Melissa Mogensen History of Mathematics History of Linear
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Lesson 2: the Multiplication of Polynomials
NYS COMMON CORE MATHEMATICS CURRICULUM Lesson 2 M1 ALGEBRA II Lesson 2: The Multiplication of Polynomials Student Outcomes . Students develop the distributive property for application to polynomial multiplication. Students connect multiplication of polynomials with multiplication of multi-digit integers. Lesson Notes This lesson begins to address standards A-SSE.A.2 and A-APR.C.4 directly and provides opportunities for students to practice MP.7 and MP.8. The work is scaffolded to allow students to discern patterns in repeated calculations, leading to some general polynomial identities that are explored further in the remaining lessons of this module. As in the last lesson, if students struggle with this lesson, they may need to review concepts covered in previous grades, such as: The connection between area properties and the distributive property: Grade 7, Module 6, Lesson 21. Introduction to the table method of multiplying polynomials: Algebra I, Module 1, Lesson 9. Multiplying polynomials (in the context of quadratics): Algebra I, Module 4, Lessons 1 and 2. Since division is the inverse operation of multiplication, it is important to make sure that your students understand how to multiply polynomials before moving on to division of polynomials in Lesson 3 of this module. In Lesson 3, division is explored using the reverse tabular method, so it is important for students to work through the table diagrams in this lesson to prepare them for the upcoming work. There continues to be a sharp distinction in this curriculum between justification and proof, such as justifying the identity (푎 + 푏)2 = 푎2 + 2푎푏 + 푏 using area properties and proving the identity using the distributive property. -

Things You Need to Know About Linear Algebra Math 131 Multivariate
the standard (x; y; z) coordinate three-space. Nota- tions for vectors. Geometric interpretation as vec- tors as displacements as well as vectors as points. Vector addition, the zero vector 0, vector subtrac- Things you need to know about tion, scalar multiplication, their properties, and linear algebra their geometric interpretation. Math 131 Multivariate Calculus We start using these concepts right away. In D Joyce, Spring 2014 chapter 2, we'll begin our study of vector-valued functions, and we'll use the coordinates, vector no- The relation between linear algebra and mul- tation, and the rest of the topics reviewed in this tivariate calculus. We'll spend the first few section. meetings reviewing linear algebra. We'll look at just about everything in chapter 1. Section 1.2. Vectors and equations in R3. Stan- Linear algebra is the study of linear trans- dard basis vectors i; j; k in R3. Parametric equa- formations (also called linear functions) from n- tions for lines. Symmetric form equations for a line dimensional space to m-dimensional space, where in R3. Parametric equations for curves x : R ! R2 m is usually equal to n, and that's often 2 or 3. in the plane, where x(t) = (x(t); y(t)). A linear transformation f : Rn ! Rm is one that We'll use standard basis vectors throughout the preserves addition and scalar multiplication, that course, beginning with chapter 2. We'll study tan- is, f(a + b) = f(a) + f(b), and f(ca) = cf(a). We'll gent lines of curves and tangent planes of surfaces generally use bold face for vectors and for vector- in that chapter and throughout the course. -

Algorithmic Factorization of Polynomials Over Number Fields
Rose-Hulman Institute of Technology Rose-Hulman Scholar Mathematical Sciences Technical Reports (MSTR) Mathematics 5-18-2017 Algorithmic Factorization of Polynomials over Number Fields Christian Schulz Rose-Hulman Institute of Technology Follow this and additional works at: https://scholar.rose-hulman.edu/math_mstr Part of the Number Theory Commons, and the Theory and Algorithms Commons Recommended Citation Schulz, Christian, "Algorithmic Factorization of Polynomials over Number Fields" (2017). Mathematical Sciences Technical Reports (MSTR). 163. https://scholar.rose-hulman.edu/math_mstr/163 This Dissertation is brought to you for free and open access by the Mathematics at Rose-Hulman Scholar. It has been accepted for inclusion in Mathematical Sciences Technical Reports (MSTR) by an authorized administrator of Rose-Hulman Scholar. For more information, please contact [email protected]. Algorithmic Factorization of Polynomials over Number Fields Christian Schulz May 18, 2017 Abstract The problem of exact polynomial factorization, in other words expressing a poly- nomial as a product of irreducible polynomials over some field, has applications in algebraic number theory. Although some algorithms for factorization over algebraic number fields are known, few are taught such general algorithms, as their use is mainly as part of the code of various computer algebra systems. This thesis provides a summary of one such algorithm, which the author has also fully implemented at https://github.com/Whirligig231/number-field-factorization, along with an analysis of the runtime of this algorithm. Let k be the product of the degrees of the adjoined elements used to form the algebraic number field in question, let s be the sum of the squares of these degrees, and let d be the degree of the polynomial to be factored; then the runtime of this algorithm is found to be O(d4sk2 + 2dd3). -

Schaum's Outline of Linear Algebra (4Th Edition)
SCHAUM’S SCHAUM’S outlines outlines Linear Algebra Fourth Edition Seymour Lipschutz, Ph.D. Temple University Marc Lars Lipson, Ph.D. University of Virginia Schaum’s Outline Series New York Chicago San Francisco Lisbon London Madrid Mexico City Milan New Delhi San Juan Seoul Singapore Sydney Toronto Copyright © 2009, 2001, 1991, 1968 by The McGraw-Hill Companies, Inc. All rights reserved. Except as permitted under the United States Copyright Act of 1976, no part of this publication may be reproduced or distributed in any form or by any means, or stored in a database or retrieval system, without the prior writ- ten permission of the publisher. ISBN: 978-0-07-154353-8 MHID: 0-07-154353-8 The material in this eBook also appears in the print version of this title: ISBN: 978-0-07-154352-1, MHID: 0-07-154352-X. All trademarks are trademarks of their respective owners. Rather than put a trademark symbol after every occurrence of a trademarked name, we use names in an editorial fashion only, and to the benefit of the trademark owner, with no intention of infringement of the trademark. Where such designations appear in this book, they have been printed with initial caps. McGraw-Hill eBooks are available at special quantity discounts to use as premiums and sales promotions, or for use in corporate training programs. To contact a representative please e-mail us at [email protected]. TERMS OF USE This is a copyrighted work and The McGraw-Hill Companies, Inc. (“McGraw-Hill”) and its licensors reserve all rights in and to the work. -
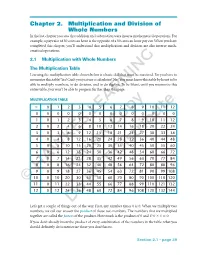
Chapter 2. Multiplication and Division of Whole Numbers in the Last Chapter You Saw That Addition and Subtraction Were Inverse Mathematical Operations
Chapter 2. Multiplication and Division of Whole Numbers In the last chapter you saw that addition and subtraction were inverse mathematical operations. For example, a pay raise of 50 cents an hour is the opposite of a 50 cents an hour pay cut. When you have completed this chapter, you’ll understand that multiplication and division are also inverse math- ematical operations. 2.1 Multiplication with Whole Numbers The Multiplication Table Learning the multiplication table shown below is a basic skill that must be mastered. Do you have to memorize this table? Yes! Can’t you just use a calculator? No! You must know this table by heart to be able to multiply numbers, to do division, and to do algebra. To be blunt, until you memorize this entire table, you won’t be able to progress further than this page. MULTIPLICATION TABLE ϫ 012 345 67 89101112 0 000 000LEARNING 00 000 00 1 012 345 67 89101112 2 024 681012Copy14 16 18 20 22 24 3 036 9121518212427303336 4 0481216 20 24 28 32 36 40 44 48 5051015202530354045505560 6061218243036424854606672Distribute 7071421283542495663707784 8081624324048566472808896 90918273HAWKESReview645546372819099108 10 0 10 20 30 40 50 60 70 80 90 100 110 120 ©11 0 11 22 33 44NOT 55 66 77 88 99 110 121 132 12 0 12 24 36 48 60 72 84 96 108 120 132 144 Do Let’s get a couple of things out of the way. First, any number times 0 is 0. When we multiply two numbers, we call our answer the product of those two numbers. -

Grade 7/8 Math Circles the Scale of Numbers Introduction
Faculty of Mathematics Centre for Education in Waterloo, Ontario N2L 3G1 Mathematics and Computing Grade 7/8 Math Circles November 21/22/23, 2017 The Scale of Numbers Introduction Last week we quickly took a look at scientific notation, which is one way we can write down really big numbers. We can also use scientific notation to write very small numbers. 1 × 103 = 1; 000 1 × 102 = 100 1 × 101 = 10 1 × 100 = 1 1 × 10−1 = 0:1 1 × 10−2 = 0:01 1 × 10−3 = 0:001 As you can see above, every time the value of the exponent decreases, the number gets smaller by a factor of 10. This pattern continues even into negative exponent values! Another way of picturing negative exponents is as a division by a positive exponent. 1 10−6 = = 0:000001 106 In this lesson we will be looking at some famous, interesting, or important small numbers, and begin slowly working our way up to the biggest numbers ever used in mathematics! Obviously we can come up with any arbitrary number that is either extremely small or extremely large, but the purpose of this lesson is to only look at numbers with some kind of mathematical or scientific significance. 1 Extremely Small Numbers 1. Zero • Zero or `0' is the number that represents nothingness. It is the number with the smallest magnitude. • Zero only began being used as a number around the year 500. Before this, ancient mathematicians struggled with the concept of `nothing' being `something'. 2. Planck's Constant This is the smallest number that we will be looking at today other than zero. -

Determinants Math 122 Calculus III D Joyce, Fall 2012
Determinants Math 122 Calculus III D Joyce, Fall 2012 What they are. A determinant is a value associated to a square array of numbers, that square array being called a square matrix. For example, here are determinants of a general 2 × 2 matrix and a general 3 × 3 matrix. a b = ad − bc: c d a b c d e f = aei + bfg + cdh − ceg − afh − bdi: g h i The determinant of a matrix A is usually denoted jAj or det (A). You can think of the rows of the determinant as being vectors. For the 3×3 matrix above, the vectors are u = (a; b; c), v = (d; e; f), and w = (g; h; i). Then the determinant is a value associated to n vectors in Rn. There's a general definition for n×n determinants. It's a particular signed sum of products of n entries in the matrix where each product is of one entry in each row and column. The two ways you can choose one entry in each row and column of the 2 × 2 matrix give you the two products ad and bc. There are six ways of chosing one entry in each row and column in a 3 × 3 matrix, and generally, there are n! ways in an n × n matrix. Thus, the determinant of a 4 × 4 matrix is the signed sum of 24, which is 4!, terms. In this general definition, half the terms are taken positively and half negatively. In class, we briefly saw how the signs are determined by permutations. -

Span, Linear Independence and Basis Rank and Nullity
Remarks for Exam 2 in Linear Algebra Span, linear independence and basis The span of a set of vectors is the set of all linear combinations of the vectors. A set of vectors is linearly independent if the only solution to c1v1 + ::: + ckvk = 0 is ci = 0 for all i. Given a set of vectors, you can determine if they are linearly independent by writing the vectors as the columns of the matrix A, and solving Ax = 0. If there are any non-zero solutions, then the vectors are linearly dependent. If the only solution is x = 0, then they are linearly independent. A basis for a subspace S of Rn is a set of vectors that spans S and is linearly independent. There are many bases, but every basis must have exactly k = dim(S) vectors. A spanning set in S must contain at least k vectors, and a linearly independent set in S can contain at most k vectors. A spanning set in S with exactly k vectors is a basis. A linearly independent set in S with exactly k vectors is a basis. Rank and nullity The span of the rows of matrix A is the row space of A. The span of the columns of A is the column space C(A). The row and column spaces always have the same dimension, called the rank of A. Let r = rank(A). Then r is the maximal number of linearly independent row vectors, and the maximal number of linearly independent column vectors. So if r < n then the columns are linearly dependent; if r < m then the rows are linearly dependent. -

Subclass Discriminant Nonnegative Matrix Factorization for Facial Image Analysis
Pattern Recognition 45 (2012) 4080–4091 Contents lists available at SciVerse ScienceDirect Pattern Recognition journal homepage: www.elsevier.com/locate/pr Subclass discriminant Nonnegative Matrix Factorization for facial image analysis Symeon Nikitidis b,a, Anastasios Tefas b, Nikos Nikolaidis b,a, Ioannis Pitas b,a,n a Informatics and Telematics Institute, Center for Research and Technology, Hellas, Greece b Department of Informatics, Aristotle University of Thessaloniki, Greece article info abstract Article history: Nonnegative Matrix Factorization (NMF) is among the most popular subspace methods, widely used in Received 4 October 2011 a variety of image processing problems. Recently, a discriminant NMF method that incorporates Linear Received in revised form Discriminant Analysis inspired criteria has been proposed, which achieves an efficient decomposition of 21 March 2012 the provided data to its discriminant parts, thus enhancing classification performance. However, this Accepted 26 April 2012 approach possesses certain limitations, since it assumes that the underlying data distribution is Available online 16 May 2012 unimodal, which is often unrealistic. To remedy this limitation, we regard that data inside each class Keywords: have a multimodal distribution, thus forming clusters and use criteria inspired by Clustering based Nonnegative Matrix Factorization Discriminant Analysis. The proposed method incorporates appropriate discriminant constraints in the Subclass discriminant analysis NMF decomposition cost function in order to address the problem of finding discriminant projections Multiplicative updates that enhance class separability in the reduced dimensional projection space, while taking into account Facial expression recognition Face recognition subclass information. The developed algorithm has been applied for both facial expression and face recognition on three popular databases. -

The Notion Of" Unimaginable Numbers" in Computational Number Theory
Beyond Knuth’s notation for “Unimaginable Numbers” within computational number theory Antonino Leonardis1 - Gianfranco d’Atri2 - Fabio Caldarola3 1 Department of Mathematics and Computer Science, University of Calabria Arcavacata di Rende, Italy e-mail: [email protected] 2 Department of Mathematics and Computer Science, University of Calabria Arcavacata di Rende, Italy 3 Department of Mathematics and Computer Science, University of Calabria Arcavacata di Rende, Italy e-mail: [email protected] Abstract Literature considers under the name unimaginable numbers any positive in- teger going beyond any physical application, with this being more of a vague description of what we are talking about rather than an actual mathemati- cal definition (it is indeed used in many sources without a proper definition). This simply means that research in this topic must always consider shortened representations, usually involving recursion, to even being able to describe such numbers. One of the most known methodologies to conceive such numbers is using hyper-operations, that is a sequence of binary functions defined recursively starting from the usual chain: addition - multiplication - exponentiation. arXiv:1901.05372v2 [cs.LO] 12 Mar 2019 The most important notations to represent such hyper-operations have been considered by Knuth, Goodstein, Ackermann and Conway as described in this work’s introduction. Within this work we will give an axiomatic setup for this topic, and then try to find on one hand other ways to represent unimaginable numbers, as well as on the other hand applications to computer science, where the algorith- mic nature of representations and the increased computation capabilities of 1 computers give the perfect field to develop further the topic, exploring some possibilities to effectively operate with such big numbers. -

Multiplication Fact Strategies Assessment Directions and Analysis
Multiplication Fact Strategies Wichita Public Schools Curriculum and Instructional Design Mathematics Revised 2014 KCCRS version Table of Contents Introduction Page Research Connections (Strategies) 3 Making Meaning for Operations 7 Assessment 9 Tools 13 Doubles 23 Fives 31 Zeroes and Ones 35 Strategy Focus Review 41 Tens 45 Nines 48 Squared Numbers 54 Strategy Focus Review 59 Double and Double Again 64 Double and One More Set 69 Half and Then Double 74 Strategy Focus Review 80 Related Equations (fact families) 82 Practice and Review 92 Wichita Public Schools 2014 2 Research Connections Where Do Fact Strategies Fit In? Adapted from Randall Charles Fact strategies are considered a crucial second phase in a three-phase program for teaching students basic math facts. The first phase is concept learning. Here, the goal is for students to understand the meanings of multiplication and division. In this phase, students focus on actions (i.e. “groups of”, “equal parts”, “building arrays”) that relate to multiplication and division concepts. An important instructional bridge that is often neglected between concept learning and memorization is the second phase, fact strategies. There are two goals in this phase. First, students need to recognize there are clusters of multiplication and division facts that relate in certain ways. Second, students need to understand those relationships. These lessons are designed to assist with the second phase of this process. If you have students that are not ready, you will need to address the first phase of concept learning. The third phase is memorization of the basic facts. Here the goal is for students to master products and quotients so they can recall them efficiently and accurately, and retain them over time. -

MATH 532: Linear Algebra Chapter 4: Vector Spaces
MATH 532: Linear Algebra Chapter 4: Vector Spaces Greg Fasshauer Department of Applied Mathematics Illinois Institute of Technology Spring 2015 [email protected] MATH 532 1 Outline 1 Spaces and Subspaces 2 Four Fundamental Subspaces 3 Linear Independence 4 Bases and Dimension 5 More About Rank 6 Classical Least Squares 7 Kriging as best linear unbiased predictor [email protected] MATH 532 2 Spaces and Subspaces Outline 1 Spaces and Subspaces 2 Four Fundamental Subspaces 3 Linear Independence 4 Bases and Dimension 5 More About Rank 6 Classical Least Squares 7 Kriging as best linear unbiased predictor [email protected] MATH 532 3 Spaces and Subspaces Spaces and Subspaces While the discussion of vector spaces can be rather dry and abstract, they are an essential tool for describing the world we work in, and to understand many practically relevant consequences. After all, linear algebra is pretty much the workhorse of modern applied mathematics. Moreover, many concepts we discuss now for traditional “vectors” apply also to vector spaces of functions, which form the foundation of functional analysis. [email protected] MATH 532 4 Spaces and Subspaces Vector Space Definition A set V of elements (vectors) is called a vector space (or linear space) over the scalar field F if (A1) x + y 2 V for any x; y 2 V (M1) αx 2 V for every α 2 F and (closed under addition), x 2 V (closed under scalar (A2) (x + y) + z = x + (y + z) for all multiplication), x; y; z 2 V, (M2) (αβ)x = α(βx) for all αβ 2 F, (A3) x + y = y + x for all x; y 2 V, x 2 V, (A4) There exists a zero vector 0 2 V (M3) α(x + y) = αx + αy for all α 2 F, such that x + 0 = x for every x; y 2 V, x 2 V, (M4) (α + β)x = αx + βx for all (A5) For every x 2 V there is a α; β 2 F, x 2 V, negative (−x) 2 V such that (M5)1 x = x for all x 2 V.