Chapter 4 Symmetric Matrices and the Second Derivative Test
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Mean Value Theorem Math 120 Calculus I Fall 2015
The Mean Value Theorem Math 120 Calculus I Fall 2015 The central theorem to much of differential calculus is the Mean Value Theorem, which we'll abbreviate MVT. It is the theoretical tool used to study the first and second derivatives. There is a nice logical sequence of connections here. It starts with the Extreme Value Theorem (EVT) that we looked at earlier when we studied the concept of continuity. It says that any function that is continuous on a closed interval takes on a maximum and a minimum value. A technical lemma. We begin our study with a technical lemma that allows us to relate 0 the derivative of a function at a point to values of the function nearby. Specifically, if f (x0) is positive, then for x nearby but smaller than x0 the values f(x) will be less than f(x0), but for x nearby but larger than x0, the values of f(x) will be larger than f(x0). This says something like f is an increasing function near x0, but not quite. An analogous statement 0 holds when f (x0) is negative. Proof. The proof of this lemma involves the definition of derivative and the definition of limits, but none of the proofs for the rest of the theorems here require that depth. 0 Suppose that f (x0) = p, some positive number. That means that f(x) − f(x ) lim 0 = p: x!x0 x − x0 f(x) − f(x0) So you can make arbitrarily close to p by taking x sufficiently close to x0. -

Basic Concepts of Linear Algebra by Jim Carrell Department of Mathematics University of British Columbia 2 Chapter 1
1 Basic Concepts of Linear Algebra by Jim Carrell Department of Mathematics University of British Columbia 2 Chapter 1 Introductory Comments to the Student This textbook is meant to be an introduction to abstract linear algebra for first, second or third year university students who are specializing in math- ematics or a closely related discipline. We hope that parts of this text will be relevant to students of computer science and the physical sciences. While the text is written in an informal style with many elementary examples, the propositions and theorems are carefully proved, so that the student will get experince with the theorem-proof style. We have tried very hard to em- phasize the interplay between geometry and algebra, and the exercises are intended to be more challenging than routine calculations. The hope is that the student will be forced to think about the material. The text covers the geometry of Euclidean spaces, linear systems, ma- trices, fields (Q; R, C and the finite fields Fp of integers modulo a prime p), vector spaces over an arbitrary field, bases and dimension, linear transfor- mations, linear coding theory, determinants, eigen-theory, projections and pseudo-inverses, the Principal Axis Theorem for unitary matrices and ap- plications, and the diagonalization theorems for complex matrices such as the Jordan decomposition. The final chapter gives some applications of symmetric matrices positive definiteness. We also introduce the notion of a graph and study its adjacency matrix. Finally, we prove the convergence of the QR algorithm. The proof is based on the fact that the unitary group is compact. -

AP Calculus AB Topic List 1. Limits Algebraically 2. Limits Graphically 3
AP Calculus AB Topic List 1. Limits algebraically 2. Limits graphically 3. Limits at infinity 4. Asymptotes 5. Continuity 6. Intermediate value theorem 7. Differentiability 8. Limit definition of a derivative 9. Average rate of change (approximate slope) 10. Tangent lines 11. Derivatives rules and special functions 12. Chain Rule 13. Application of chain rule 14. Derivatives of generic functions using chain rule 15. Implicit differentiation 16. Related rates 17. Derivatives of inverses 18. Logarithmic differentiation 19. Determine function behavior (increasing, decreasing, concavity) given a function 20. Determine function behavior (increasing, decreasing, concavity) given a derivative graph 21. Interpret first and second derivative values in a table 22. Determining if tangent line approximations are over or under estimates 23. Finding critical points and determining if they are relative maximum, relative minimum, or neither 24. Second derivative test for relative maximum or minimum 25. Finding inflection points 26. Finding and justifying critical points from a derivative graph 27. Absolute maximum and minimum 28. Application of maximum and minimum 29. Motion derivatives 30. Vertical motion 31. Mean value theorem 32. Approximating area with rectangles and trapezoids given a function 33. Approximating area with rectangles and trapezoids given a table of values 34. Determining if area approximations are over or under estimates 35. Finding definite integrals graphically 36. Finding definite integrals using given integral values 37. Indefinite integrals with power rule or special derivatives 38. Integration with u-substitution 39. Evaluating definite integrals 40. Definite integrals with u-substitution 41. Solving initial value problems (separable differential equations) 42. Creating a slope field 43. -

SUPPLEMENTARY MATERIAL: I. Fitting of the Hessian Matrix
Supplementary Material (ESI) for PCCP This journal is © the Owner Societies 2010 1 SUPPLEMENTARY MATERIAL: I. Fitting of the Hessian matrix In the fitting of the Hessian matrix elements as functions of the reaction coordinate, one can take advantage of symmetry. The non-diagonal elements may be written in the form of numerical derivatives as E(Δα, Δβ ) − E(Δα,−Δβ ) − E(−Δα, Δβ ) + E(−Δα,−Δβ ) H (α, β ) = . (S1) 4δ 2 Here, α and β label any of the 15 atomic coordinates in {Cx, Cy, …, H4z}, E(Δα,Δβ) denotes the DFT energy of CH4 interacting with Ni(111) with a small displacement along α and β, and δ the small displacement used in the second order differencing. For example, the H(Cx,Cy) (or H(Cy,Cx)) is 0, since E(ΔCx ,ΔC y ) = E(ΔC x ,−ΔC y ) and E(−ΔCx ,ΔC y ) = E(−ΔCx ,−ΔC y ) . From Eq.S1, one can deduce the symmetry properties of H of methane interacting with Ni(111) in a geometry belonging to the Cs symmetry (Fig. 1 in the paper): (1) there are always 18 zero elements in the lower triangle of the Hessian matrix (see Fig. S1), (2) the main block matrices A, B and F (see Fig. S1) can be split up in six 3×3 sub-blocks, namely A1, A2 , B1, B2, F1 and F2, in which the absolute values of all the corresponding elements in the sub-blocks corresponding to each other are numerically identical to each other except for the sign of their off-diagonal elements, (3) the triangular matrices E1 and E2 are also numerically the same except for the sign of their off-diagonal terms, (4) the 1 Supplementary Material (ESI) for PCCP This journal is © the Owner Societies 2010 2 block D is a unique block and its off-diagonal terms differ only from each other in their sign. -

EUCLIDEAN DISTANCE MATRIX COMPLETION PROBLEMS June 6
EUCLIDEAN DISTANCE MATRIX COMPLETION PROBLEMS HAW-REN FANG∗ AND DIANNE P. O’LEARY† June 6, 2010 Abstract. A Euclidean distance matrix is one in which the (i, j) entry specifies the squared distance between particle i and particle j. Given a partially-specified symmetric matrix A with zero diagonal, the Euclidean distance matrix completion problem (EDMCP) is to determine the unspecified entries to make A a Euclidean distance matrix. We survey three different approaches to solving the EDMCP. We advocate expressing the EDMCP as a nonconvex optimization problem using the particle positions as variables and solving using a modified Newton or quasi-Newton method. To avoid local minima, we develop a randomized initial- ization technique that involves a nonlinear version of the classical multidimensional scaling, and a dimensionality relaxation scheme with optional weighting. Our experiments show that the method easily solves the artificial problems introduced by Mor´e and Wu. It also solves the 12 much more difficult protein fragment problems introduced by Hen- drickson, and the 6 larger protein problems introduced by Grooms, Lewis, and Trosset. Key words. distance geometry, Euclidean distance matrices, global optimization, dimensional- ity relaxation, modified Cholesky factorizations, molecular conformation AMS subject classifications. 49M15, 65K05, 90C26, 92E10 1. Introduction. Given the distances between each pair of n particles in Rr, n r, it is easy to determine the relative positions of the particles. In many applications,≥ though, we are given only some of the distances and we would like to determine the missing distances and thus the particle positions. We focus in this paper on algorithms to solve this distance completion problem. -

Multivariable and Vector Calculus
Multivariable and Vector Calculus Lecture Notes for MATH 0200 (Spring 2015) Frederick Tsz-Ho Fong Department of Mathematics Brown University Contents 1 Three-Dimensional Space ....................................5 1.1 Rectangular Coordinates in R3 5 1.2 Dot Product7 1.3 Cross Product9 1.4 Lines and Planes 11 1.5 Parametric Curves 13 2 Partial Differentiations ....................................... 19 2.1 Functions of Several Variables 19 2.2 Partial Derivatives 22 2.3 Chain Rule 26 2.4 Directional Derivatives 30 2.5 Tangent Planes 34 2.6 Local Extrema 36 2.7 Lagrange’s Multiplier 41 2.8 Optimizations 46 3 Multiple Integrations ........................................ 49 3.1 Double Integrals in Rectangular Coordinates 49 3.2 Fubini’s Theorem for General Regions 53 3.3 Double Integrals in Polar Coordinates 57 3.4 Triple Integrals in Rectangular Coordinates 62 3.5 Triple Integrals in Cylindrical Coordinates 67 3.6 Triple Integrals in Spherical Coordinates 70 4 Vector Calculus ............................................ 75 4.1 Vector Fields on R2 and R3 75 4.2 Line Integrals of Vector Fields 83 4.3 Conservative Vector Fields 88 4.4 Green’s Theorem 98 4.5 Parametric Surfaces 105 4.6 Stokes’ Theorem 120 4.7 Divergence Theorem 127 5 Topics in Physics and Engineering .......................... 133 5.1 Coulomb’s Law 133 5.2 Introduction to Maxwell’s Equations 137 5.3 Heat Diffusion 141 5.4 Dirac Delta Functions 144 1 — Three-Dimensional Space 1.1 Rectangular Coordinates in R3 Throughout the course, we will use an ordered triple (x, y, z) to represent a point in the three dimensional space. -

Removing External Degrees of Freedom from Transition State
Removing External Degrees of Freedom from Transition State Search Methods using Quaternions Marko Melander1,2*, Kari Laasonen1,2, Hannes Jónsson3,4 1) COMP Centre of Excellence, Aalto University, FI-00076 Aalto, Finland 2) Department of Chemistry, Aalto University, FI-00076 Aalto, Finland 3) Department of Applied Physics, Aalto University, FI-00076 Aalto, Finland 4) Faculty of Physical Sciences, University of Iceland, 107 Reykjavík, Iceland 1 ABSTRACT In finite systems, such as nanoparticles and gas-phase molecules, calculations of minimum energy paths (MEP) connecting initial and final states of transitions as well as searches for saddle points are complicated by the presence of external degrees of freedom, such as overall translation and rotation. A method based on quaternion algebra for removing the external degrees of freedom is described here and applied in calculations using two commonly used methods: the nudged elastic band (NEB) method for finding minimum energy paths and DIMER method for finding the minimum mode in minimum mode following searches of first order saddle points. With the quaternion approach, fewer images in the NEB are needed to represent MEPs accurately. In both NEB and DIMER calculations of finite systems, the number of iterations required to reach convergence is significantly reduced. The algorithms have been implemented in the Atomic Simulation Environment (ASE) open source software. Keywords: Nudged Elastic Band, DIMER, quaternion, saddle point, transition. 2 1. INTRODUCTION Chemical reactions, diffusion events and configurational changes of molecules are transitions from some initial arrangement of the atoms to another, from an initial state minimum on the energy surface to a final state minimum. -
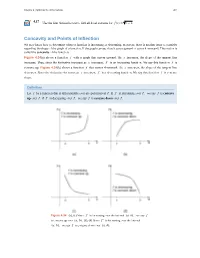
Concavity and Points of Inflection We Now Know How to Determine Where a Function Is Increasing Or Decreasing
Chapter 4 | Applications of Derivatives 401 4.17 3 Use the first derivative test to find all local extrema for f (x) = x − 1. Concavity and Points of Inflection We now know how to determine where a function is increasing or decreasing. However, there is another issue to consider regarding the shape of the graph of a function. If the graph curves, does it curve upward or curve downward? This notion is called the concavity of the function. Figure 4.34(a) shows a function f with a graph that curves upward. As x increases, the slope of the tangent line increases. Thus, since the derivative increases as x increases, f ′ is an increasing function. We say this function f is concave up. Figure 4.34(b) shows a function f that curves downward. As x increases, the slope of the tangent line decreases. Since the derivative decreases as x increases, f ′ is a decreasing function. We say this function f is concave down. Definition Let f be a function that is differentiable over an open interval I. If f ′ is increasing over I, we say f is concave up over I. If f ′ is decreasing over I, we say f is concave down over I. Figure 4.34 (a), (c) Since f ′ is increasing over the interval (a, b), we say f is concave up over (a, b). (b), (d) Since f ′ is decreasing over the interval (a, b), we say f is concave down over (a, b). 402 Chapter 4 | Applications of Derivatives In general, without having the graph of a function f , how can we determine its concavity? By definition, a function f is concave up if f ′ is increasing. -

Linear Algebra Review James Chuang
Linear algebra review James Chuang December 15, 2016 Contents 2.1 vector-vector products ............................................... 1 2.2 matrix-vector products ............................................... 2 2.3 matrix-matrix products ............................................... 4 3.2 the transpose .................................................... 5 3.3 symmetric matrices ................................................. 5 3.4 the trace ....................................................... 6 3.5 norms ........................................................ 6 3.6 linear independence and rank ............................................ 7 3.7 the inverse ...................................................... 7 3.8 orthogonal matrices ................................................. 8 3.9 range and nullspace of a matrix ........................................... 8 3.10 the determinant ................................................... 9 3.11 quadratic forms and positive semidefinite matrices ................................ 10 3.12 eigenvalues and eigenvectors ........................................... 11 3.13 eigenvalues and eigenvectors of symmetric matrices ............................... 12 4.1 the gradient ..................................................... 13 4.2 the Hessian ..................................................... 14 4.3 gradients and hessians of linear and quadratic functions ............................. 15 4.5 gradients of the determinant ............................................ 16 4.6 eigenvalues -

Chapter 8. Eigenvalues: Further Applications and Computations
8.1 Diagonalization of Quadratic Forms 1 Chapter 8. Eigenvalues: Further Applications and Computations 8.1. Diagonalization of Quadratic Forms Note. In this section we define a quadratic form and relate it to a vector and ma- trix product. We define diagonalization of a quadratic form and give an algorithm to diagonalize a quadratic form. The fact that every quadratic form can be diago- nalized (using an orthogonal matrix) is claimed by the “Principal Axis Theorem” (Theorem 8.1). It is applied in Section 8.2 to address quadratic surfaces. Definition. A quadratic form f(~x) = f(x1, x2,...,xn) in n variables is a polyno- mial that can be written as n f(~x)= u x x X ij i j i,j=1; i≤j where not all uij are zero. Note. For n = 2, a quadratic form is f(x, y)= ax2 + bxy + xy2. The graph of such an equation in the xy-plane is a conic section (ellipse, hyperbola, or parabola). For n = 3, we have 2 2 2 f(x1, x2, x3)= u11x1 + u12x1x2 + u13x1x3 + u22x2 + u23x2x3 + u33x2. We’ll see in the next section that the graph of f(x1, x2, x3) is a quadric surface. We 8.1 Diagonalization of Quadratic Forms 2 can easily verify that u11 u12 u13 x1 [f(x1, x2, x3)]= [x1, x2, x3] 0 u22 u23 x2 . 0 0 u33 x3 Definition. In the quadratic form ~xT U~x, the matrix U is the upper-triangular coefficient matrix of the quadratic form. Example. Page 417 Number 4(a). -

An Introduction to the HESSIAN
An introduction to the HESSIAN 2nd Edition Photograph of Ludwig Otto Hesse (1811-1874), circa 1860 https://upload.wikimedia.org/wikipedia/commons/6/65/Ludwig_Otto_Hesse.jpg See page for author [Public domain], via Wikimedia Commons I. As the students of the first two years of mathematical analysis well know, the Wronskian, Jacobian and Hessian are the names of three determinants and matrixes, which were invented in the nineteenth century, to make life easy to the mathematicians and to provide nightmares to the students of mathematics. II. I don’t know how the Hessian came to the mind of Ludwig Otto Hesse (1811-1874), a quiet professor father of nine children, who was born in Koenigsberg (I think that Koenigsberg gave birth to a disproportionate 1 number of famous men). It is possible that he was studying the problem of finding maxima, minima and other anomalous points on a bi-dimensional surface. (An alternative hypothesis will be presented in section X. ) While pursuing such study, in one variable, one first looks for the points where the first derivative is zero (if it exists at all), and then examines the second derivative at each of those points, to find out its “quality”, whether it is a maximum, a minimum, or an inflection point. The variety of anomalies on a bi-dimensional surface is larger than for a one dimensional line, and one needs to employ more powerful mathematical instruments. Still, also in two dimensions one starts by looking for points where the two first partial derivatives, with respect to x and with respect to y respectively, exist and are both zero. -

Calculus Terminology
AP Calculus BC Calculus Terminology Absolute Convergence Asymptote Continued Sum Absolute Maximum Average Rate of Change Continuous Function Absolute Minimum Average Value of a Function Continuously Differentiable Function Absolutely Convergent Axis of Rotation Converge Acceleration Boundary Value Problem Converge Absolutely Alternating Series Bounded Function Converge Conditionally Alternating Series Remainder Bounded Sequence Convergence Tests Alternating Series Test Bounds of Integration Convergent Sequence Analytic Methods Calculus Convergent Series Annulus Cartesian Form Critical Number Antiderivative of a Function Cavalieri’s Principle Critical Point Approximation by Differentials Center of Mass Formula Critical Value Arc Length of a Curve Centroid Curly d Area below a Curve Chain Rule Curve Area between Curves Comparison Test Curve Sketching Area of an Ellipse Concave Cusp Area of a Parabolic Segment Concave Down Cylindrical Shell Method Area under a Curve Concave Up Decreasing Function Area Using Parametric Equations Conditional Convergence Definite Integral Area Using Polar Coordinates Constant Term Definite Integral Rules Degenerate Divergent Series Function Operations Del Operator e Fundamental Theorem of Calculus Deleted Neighborhood Ellipsoid GLB Derivative End Behavior Global Maximum Derivative of a Power Series Essential Discontinuity Global Minimum Derivative Rules Explicit Differentiation Golden Spiral Difference Quotient Explicit Function Graphic Methods Differentiable Exponential Decay Greatest Lower Bound Differential