Uvic Thesis Template
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Data Warehouse: an Integrated Decision Support Database Whose Content Is Derived from the Various Operational Databases
1 www.onlineeducation.bharatsevaksamaj.net www.bssskillmission.in DATABASE MANAGEMENT Topic Objective: At the end of this topic student will be able to: Understand the Contrasting basic concepts Understand the Database Server and Database Specified Understand the USER Clause Definition/Overview: Data: Stored representations of objects and events that have meaning and importance in the users environment. Information: Data that have been processed in such a way that they can increase the knowledge of the person who uses it. Metadata: Data that describes the properties or characteristics of end-user data and the context of that data. Database application: An application program (or set of related programs) that is used to perform a series of database activities (create, read, update, and delete) on behalf of database users. WWW.BSSVE.IN Data warehouse: An integrated decision support database whose content is derived from the various operational databases. Constraint: A rule that cannot be violated by database users. Database: An organized collection of logically related data. Entity: A person, place, object, event, or concept in the user environment about which the organization wishes to maintain data. Database management system: A software system that is used to create, maintain, and provide controlled access to user databases. www.bsscommunitycollege.in www.bssnewgeneration.in www.bsslifeskillscollege.in 2 www.onlineeducation.bharatsevaksamaj.net www.bssskillmission.in Data dependence; data independence: With data dependence, data descriptions are included with the application programs that use the data, while with data independence the data descriptions are separated from the application programs. Data warehouse; data mining: A data warehouse is an integrated decision support database, while data mining (described in the topic introduction) is the process of extracting useful information from databases. -

A Comparative Evaluation of Geospatial Semantic Web Frameworks for Cultural Heritage
heritage Article A Comparative Evaluation of Geospatial Semantic Web Frameworks for Cultural Heritage Ikrom Nishanbaev 1,* , Erik Champion 1,2,3 and David A. McMeekin 4,5 1 School of Media, Creative Arts, and Social Inquiry, Curtin University, Perth, WA 6845, Australia; [email protected] 2 Honorary Research Professor, CDHR, Sir Roland Wilson Building, 120 McCoy Circuit, Acton 2601, Australia 3 Honorary Research Fellow, School of Social Sciences, FABLE, University of Western Australia, 35 Stirling Highway, Perth, WA 6907, Australia 4 School of Earth and Planetary Sciences, Curtin University, Perth, WA 6845, Australia; [email protected] 5 School of Electrical Engineering, Computing and Mathematical Sciences, Curtin University, Perth, WA 6845, Australia * Correspondence: [email protected] Received: 14 July 2020; Accepted: 4 August 2020; Published: 12 August 2020 Abstract: Recently, many Resource Description Framework (RDF) data generation tools have been developed to convert geospatial and non-geospatial data into RDF data. Furthermore, there are several interlinking frameworks that find semantically equivalent geospatial resources in related RDF data sources. However, many existing Linked Open Data sources are currently sparsely interlinked. Also, many RDF generation and interlinking frameworks require a solid knowledge of Semantic Web and Geospatial Semantic Web concepts to successfully deploy them. This article comparatively evaluates features and functionality of the current state-of-the-art geospatial RDF generation tools and interlinking frameworks. This evaluation is specifically performed for cultural heritage researchers and professionals who have limited expertise in computer programming. Hence, a set of criteria has been defined to facilitate the selection of tools and frameworks. -

Knowledge Graphs on the Web – an Overview Arxiv:2003.00719V3 [Cs
January 2020 Knowledge Graphs on the Web – an Overview Nicolas HEIST, Sven HERTLING, Daniel RINGLER, and Heiko PAULHEIM Data and Web Science Group, University of Mannheim, Germany Abstract. Knowledge Graphs are an emerging form of knowledge representation. While Google coined the term Knowledge Graph first and promoted it as a means to improve their search results, they are used in many applications today. In a knowl- edge graph, entities in the real world and/or a business domain (e.g., people, places, or events) are represented as nodes, which are connected by edges representing the relations between those entities. While companies such as Google, Microsoft, and Facebook have their own, non-public knowledge graphs, there is also a larger body of publicly available knowledge graphs, such as DBpedia or Wikidata. In this chap- ter, we provide an overview and comparison of those publicly available knowledge graphs, and give insights into their contents, size, coverage, and overlap. Keywords. Knowledge Graph, Linked Data, Semantic Web, Profiling 1. Introduction Knowledge Graphs are increasingly used as means to represent knowledge. Due to their versatile means of representation, they can be used to integrate different heterogeneous data sources, both within as well as across organizations. [8,9] Besides such domain-specific knowledge graphs which are typically developed for specific domains and/or use cases, there are also public, cross-domain knowledge graphs encoding common knowledge, such as DBpedia, Wikidata, or YAGO. [33] Such knowl- edge graphs may be used, e.g., for automatically enriching data with background knowl- arXiv:2003.00719v3 [cs.AI] 12 Mar 2020 edge to be used in knowledge-intensive downstream applications. -

Bi-Directional Transformation Between Normalized Systems Elements and Domain Ontologies in OWL
Bi-directional Transformation between Normalized Systems Elements and Domain Ontologies in OWL Marek Suchanek´ 1 a, Herwig Mannaert2, Peter Uhnak´ 3 b and Robert Pergl1 c 1Faculty of Information Technology, Czech Technical University in Prague, Thakurova´ 9, Prague, Czech Republic 2Normalized Systems Institute, University of Antwerp, Prinsstraat 13, Antwerp, Belgium 3NSX bvba, Wetenschapspark Universiteit Antwerpen, Galileilaan 15, 2845 Niel, Belgium Keywords: Ontology, Normalized Systems, Transformation, Model-driven Development, Ontology Engineering, Software Modelling. Abstract: Knowledge representation in OWL ontologies gained a lot of popularity with the development of Big Data, Artificial Intelligence, Semantic Web, and Linked Open Data. OWL ontologies are very versatile, and there are many tools for analysis, design, documentation, and mapping. They can capture concepts and categories, their properties and relations. Normalized Systems (NS) provide a way of code generation from a model of so-called NS Elements resulting in an information system with proven evolvability. The model used in NS contains domain-specific knowledge that can be represented in an OWL ontology. This work clarifies the potential advantages of having OWL representation of the NS model, discusses the design of a bi-directional transformation between NS models and domain ontologies in OWL, and describes its implementation. It shows how the resulting ontology enables further work on the analytical level and leverages the system design. Moreover, due to the fact that NS metamodel is metacircular, the transformation can generate ontology of NS metamodel itself. It is expected that the results of this work will help with the design of larger real-world applications as well as the metamodel and that the transformation tool will be further extended with additional features which we proposed. -

A Survey and Classification of Controlled Natural Languages
A Survey and Classification of Controlled Natural Languages ∗ Tobias Kuhn ETH Zurich and University of Zurich What is here called controlled natural language (CNL) has traditionally been given many different names. Especially during the last four decades, a wide variety of such languages have been designed. They are applied to improve communication among humans, to improve translation, or to provide natural and intuitive representations for formal notations. Despite the apparent differences, it seems sensible to put all these languages under the same umbrella. To bring order to the variety of languages, a general classification scheme is presented here. A comprehensive survey of existing English-based CNLs is given, listing and describing 100 languages from 1930 until today. Classification of these languages reveals that they form a single scattered cloud filling the conceptual space between natural languages such as English on the one end and formal languages such as propositional logic on the other. The goal of this article is to provide a common terminology and a common model for CNL, to contribute to the understanding of their general nature, to provide a starting point for researchers interested in the area, and to help developers to make design decisions. 1. Introduction Controlled, processable, simplified, technical, structured,andbasic are just a few examples of attributes given to constructed languages of the type to be discussed here. We will call them controlled natural languages (CNL) or simply controlled languages.Basic English, Caterpillar Fundamental English, SBVR Structured English, and Attempto Controlled English are some examples; many more will be presented herein. This article investigates the nature of such languages, provides a general classification scheme, and explores existing approaches. -

A Conceptual Framework for Constructing Distributed Object Libraries Using Gellish
A Conceptual Framework for Constructing Distributed Object Libraries using Gellish Master's Thesis in Computer Science Michael Rudi Henrichs [email protected] Parallel and Distributed Systems group Faculty of Electrical Engineering, Mathematics and Computer Science Delft University of Technology June 1, 2009 Student Michael Rudi Henrichs Studentnumber: 9327103 Oranjelaan 8 2264 CW Leidschendam [email protected] MSc Presentation June 2, 2009 at 14:00 Lipkenszaal (LB 01.150), Faculty EWI, Mekelweg 4, Delft Committee Chair: Prof. Dr. Ir. H.J. Sips [email protected] Member: Dr. Ir. D.H.J. Epema [email protected] Member: Ir. N.W. Roest [email protected] Supervisor: Dr. K. van der Meer [email protected] Idoro B.V. Zonnebloem 52 2317 LM Leiden The Netherlands Parallel and Distributed Systems group Department of Software Technology Faculty of Electrical Engineering, Mathematics and Computer Science Delft University of Technology Mekelweg 4 2826 CD Delft The Netherlands www.ewi.tudelft.nl Sponsors: This master's thesis was typeset with MiKTEX 2.7, edited on TEXnicCenter 1 beta 7.50. Illustrations and diagrams were created using Microsoft Visio 2003 and Corel Paint Shop Pro 12.0. All running on an Acer Aspire 6930. Copyright c 2009 by Michael Henrichs, Idoro B.V. Cover photo and design by Michael Henrichs c 2009 http:nnphoto.lemantle.com All rights reserved. No part of the material protected by this copyright notice may be reproduced or utilized in any form or by any means, electronic or mechanical, including photocopying, recording or by any information storage and retrieval system, without the prior permission of the author. -

Data Models for Home Services
__________________________________________PROCEEDING OF THE 13TH CONFERENCE OF FRUCT ASSOCIATION Data Models for Home Services Vadym Kramar, Markku Korhonen, Yury Sergeev Oulu University of Applied Sciences, School of Engineering Raahe, Finland {vadym.kramar, markku.korhonen, yury.sergeev}@oamk.fi Abstract An ultimate penetration of communication technologies allowing web access has enriched a conception of smart homes with new paradigms of home services. Modern home services range far beyond such notions as Home Automation or Use of Internet. The services expose their ubiquitous nature by being integrated into smart environments, and provisioned through a variety of end-user devices. Computational intelligence require a use of knowledge technologies, and within a given domain, such requirement as a compliance with modern web architecture is essential. This is where Semantic Web technologies excel. A given work presents an overview of important terms, vocabularies, and data models that may be utilised in data and knowledge engineering with respect to home services. Index Terms: Context, Data engineering, Data models, Knowledge engineering, Semantic Web, Smart homes, Ubiquitous computing. I. INTRODUCTION In recent years, a use of Semantic Web technologies to build a giant information space has shown certain benefits. Rapid development of Web 3.0 and a use of its principle in web applications is the best evidence of such benefits. A traditional database design in still and will be widely used in web applications. One of the most important reason for that is a vast number of databases developed over years and used in a variety of applications varying from simple web services to enterprise portals. In accordance to Forrester Research though a growing number of document, or knowledge bases, such as NoSQL is not a hype anymore [1]. -

New Generation of Social Networks Based on Semantic Web Technologies: the Importance of Social Data Portability
Workshop on Adaptation and Personalization for Web 2.0, UMAP'09, June 22-26, 2009 New Generation of Social Networks Based on Semantic Web Technologies: the Importance of Social Data Portability Liana Razmerita1, Martynas Jusevičius2, Rokas Firantas2 Copenhagen Business School, Denmark1 IT University of Copenhagen, Copenhagen, Denmark2 [email protected], [email protected], [email protected] Abstract. This article investigates several well-known social network applications such as Last.fm, Flickr and identifies social data portability as one of the main technical issues that need to be addressed in the future. We argue that this issue can be addressed by building social networks as Semantic Web applications with FOAF, SIOC, and Linked Data technologies, and prove it by implementing a prototype application using Java and core Semantic Web standards. Furthermore, the developed prototype shows how features from semantic websites such as Freebase and DBpedia can be reused in social applications and lead to more relevant content and stronger social connections. 1 Introduction Social networking sites are developing at a very fast pace, attracting more and more users. Their application domain can be music sharing, photos sharing, videos sharing, bookmarks sharing, professional networks, and others. Despite their tremendous success social networking websites have a number of limitations that are identified and discussed within this article. Most of the social networking applications are “walled websites” and the “online communities are like islands in a sea”[1]. Lack of interoperability between data in different social networks applications limits access to relevant content available on different social networking sites, and limits the integration and reuse of available data and information. -

How Much Is a Triple? Estimating the Cost of Knowledge Graph Creation
How much is a Triple? Estimating the Cost of Knowledge Graph Creation Heiko Paulheim Data and Web Science Group, University of Mannheim, Germany [email protected] Abstract. Knowledge graphs are used in various applications and have been widely analyzed. A question that is not very well researched is: what is the price of their production? In this paper, we propose ways to estimate the cost of those knowledge graphs. We show that the cost of manually curating a triple is between $2 and $6, and that the cost for automatically created knowledge graphs is by a factor of 15 to 250 cheaper (i.e., 1g to 15g per statement). Furthermore, we advocate for taking cost into account as an evaluation metric, showing the correspon- dence between cost per triple and semantic validity as an example. Keywords: Knowledge Graphs, Cost Estimation, Automation 1 Estimating the Cost of Knowledge Graphs With the increasing attention larger scale knowledge graphs, such as DBpedia [5], YAGO [12] and the like, have drawn towards themselves, they have been inspected under various angles, such as as size, overlap [11], or quality [3]. How- ever, one dimension that is underrepresented in those analyses is cost, i.e., the prize of creating the knowledge graphs. 1.1 Manual Curation: Cyc and Freebase For manually created knowledge graphs, we have to estimate the effort of pro- viding the statements directly. Cyc [6] is one of the earliest general purpose knowledge graphs, and, at the same time, the one for which the development effort is known. At a 2017 con- ference, Douglas Lenat, the inventor of Cyc, denoted the cost of creation of Cyc at $120M.1 In the same presentation, Lenat states that Cyc consists of 21M assertions, which makes a cost of $5.71 per statement. -

Universidad Carlos III De Madrid Escuela Politécnica Superior
Universidad Carlos III de Madrid Escuela Politécnica Superior Ingeniería en Informática Proyecto Fin de Carrera DISEÑO DE UN MUNDO VIRTUAL PARA LA ENSEÑANZA DE ARQUITECTURA SOFTWARE Autor: Verónica Casado Manzanero Tutor: Anabel Fraga Vázquez Diciembre, 2009 DISEÑO DE UN MUNDO VIRTUAL PARA LA ENSEÑANZA DE ARQUITECTURA SOFTWARE Agradecimientos En primer lugar querría dar las gracias a mis padres, por su apoyo, comprensión, generosidad, por darme todo lo que necesito y más, y sobre todo, por enseñarme a ser como soy y servirme de ejemplo para convertirme en mejor persona cada día. También me gustaría recordar a mi hermana por ayudarme siempre en lo he necesitado con esa gran dosis de paciencia que sé que ha de tener. A mis amigas Carol y Raquel, por permanecer siempre a mi lado a pesar de estar semanas sin vernos. A mi novio Marcos, por pasarme esa paciencia y tranquilidad suya que tanto aprecio, por apoyarme en todo momento, por creer en mí y por permanecer a mi lado durante estos seis largos años. Por último, agradecerle a mi tutora Anabel toda la ayuda prestada, tanto en las asignaturas como en este proyecto. Gracias a su inestimable ayuda y entusiasmo he podido completar con éxito el trabajo aquí propuesto. Ha sido un verdadero placer trabajar con ella. Verónica Casado Manzanero 3/254 Universidad Carlos III de Madrid DISEÑO DE UN MUNDO VIRTUAL PARA LA ENSEÑANZA DE ARQUITECTURA SOFTWARE Verónica Casado Manzanero 4/254 Universidad Carlos III de Madrid DISEÑO DE UN MUNDO VIRTUAL PARA LA ENSEÑANZA DE ARQUITECTURA SOFTWARE Contenido 1. Introducción y motivación ......................................................................................... -
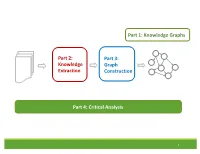
Knowledge Extraction Part 3: Graph
Part 1: Knowledge Graphs Part 2: Part 3: Knowledge Graph Extraction Construction Part 4: Critical Analysis 1 Tutorial Outline 1. Knowledge Graph Primer [Jay] 2. Knowledge Extraction from Text a. NLP Fundamentals [Sameer] b. Information Extraction [Bhavana] Coffee Break 3. Knowledge Graph Construction a. Probabilistic Models [Jay] b. Embedding Techniques [Sameer] 4. Critical Overview and Conclusion [Bhavana] 2 Critical Overview SUMMARY SUCCESS STORIES DATASETS, TASKS, SOFTWARES EXCITING ACTIVE RESEARCH FUTURE RESEARCH DIRECTIONS 3 Critical Overview SUMMARY SUCCESS STORIES DATASETS, TASKS, SOFTWARES EXCITING ACTIVE RESEARCH FUTURE RESEARCH DIRECTIONS 4 Why do we need Knowledge graphs? • Humans can explore large database in intuitive ways •AI agents get access to human common sense knowledge 5 Knowledge graph construction A1 E1 • Who are the entities A2 (nodes) in the graph? • What are their attributes E2 and types (labels)? A1 A2 • How are they related E3 (edges)? A1 A2 6 Knowledge Graph Construction Knowledge Extraction Graph Knowledge Text Extraction graph Construction graph 7 Two perspectives Extraction graph Knowledge graph Who are the entities? (nodes) What are their attributes? (labels) How are they related? (edges) 8 Two perspectives Extraction graph Knowledge graph Who are the entities? • Named Entity • Entity Linking (nodes) Recognition • Entity Resolution • Entity Coreference What are their • Entity Typing • Collective attributes? (labels) classification How are they related? • Semantic role • Link prediction (edges) labeling • Relation Extraction 9 Knowledge Extraction John was born in Liverpool, to Julia and Alfred Lennon. Text NLP Lennon.. Mrs. Lennon.. his father John Lennon... the Pool .. his mother .. he Alfred Person Location Person Person John was born in Liverpool, to Julia and Alfred Lennon. -

Ontology Languages – a Review
International Journal of Computer Theory and Engineering, Vol.2, No.6, December, 2010 1793-8201 Ontology Languages – A Review V. Maniraj, Dr.R. Sivakumar 1) Logical Languages Abstract—Ontologies have been becoming a hot research • First order predicate logic topic for the application in artificial intelligence, semantic web, Software Engineering, Library Science and information • Rule based logic Architecture. Ontology is a formal representation of set of concepts within a domain and relationships between those • concepts. It is used to reason about the properties of that Description logic domain and may be used to define the domain. An ontology language is a formal language used to encode the ontologies. A 2) Frame based Languages number of research languages have been designed and released • Similar to relational databases during the past few years by the research community. They are both proprietary and standard based. In this paper a study has 3) Graph based Languages been reported on the different features and issues of these • languages. This paper also addresses the challenges for Semantic network research community in the further development of ontology languages. • Analogy with the web is rationale for the semantic web I. INTRODUCTION Ontology engineering (or ontology building) is a subfield II. BACKGROUND of knowledge engineering that studies the methods and CycL1 in computer science and artificial intelligence is an methodologies for building ontologies. It studies the ontology language used by Doug Lenat’s Cye artificial ontology development process, the ontology life cycle, the intelligence project. Ramanathan V. Guna was instrumental methods and methodologies for building ontologies, and the in the design of the language.