Time Series Modeling for Dream Team in Fantasy Premier League
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Date: 21 May 2017 Opposition: Middlesbrough Competition: League
Date: 21 May 2017 Times Telegraph Echo May2017 21 Opposition: Middlesbrough Guardian Mirror Gazette Competition: League Independent Mail BBC United fan who used to hang out with George Best. Klopp was marching onto the pitch, repeatedly thumping the Liverpool crest on his chest as Anfield's heartbeat Chest-beating Klopp puts Liverpool back among European elite quickened at the prospect of Champions League football again. RATINGS Liverpool (4-4-2): S Mignolet 7 -- N Clyne 6, J Matip 6, D Lovren 6, J Liverpool 3 Wijnaldum 45+1, Coutinho 51 Lallana 56 Middlesbrough 0 Milner 7 (sub: A Moreno 86min) -- E Can 7, G Wijnaldum 7, P Coutinho 8, A Lallana Referee M Atkinson Attendance 53,191 7 -- D Sturridge 6 (sub: D Origi 82), R Firmino 7 (sub: L Leiva 79). Substitutes not It was shortly after Middlesbrough's feisty fans tried to goad used L Karius, M Grujic, T Alexander-Arnold, R Klavan. Middlesbrough (4-5-1): B their Liverpool counterparts with "Champions League, you're having a laugh" that Guzan 4 -- F Da Silva 5 (sub: D Ayala 73), C Chambers 5, B Gibson 5, G Friend 6 -- P Georginio Wijnaldum struck his sixth, and most important, Premier League goal of Bamford 6, A Clayton 5, G Leadbitter 5, A Forshaw 5, S Downing 5 -- R Gestede 6 the season. Wijnaldum's cathartic contribution meant so much and, with the (sub: A Negredo 73). Substitutes not used D Konstantopoulos, Bernardo, V tension eased, Philippe Coutinho and Adam Lallana wrapped up qualification for Fischer, M De Roon, C Stuani. -

The 21St Barclays Premier League
SEASON 2012/2013 ISSUE One BarcLays Premier League BarcLays Premier League BarcLays Premier League race for the goLden Boot race for the goLden gLove statistics 2011/12 Player (Team) Goals Player (Team) Clean Sheets The Player With The Most........ Robin van Persie (Arsenal) 30 Joe Hart (Man City) 17 Shots On Target Wayne Rooney (Man Utd) 27 Tim Krul (Newcastle) 15 Robin van Persie (Arsenal) 104 Sergio Aguero (Man City) 23 Brad Friedel (Tottenham) 14 Shots Off Target Ayegbeni Yakubu (Blackburn) 17 Michel Vorm (Swansea) 14 Robin van Persie (Arsenal) 58 Clint Dempsey (Fulham) 17 Wojciech Szczesny (Arsenal) 13 Shots Without Scoring Stewart Downing (Liverpool) 64 Shots Per Goal Welcome to the 21st Adel Taarabt (QPR) 42 Assists David Silva (Man City) 17 Barclays Premier League Offsides Emmanuel Adebayor (Tottenham) 51 he 21st season of the Barclays Premier League Fouls Tgets under way and Marouane Fellaini (Everton) 85 another campaign of twists Fouls Without A Card and turns, high drama and D Graham (Swansea), D Silva (Man City) 21 controversy is sure to follow. Manchester City, still buzzing Free-Kicks Won from the final-day elation of last Jonas Gutierrez (Newcastle) 82 May, begin their defence of the Penalties Scored title by hosting Southampton Wayne Rooney (Man Utd) 6 at the Etihad Stadium. Roberto Mancini’s side will Goals Scored Direct From Free-Kicks be under even more pressure Sebastian Larsson (Sunderland) 3 to deliver silverware this Saves Made time around while the game have more to prove than Andre dugout for the first time Wayne Hennessey (Wolverhampton) 223 represents a return to the top Villas-Boas at Tottenham. -

SPORTS 2424 Monday, March 20, 2017 United on the up As Fellaini
Griezmann lifts P23 Atletico SPORTS 2424 Monday, March 20, 2017 United on the up as Fellaini strikes Manchester United’s Marouane Fellaini (L) celebrates with teammates Middlesbrough Replays showed there was no they took a deserved 30th minute lead Ashley Young cut in from the left contest with a stunning double save arouane Fellaini scored his contact as the pair engaged in an through Fellaini. to send over a searching cross to the to keep out a point-blank Marcus first Premier League goal for angry clinch, but punches appeared The Belgian international midfielder far post, and as Valdes and former Rashford effort from Juan Mata’s 15M months as Manchester United to be thrown afterwards in the players had scored his previous league goal Manchester United defender Fabio cross, before recovering to block the extended their unbeaten Premier tunnel a both sides left the pitch. in a 2-1 defeat at Bournemouth in hesitated, Fellaini was left with the follow-up from Valencia. League run to 18 games to move up to United were last beaten in the December 2015, but had few problems simple task of heading the ball into an fifth with a 3-1 victory at relegation- league at the end of October, a record in ending that barren run with his unguarded net from close range. Astute threatened Middlesbrough yesterday. which rarely looked under threat once third goal of the season. Valdes had kept his side in the The former Barcelona keeper had Jesse Lingard added a stunning already denied Rashford with a fine second and Antonio Valencia block after the forward out-paced his a stoppage-time third after an marker Bernardo to Valencia’s astute embarrassing mistake by former through-ball. -

Intermediary Transactions 2019-20 1.9MB
24/06/2020 01/03/2019AFC Bournemouth David Robert Brooks AFC Bournemouth Updated registration Unique Sports Management IMSC000239 Player, Registering Club No 04/04/2019AFC Bournemouth Matthew David Butcher AFC Bournemouth Updated registration Midas Sports Management Ltd IMSC000039 Player, Registering Club No 20/05/2019 AFC Bournemouth Lloyd Casius Kelly Bristol City FC Permanent transfer Stellar Football Limited IMSC000059 Player, Registering Club No 01/08/2019 AFC Bournemouth Arnaut Danjuma Groeneveld Club Brugge NV Permanent transfer Jeroen Hoogewerf IMS000672 Player, Registering Club No 29/07/2019AFC Bournemouth Philip Anyanwu Billing Huddersfield Town FC Permanent transfer Neil Fewings IMS000214 Player, Registering Club No 29/07/2019AFC Bournemouth Philip Anyanwu Billing Huddersfield Town FC Permanent transfer Base Soccer Agency Ltd. IMSC000058 Former Club No 07/08/2019 AFC Bournemouth Harry Wilson Liverpool FC Premier league loan Base Soccer Agency Ltd. IMSC000058 Player, Registering Club No 07/08/2019 AFC Bournemouth Harry Wilson Liverpool FC Premier league loan Nicola Wilson IMS004337 Player Yes 07/08/2019 AFC Bournemouth Harry Wilson Liverpool FC Premier league loan David Threlfall IMS000884 Former Club No 08/07/2019 AFC Bournemouth Jack William Stacey Luton Town Permanent transfer Unique Sports Management IMSC000239 Player, Registering Club No 24/05/2019AFC Bournemouth Mikael Bongili Ndjoli AFC Bournemouth Updated registration Tamas Byrne IMS000208 Player, Registering Club No 26/04/2019AFC Bournemouth Steve Anthony Cook AFC Bournemouth -

Answers Round 1 Q1 Tom Henning Ovebro. Q2 Pokemon – More
Answers Round 1 Q1 Tom Henning Ovebro. Q2 Pokemon – more than at any other London football ground. Q3 Danny Blanchflower 16%. Q4 Avram Grant 67%. Mourinho across both stints 63%. Hiddink 73% first, 53% across both/. Q5 True – Grand Royal. Aung Moe Kyaw, chairman, said: 'Our Grand Royal brand shares the same winning spirit demonstrated by Chelsea FC, making this partnership a perfect fit.' Q6 Tony Cascarino (1993-94). Q7 SW6 1HS Q8 Kevin Hitchcock – 247 times, playing only four. Q9 Eden Hazard, John Terry, Branislav Ivanovic. Q10 1994 FA Cup final record 'No One Can Stop Us Now'. Round 2 Q1 #NotOnMyWatch Q2 Jimmy Floyd Hasselbaink (12 out of 12). Q3 Oxford United, Swindon Town and Exeter City. Q4 A power failure. Q5 Oscar dos Santos Emboaba Junior. Q6 Canada. Q7 Graphite and tangerine. Q8 True (entered into the official register in April this year). Q9 A1 (a) Arms – Guy Thill born with one arm. One player did wear glasses. Q10 Darlington. Round 3 Q1 Zilina (of Slovakia). Q2 Glossop (9-2 in 1906/07). Q3 John Terry. Q4 West 13,422. (East 10,889, Matthew Harding 10,770, Shed 6,550). Q5 Ruud Gullit. Q6 P3, W2, D1, L0. (CWC final & replay 1971, Super Cup 1998). Q7 Roberto Di Matteo (1997), Louis Saha (for Everton 2009). Q8 Jimmy Greaves, 41 in 1960-61. Q9 As a mark of respect for, and so as not to clash with, Mowcow Dynamo's blue shirts. Q10 18th (in 1983). Round 4 Q1 Orient (6,009). Q2 Liverpool (a 4-0 friendly win). -

2015 Topps Premier Gold Soccer Checklist
BASE BASE CARDS 1 Artur Boruc AFC Bournemouth 2 Tommy Elphick AFC Bournemouth 3 Marc Pugh AFC Bournemouth 4 Harry Arter AFC Bournemouth 5 Matt Ritchie AFC Bournemouth 6 Max Gradel AFC Bournemouth 7 Callum Wilson AFC Bournemouth 8 Theo Walcott Arsenal 9 Laurent Koscielny Arsenal 10 Mikel Arteta Arsenal 11 Aaron Ramsey Arsenal 12 Santi Cazorla Arsenal 13 Mesut Ozil Arsenal 14 Alexis Sanchez Arsenal 15 Olivier Giroud Arsenal 16 Bradley Guzan Aston Villa 17 Jordan Amavi Aston Villa 18 Micah Richards Aston Villa 19 Idrissa Gueye Aston Villa 20 Jack Grealish Aston Villa 21 Gabriel Agbonlahor Aston Villa 22 Rudy Gestede Aston Villa 23 Thibaut Courtois Chelsea 24 Branislav Ivanovic Chelsea 25 John Terry Chelsea 26 Nemanja Matic Chelsea 27 Eden Hazard Chelsea 28 Cesc Fabregas Chelsea 29 Radamel Falcao Chelsea 30 Diego Costa Chelsea 31 Julian Speroni Crystal Palace 32 Scott Dann Crystal Palace 33 Joel Ward Crystal Palace 34 Jason Puncheon Crystal Palace 35 Yannick Bolasie Crystal Palace 36 Mile Jedinak Crystal Palace 37 Wilfried Zaha Crystal Palace 38 Connor Wickham Crystal Palace 39 Tim Howard Everton 40 Leighton Baines Everton 41 Seamus Coleman Everton 42 Phil Jagielka Everton 43 Ross Barkley Everton 44 John Stones Everton 45 Romelu Lukaku Everton 46 Kasper Schmeichel Leicester City 47 Wes Morgan Leicester City 48 Robert Huth Leicester City 49 Riyad Mahrez Leicester City 50 Jeff Schlupp Leicester City 51 Shinji Okazaki Leicester City 52 Jamie Vardy Leicester City 53 Simon Mignolet Liverpool FC 54 Martin Skrtel Liverpool FC 55 Nathaniel Clyne Liverpool -

2016 Panini Flawless Soccer Cards Checklist
Card Set Number Player Base 1 Keisuke Honda Base 2 Riccardo Montolivo Base 3 Antoine Griezmann Base 4 Fernando Torres Base 5 Koke Base 6 Ilkay Gundogan Base 7 Marco Reus Base 8 Mats Hummels Base 9 Pierre-Emerick Aubameyang Base 10 Shinji Kagawa Base 11 Andres Iniesta Base 12 Dani Alves Base 13 Lionel Messi Base 14 Luis Suarez Base 15 Neymar Jr. Base 16 Arjen Robben Base 17 Arturo Vidal Base 18 Franck Ribery Base 19 Manuel Neuer Base 20 Thomas Muller Base 21 Fernando Muslera Base 22 Wesley Sneijder Base 23 David Luiz Base 24 Edinson Cavani Base 25 Marco Verratti Base 26 Thiago Silva Base 27 Zlatan Ibrahimovic Base 28 Cristiano Ronaldo Base 29 Gareth Bale Base 30 Keylor Navas Base 31 James Rodriguez Base 32 Raphael Varane Base 33 Karim Benzema Base 34 Axel Witsel Base 35 Ezequiel Garay Base 36 Hulk Base 37 Angel Di Maria Base 38 Gonzalo Higuain Base 39 Javier Mascherano Base 40 Lionel Messi Base 41 Pablo Zabaleta Base 42 Sergio Aguero Base 43 Eden Hazard Base 44 Jan Vertonghen Base 45 Marouane Fellaini Base 46 Romelu Lukaku Base 47 Thibaut Courtois Base 48 Vincent Kompany Base 49 Edin Dzeko Base 50 Dani Alves Base 51 David Luiz Base 52 Kaka Base 53 Neymar Jr. Base 54 Thiago Silva Base 55 Alexis Sanchez Base 56 Arturo Vidal Base 57 Claudio Bravo Base 58 James Rodriguez Base 59 Radamel Falcao Base 60 Ivan Rakitic Base 61 Luka Modric Base 62 Mario Mandzukic Base 63 Gary Cahill Base 64 Joe Hart Base 65 Raheem Sterling Base 66 Wayne Rooney Base 67 Hugo Lloris Base 68 Morgan Schneiderlin Base 69 Olivier Giroud Base 70 Patrice Evra Base 71 Paul -

2019-20 2020 Panini Select UEFA Euro Hobby Soccer Checklist
2019-20 Select UEFA Euro Soccer Checklist Hobby Green = Autographs and Relics; 21 Countries (all have hits except Finland) Player Set Card # Country Print Run David Alaba Auto - Select Signatures 20 Austria David Alaba Auto - Select Signatures Parallels 20 Austria 135 Marc Janko Auto - Historical Significance 7 Austria Marc Janko Auto - Historical Significance Parallels 7 Austria 135 Marko Arnautovic Relic - Select Stars 7 Austria Marko Arnautovic Relic - Select Stars Parallels 7 Austria 101 Marko Arnautovic Relic - Triumph 10 Austria Marko Arnautovic Relic - Triumph Parallels 10 Austria 101 Aleksandar Dragovic Base Set - Terrace 95 Austria Cican Stankovic Base Set - Field Level 257 Austria David Alaba Base Set - Mezzanine 101 Austria David Alaba Base Set - Mezzanine Color Variation 101 Austria David Alaba Insert - Top of the Class 20 Austria Florian Grillitsch Base Set - Field Level 177 Austria Julian Baumgartlinger Base Set - Terrace 97 Austria Marcel Sabitzer Base Set - Terrace 98 Austria Marcel Sabitzer Insert - Equalizers 1 Austria Marcel Sabitzer Insert - Visionary 21 Austria Marko Arnautovic Base Set - Terrace 100 Austria Martin Hinteregger Base Set - Terrace 96 Austria Michael Gregoritsch Base Set - Field Level 217 Austria None Insert - Squads Team Logo 1 Austria None Insert - Team Crests 1 Austria Stefan Ilsanker Base Set - Terrace 99 Austria Stefan Lainer Base Set - Field Level 237 Austria Stefan Posch Base Set - Field Level 197 Austria Valentino Lazaro Base Set - Terrace 94 Austria Valentino Lazaro Insert - Visionary 22 Austria -
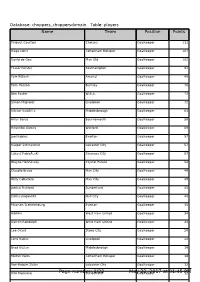
Page Number: 1/22 May 22, 2017 at 01:45 PM
Database: choppers_choppersdomain, Table: players Name Name Team Team PositionPosition PointsPoints Thibaut Courtois Chelsea Goalkeeper 111 Hugo Lloris Tottenham Hotspur Goalkeeper 107 David de Gea Man Utd Goalkeeper 102 Fraser Forster Southampton Goalkeeper 91 Petr ÄŒech Arsenal Goalkeeper 88 Tom Heaton Burnley Goalkeeper 76 Ben Foster W.B.A. Goalkeeper 73 Simon Mignolet Liverpool Goalkeeper 72 VÃctor Valdés Middlesbrough Goalkeeper 63 Artur Boruc Bournemouth Goalkeeper 58 Heurelho Gomes Watford Goalkeeper 58 Joel Robles Everton Goalkeeper 57 Kasper Schmeichel Leicester City Goalkeeper 57 Lukasz FabiaÅ„ski Swansea City Goalkeeper 57 Wayne Hennessey Crystal Palace Goalkeeper 54 Claudio Bravo Man City Goalkeeper 49 Willy Caballero Man City Goalkeeper 49 Jordan Pickford Sunderland Goalkeeper 45 Eldin Jakupović Hull City Goalkeeper 40 Maarten Stekelenburg Everton Goalkeeper 35 Adrián West Ham United Goalkeeper 34 Darren Randolph West Ham United Goalkeeper 34 Lee Grant Stoke City Goalkeeper 28 Loris Karius Liverpool Goalkeeper 24 Brad Guzan Middlesbrough Goalkeeper 19 Michel Vorm Tottenham Hotspur Goalkeeper 16 Ron-Robert Zieler Leicester City Goalkeeper 12 Vito Mannone Page number:Sunderland 1/22 MayGoalkeeper 22, 2017 at 01:45 PM12 Database: choppers_choppersdomain, Table: players Name Name Team Team PositionPosition PointsPoints Jack Butland Stoke City Goalkeeper 11 Sergio Romero Man Utd Goalkeeper 10 Steve Mandanda Crystal Palace Goalkeeper 10 Adam Federici Bournemouth Goalkeeper 4 David Marshall Hull City Goalkeeper 3 Paul Robinson Burnley Goalkeeper 2 Kristoffer Nordfeldt Swansea City Goalkeeper 2 David Ospina Arsenal Goalkeeper 1 Asmir Begovic Chelsea Goalkeeper 1 Wojciech SzczÄ™sny Arsenal Goalkeeper 0 Alex McCarthy Southampton Goalkeeper 0 Allan McGregor Hull City Goalkeeper 0 Danny Ward Liverpool Goalkeeper 0 Joe Hart Man City Goalkeeper 0 Dimitrios Konstantopoulos Middlesbrough Goalkeeper 0 Paulo Gazzaniga Southampton Goalkeeper 0 Jakob Haugaard Stoke City Goalkeeper 0 Boaz Myhill W.B.A. -

Dutch Pro Academy Training Sessions Vol 1
This ebook has been licensed to: Bob Hansen ([email protected]) If you are not Bob Hansen please destroy this copy and contact WORLD CLASS COACHING. This ebook has been licensed to: Bob Hansen ([email protected]) Dutch Pro Academy Training Sessions Vol 1 By Dan Brown Published by WORLD CLASS COACHING If you are not Bob Hansen please destroy this copy and contact WORLD CLASS COACHING. This ebook has been licensed to: Bob Hansen ([email protected]) First published September, 2019 by WORLD CLASS COACHING 3404 W. 122nd Leawood, KS 66209 (913) 402-0030 Copyright © WORLD CLASS COACHING 2019 All rights reserved. No parts of this publication may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording or otherwise, without prior written permission of the publisher. Author – Dan Brown Edited by Tom Mura Front Cover Design – Barrie Bee Dutch Pro Academy Training Sessions I 1 ©WORLD CLASS COACHING If you are not Bob Hansen please destroy this copy and contact WORLD CLASS COACHING. This ebook has been licensed to: Bob Hansen ([email protected]) Table of Contents 3 Overview and Itinerary 8 Opening Presentation with Harry Jensen, KNVB 10 Notes from Visit to ESA Arnhem Rijkerswoerd Youth Club 12 Schalke ’04 Stadium and Training Complex Tour 13 Ajax Background 16 Training Session with Harry Jensen, KNVB 19 Training Session with Joost van Elden, Trekvogels FC 22 Ajax Youth Team Sessions 31 Ajax U13 Goalkeeper Training 34 Ajax Reserve Game & Attacking Tendencies Dutch Pro Academy Training Sessions I 2 ©WORLD CLASS COACHING If you are not Bob Hansen please destroy this copy and contact WORLD CLASS COACHING. -

Premier League: the Championship: Revansjejakt I Hovedstaden Ny Spenning I Tet Side 10 Side 14 INNHOLD Tipsuken
ÅRGANG 73 // TIRSDAG 23. JUNI 2020 // NR. 25 LØSSALG KR 80,– SIDE 3-7 SIDE ALARMENUsle ett poeng fra første to runder fikk alarmen til å dure i GÅRRosenborg-garderoben. Denne ukens møter med Glimt og Brann vil kunne definere trøndernes sesong. Premier League: The Championship: Revansjejakt i hovedstaden Ny spenning i tet Side 10 Side 14 INNHOLD Tipsuken .....................................................2 Norge Eliteserien .....................................3-7 Tipsbladet-duellen .....................................9 England Premier League .....................10-13 England The Championship ...............14-17 Liganytt .....................................................19 Tyskland Bundesliga ...........................20-22 Italia Serie A .........................................23-27 Spania La Liga ......................................28-33 Danmark Superligaen .........................34-36 Sverige Allsvenskan .............................38-40 Ukens TV-liste ......................................42-73 Tipsfondet............................................44-45 Midtukekupongen ....................................46 Lørdagskupongen ....................................47 Søndagskupongen ...................................48 Resultater.............................................49-63 Feriemodus Premier League-fotballen startet opp var Everton som kom nærmest med igjen forrige uke, men det ble på ingen en enorm dobbeltsjanse mot slutten. måte en eksplosjon av underholdning. At det etterlengtede ligagullet fortsatt Kanskje hadde -

Middlesbrough Awarded Efl Community Club of the Year at House of Commons Showcase
MFC FOUNDAT ION OFFICIAL NEWSLETTER SUMMER 2018 www.mfcfoundation.co.uk OF PRO FOUNDATION TO HOST THIRD ANNUAL CHARITY DINNER MIDDLESBROUGH AWARDED EFL COMMUNITY CLUB OF THE YEAR AT HOUSE OF COMMONS SHOWCASE MFC Foundation were delighted to accept “Every project we witnessed has made Middlesbrough Football Club Foundation is Middlesbrough FC’s EFL Checkatrade North such a tremendous impact in their delighted to announce the date of their East & Yorkshire Community Club of the respective regions, and to be a part of this third annual charity dinner at Rockliffe Hall Year Award at the showcase event at the celebration today was truly humbling. Hotel & Spa. House of Commons in London. “Stepping Up has gone from strength to Held in the Rockliffe Suite, the black tie The awards are designed to recognise the strength since the programme was event is taking place on March 1st 2019, best performing club community trusts implemented, as we have continued to and will celebrate the 22-year history of around the country, as well as some of the expand our reach to other areas of MFC Foundation, the official charitable arm key individuals associated to the projects, Teesside. of Middlesbrough FC. whether that be in a participating or coaching capacity. The dinner will boast fine dining and exquisite service at one of the North East’s Following an application process open to most prestigious country venues. all 72 EFL clubs, Blackburn Rovers, Portsmouth, Charlton Athletic, Bristol City, Following the fantastic success of previous Derby County and Middlesbrough were all years’ dinner, March’s event will look back celebrated for their innovative and ground- at some of the highlights of 2018 at MFC breaking work across many areas over the Foundation, and the fantastic work done to past year.