Kapitola: the Connection Between the Iterated Logarithm and the Inverse Ackermann Function
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Introduction to Dependence Relations and Their Links to Algebraic Hyperstructures
mathematics Article Introduction to Dependence Relations and Their Links to Algebraic Hyperstructures Irina Cristea 1,* , Juš Kocijan 1,2 and Michal Novák 3 1 Centre for Information Technologies and Applied Mathematics, University of Nova Gorica, 5000 Nova Gorica, Slovenia; [email protected] 2 Department of Systems and Control, Jožef Stefan Institut, Jamova Cesta 39, 1000 Ljubljana, Slovenia 3 Faculty of Electrical Engineering and Communication, Brno University of Technology, Technická 10, 61600 Brno, Czech Republic; [email protected] * Correspondence: [email protected] or [email protected]; Tel.: +386-533-153-95 Received: 11 July 2019; Accepted: 19 September 2019; Published: 23 September 2019 Abstract: The aim of this paper is to study, from an algebraic point of view, the properties of interdependencies between sets of elements (i.e., pieces of secrets, atmospheric variables, etc.) that appear in various natural models, by using the algebraic hyperstructure theory. Starting from specific examples, we first define the relation of dependence and study its properties, and then, we construct various hyperoperations based on this relation. We prove that two of the associated hypergroupoids are Hv-groups, while the other two are, in some particular cases, only partial hypergroupoids. Besides, the extensivity and idempotence property are studied and related to the cyclicity. The second goal of our paper is to provide a new interpretation of the dependence relation by using elements of the theory of algebraic hyperstructures. Keywords: hyperoperation; hypergroupoid; dependence relation; influence; impact 1. Introduction In many real-life situations, there are contexts with numerous “variables”, which somehow depend on one another. -

Large but Finite
Department of Mathematics MathClub@WMU Michigan Epsilon Chapter of Pi Mu Epsilon Large but Finite Drake Olejniczak Department of Mathematics, WMU What is the biggest number you can imagine? Did you think of a million? a billion? a septillion? Perhaps you remembered back to the time you heard the term googol or its show-off of an older brother googolplex. Or maybe you thought of infinity. No. Surely, `infinity' is cheating. Large, finite numbers, truly monstrous numbers, arise in several areas of mathematics as well as in astronomy and computer science. For instance, Euclid defined perfect numbers as positive integers that are equal to the sum of their proper divisors. He is also credited with the discovery of the first four perfect numbers: 6, 28, 496, 8128. It may be surprising to hear that the ninth perfect number already has 37 digits, or that the thirteenth perfect number vastly exceeds the number of particles in the observable universe. However, the sequence of perfect numbers pales in comparison to some other sequences in terms of growth rate. In this talk, we will explore examples of large numbers such as Graham's number, Rayo's number, and the limits of the universe. As well, we will encounter some fast-growing sequences and functions such as the TREE sequence, the busy beaver function, and the Ackermann function. Through this, we will uncover a structure on which to compare these concepts and, hopefully, gain a sense of what it means for a number to be truly large. 4 p.m. Friday October 12 6625 Everett Tower, WMU Main Campus All are welcome! http://www.wmich.edu/mathclub/ Questions? Contact Patrick Bennett ([email protected]) . -

Grade 7/8 Math Circles the Scale of Numbers Introduction
Faculty of Mathematics Centre for Education in Waterloo, Ontario N2L 3G1 Mathematics and Computing Grade 7/8 Math Circles November 21/22/23, 2017 The Scale of Numbers Introduction Last week we quickly took a look at scientific notation, which is one way we can write down really big numbers. We can also use scientific notation to write very small numbers. 1 × 103 = 1; 000 1 × 102 = 100 1 × 101 = 10 1 × 100 = 1 1 × 10−1 = 0:1 1 × 10−2 = 0:01 1 × 10−3 = 0:001 As you can see above, every time the value of the exponent decreases, the number gets smaller by a factor of 10. This pattern continues even into negative exponent values! Another way of picturing negative exponents is as a division by a positive exponent. 1 10−6 = = 0:000001 106 In this lesson we will be looking at some famous, interesting, or important small numbers, and begin slowly working our way up to the biggest numbers ever used in mathematics! Obviously we can come up with any arbitrary number that is either extremely small or extremely large, but the purpose of this lesson is to only look at numbers with some kind of mathematical or scientific significance. 1 Extremely Small Numbers 1. Zero • Zero or `0' is the number that represents nothingness. It is the number with the smallest magnitude. • Zero only began being used as a number around the year 500. Before this, ancient mathematicians struggled with the concept of `nothing' being `something'. 2. Planck's Constant This is the smallest number that we will be looking at today other than zero. -
Power Towers and the Tetration of Numbers
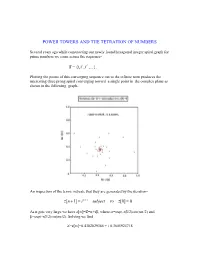
POWER TOWERS AND THE TETRATION OF NUMBERS Several years ago while constructing our newly found hexagonal integer spiral graph for prime numbers we came across the sequence- i S {i,i i ,i i ,...}, Plotting the points of this converging sequence out to the infinite term produces the interesting three prong spiral converging toward a single point in the complex plane as shown in the following graph- An inspection of the terms indicate that they are generated by the iteration- z[n 1] i z[n] subject to z[0] 0 As n gets very large we have z[]=Z=+i, where =exp(-/2)cos(/2) and =exp(-/2)sin(/2). Solving we find – Z=z[]=0.4382829366 + i 0.3605924718 It is the purpose of the present article to generalize the above result to any complex number z=a+ib by looking at the general iterative form- z[n+1]=(a+ib)z[n] subject to z[0]=1 Here N=a+ib with a and b being real numbers which are not necessarily integers. Such an iteration represents essentially a tetration of the number N. That is, its value up through the nth iteration, produces the power tower- Z Z n Z Z Z with n-1 zs in the exponents Thus- 22 4 2 22 216 65536 Note that the evaluation of the powers is from the top down and so is not equivalent to the bottom up operation 44=256. Also it is clear that the sequence {1 2,2 2,3 2,4 2,...}diverges very rapidly unlike the earlier case {1i,2 i,3i,4i,...} which clearly converges. -

Parameter Free Induction and Provably Total Computable Functions
Parameter free induction and provably total computable functions Lev D. Beklemishev∗ Steklov Mathematical Institute Gubkina 8, 117966 Moscow, Russia e-mail: [email protected] November 20, 1997 Abstract We give a precise characterization of parameter free Σn and Πn in- − − duction schemata, IΣn and IΠn , in terms of reflection principles. This I − I − allows us to show that Πn+1 is conservative over Σn w.r.t. boolean com- binations of Σn+1 sentences, for n ≥ 1. In particular, we give a positive I − answer to a question, whether the provably recursive functions of Π2 are exactly the primitive recursive ones. We also characterize the provably − recursive functions of theories of the form IΣn + IΠn+1 in terms of the fast growing hierarchy. For n = 1 the corresponding class coincides with the doubly-recursive functions of Peter. We also obtain sharp results on the strength of bounded number of instances of parameter free induction in terms of iterated reflection. Keywords: parameter free induction, provably recursive functions, re- flection principles, fast growing hierarchy Mathematics Subject Classification: 03F30, 03D20 1 Introduction In this paper we shall deal with the first order theories containing Kalmar ele- mentary arithmetic EA or, equivalently, I∆0 + Exp (cf. [11]). We are interested in the general question how various ways of formal reasoning correspond to models of computation. This kind of analysis is traditionally based on the con- cept of provably total recursive function (p.t.r.f.) of a theory. Given a theory T containing EA, a function f(~x) is called provably total recursive in T , iff there is a Σ1 formula φ(~x, y), sometimes called specification, that defines the graph of f in the standard model of arithmetic and such that T ⊢ ∀~x∃!y φ(~x, y). -

Categorical Comprehensions and Recursion Arxiv:1501.06889V2
Categorical Comprehensions and Recursion Joaquín Díaz Boilsa,∗ aFacultad de Ciencias Exactas y Naturales. Pontificia Universidad Católica del Ecuador. 170150. Quito. Ecuador. Abstract A new categorical setting is defined in order to characterize the subrecursive classes belonging to complexity hierarchies. This is achieved by means of coer- cion functors over a symmetric monoidal category endowed with certain recur- sion schemes that imitate the bounded recursion scheme. This gives a categorical counterpart of generalized safe composition and safe recursion. Keywords: Symmetric Monoidal Category, Safe Recursion, Ramified Recursion. 1. Introduction Various recursive function classes have been characterized in categorical terms. It has been achieved by considering a category with certain structure endowed with a recursion scheme. The class of Primitive Recursive Functions (PR in the sequel), for instance, has been chased simply by means of a carte- sian category and a Natural Numbers Object with parameters (nno in the sequel, see [11]). In [13] it can be found a generalization of that characterization to a monoidal setting, that is achieved by endowing a monoidal category with a spe- cial kind of nno (a left nno) where the tensor product is included. It is also known that other classes containing PR can be obtained by adding more struc- ture: considering for instance a topos ([8]), a cartesian closed category ([14]) or a category with finite limits ([12]).1 Less work has been made, however, on categorical characterizations of sub- arXiv:1501.06889v2 [math.CT] 28 Jan 2015 recursive function classes, that is, those contained in PR (see [4] and [5]). In PR there is at least a sequence of functions such that every function in it has a more complex growth than the preceding function in the sequence. -

Attributes of Infinity
International Journal of Applied Physics and Mathematics Attributes of Infinity Kiamran Radjabli* Utilicast, La Jolla, California, USA. * Corresponding author. Email: [email protected] Manuscript submitted May 15, 2016; accepted October 14, 2016. doi: 10.17706/ijapm.2017.7.1.42-48 Abstract: The concept of infinity is analyzed with an objective to establish different infinity levels. It is proposed to distinguish layers of infinity using the diverging functions and series, which transform finite numbers to infinite domain. Hyper-operations of iterated exponentiation establish major orders of infinity. It is proposed to characterize the infinity by three attributes: order, class, and analytic value. In the first order of infinity, the infinity class is assessed based on the “analytic convergence” of the Riemann zeta function. Arithmetic operations in infinity are introduced and the results of the operations are associated with the infinity attributes. Key words: Infinity, class, order, surreal numbers, divergence, zeta function, hyperpower function, tetration, pentation. 1. Introduction Traditionally, the abstract concept of infinity has been used to generically designate any extremely large result that cannot be measured or determined. However, modern mathematics attempts to introduce new concepts to address the properties of infinite numbers and operations with infinities. The system of hyperreal numbers [1], [2] is one of the approaches to define infinite and infinitesimal quantities. The hyperreals (a.k.a. nonstandard reals) *R, are an extension of the real numbers R that contains numbers greater than anything of the form 1 + 1 + … + 1, which is infinite number, and its reciprocal is infinitesimal. Also, the set theory expands the concept of infinity with introduction of various orders of infinity using ordinal numbers. -

Primality Testing for Beginners
STUDENT MATHEMATICAL LIBRARY Volume 70 Primality Testing for Beginners Lasse Rempe-Gillen Rebecca Waldecker http://dx.doi.org/10.1090/stml/070 Primality Testing for Beginners STUDENT MATHEMATICAL LIBRARY Volume 70 Primality Testing for Beginners Lasse Rempe-Gillen Rebecca Waldecker American Mathematical Society Providence, Rhode Island Editorial Board Satyan L. Devadoss John Stillwell Gerald B. Folland (Chair) Serge Tabachnikov The cover illustration is a variant of the Sieve of Eratosthenes (Sec- tion 1.5), showing the integers from 1 to 2704 colored by the number of their prime factors, including repeats. The illustration was created us- ing MATLAB. The back cover shows a phase plot of the Riemann zeta function (see Appendix A), which appears courtesy of Elias Wegert (www.visual.wegert.com). 2010 Mathematics Subject Classification. Primary 11-01, 11-02, 11Axx, 11Y11, 11Y16. For additional information and updates on this book, visit www.ams.org/bookpages/stml-70 Library of Congress Cataloging-in-Publication Data Rempe-Gillen, Lasse, 1978– author. [Primzahltests f¨ur Einsteiger. English] Primality testing for beginners / Lasse Rempe-Gillen, Rebecca Waldecker. pages cm. — (Student mathematical library ; volume 70) Translation of: Primzahltests f¨ur Einsteiger : Zahlentheorie - Algorithmik - Kryptographie. Includes bibliographical references and index. ISBN 978-0-8218-9883-3 (alk. paper) 1. Number theory. I. Waldecker, Rebecca, 1979– author. II. Title. QA241.R45813 2014 512.72—dc23 2013032423 Copying and reprinting. Individual readers of this publication, and nonprofit libraries acting for them, are permitted to make fair use of the material, such as to copy a chapter for use in teaching or research. Permission is granted to quote brief passages from this publication in reviews, provided the customary acknowledgment of the source is given. -

Upper and Lower Bounds on Continuous-Time Computation
Upper and lower bounds on continuous-time computation Manuel Lameiras Campagnolo1 and Cristopher Moore2,3,4 1 D.M./I.S.A., Universidade T´ecnica de Lisboa, Tapada da Ajuda, 1349-017 Lisboa, Portugal [email protected] 2 Computer Science Department, University of New Mexico, Albuquerque NM 87131 [email protected] 3 Physics and Astronomy Department, University of New Mexico, Albuquerque NM 87131 4 Santa Fe Institute, 1399 Hyde Park Road, Santa Fe, New Mexico 87501 Abstract. We consider various extensions and modifications of Shannon’s General Purpose Analog Com- puter, which is a model of computation by differential equations in continuous time. We show that several classical computation classes have natural analog counterparts, including the primitive recursive functions, the elementary functions, the levels of the Grzegorczyk hierarchy, and the arithmetical and analytical hierarchies. Key words: Continuous-time computation, differential equations, recursion theory, dynamical systems, elementary func- tions, Grzegorczyk hierarchy, primitive recursive functions, computable functions, arithmetical and analytical hierarchies. 1 Introduction The theory of analog computation, where the internal states of a computer are continuous rather than discrete, has enjoyed a recent resurgence of interest. This stems partly from a wider program of exploring alternative approaches to computation, such as quantum and DNA computation; partly as an idealization of numerical algorithms where real numbers can be thought of as quantities in themselves, rather than as strings of digits; and partly from a desire to use the tools of computation theory to better classify the variety of continuous dynamical systems we see in the world (or at least in its classical idealization). -

The Notion Of" Unimaginable Numbers" in Computational Number Theory
Beyond Knuth’s notation for “Unimaginable Numbers” within computational number theory Antonino Leonardis1 - Gianfranco d’Atri2 - Fabio Caldarola3 1 Department of Mathematics and Computer Science, University of Calabria Arcavacata di Rende, Italy e-mail: [email protected] 2 Department of Mathematics and Computer Science, University of Calabria Arcavacata di Rende, Italy 3 Department of Mathematics and Computer Science, University of Calabria Arcavacata di Rende, Italy e-mail: [email protected] Abstract Literature considers under the name unimaginable numbers any positive in- teger going beyond any physical application, with this being more of a vague description of what we are talking about rather than an actual mathemati- cal definition (it is indeed used in many sources without a proper definition). This simply means that research in this topic must always consider shortened representations, usually involving recursion, to even being able to describe such numbers. One of the most known methodologies to conceive such numbers is using hyper-operations, that is a sequence of binary functions defined recursively starting from the usual chain: addition - multiplication - exponentiation. arXiv:1901.05372v2 [cs.LO] 12 Mar 2019 The most important notations to represent such hyper-operations have been considered by Knuth, Goodstein, Ackermann and Conway as described in this work’s introduction. Within this work we will give an axiomatic setup for this topic, and then try to find on one hand other ways to represent unimaginable numbers, as well as on the other hand applications to computer science, where the algorith- mic nature of representations and the increased computation capabilities of 1 computers give the perfect field to develop further the topic, exploring some possibilities to effectively operate with such big numbers. -

Hyperoperations and Nopt Structures
Hyperoperations and Nopt Structures Alister Wilson Abstract (Beta version) The concept of formal power towers by analogy to formal power series is introduced. Bracketing patterns for combining hyperoperations are pictured. Nopt structures are introduced by reference to Nept structures. Briefly speaking, Nept structures are a notation that help picturing the seed(m)-Ackermann number sequence by reference to exponential function and multitudinous nestings thereof. A systematic structure is observed and described. Keywords: Large numbers, formal power towers, Nopt structures. 1 Contents i Acknowledgements 3 ii List of Figures and Tables 3 I Introduction 4 II Philosophical Considerations 5 III Bracketing patterns and hyperoperations 8 3.1 Some Examples 8 3.2 Top-down versus bottom-up 9 3.3 Bracketing patterns and binary operations 10 3.4 Bracketing patterns with exponentiation and tetration 12 3.5 Bracketing and 4 consecutive hyperoperations 15 3.6 A quick look at the start of the Grzegorczyk hierarchy 17 3.7 Reconsidering top-down and bottom-up 18 IV Nopt Structures 20 4.1 Introduction to Nept and Nopt structures 20 4.2 Defining Nopts from Nepts 21 4.3 Seed Values: “n” and “theta ) n” 24 4.4 A method for generating Nopt structures 25 4.5 Magnitude inequalities inside Nopt structures 32 V Applying Nopt Structures 33 5.1 The gi-sequence and g-subscript towers 33 5.2 Nopt structures and Conway chained arrows 35 VI Glossary 39 VII Further Reading and Weblinks 42 2 i Acknowledgements I’d like to express my gratitude to Wikipedia for supplying an enormous range of high quality mathematics articles. -

I Jornada De Investigación Sistemas.Pdf
ISBN: 978-9942-9902-6-6 1 1 Copyright: Dirección de Investigación de la Pontificia Universidad Católica del Ecuador Sede Esmeraldas, prohibida la reproducción total o parcial de este libro por ningún medio impreso o electrónico sin el permiso previo y por escrito del dueño del copyright. PONTIFICIA UNIVERSIDAD CATÓLICA DEL ECUADOR SEDE ESMERALDAS Dirección: Espejo y subida a Santa Cruz Casilla: 08-01-0065 Teléfonos: +593 (06) 2721983 – 2721595 Email: [email protected] www.pucese.edu.ec ESMERALDAS - ECUADOR PUBLICACIÓN ELECTRÓNICA ISBN: 978-9942-9902-6-6 Los artículos incluidos en esta publicación fueron sometidos a procedimientos de admisión y revisión por pares, llevados a cabo por un comité científico nacional e internacional de alto nivel. 2 La simulación en ingeniería, transcendiendo fronteras Coordinador de la Carrera de Sistemas y Computación Víctor Xavier Quiñonez Ku Director de Investigación PUCE Esmeraldas Ignacio Carazo Ortega Comité Organizador Víctor Xavier Quiñonez Ku Jaime Paúl Sayago Heredia Luis Alberto Herrera Izquierdo Comité Editorial Pablo Antonio Pico Valencia, Universidad de Granada – España Evelin Lorena Flores García, Universidad de Almería – España Cesar Raúl García Jacas, Universidad Nacional Autónoma de México José Luis Sampietro Saquicela, Universidad de Barcelona – España Luis Dionicio Rosales Romero, Universidad de los Andes – Venezuela Juan Luis Casierra Cavada, Pontificia Universidad Católica del Ecuador Pedro Roberto Suarez Suri, Pontificia Universidad Católica del Ecuador Víctor Xavier Quiñonez