Download Vol 7, No 1&2, Year 2014
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Winamp "Classic" 2.81: * Updated to PP's Latest Input and Output Plugins * in Mp3 Now Doesnt Continue to Play on Output Plugin Error
Winamp "Classic" 2.81: * updated to PP's latest input and output plugins * in_mp3 now doesnt continue to play on output plugin error. * smaller installers because we use msvcrt.dll now * fixed bugs relating to files with ~ in their names. * doublerightclick in credits makes for fullscreen credits * more bugfixes (including a fix in the version update notification checking) * updated installer to have nicer error messages. * made systray icon update if explorer restarts * and more (muahaha)! Winamp 2.80: * fixed drag&drop from open file dialog related bugs * made CDDB support better handle notfound CDs/lack of CDDB installed. * update to CDDB ui (bugfix) * new splash screen * minibrowser security fix * updated winamp agent to support both winamp 2.x and 3.x * included PP's hacks for slightly better unicode filename support * in_wave support for floating point .WAV files fixed * better win9x compatibility for DirectSound * waveOut made skip less * some in_mod perfile fixes * OGG Vorbis support for Standard and Full installs. * CD support back in lite installer. Winamp 2.79: * upgraded unzip/decompress support to zlib 1.1.4, for big security fix * improved multiple instance detection code/opening many files from explorer iss ues * winamp agent tooltip improvement * fix to id3v2+unicode support Winamp 2.78: * minibrowser fixes * cddb2 support * updates to mod, midi, and wav support (from the wonderful PP) Winamp 2.77: * mb.ini skin support (Winamp/MBOpen) * added page and slider for 'shuffle morph rate' to Preferences so you can control how much the playlist morphs (mutates) each time it cycles through. * PP's ACM disk writer output plugin instead of the classic one * PP's WAV/VOC reader (Which is apparently so much better, but we will see) * included new in_midi and in_mod (yay) * made playlist editor automatically size down when necessary (on startup) * made drag&drop playlist URLs work * made alt+delete work again in playlist editor * made winamp.exe and winampa.exe both much less likely to fudge HKCR/. -

How to Play Your Digital Album
How to Play Your Digital Album Step 1 – *Best if executed on a desktop or laptop computer. ▪ Download the file via the link in either your purchase receipt or in the email you receive post purchase. Example: Richard+S.+Grossman+-+Faded+Photograhs%282%29.zip Step 2 – *If Step 2 doesn’t apply to you, skip ahead to Step 3. ▪ Make sure you have iTunes, Windows Media Player or one of the other player apps in the list on page 2 of these instructions installed on your device (Virtually all Mac and Windows computers will already have at least one of these installed). If not, go to your appropriate App Store in your web browser to download the app you need. ▪ https://apps.apple.com/us/genre/ios/id36 ▪ https://www.microsoft.com/en-us/download/details.aspx?id=20426 ▪ https://www.videolan.org/vlc/index.html Step 3 – ▪ On a Mac device, go to your ‘Downloads’ folder and double-click on the link that has the name of the file you downloaded. This will extract the compressed .zip file to show a folder icon with the same name (minus the .zip). Open that folder and double click on the file with the ‘.m3u’ extension at the of its name. This should automatically launch your default media player, load the album into your player’s library and begin playing the first track (check your volume or mute button if you don’t hear anything). If this doesn’t work, you may need to manually launch your media player. ▪ On a Windows device, right-click on the downloaded file and then select ‘Extract’ from the contextual menu options. -

Nextkast User Manual
User Manual v 2.2 Broadcast/Pro/Standard Index ?Quick Start Overview................................................................ 4 ?Quick Start Create Categories................................................. 5 ?Quick Start Create Rotation..................................................... 6 ?Downloading.............................................................................. 7 ?Installation................................................................................. 7 ?Software Overview.................................................................... 8 ?Installation Considerations...................................................... 9 ?A Word About Audio Files........................................................ 10 ?Main User Interface Buttons Described.................................. 11 ?Settings Window........................................................................ 12 ?Library Location / Software Updates....................................... 13 ?Library Location........................................................................ 14 ?Screen Modes............................................................................ 15 ?Getting Started.......................................................................... 16 ?Adding Music Files to The Categories.................................... 17 ?MarkingTrackSweepers/Intro/Outro Next Start/URL Embed. 18 ?Adding Additional Track Info.................................................... 19 ?Cue Editor Window................................................................... -

Mopidy Documentation Release 3.2.0-17-G2cc7d953
Mopidy Documentation Release 3.2.0-17-g2cc7d953 Stein Magnus Jodal and contributors 2021 USAGE 1 Installation 3 1.1 Debian/Ubuntu..............................................3 1.2 Arch Linux................................................4 1.3 Fedora..................................................5 1.4 macOS..................................................6 1.5 Install from PyPI.............................................7 1.6 Raspberry Pi...............................................9 2 Running 11 2.1 Running in a terminal.......................................... 11 2.2 Running as a service........................................... 12 3 Configuration 17 3.1 Configuration file location........................................ 17 3.2 Editing the configuration......................................... 17 3.3 View effective configuration....................................... 17 3.4 Core configuration............................................ 18 3.5 Extension configuration......................................... 21 3.6 Adding new configuration values.................................... 21 4 Clients 23 4.1 Web clients................................................ 23 4.2 MPD clients............................................... 24 4.3 MPRIS clients.............................................. 24 5 Troubleshooting 25 5.1 Getting help............................................... 25 5.2 Show effective configuration....................................... 25 5.3 Show installed dependencies....................................... 25 -

Peter Van Eeckhoutte's Blog
Save the environment - don’t print this document ! http://www.corelan.be:8800 - Page 1 / 44 Peter Van Eeckhoutte's Blog :: [Knowledge is not an object, it´s a flow] :: Exploit writing tutorial part 10 : Chaining DEP with ROP – the Rubik’s[TM] Cube Peter Van Eeckhoutte · Wednesday, June 16th, 2010 Table of Contents ● Introduction ● Hardware DEP in the Win32 world ● Bypassing DEP – Building blocks ❍ What are our options ? ❍ The gadget ❍ Windows function calls to bypass DEP ❍ Choose your weapon ❍ Function parameters & usage tips ❍ ROP Exploit transportability ● From EIP to ROP ❍ Direct RET ❍ SEH based ❍ Before we begin ● Direct RET – The ROP version – VirtualProtect() ❍ Time to ROP ‘n ROLL ❍ How to build the chain (chaining basics) ❍ Finding ROP gadgets ❍ "CALL register" gadgets ❍ Gotcha. But how/where exactly do I start ? ❍ Test before you start ❍ Everybody stay cool, this is a roppery ● Direct RET – ROP Version 2 – NtSetInformationProcess() ● Direct RET – ROP Version 3 – SetProcessDEPPolicy() ● Direct RET – ROP Version 4 – ret-to-libc : WinExec() ● SEH Based – The ROP version – WriteProcessMemory() ❍ Triggering the bug ❍ Stack pivoting ❍ ROP NOP ❍ Building the ROP chain – WriteProcessMemory() ● Egg hunters ❍ Scenario 1 : patch the egg hunter ❍ Scenario 2 : prepend the shellcode ● Unicode ● ASLR and DEP ? ❍ The theory ❍ An example ● Other literature on DEP / Memory protection bypass ● Questions ? ● Thanks to w o l f Introduction a About 3 months after finishing my previous exploit writing related tutorial, I finally found some time and fresh energy to start writing a new article. s In the previous tutorials, I have explained the basics of stack based overflows and how they can lead to arbitrary code execution. -
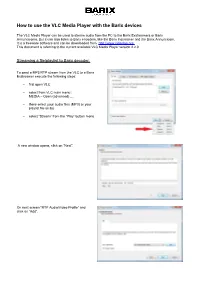
How to Use the VLC Media Player Together with Barix Products
How to use the VLC Media Player with the Barix devices The VLC Media Player can be used to stream audio from the PC to the Barix Exstreamers or Barix Annuncicoms. But it can also listen to Barix encoders, like the Barix Instreamer and the Barix Annuncicom. It is a freeware software and can be downloaded from http://www.videolan.org . This document is referring to the current available VLC Media Player version 2.2.0 Streaming a file/playlist to Barix decoder To send a MP3 RTP stream from the VLC to a Barix Exstreamer execute the following steps: – first open VLC – select from VLC main menu : MEDIA – Open (advanced) … – there select your audio files (MP3) or your playlist file (m3u) – select “Stream” from the “Play” button menu A new window opens, click on “Next”. On next screen “RTP Audio/Video Profile” and click on “Add”. As next define target IP-address and target port number then click “Next”. On next screen set the target format “Audio-MP3”. “Transcoding” is mostly not needed and can be deactivated then click “Next”. As last comes the Summary/Option setup screen showing the command line for the before selected options, click on “Stream” to start the streaming. Such stream can be received e.g. from the “Barix Streaming Client” firmware, the “Any to All” firmware or the STL firmware. Option command for RAW UDP Streaming e.g. to Annuncicom :sout=#duplicate{dst=std{access=udp,mux=raw,dst=224.0.0.1:3030}} (String is for the Option Setup screen, see picture above, generates a RAW UDP multicast stream to port 3030) The target port number and/or target IP address at the end of the string is changable! Thereafter click on “Stream”. -

Music Player Free Download for Pc 10 Best Music Players for Windows Pcs
music player free download for pc 10 Best Music Players for Windows PCs. Are you fond of listening to music? Here are the pros and cons for 10 best music players for Windows users. Some of them play videos, but all play audio files. Check this list and decide which music player you should stick to. Freemake Music Box. Freemake Music Box is a free software developed by Freemake Assets Corporation. Originally Freemake Music Box played only online music from YouTube. However, now the software supports offline files from your PC. Pros: Freemake Music Box is easy to use and lets you manage your music library easily. It is free and many people adore it for its intelligent music search capabilities. The software features a very crisp visual interface and video watching function. The main feature of Freemake Music Box is the ability to play both offline and play online music. If the software can’t find a track on your PC, it’ll stream it from the Web. Freemake Music Box also lets create and import playlists in most popular formats: M3U, M3U8, ASX, TPL, KPL, WPL, AIMPPL, PLC, PLS, RLC, ZPL, XSPT, SMI. Cons: The interface is not very full and looks a little too empty when compared to others. The software doesn’t have an equalizer option, neither it supports music CDs. Moreover, if you like changing skins of your music player, Freemake Music Box is not your choice. Supported formats: MP3, WMA, AAC, FLAC, WAV, OGG, M4A, APE, AIFF, M4B, MP2, MP1, MPC, M4R, SPX. Windows Media Player. -

Bob Rathbone Computer Consultancy
Raspberry Pi Internet Radio Constructors Manual A comprehensive guide to building Internet radios using the Raspberry Pi and MPD (Music Player Daemon) Bob Rathbone Computer Consultancy www.bobrathbone.com 19th of December 2020 Version 6.15 Contents Chapter 1 - Introduction ......................................................................................................................... 1 Document Overview ........................................................................................................................... 4 Quick links ........................................................................................................................................... 4 Examples ............................................................................................................................................. 5 Vintage Radio Conversion ................................................................................................................. 10 Chapter 2 - Hardware overview ............................................................................................................ 12 Raspberry Pi computer ..................................................................................................................... 12 The Raspberry Pi model 3B ........................................................................................................... 12 Raspberry Pi model 4B .................................................................................................................. 13 Audio and -

Bob Rathbone Computer Consultancy
Raspberry PI Internet Radio Constructors Manual Bob Rathbone Computer Consultancy www.bobrathbone.com 1st of January 2016 Version 4.7 Bob Rathbone |Raspberry PI Internet Radio - / 1 Contents Introduction .......................................................................................................................................... 11 Examples ........................................................................................................................................... 12 Building in a IR sensor and remote control ....................................................................................... 15 Hardware .............................................................................................................................................. 16 Raspberry PI computer ..................................................................................................................... 16 The HD44780 LCD display ................................................................................................................. 17 Using the Raspberry PI model B+ an Model 2 .................................................................................. 17 Raspberry Pi Zero .............................................................................................................................. 18 Radio variants ................................................................................................................................... 20 Housing the radio ............................................................................................................................. -

Version 3.0 User Manual
Version 3.0 User manual User manual ZaraStudio Contents 1. INTRODUCTION TO ZARASTUDIO...................................................................5 2. THE FIRST EXECUTION......................................................................................5 2.1. Default user..................................................................................................................5 3. THE MAIN WINDOW.........................................................................................5 4. THE BUTTONS BAR...........................................................................................7 5. THE AUDIO EXPLORER......................................................................................8 5.1. Audio sources...............................................................................................................9 5.2. Database audio sources............................................................................................10 5.2.1. Create, edit and delete audio sources............................................................10 5.2.2. Window controls................................................................................................11 5.2.3. Folder creation...................................................................................................13 5.2.4. Audio import......................................................................................................14 5.2.5. Audio properties................................................................................................14 -

Quicktime 4.1
QuickTime 4.1 Apple Technical Publications January 2000 Apple Computer, Inc. Apple, the Apple logo, FireWire, Mac, LIMITED WARRANTY ON MEDIA AND © 2000 Apple Computer, Inc. Macintosh, and QuickTime are REPLACEMENT All rights reserved. trademarks of Apple Computer, Inc., ALL IMPLIED WARRANTIES ON THIS No part of this publication or the registered in the United States and other MANUAL, INCLUDING IMPLIED software described in it may be countries. WARRANTIES OF MERCHANTABILITY reproduced, stored in a retrieval system, The QuickTime logo is a trademark of AND FITNESS FOR A PARTICULAR or transmitted, in any form or by any Apple Computer, Inc. PURPOSE, ARE LIMITED IN DURATION means, mechanical, electronic, Adobe, Acrobat, Photoshop, and TO NINETY (90) DAYS FROM THE DATE photocopying, recording, or otherwise, PostScript are trademarks of Adobe OF DISTRIBUTION OF THIS PRODUCT. without prior written permission of Systems Incorporated or its subsidiaries Even though Apple has reviewed this Apple Computer, Inc., except in the and may be registered in certain manual, APPLE MAKES NO WARRANTY normal use of the software or to make a jurisdictions. OR REPRESENTATION, EITHER EXPRESS backup copy of the software or Flash is a trademark of Macromedia OR IMPLIED, WITH RESPECT TO THIS documentation. The same proprietary Incorporated. MANUAL, ITS QUALITY, ACCURACY, and copyright notices must be affixed to MacPaint is a trademark of Apple MERCHANTABILITY, OR FITNESS FOR A any permitted copies as were affixed to Computer, Inc., registered in the U.S. PARTICULAR PURPOSE. AS A RESULT, the original. This exception does not and other countries. THIS MANUAL IS DISTRIBUTED “AS IS,” allow copies to be made for others, AND YOU ARE ASSUMING THE ENTIRE whether or not sold, but all of the Helvetica and Palatino are registered trademarks of Linotype-Hell AG and/or RISK AS TO ITS QUALITY AND material purchased (with all backup ACCURACY. -

Wireless Digital Media Player
MP115 Wireless Digital Media Player • Help is there when you need it! Enjoy Digital Music, Pictures, and Movies in Your Living Room NETGEAR provides 24x7 NETGEAR's Wireless Digital Media Player wirelessly connects your stereo and television to your technical support* in English, home computer network so you can access digital music, pictures, and movies from your with selected local language living room. Time to relax? Find the most comfortable seat in your home, and sit back with support during office hours. your family and friends to share your photos, videos, and music files, and stream music from the Internet to your TV. The Wireless Digital Media Player is compatible with your 802.11b or 802.11g wireless network and features 108 Mbps Super G™ enhanced throughput for streaming high-quality video. Very simple to set up and use, the media player connects to your TV without interfering with your video/DVD player hookup. Easy to install software automatically finds all your media files on any networked PC and collects them into one complete database so you don’t have to do the work. With the convenient remote control you can select what to watch or listen to without even getting out of your chair. Untethered Enjoy all kinds of media entertainment without being tied to your computer. NETGEAR's Wireless Digital Media Player lets you scroll through the pictures stored on your computer, share your digital slideshows and music files, and stream movies and Internet radio with a whole roomful of friends and family. Fast & Easy Connect the cable to your TV, install the software on one PC, and you're ready to enjoy the entire range of digital entertainment.