Composing a More Complete and Relevant Twitter Dataset
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

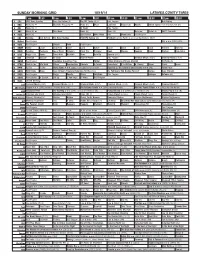
Sunday Morning Grid 12/28/14 Latimes.Com/Tv Times
SUNDAY MORNING GRID 12/28/14 LATIMES.COM/TV TIMES 7 am 7:30 8 am 8:30 9 am 9:30 10 am 10:30 11 am 11:30 12 pm 12:30 2 CBS CBS News Sunday Face the Nation (N) The NFL Today (N) Å Football Chargers at Kansas City Chiefs. (N) Å 4 NBC News (N) Å Meet the Press (N) Å News 1st Look Paid Premier League Goal Zone (N) (TVG) World/Adventure Sports 5 CW News (N) Å In Touch Paid Program 7 ABC News (N) Å This Week News (N) News (N) Outback Explore St. Jude Hospital College 9 KCAL News (N) Joel Osteen Mike Webb Paid Woodlands Paid Program 11 FOX Paid Joel Osteen Fox News Sunday FOX NFL Sunday (N) Football Philadelphia Eagles at New York Giants. (N) Å 13 MyNet Paid Program Black Knight ›› (2001) 18 KSCI Paid Program Church Faith Paid Program 22 KWHY Como Local Jesucristo Local Local Gebel Local Local Local Local Transfor. Transfor. 24 KVCR Painting Dewberry Joy of Paint Wyland’s Paint This Painting Kitchen Mexico Cooking Chefs Life Simply Ming Ciao Italia 28 KCET Raggs Play. Space Travel-Kids Biz Kid$ News Asia Biz Ed Slott’s Retirement Rescue for 2014! (TVG) Å BrainChange-Perlmutter 30 ION Jeremiah Youssef In Touch Hour Of Power Paid Program 34 KMEX Paid Program Al Punto (N) República Deportiva (TVG) 40 KTBN Walk in the Win Walk Prince Redemption Liberate In Touch PowerPoint It Is Written B. Conley Super Christ Jesse 46 KFTR Tu Dia Tu Dia Happy Feet ››› (2006) Elijah Wood. -

Humber Today in a Past Interview
HIVES OF ACTIVITY AN AUTOMATIC HUMBER Two new floors of labs, SUCCESS classrooms and study spaces Humber’s Electromechanical “REIGNS” overlook the Arboretum and Engineering program produces OVER FILM elevate the F Wing. P. 2 in-demand graduates. P. 4 FESTIVALS P. 3 Our top 5 athletic moments P. 4 + ABUZZ FOR BEES P.2 + POLICING PROJECT P.3 + NEW FOOD TRUCK P.3 + LGBTQ+ CENTRE P.3 WINTER 2016 • CHECK OUT HUMBER’S EXCLUSIVE ONLINE STORIES AT HUMBER.CA/HUMBERTODAY GIACOMO OYIN OLADEJO GIANNIOTTI RISING STARS The graduating class of 2012’s Theatre Performance program are a talented bunch. Giacomo Gianniotti was in the latest season of Grey’s Anatomy. Matt Murray is a regular on the ABC Family show Kevin from Work. And Oyin Oladejo and Sina Gilani are regulars on the Toronto theatre scene. Gilani is best known for his recent dramatic (and controversial) turn in the Buddies in Bad Times play The 20th of November. The one-man show features Gilani as school shooter Bastian Bosse. It’s based mainly on the 18-year-old’s blog entries, right until Nov. 20, 2006, when he shot 30 classmates and teachers in Germany. “Acting is a craft,” says Gilani, who originally came to Canada from Iran to study physics. “It takes the rehearsal process to try and find your way into the character and the play. The collective of the artists working on the play helped get inside Bastian's world and his twisted psychology. It is called a one-person show, but it is not a one-person production.” The actor and playwright is currently working on touring his Summerworks-featured play In Case of Nothing, as well as two films and workshopping his new play Field of Reeds. -
Sunday Morning Grid 10/19/14 Latimes.Com/Tv Times
SUNDAY MORNING GRID 10/19/14 LATIMES.COM/TV TIMES 7 am 7:30 8 am 8:30 9 am 9:30 10 am 10:30 11 am 11:30 12 pm 12:30 2 CBS CBS News Sunday Face the Nation (N) The NFL Today (N) Å Paid Program Bull Riding 4 NBC News (N) Å Meet the Press (N) Å News (N) Meet LazyTown Poppy Cat Noodle Action Sports From Brooklyn, N.Y. (N) 5 CW News (N) Å In Touch Paid Program 7 ABC News (N) Å This Week News (N) News (N) News Å Vista L.A. ABC7 Presents 9 KCAL News (N) Joel Osteen Mike Webb Paid Woodlands Paid Program 11 FOX Winning Joel Osteen Fox News Sunday FOX NFL Sunday (N) Football Carolina Panthers at Green Bay Packers. (N) Å 13 MyNet Paid Program I.Q. ››› (1994) (PG) 18 KSCI Paid Program Church Faith Paid Program 22 KWHY Como Local Jesucristo Local Local Gebel Local Local Local Local Transfor. Transfor. 24 KVCR Painting Dewberry Joy of Paint Wyland’s Paint This Painting Cook Mexico Cooking Cook Kitchen Ciao Italia 28 KCET Raggs Cold. Space Travel-Kids Biz Kid$ News Asia Biz Special (TVG) 30 ION Jeremiah Youssef In Touch Hour Of Power Paid Program Criminal Minds (TV14) Criminal Minds (TV14) 34 KMEX Paid Program República Deportiva (TVG) Fútbol Fútbol Mexicano Primera División Al Punto (N) 40 KTBN Walk in the Win Walk Prince Redemption Liberate In Touch PowerPoint It Is Written B. Conley Super Christ Jesse 46 KFTR Tu Dia Tu Dia Home Alone 4 ›› (2002, Comedia) French Stewart. -

Getting a on Transmedia
® A PUBLICATION OF BRUNICO COMMUNICATIONS LTD. SPRING 2014 Getting a STATE OF SYN MAKES THE LEAP GRIon transmediaP + NEW RIVALRIES AT THE CSAs MUCH TURNS 30 | EXIT INTERVIEW: TOM PERLMUTTER | ACCT’S BIG BIRTHDAY PB.24462.CMPA.Ad.indd 1 2014-02-05 1:17 PM SPRING 2014 table of contents Behind-the-scenes on-set of Global’s new drama series Remedy with Dillon Casey shooting on location in Hamilton, ON (Photo: Jan Thijs) 8 Upfront 26 Unconventional and on the rise 34 Cultivating cult Brilliant biz ideas, Fort McMoney, Blue Changing media trends drive new rivalries How superfans build buzz and drive Ant’s Vanessa Case, and an exit interview at the 2014 CSAs international appeal for TV series with the NFB’s Tom Perlmutter 28 Indie and Indigenous 36 (Still) intimate & interactive 20 Transmedia: Bloody good business? Aboriginal-created content’s big year at A look back at MuchMusic’s three Canadian producers and mediacos are the Canadian Screen Awards decades of innovation building business strategies around multi- platform entertainment 30 Best picture, better box offi ce? 40 The ACCT celebrates its legacy Do the new CSA fi lm guidelines affect A tribute to the Academy of Canadian 24 Synful business marketing impact? Cinema and Television and 65 years of Going inside Smokebomb’s new Canadian screen achievements transmedia property State of Syn 32 The awards effect From books to music to TV and fi lm, 46 The Back Page a look at what cultural awards Got an idea for a transmedia project? mean for the business bottom line Arcana’s Sean Patrick O’Reilly charts a course for success Cover note: This issue’s cover features Smokebomb Entertainment’s State of Syn. -

Wedding Band Bio Poster.Indd
PLAY BY THE BOOK: UPRISING SERIES Wedding Band by Alice Childress MARION ADLER HERMANN’S MOTHER ALLISON EDWARDSCREWE MATTIE Stratford: Grandma Elliot in Billy Elliot the Musical, lyricist for The Merry Wives of Allison has traveled across Canada performing on stage and screen. Selected Windsor, Lady Markby in An Ideal Husband, Mrs. Dubose in To Kill a Mockingbird, credits: Theatre: Serving Elizabeth (Western Canada Theatre); The Color Purple Cicero, Volumnius in Julius Caesar, Lady Capulet in Romeo and Juliet, Gabrielle (Citadel Theatre and Royal Manitoba Theatre Centre); School Girls; Or, the African in The Madwoman of Chaillot, Diana in and lyricist for The Adventures of Pericles. Mean Girls Play (Obsidian and Nightwood Theatre); How Black Mothers Say Elsewhere: Paulina and Hermione in The Winter’s Tale, Queen Marguerite in I Love You (Factory Theatre); All Shook Up (The Globe Theatre); Miss Bennet: Exit the King, Beatrice in Much Ado About Nothing, Philaminte in The Learned Christmas at Pemberley (Citadel); Girls Like That (Tarragon Theatre); ’da Kink in Ladies, Titania in A Midsummer Night’s Dream (Shakespeare Theatre of New My Hair (Theatre Calgary, National Arts Centre); Dreamgirls (Grand Theatre). Film/ Jersey); Princess of France in Love’s Labour’s Lost, Emilia in Othello, Mistress TV: The Handmaid’s Tale (MGM/Hulu), Baby in a Manger (BrainPower), Surviving Quickly in Henry IV Part 2 (Shakespeare Santa Cruz). Et cetera: Ms Adler is an Evil (Cinefl ix), Black Actress (JungleWild). Audio Dramas: Liming (Expect Theatre/CBC), Every Second internationally acclaimed, award-winning lyricist. of Every Day (Factory Theatre). Training: High Honours Bachelor of Music Theatre, Sheridan College. -

Coca-Cola Stage Backgrounder 2016
May 26, 2016 BACKGROUNDER 2016 Coca-Cola Stage lineup Christian Hudson Appearing Thursday, July 7, 7 p.m. Website: http://www.christianhudsonmusic.com/ Facebook: https://www.facebook.com/ChristianHudsonMusic Twitter: www.twitter.com/CHsongs While most may know Christian Hudson by his unique and memorable performances at numerous venues across Western Canada, others seem to know him by his philanthropy. This talented young man won the prestigious Calgary Stampede Talent Show last summer but what was surprising to many was he took his prize money of $10,000 and donated it all to the local drop-in centre. He was touched by the stories he was told by a few people experiencing homelessness he had met one night prior to the contest’s finale. His infectious originals have caught the ears of many in the industry that are now assisting his career. He was honoured to receive 'The Spirit of Calgary' Award at the inaugural Vigor Awards for his generosity. Hudson will soon be touring Canada upon the release of his first single on national radio. JJ Shiplett Appearing Thursday, July 7, 8 p.m. Website: http://www.jjshiplettmusic.com/ Facebook: https://www.facebook.com/jjshiplettmusic/ Twitter: www.twitter.com/jjshiplettmusic Rugged, raspy and reserved, JJ Shiplett is a true artist in every sense of the word. Unapologetically himself, the Alberta born singer-songwriter and performer is both bold in range and musical creativity and has a passion and reverence for the art of music and performance that has captured the attention of music fans across the country. He spent the major part of early 2016 as one of the opening acts on the Johnny Reid tour and is also signed to Johnny Reid’s company. -

Canada's #1 Original Drama Rookie Blue Moves To
CANADA’S #1 ORIGINAL DRAMA ROOKIE BLUE MOVES TO WEDNESDAY NIGHTS STARTING JUNE 24 Global’s Ratings Juggernaut Blazes Through Competition with Over 1.5 Million Weekly Viewers For additional photography and press kit materials visit: http://shawmediatv.ca and follow us on Twitter at @GlobalTV_PR / @ShawMediaTV_PR For Immediate Release: TORONTO, June 22, 2015 – Starting June 24, Global’s homegrown hit Rookie Blue moves to an all new timeslot on Wednesday nights at 9pm ET/PT. The nation’s top Canadian drama of 2015 (A18-49, A25-54) had an explosive premiere this spring, and is averaging over 1.5 million weekly viewers (2+) with no intention of slowing down. This Wednesday’s all-new episode starts with a bang after a community-outreach baseball game erupts in a drive-by shooting and Gail’s relationship with her brother, Steve Peck, is put to the test in the search for the shooter. Meanwhile, Sam plans a getaway with Andy up to Oliver’s cabin, which goes off the rails in every possible way – except one. The sixth season of Rookie Blue has been chock-full of dramatic, edge-of-your-seat moments anchoring the series as Global’s #1 Canadian series of 2015. For additional data highlights, please see below. DATA HIGHLIGHTS Rookie Blue averages over 1.5 million weekly viewers (2+) Rookie Blue is Global’s #1 Canadian series of 2015 (+2, W25-54) Rookie Blue is the #1 Canadian drama series of 2015 (A18-49, A25-54) Rookie Blue is the #1 Canadian drama series of 2015 across all conventional in four meter markets (Toronto, Calgary, Edmonton, Vancouver) (A18-49, A25-54) Viewers can also catch up on episodes from this season of Rookie Blue on Global Go. -

Rookie Blue’S Green Guy
COVER Story Rookie Blue’s green guy ter mess, but upon closer inspec- tion, there’s more to his story than meets the eye. BILL As far as Mooney’s character Nick goes, there’s more to his story than HarrIS meets the eye, too. Television “Gail, Charlotte Sullivan’s char- acter, and Nick have a history,” said Mooney, who originally is from There were uniform considera- Winnipeg. “So that helps bring Nick tions for Peter Mooney when he right into the middle of things, for joined Rookie Blue fresh off his role better or worse. in Camelot. “There are a lot of characters “They wouldn’t let me keep a on Rookie Blue, but it’s so well sword in my gun belt, for some rea- designed as an ensemble show, son,” Mooney said. “I thought it in that there’s so much we all do would be kind of a cool character together. So I’m definitely not trait.” bored. It’s busy.” Nonetheless, the transition of There obviously are a lot of police skills from one job to another also shows on TV, many of them centred is the issue for Mooney’s character on young cops who work hard, play in Rookie Blue, which returns for its hard, live hard and love hard, dam- third season Thursday, on Global mit. Mooney — who played Sir Kay and ABC. in Camelot, which was cancelled “Nick Collins comes in, he’s the after one season — was asked if he new rookie,” Mooney said. “But it’s has a theory as to why Rookie Blue an interesting dynamic with him, cuts through the clutter. -

2013 CANADIAN SCREEN AWARDS Television Nominations
2013 CANADIAN SCREEN AWARDS Television Nominations Best Animated Program or Series Almost Naked Animals YTV (Corus) (9 Story Entertainment Inc.) Vince Commisso, Tanya Green, Tristan Homer, Steven Jarosz, Noah Z. Jones Jack TVO (TVOntario) (PVP Interactif / Productions Vic Pelletier, Spark Animation -Wong Kok Cheong) François Trudel, Wong Kok Cheong, Vincent Leroux, Vic Pelletier Producing Parker TVtropolis (Shaw Media) (Breakthrough Entertainment) Ira Levy, Jun Camerino, Laura Kosterski, Peter Williamson Rated A for Awesome YTV (Corus) (Nerd Corps Entertainment) Ace Fipke, Ken Faier, Chuck Johnson Best Breaking News Coverage PEI Votes CBC (CBC) (CBC PEI) Julie Clow, Mark Bulgutch, Sharon Musgrave CBC News Now: Gadhafi Dead CBC (CBC) (CBC News) Nancy Kelly, Tania Dahiroc, Rona Martell Eaton Centre Shooting Citytv (Rogers) (Citytv) Kathleen O'Keefe, Irena Hrzina, James Shutsa, Kelly Todd CBC News Now: Jack Layton's Death CBC (CBC) (CBC) Jennifer Sheepy, Layal El Abdallah, Paul Bisson, Gerry Buffett, Patricia Craigen, Seema Patel, Marc Riddell, Bill Thornberry Global National - Johnsons Landing Slide Global TV (Shaw Media) (Global National) Doriana Temolo, Mike Gill, Bryan Grahn, Francis Silvaggio, Shelly Sorochuk Best Breaking Reportage, Local CBC News Ottawa at 5, 5:30, 6:00 - School Explosion CBC (CBC) (CBC Ottawa) Lynn Douris, Omar Dabaghi-Pacheco, Marni Kagan CBC News Toronto - CBC News Toronto - Miriam Makashvili CBC (CBC) (CBC Television) John Lancaster, Nil Koksal Best Breaking Reportage, National CBC News The National - Reports -

Canadian Canada $7 Fall 2016 Vol.19, No.1 Screenwriter Film | Television | Radio | Digital Media
CANADIAN CANADA $7 FALL 2016 VOL.19, NO.1 SCREENWRITER FILM | TELEVISION | RADIO | DIGITAL MEDIA We Celebrate Our Epic Screenwriting Success Stories It’s Time To Work On Your Pitch Baroness Von Sketch Show: Creating A World In Two Minutes Animated Conversation: Ken Cuperus Opens Up About His Live Action-Cartoon Crossover PM40011669 ★ ★ SCREENWRITERS STAY TUNED FOR IMPORTANT DEADLINES THE 21ST ANNUAL WGC SCREENWRITING AWARDS APRIL 24, 2017 | KOERNER HALL, TORONTO 2017 SPECIAL AWARDS: THE WGC SHOWRUNNER AWARD for excellence in showrunning THE JIM BURT SCREENWRITING PRIZE for longform screenwriting talent THE SONDRA KELLY AWARD for female screenwriters CALL FOR ENTRIES COMING SOON TO WWW.WGC.CA CANADIAN SCREENWRITER The journal of the Writers Guild of Canada Vol. 19 No. 1 Fall 2016 ISSN 1481-6253 Publication Mail Agreement Number 400-11669 Contents Publisher Maureen Parker Editor Tom Villemaire Features [email protected] Having An Animated Conversation 6 Director of Communications Li Robbins We talk to Ken Cuperus about how he and his writing team create a hybrid animation and live-action comedy. Editorial Advisory Board By Mark Dillon Denis McGrath (Chair) Michael MacLennan Susin Nielsen Simon Racioppa Changing The Rules 12 President Jill Golick (Central) While bureaucrats tinker with the points system in an effort Councillors to make Canadian television more successful, we offer our Michael Amo (Atlantic) epic track record, proving the system works. Mark Ellis (Central) By Matthew Hays Dennis Heaton (Pacific) Denis McGrath (Central) Warming Up For The Pitch 16 Anne-Marie Perrotta (Quebec) Pitching is often a bigger challenge to writers than, Andrew Wreggitt (Western) well, writing. -

Toronto's On-Screen Industry: 2014
Toronto’s On-screen Industry: 2014 – The Year In Review toronto.ca/business | toronto.ca/culture The Strain - FX Reign - CW Saving Hope - CTV Rookie Blue - Global Vikings – History Orphan Black - CTV Pixels - Feature Nissan Rogue – Commercial Annedroids- TVO Toronto 2014 Great Film, Great Television, Great Digital Media Suits - Bravo • The following statistical charts prepared by the Toronto Film, Television & Digital Media Office report investments in Toronto’s economy for productions which have been either filmed on location or in studio or have been post produced in Toronto. • In addition to the expenditures and investments detailed in this presentation, the creative screen industry generates hundreds of millions of dollars in additional spending in Toronto related to in-house or studio broadcasts, unscripted series, public affairs programming, news and sports telecasts. • Historically, these expenditures have not been included in this presentation. Future annual reports will provide an overview of this investment by these broadcasters and other industry stakeholders. Total Production Investment Toronto 2014 Music Videos Animation Expenditures by screen based $1.2million $87.1million Major Productions production companies in Toronto Commercials 0.1% 7.1% reached a record $1.23 billion in $195million Commercials 2014. 15.8% Music Videos Animation 2014 is the 4th consecutive year total production spending has exceeded $1billion. 2014 saw a 4.3% increase in total production Major spending over the $1.18 billion Productions reported in 2013. $953.1 million 77.5% Total $1.23B Production spending in 2014 increased significantly in Music Videos Animation Commercials and moderately in $5.80 million 2013 Commercials 0.5% $103 million major productions. -

1. a Crisis of Quality
1. A Crisis oF QuAlity On June 23, 2010, Canadians were startled with some big news in the media world. No, Oprah wasn’t joining the cbc. But some other ideas from south of the border had washed up in Montreal. A press conference had been called by Quebecor, one of Canada’s biggest media corporations. The other media outlets sensed something newsworthy. Kory Teneycke, an aggressive conservative who had previously served as Stephen Harper’s communications director, bounded onstage wearing a big, pale blue tie. He was here to reveal the birth of a new television network — Sun tv. Spectators immediately made the connection with Fox News in the U.S. when Teneycke boasted: “We’re taking on the mainstream media. We’re taking on smug, condescending, often irrelevant journalism. We’re taking on political correctness. We will not be a state broadcaster offering boring news by bureaucrats, for elites and paid for by taxpayers.”1 Now, said the wags, Canada would have a Fox News North, something to challenge that smug, condescending cbc. Starting in 2011, Quebecor’s new venture promised to bring us cheap opinion shows in the mould of Fox News, what Nancy Franklin, of the New Yorker, calls the screech shows. The gathering of actual news by professional journalists needn’t take up much of the budget. The Canadian media enjoy high ratings at home and abroad 5 6 About CAnAdA: MediA for their serious journalism, their advanced telecommunications and their lively entertainment in radio, film andtv . As my dad reminds me: “Canadian comedians Wayne and Shuster appeared on the Ed Sullivan Show more than any other comedians.” The National Film Board of Canada has long been admired for its high quality documentaries and animation.