19 Introduction ............................................................................................................................................ 19 Historical Background ............................................................................................................................ -

4.Employment Education Hebrew Arnona Culture and Leisure
Did you know? Jerusalem has... STARTUPS OVER OPERATING IN THE CITY OVER SITES AND 500 SYNAGOGUES 1200 39 MUSEUMS ALTITUDE OF 630M CULTURAL INSTITUTIONS COMMUNITY 51 AND ARTS CENTERS 27 MANAGERS ( ) Aliyah2Jerusalem ( ) Aliyah2Jerusalem JERUSALEM IS ISRAEL’S STUDENTS LARGEST CITY 126,000 DUNAM Graphic design by OVER 40,000 STUDYING IN THE CITY 50,000 VOLUNTEERS Illustration by www.rinatgilboa.com • Learning centers are available throughout the city at the local Provide assistance for olim to help facilitate a smooth absorption facilities. The centers offer enrichment and study and successful integration into Jerusalem. programs for school age children. • Jerusalem offers a large selection of public and private schools Pre - Aliyah Services 2 within a broad religious spectrum. Also available are a broad range of learning methods offered by specialized schools. Assistance in registration for municipal educational frameworks. Special in Jerusalem! Assistance in finding residence, and organizing community needs. • Tuition subsidies for Olim who come to study in higher education and 16 Community Absorption Coordinators fit certain criteria. Work as a part of the community administrations throughout the • Jerusalem is home to more than 30 institutions of higher education city; these coordinators offer services in educational, cultural, sports, that are recognized by the Student Authority of the Ministry of administrative and social needs for Olim at the various community Immigration & Absorption. Among these schools is Hebrew University – centers. -

Jerusalemite Day of Diversity 2019 List of Events
Jerusalemite Day of Diversity 2019 List of Events ~~Saturday June 1~~ Praying and Signing for A Tolerant Jerusalem | Hayovel Masorati Congregation A special Shabbat morning prayer for Jerusalem. After the services we will study together the sign language version of “Jerusalem of Gold” with Aviel from Shema, an organization for the hearing impaired in Kiryat Yovel. Saturday | 9:30 | Hayovel Masorati Congregation - 1 Abraham Sharon St Stories about Jerusalem | Bab El-Yaman 4 stories, 4 points of view of Jerusalem, and an opportunity for the audience to storytell as well. Facilitated by Yael Gidanyan, a Jerusalemite activist. Saturday | 13:00 | Bab El-Yaman, 20 Azza St Heroines of the Palmach | Itamar Farhi A tour that starts and and ends in the Palmach about women, about heroism, and the connection to the most feminist street of Jerusalem. Saturday | 17:30 | Mtg Pt: Islam Museum of Art, 2 HaPalmach St A Visit from East Jerusalem to West Jerusalem | Sha’alu Shalom Yerushalayim & the Masrik and Beit Safafa Reading Stations On Shabbat BaMidbar, as Yom Yerushalayim approaches, come hear residents of Sheikh Jarrah speak about life under the threat of eviction. This event is hosted by Sha’alu Shalom Yerushalayim, religious activists who seek the welfare of vulnerable communities in East Jerusalem. The event is supported by the Mesilah Reading Stations at Masaryk and Beit Safafa. In honor of Yom Yerushalayim, the Beit Safafa Reading Station will be re-stocked with Arabic books. Enjoy, and please donate from your own unwanted books in Arabic (or any other language)! In Hebrew. Unplugged. All welcome! Saturday | 18:00 | the Mesilah Reading Station (Masaryk and HaRakevet) Shabati for Jerusalem Day! | Shabati A fascinating meeting with Rabbi Chanoch Rojchinski, a Haredi educator, in a discussion about challenges and opportunities in the Haredi world. -

מכון ירושלים לחקר ישראל Jerusalem Institute for Israel Studies שנתון
מכון ירושלים לחקר ישראל Jerusalem Institute for Israel Studies שנתון סטטיסטי לירושלים Statistical Yearbook of Jerusalem 2016 2016 לוחות נוספים – אינטרנט Additional Tables - Internet לוח ג/19 - אוכלוסיית ירושלים לפי קבוצת אוכלוסייה, רמת הומוגניות חרדית1, רובע, תת-רובע ואזור סטטיסטי, 2014 Table III/19 - Population of Jerusalem by Population Group, Ultra-Orthodox Homogeneity Level1, Quarter, Sub-Quarter, and Statistical Area, 2014 % רמת הומוגניות חרדית )1-12( סך הכל יהודים ואחרים אזור סטטיסטי ערבים Statistical area Ultra-Orthodox Jews and Total homogeneity Arabs others level )1-12( ירושלים - סך הכל Jerusalem - Total 10 37 63 849,780 רובע Quarter 1 10 2 98 61,910 1 תת רובע 011 - נווה יעקב Sub-quarter 011 - 3 1 99 21,260 Neve Ya'akov א"ס .S.A 0111 נווה יעקב )מזרח( Neve Ya'akov (east) 1 0 100 2,940 0112 נווה יעקב - Neve Ya'akov - 1 0 100 2,860 קרית קמניץ Kiryat Kamenetz 0113 נווה יעקב )דרום( - Neve Ya'akov (south) - 6 1 99 3,710 רח' הרב פניז'ל, ,.Harav Fenigel St מתנ"ס community center 0114 נווה יעקב )מרכז( - Neve Ya'akov (center) - 6 1 99 3,450 מבוא אדמונד פלג .Edmond Fleg St 0115 נווה יעקב )צפון( - 3,480 99 1 6 Neve Ya'akov (north) - Meir Balaban St. רח' מאיר בלבן 0116 נווה יעקב )מערב( - 4,820 97 3 9 Neve Ya'akov (west) - Abba Ahimeir St., רח' אבא אחימאיר, Moshe Sneh St. רח' משה סנה תת רובע 012 - פסגת זאב צפון Sub-quarter 012 - - 4 96 18,500 Pisgat Ze'ev north א"ס .S.A 0121 פסגת זאב צפון )מערב( Pisgat Ze'ev north (west) - 6 94 4,770 0122 פסגת זאב צפון )מזרח( - Pisgat Ze'ev north (east) - - 1 99 3,120 רח' נתיב המזלות .Netiv Hamazalot St 0123 -

Israel: Off the Beaten Track by Carol Goodman Kaufman
Page 16BerkshireJewishVoice• jewishberkshires.org March 11-April 11, 2013 Traveling with Jewish Taste© Israel: Off the Beaten Track By Carol Goodman Kaufman In October, Joel and I traveled to Israel to celebrate The Center’s facil- Hadassah’s centennial anniversary. After the excitement ity and its location are and hoopla of the three-day convention, we remained in truly emblematic of the country to visit family. While we didn’t get a chance both its history and to see everybody, we did manage to catch up with some its mission, which cousins while at the same time getting an “off-the-beaten- is “to assist the city path” look at Israel. residents, of various I hadn’t been to Motza Illit in many years, but it looks identities, in becoming exactly the way I remembered it: lush, green, and quiet active and responsible – an idyllic retreat from the hustle and bustle of Jerusa- partners in the devel- lem. But, life wasn’t always so peaceful. During the riots opment of their com- of 1929, Arabs attacked Jews throughout the country, munities.” The JICC including the tiny village of Motza. develops programs and Many residents died, prompting its leaders to consider relocating. In 1934, twenty partnerships that pro- Jewish families established Motza Illit (meaning “Upper Motza”) higher up on the mote dialogue among same hill. the various constituen- This village of fewer than a thousand residents, just west of the Jerusalem city cies, such as cultural limits, no longer functions as a moshav (a cooperative agricultural community), but competence training is now more of a bedroom community. -

Knessia Gedolah Diary
THE JEWISH OBSERVER (ISSN 0021-6615) is published monthly, in this issue ... except July and August, by the Agudath lsrael of Ameri.ca, 5 Beekman Street, New York, N.Y. The Sixth Knessia Gedolah of Agudath Israel . 3 10038. Second class postage paid at New York, N.Y. Subscription Knessia Gedolah Diary . 5 $9.00 per year; two years, $17.50, Rabbi Elazar Shach K"ti•?111: The Essence of Kial Yisroel 13 three years, $25.00; outside of the United States, $10.00 per year Rabbi Yaakov Kamenetzky K"ti•?111: Blessings of "Shalom" 16 Single copy, $1.25 Printed in the U.S.A. What is an Agudist . 17 Rabbi Yaakov Yitzchok Ruderman K"ti•?111: RABBI NISSON WotP!N Editor An Agenda of Restraint and Vigilance . 18 The Vizhnitzer Rebbe K"ti•'i111: Saving Our Children .19 Editorial Board Rabbi Shneur Kotler K"ti•'i111: DR. ERNST BODENHEIMER Chairman The Ability and the Imperative . 21 RABBI NATHAN BULMAN RABBI JOSEPH ELIAS Helping Others Make it, Mordechai Arnon . 27 JOSEPH FRJEDENSON "Hereby Resolved .. Report and Evaluation . 31 RABBI MOSHE SHERER :'-a The Crooked Mirror, Menachem Lubinsky .39 THE JEWISH OBSERVER does not Discovering Eretz Yisroel, Nissan Wolpin .46 assume responsibility for the Kae;hrus of any product or ser Second Looks at the Jewish Scene vice advertised in its pages. Murder in Hebron, Violation in Jerusalem ..... 57 On Singing a Different Tune, Bernard Fryshman .ss FEB., 1980 VOL. XIV, NOS. 6-7 Letters to the Editor . • . 6 7 ___.., _____ -- -· - - The Jewish Observer I February, 1980 3 Expectations ran high, and rightfully so. -

Insiders' Jerusalem - Urgent
Kristin McCarthy <[email protected]> Insiders' Jerusalem - Urgent. Givat Hamatos tenders to be published. 1 message Daniel Seidemann <[email protected]> Tue, Nov 10, 2020 at 5:30 PM Reply-To: Daniel Seidemann <[email protected]> To: [email protected] Insiders' Jerusalem November 11, 2020 Urgent: Givat Hamatos tenders about to be published Dear Friends, In recent hours, our friends at Peace Now have learned from a highly reliable Israeli government official that the publication of the tender booklet/terms will take place by the end of this week. As many of you know, Givat Hamatos has long been considered a "doomsday" settlement, having major strategic ramifications on the very possibility of any future political agreement, and this publication will bring the scheme to the brink of implementation. The next 24 hours may prove to be critical to deter the Israeli government to proceed with the publication. Our detailed analysis of Givat Hamatos that we published on February 29, 2020 appears below. This is a brief summary of the current acute situation. 1. For decades, there has been a broad consensus in the international community that two Israeli settlement schemes - Givat Hamatos and E-1 - would have a devastating impact on any future political agreements (see the enclosed map). Throughout much of this period, there has been a coherent, focused and sustained international effort, cautioning Israel that this would meet broad and resolute international opposition. Those efforts have, until now, succeeded, and no Israeli Prime Minister, including Netanyahu, has dared take major steps towards implementation. 2. This began to change last February when Netanyahu, fighting for his political life, took steps towards implementation. -

Excluded, for God's Sake: Gender Segregation and the Exclusion of Women in Public Space in Israel
Excluded, For God’s Sake: Gender Segregation and the Exclusion of Women in Public Space in Israel המרכז הרפורמי לדת ומדינה -לוגו ללא מספר. Third Annual Report – December 2013 Israel Religious Action Center Israel Movement for Reform and Progressive Judaism Excluded, For God’s Sake: Gender Segregation and the Exclusion of Women in Public Space in Israel Third Annual Report – December 2013 Written by: Attorney Ruth Carmi, Attorney Ricky Shapira-Rosenberg Consultation: Attorney Einat Hurwitz, Attorney Orly Erez-Lahovsky English translation: Shaul Vardi Cover photo: Tomer Appelbaum, Haaretz, September 29, 2010 – © Haaretz Newspaper Ltd. © 2014 Israel Religious Action Center, Israel Movement for Reform and Progressive Judaism Israel Religious Action Center 13 King David St., P.O.B. 31936, Jerusalem 91319 Telephone: 02-6203323 | Fax: 03-6256260 www.irac.org | [email protected] Acknowledgement In loving memory of Dick England z"l, Sherry Levy-Reiner z"l, and Carole Chaiken z"l. May their memories be blessed. With special thanks to Loni Rush for her contribution to this report IRAC's work against gender segregation and the exclusion of women is made possible by the support of the following people and organizations: Kathryn Ames Foundation Claudia Bach Philip and Muriel Berman Foundation Bildstein Memorial Fund Jacob and Hilda Blaustein Foundation Inc. Donald and Carole Chaiken Foundation Isabel Dunst Naomi and Nehemiah Cohen Foundation Eugene J. Eder Charitable Foundation John and Noeleen Cohen Richard and Lois England Family Jay and Shoshana Dweck Foundation Foundation Lewis Eigen and Ramona Arnett Edith Everett Finchley Reform Synagogue, London Jim and Sue Klau Gold Family Foundation FJC- A Foundation of Philanthropic Funds Vicki and John Goldwyn Mark and Peachy Levy Robert Goodman & Jayne Lipman Joseph and Harvey Meyerhoff Family Richard and Lois Gunther Family Foundation Charitable Funds Richard and Barbara Harrison Yocheved Mintz (Dr. -

Ground to a Halt, Denial of Palestinians' Freedom Of
Since the beginning of the second intifada, in September 2000, Israel has imposed restrictions on the movement of Palestinians in the West Bank that are unprecedented in scope and duration. As a result, Palestinian freedom of movement, which was limited in any event, has turned from a fundamental human right to a privilege that Israel grants or withholds as it deems fit. The restrictions have made traveling from one section to another an exceptional occurrence, subject to various conditions and a showing of justification for the journey. Almost every trip in the West Bank entails a great loss of time, much uncertainty, friction with soldiers, and often substantial additional expense. The restrictions on movement that Israel has imposed on Palestinians in the West Bank have split the West Bank into six major geographical units: North, Central, South, the Jordan Valley and northern Dead Sea, the enclaves resulting from the Separation Barrier, and East Jerusalem. In addition to the restrictions on movement from area to area, Israel also severely restricts movement within each area by splitting them up into subsections, and by controlling and limiting movement between them. This geographic division of the West Bank greatly affects every aspect of Palestinian life. B’TSELEM - The Israeli Information Center for Human Rights in the Occupied Territories Ground to a Halt 8 Hata’asiya St., Talpiot P.O. Box 53132 Jerusalem 91531 Denial of Palestinians’ Freedom Tel. (972) 2-6735599 Fax. (972) 2-6749111 of Movement in the West Bank www.btselem.org • [email protected] August 2007 Ground to a Halt Denial of Palestinians’ Freedom of Movement in the West Bank August 2007 Stolen land is concrete, so here and there calls are heard to stop the building in settlements and not to expropriate land. -

The Upper Kidron Valley
Jerusalem Institute for Israel Studies Founded by the Charles H. Revson Foundation The Upper Kidron Valley Conservation and Development in the Visual Basin of the Old City of Jerusalem Editor: Israel Kimhi Jerusalem 2010 Jerusalem Institute for Israel Studies – Study No. 398 The Upper Kidron Valley Conservation and Development in the Visual Basin of the Old City of Jerusalem Editor: Israel Kimhi This publication was made possible thanks to the assistance of the Richard and Rhoda Goldman Fund, San Francisco. 7KHFRQWHQWRIWKLVGRFXPHQWUHÀHFWVWKHDXWKRUV¶RSLQLRQRQO\ Photographs: Maya Choshen, Israel Kimhi, and Flash 90 Linguistic editing (Hebrew): Shlomo Arad Production and printing: Hamutal Appel Pagination and design: Esti Boehm Translation: Sagir International Translations Ltd. © 2010, The Jerusalem Institute for Israel Studies Hay Elyachar House 20 Radak St., Jerusalem 92186 http://www.jiis.org E-mail: [email protected] Research Team Israel Kimhi – head of the team and editor of the report Eran Avni – infrastructures, public participation, tourism sites Amir Eidelman – geology Yair Assaf-Shapira – research, mapping, and geographical information systems Malka Greenberg-Raanan – physical planning, development of construction Maya Choshen – population and society Mike Turner – physical planning, development of construction, visual analysis, future development trends Muhamad Nakhal ±UHVLGHQWSDUWLFLSDWLRQKLVWRU\SUR¿OHRIWKH$UDEQHLJKERU- hoods Michal Korach – population and society Israel Kimhi – recommendations for future development, land uses, transport, planning Amnon Ramon – history, religions, sites for conservation Acknowledgments The research team thanks the residents of the Upper Kidron Valley and the Visual Basin of the Old City, and their representatives, for cooperating with the researchers during the course of the study and for their willingness to meet frequently with the team. -
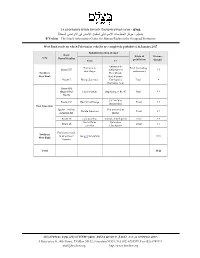
Forbidden Roads Table
בצלם - מרכז המידע הישראלי לזכויות האדם בשטחים (ע.ר.) بتسيلم - مركز المعلومات اﻹسرائيلي لحقوق اﻹنسان في اﻷراضي المحتلة B’Tselem – The Israeli Information Center for Human Rights in the Occupied Territories West Bank roads on which Palestinian vehicles are completely prohibited, 31 January 2017 Prohibited section of road Road Scope of Distance Area Name/Number prohibition From To (in km) Entrance to Entrance to Total (including Route 557 settlement of 3.9 Beit Dajan pedestrians) Northern Elon Moreh West Bank Kafr Kassem Route 5 Bruqin Junction Checkpoint, Total 4 the Green Line Route 404 (Begin Blvd. Har Hotzvim Beginning of Rt. 45 Total 5.8 North) Giv’at Ze’ev Route 443 Beit ‘Ur al-Fauqa Total 7.8 intersection East Jerusalem Qedar – Ma’ale Old entrance to Ma’ale Adumim Total 4.2 Adumim Rd. Qedar Route 60 Gilo Junction Tunnels Checkpoint Total 4.6 Giv’at Ze’ev Qalandiya Route 45 Total 3.2 Junction Checkpoint Prohibited roads Southern in downtown See p. 3 for details 6.72 West Bank Hebron Total 40.22 רחוב התעשייה 8, ת.ד. 53132, ירושלים 91531, טלפון 6735599 (02), פקס 6749111 (02) 8 Hata’asiya St. (4th Floor), P.O.Box 53132, Jerusalem 91531, Tel. (02) 6735599, Fax (02) 6749111 [email protected] http://www.btselem.org West Bank roads on which Palestinian vehicles are restricted, 31 January 2017 Prohibited section of road Road Scope of Distance Area Name/Number prohibition (in km) From To Jaljulye Checkpoint, 1 Route 55 The Green Line Partial 3.6 Central east of Qalqiliya West Bank 2 Route 466 Beit El Route 60 Partial 5.5 Giv’at Ze’ev/Neighborhood