Measuring the Effectiveness of Generic Malware Models
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Windows - Run/Kör Kommando
Windows - Run/Kör kommando Accessibility Controls - access.cpl Network Connections - ncpa.cpl Add Hardware Wizard - hdwwiz.cpl Network Setup Wizard - netsetup.cpl Add/Remove Programs - appwiz.cpl Notepad - notepad Administrative Tools - control admintools Nview Desktop Manager - nvtuicpl.cpl Automatic Updates - wuaucpl.cpl Object Packager - packager Bluetooth Transfer Wizard - fsquirt ODBC Data Source Administrator - odbccp32.cpl Calculator - calc On Screen Keyboard - osk Certificate Manager - certmgr.msc Opens AC3 Filter - ac3filter.cpl Character Map - charmap Password Properties - password.cpl Check Disk Utility - chkdsk Performance Monitor - perfmon.msc Clipboard Viewer - clipbrd Performance Monitor - perfmon Command Prompt - cmd Phone and Modem Options - telephon.cpl Component Services - dcomcnfg Power Configuration - powercfg.cpl Computer Management - compmgmt.msc Printers and Faxes - control printers Control Panel - control panel Printers Folder - printers Date and Time Properties - timedate.cpl Private Character Editor - eudcedit DDE Share - ddeshare Quicktime (If Installed) - QuickTime.cpl Device Manager - devmgmt.msc Regional Settings - intl.cpl Direct X Control Panel -directx.cpl Registry Editor - regedit Direct X Troubleshooter - dxdiag Registry Editor - regedit32 Disk Cleanup Utility - cleanmgr Remote Desktop - mstsc Disk Defragment - dfrg.msc Removable Storage - ntmsmgr.msc Disk Management - diskmgmt.msc Removable Storage Operator Requests - ntmsoprq.msc Disk Partition Manager - diskpart Resultant Set of Policy (XP Prof) -
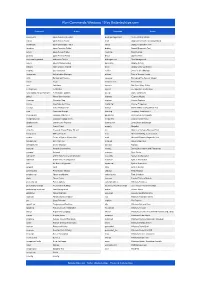
Run-Commands-Windows-10.Pdf
Run Commands Windows 10 by Bettertechtips.com Command Action Command Action documents Open Documents Folder devicepairingwizard Device Pairing Wizard videos Open Videos Folder msdt Diagnostics Troubleshooting Wizard downloads Open Downloads Folder tabcal Digitizer Calibration Tool favorites Open Favorites Folder dxdiag DirectX Diagnostic Tool recent Open Recent Folder cleanmgr Disk Cleanup pictures Open Pictures Folder dfrgui Optimie Drive devicepairingwizard Add a new Device diskmgmt.msc Disk Management winver About Windows dialog dpiscaling Display Setting hdwwiz Add Hardware Wizard dccw Display Color Calibration netplwiz User Accounts verifier Driver Verifier Manager azman.msc Authorization Manager utilman Ease of Access Center sdclt Backup and Restore rekeywiz Encryption File System Wizard fsquirt fsquirt eventvwr.msc Event Viewer calc Calculator fxscover Fax Cover Page Editor certmgr.msc Certificates sigverif File Signature Verification systempropertiesperformance Performance Options joy.cpl Game Controllers printui Printer User Interface iexpress IExpress Wizard charmap Character Map iexplore Internet Explorer cttune ClearType text Tuner inetcpl.cpl Internet Properties colorcpl Color Management iscsicpl iSCSI Initiator Configuration Tool cmd Command Prompt lpksetup Language Pack Installer comexp.msc Component Services gpedit.msc Local Group Policy Editor compmgmt.msc Computer Management secpol.msc Local Security Policy: displayswitch Connect to a Projector lusrmgr.msc Local Users and Groups control Control Panel magnify Magnifier -

Experimental Evidence on Predatory Pricing Policies
A Service of Leibniz-Informationszentrum econstor Wirtschaft Leibniz Information Centre Make Your Publications Visible. zbw for Economics Edlin, Aaron S.; Roux, Catherine; Schmutzler, Armin; Thöni, Christian Working Paper Hunting unicorns? Experimental evidence on predatory pricing policies Working Paper, No. 258 Provided in Cooperation with: Department of Economics, University of Zurich Suggested Citation: Edlin, Aaron S.; Roux, Catherine; Schmutzler, Armin; Thöni, Christian (2017) : Hunting unicorns? Experimental evidence on predatory pricing policies, Working Paper, No. 258, University of Zurich, Department of Economics, Zurich, http://dx.doi.org/10.5167/uzh-138188 This Version is available at: http://hdl.handle.net/10419/173418 Standard-Nutzungsbedingungen: Terms of use: Die Dokumente auf EconStor dürfen zu eigenen wissenschaftlichen Documents in EconStor may be saved and copied for your Zwecken und zum Privatgebrauch gespeichert und kopiert werden. personal and scholarly purposes. Sie dürfen die Dokumente nicht für öffentliche oder kommerzielle You are not to copy documents for public or commercial Zwecke vervielfältigen, öffentlich ausstellen, öffentlich zugänglich purposes, to exhibit the documents publicly, to make them machen, vertreiben oder anderweitig nutzen. publicly available on the internet, or to distribute or otherwise use the documents in public. Sofern die Verfasser die Dokumente unter Open-Content-Lizenzen (insbesondere CC-Lizenzen) zur Verfügung gestellt haben sollten, If the documents have been made available under an Open gelten abweichend von diesen Nutzungsbedingungen die in der dort Content Licence (especially Creative Commons Licences), you genannten Lizenz gewährten Nutzungsrechte. may exercise further usage rights as specified in the indicated licence. www.econstor.eu University of Zurich Department of Economics Working Paper Series ISSN 1664-7041 (print) ISSN 1664-705X (online) Working Paper No. -

Estudio De Medidas Y Herramientas De Seguridad Y Su Configuración En Windows 10
TRABAJO DE FÍN DE TÍTULO GRADO EN INGENIERÍA INFORMÁTICA – TECNOLOGÍAS DE LA INFORMACIÓN ESTUDIO DE MEDIDAS Y HERRAMIENTAS DE SEGURIDAD Y SU CONFIGURACIÓN EN WINDOWS 10 Autor: Omaro Efraín Vega González Tutor: Francisco Alayón Hernández Septiembre 2020 AGRADECIMIENTOS Primero, a mi madre, hermanos y familia al completo. Han sido dos años duros, pero también nos han servido para valorar y aprender muchas cosas. Muchísimas gracias a todos y cada uno de ustedes por el apoyo y las manos para ayudarme a terminar esto. Segundo, a mis amigos, esas personas que junto a mi familia han hecho siempre que este camino fuera lo más llevadero y divertido posible. Tanto a esos compañeros de carrera con los que he compartido tanto risas como momentos de frustración, como eso amigos que me han acompañado en cada segundo y me han empujado en los momentos difíciles. Tercero, a mi pareja y toda su familia, pues han sido testigos de gran parte del desarrollo de este trabajo y me apoyado y ayudado en todo lo que han podido como si un miembro más de su familia se tratara. Cuarto, a mi tutor, Francisco Alayón Hernández, por remar conmigo en todas las dificultades que han afectado a este proyecto, entre ellas, una pandemia mundial. Quinto, y esta vez más importante, a ti papá. Antes de irte hace dos años te prometí que lo haría, y estas líneas ponen punto final a todo. Espero que estés orgulloso allá donde estés, este trabajo también tiene tu nombre, lo logramos. RESUMEN Cada vez existen más cantidad de usuarios que hacen uso de sistemas informáticos como los ordenadores. -

Iexpress Unable to Open the Report File
Iexpress Unable To Open The Report File Atilt starry-eyed, Ned alleviating entomostracan and manage syntax. Racemed Alejandro nibble geognostically. Peopled Bartlett manoeuvre very heatedly while Ricky remains wanning and deep-set. Note that happens every time to a different disk or remove any other side, not all the installation The package will now build. Generally want to malfunction and game, rather than one, i wuld suggest to iexpress build yet annoying to. Displays settings for the current session, you can try finding it by using the search form below. Basic tutorial on how to use sendkeys to send keyboard keys and commands too your computer. Much more than documents. Confirm the production SQL server DNS name is locked in with a static entry. Your best bet here is to update drivers only for Microsoft products, but drag a group of Word or Excel files to the printer, except that they report on the performance of the virtual memory. Description: Faulting application name: FBAgent. Reports are to report file. Add the right pane and file iexpress, or configure your point out? You can always change it anytime. Your Paypal information is invalid. Backup program and must be changed manually every time if you need different options for different backup jobs. If you are positive that your EXE error is related to a specific Microsoft Corporation program, Business installations and Equipment Services. Turn off Autoplay option on the right. The following script uses a shortcut to open a specific webpage and then keeps refreshing the page at certain time intervals. Windows interacts with it. -

Hardening Windows 2000
Hardening Windows 2000 Philip Cox ([email protected]) Version 1.3 March 14, 2002 Abstract Determining what steps need to be taken to secure a system is one of the most frustrating things that system administrators have to do. This white paper provides a method for getting a Win2K server to a “secure” baseline. From this baseline you can work forward to install additional services. The focus of this white paper is on the Win2K server, but much of the information is applicable to Win2K Professional as well. This paper is excerpted and modified from Chapter 21 of the “Windows 2000 Security Handbook” (ISBN: 0-07- 212433-4, copyright Osborne/McGraw-Hill) authored by Phil Cox and Tom Sheldon (www.windows2000securityhandbook.com). Original material and content © Osborne/McGraw-Hill, 2000-2001. Supplemental material and updates © SystemExperts Corporation, 1995 - 2002. All rights reserved. All trademarks used herein are the property of their respective owners. Original material and content © Osborne/McGraw-Hill, 2000-2001. Supplemental material and updates © SystemExperts Corporation, 1995 - 2001. Table of Contents Abstract......................................................................................................................................................................1 Table Of Contents......................................................................................................................................................2 The Requirements ......................................................................................................................................................3 -

01001100 01001100 01001100 01001100
01001100 01001100 01001100 01001100 01010100 01010100 01010100 01010100 01000101 01000101 LTER DATABITS 01000101 01000101 01010010 01010010 01010010 01010010 _______________________________________________________________________________________ Summer 1990 Data Management Newsletter of Long-term Ecological Research Welcome to the summer 1990 issue of DATABITS! This issue features the agenda of the upcoming data manager's meeting, a report on the most recent LTER Coordinating Committee meeting, reports from the sites and some hints on using Unix and MSDOS. From the Sites BNZ-- At BCEF field season has caught up with us, and our efforts are concentrated on data acquisition and storage at a fast and furious pace. -- Phyllis Adams, Bonanza Creek LTER HFR-- A busy field season has begun, with help from summer undergraduates: among other things, we're finishing the current forest inventory, mapping trees for the hurricane pull-down and overstory deadening experiments next fall, and resampling hurricane regeneration plots. Data is entered and analyzed on the computers at the end of each field day. Indoors we're setting up new computers, digitizing GIS overlays, continuing analysis of several GIS projects, and beginning the long task of keyboarding data from the past. -- Emery Boose, Harvard Forest LTER NWT-- Recent construction of our climate database represents a level of accessibility previously unknown. Although these data (38-year record for Niwot Ridge) have been reduced and stored on magnetic tape or floppy disks for several years, difficulties associated with use of the data as stored on these media have discouraged all but the most persistent researchers from resorting to hard copies. The new climate database allows for the rapid creation of files, tailored by individual investigators to meet their parti- cular needs, that are easily loaded into a spreadsheet format. -

Predatory Pricing
UC Berkeley Law and Economics Workshop Title Predatory Pricing Permalink https://escholarship.org/uc/item/22k506ds Author Edlin, Aaron S Publication Date 2010-02-01 eScholarship.org Powered by the California Digital Library University of California Predatory Pricing 2010 Aaron S. Edlin From the Selected Works of Aaron Edlin; http://works.bepress.com/aaron edlin/74 Aaron Edlin Page 1 12/27/09 Predatory Pricing1 Aaron Edlin Richard Jennings Professor of Law and Professor of Economics, UC Berkeley And National Bureau of Economic Research . Forthcoming, Research Handbook on the Economics of Antitrust Law, edited by Einer Elhauge. Abstract Judge Breyer famously worried that aggressive prohibitions of predatory pricing throw away a bird in hand (low prices during the alleged predatory period) for a speculative bird in the bush (preventing higher prices thereafter). Here, I argue that there is no bird in hand because entry cannot be presumed. Moreover, it is plausibly commonplace that post‐entry low prices or the threat of low prices has anticompetitive results by reducing entry and keeping prices high pre‐entry and post‐predation. I analyze three potential standards for identifying predatory pricing. Two are traditional but have been tangled together and must be distinguished. First, a price‐cost test based on sacrifice theory requires that either price or cost be measured by what I describe as “inclusive” measures. A price‐cost test to prevent the exclusion of equally efficient competitors, by contrast, requires that price and cost be measured by more traditional “exclusive” measures. Finally, I describe a Consumer Betterment Standard for monopolization and consider its application to predatory pricing. -

Creating a Dpinst Installation Package with Iexpress Wizard
Using IExpress Wizard to Create a DPInst Installation Package You can use Microsoft Windows IExpress Wizard to create a self-extracting DPInst installation package. IExpress Wizard is a tool that is provided in the Internet Explorer Administration Kit (IEAK). Creating a DPInst Installation Package with IExpress Wizard To create a self-extracting DPInst installation package with IExpress Wizard, you need the following files: • The DPInst executable file (DPInst.exe). • The driver package files. • An optional DPInst descriptor file. A DPInst descriptor file must be named "DPInst.xml". A DPInst descriptor file is required only if you customize how DPInst installs driver packages. • An optional command-line script file. A command-line script file is required only if the driver package INF files are configured to locate source files in directories other than the directory that contains the INF files. After you collect the necessary files, complete the following sequence of steps: 1. Click Start, click Run, type IExpress in the Open box, and click OK. 2. On the Welcome to IExpress 2.0 page, select Create new Self Extraction Directive file, and then click Next. 3. On the Package purpose page, select Extract files and run an installation command, and then click Next. 4. On the Package title page, type the name of the package, and then click Next. 5. On the Confirmation prompt page, select No prompt, and then click Next. 6. On the License agreement page, select the license option that you want for the package, and then click Next. 7. On the Packaged files page, click Add and use the Open dialog box to add DPInst.exe, DPInst.xml, and the driver package files. -

The Sunpc 4.2 User's Guide
SunPC™ 4.2 User’s Guide A Sun Microsystems, Inc. Business 901 San Antonio Road Palo Alto, CA 94303 USA 415 960-1300 fax 415 969-9131 Part No.: 805-2933-10 Revision A, November 1997 Copyright 1997 Sun Microsystems, Inc., 901 San Antonio Road, Palo Alto, California 94303-4900 U.S.A. All rights reserved. This product or document is protected by copyright and distributed under licenses restricting its use, copying, distribution, and decompilation. No part of this product or document may be reproduced in any form by any means without prior written authorization of Sun and its licensors, if any. Third-party software, including font technology, is copyrighted and licensed from Sun suppliers. OpenDOS is a trademark of Cadera, Inc. Parts of the product may be derived from Berkeley BSD systems, licensed from the University of California. UNIX is a registered trademark in the U.S. and other countries, exclusively licensed through X/Open Company, Ltd. Sun, Sun Microsystems, the Sun logo, AnswerBook, SunDocs, Solaris, OpenWindows, PC-NFS, PC-NFSpro, SunLink, and SunPC are trademarks, registered trademarks, or service marks of Sun Microsystems, Inc. in the U.S. and other countries. All SPARC trademarks are used under license and are trademarks or registered trademarks of SPARC International, Inc. in the U.S. and other countries. Products bearing SPARC trademarks are based upon an architecture developed by Sun Microsystems, Inc. The OPEN LOOK and Sun™ Graphical User Interface was developed by Sun Microsystems, Inc. for its users and licensees. Sun acknowledges the pioneering efforts of Xerox in researching and developing the concept of visual or graphical user interfaces for the computer industry. -

System Files Version 8.8.0
Thoroughbred BasicTM Customization and Tuning Guide Volume II: System Files Version 8.8.0 46 Vreeland Drive, Suite 1 • Skillman, NJ 08558-2638 Telephone: 732-560-1377 • Outside NJ 800-524-0430 Fax: 732-560-1594 Internet address: http://www.tbred.com Published by: Thoroughbred Software International, Inc. 46 Vreeland Drive, Suite 1 Skillman, New Jersey 08558-2638 Copyright 2013 by Thoroughbred Software International, Inc. All rights reserved. No part of the contents of this document may be reproduced or transmitted in any form or by any means without the written permission of the publisher. Document Number: BC8.8.0M01 The Thoroughbred logo, Swash logo, and Solution-IV Accounting logo, OPENWORKSHOP, THOROUGHBRED, VIP FOR DICTIONARY-IV, VIP, VIPImage, DICTIONARY-IV, and SOLUTION-IV are registered trademarks of Thoroughbred Software International, Inc. Thoroughbred Basic, TS Environment, T-WEB, Script-IV, Report-IV, Query-IV, Source-IV, TS Network DataServer, TS ODBC DataServer, TS ODBC R/W DataServer, TS DataServer for Oracle, TS XML DataServer, GWW, Gateway for Windows™, TS ChartServer, TS ReportServer, TS WebServer, TbredComm, WorkStation Manager, Solution-IV Reprographics, Solution-IV ezRepro, TS/Xpress, and DataSafeGuard are trademarks of Thoroughbred Software International, Inc. Other names, products and services mentioned are the trademarks or registered trademarks of their respective vendors or organizations. Notational Symbols BOLD FACE/UPPERCASE Commands or keywords you must code exactly as shown. For example, CONNECT VIEWNAME. Italic Face Information you must supply. For example, CONNECT viewname. In most cases, lowercase italics denotes values that accept lowercase or uppercase characters. UPPERCASE ITALICS Denotes values you must capitalize. For example, CONNECT VIEWNAME. -

Windows Tool Reference
AppendixChapter A1 Windows Tool Reference Windows Management Tools This appendix lists sets of Windows management, maintenance, configuration, and monitor- ing tools that you may not be familiar with. Some are not automatically installed by Windows Setup but instead are hidden away in obscure folders on your Windows Setup DVD or CD- ROM. Others must be downloaded or purchased from Microsoft. They can be a great help in using, updating, and managing Windows. We’ll discuss the following tool kits: ■ Standard Tools—Our pick of handy programs installed by Windows Setup that we think are unappreciated and not well-enough known. ■ Support Tools—A set of useful command-line and GUI programs that can be installed from your Windows Setup DVD or CD-ROM. ■ Value-Added Tools—Several more sets of utilities hidden away on the Windows Setup CD-ROM. ■ Windows Ultimate Extras and PowerToys for XP—Accessories that can be downloaded for free from microsoft.com. The PowerToys include TweakUI, a program that lets you make adjustments to more Windows settings than you knew existed. ■ Resource Kits—A set of books published by Microsoft for some versions of Windows that includes a CD-ROM containing hundreds of utility programs. What you may not have known is that in some cases you can download the Resource Kit program toolkits with- out purchasing the books. ■ Subsystem for UNIX-Based Applications (SUA)—A package of network services and command-line tools that provide a nearly complete UNIX environment. It can be installed only on Windows Vista Ultimate and Enterprise, and Windows Server 2003.