Psychoacoustics & Hearing
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Modeling of the Head-Related Transfer Functions for Reduced Computation and Storage Charles Duncan Lueck Iowa State University
Iowa State University Capstones, Theses and Retrospective Theses and Dissertations Dissertations 1995 Modeling of the head-related transfer functions for reduced computation and storage Charles Duncan Lueck Iowa State University Follow this and additional works at: https://lib.dr.iastate.edu/rtd Part of the Electrical and Electronics Commons Recommended Citation Lueck, Charles Duncan, "Modeling of the head-related transfer functions for reduced computation and storage " (1995). Retrospective Theses and Dissertations. 10929. https://lib.dr.iastate.edu/rtd/10929 This Dissertation is brought to you for free and open access by the Iowa State University Capstones, Theses and Dissertations at Iowa State University Digital Repository. It has been accepted for inclusion in Retrospective Theses and Dissertations by an authorized administrator of Iowa State University Digital Repository. For more information, please contact [email protected]. INFORMATION TO USERS This mamiscr^t has been reproduced fFom the microfilin master. UMI films the text directly from the origmal or copy submitted. Thus, some thesis and dissertation copies are in typewriter face, while others may be from ai^ type of con^ter printer. Hie qnallQr of this repfodnction is dqiendent opon the quality of the copy submitted. Broken or indistinct print, colored or poor quality illustrations and photographs, prim bleedthroug^ substandard marginc^ and in^^rqper alignment can adverse^ affect rq)roduction. In the unlikely event that the author did not send UMI a complete manuscript and there are missing pages, these will be noted. Also, if unauthorized copyri^t material had to be removed, a note will indicate the deletion. Oversize materials (e.g^ maps, drawings, charts) are reproduced sectioning the original, beginning at the upper left-hand comer and continuing from left to light in equal sections with small overk^ Each original is also photogrs^hed in one exposure and is included in reduced form at the bade of the book. -

Underwater Acoustics: Webinar Series for the International Regulatory Community
Underwater Acoustics: Webinar Series for the International Regulatory Community Webinar Outline: Marine Animal Sound Production and Reception Thursday, December 3, 2015 at 12:00pm (US East Coast Time) Sound production and reception in teleost fish (M. Clara P. Amorim, Ispa – Instituto Universitário) • Teleost fish are likely the largest vocal vertebrate group. Sounds made by fish can be an important part of marine soundscapes. • Fish possess the most diversified sonic mechanisms among vertebrates, which include the vibration of the swim bladder through intrinsic or extrinsic sonic muscles, as well as the rubbing of bony elements. • Fish sounds are usually pulsed (each sonic muscle contraction corresponds to a sound pulse), short (typically shorter than 1 s) and broadband (with most energy below 1 kHz), although some fish produce tonal sounds. Sounds generated by bony elements are often higher frequency (up to a few kHz). • In contrast with terrestrial vertebrates, fish have no external or middle ear. Fish detect sounds with the inner ear, which comprises three semicircular canals and three otolithic end organs, the utricle, the saccule and the lagena. Fish mostly detect particle motion and hear up to 1 kHz. Some species have evolved accessory auditory structures that serve as pressures transducers and present enhanced hearing sensitivity and increased frequency detection up to several kHz. Fish hearing seems to have evolved independently of sound production and is important to detect the ‘auditory scene’. • Acoustic signals are produced during social interactions or during distress situations as in insects or other vertebrates. Sounds are important in mate attraction, courtship and spawning or to defend a territory and gain access to food. -

Separation of Vocal and Non-Vocal Components from Audio Clip Using Correlated Repeated Mask (CRM)
University of New Orleans ScholarWorks@UNO University of New Orleans Theses and Dissertations Dissertations and Theses Summer 8-9-2017 Separation of Vocal and Non-Vocal Components from Audio Clip Using Correlated Repeated Mask (CRM) Mohan Kumar Kanuri [email protected] Follow this and additional works at: https://scholarworks.uno.edu/td Part of the Signal Processing Commons Recommended Citation Kanuri, Mohan Kumar, "Separation of Vocal and Non-Vocal Components from Audio Clip Using Correlated Repeated Mask (CRM)" (2017). University of New Orleans Theses and Dissertations. 2381. https://scholarworks.uno.edu/td/2381 This Thesis is protected by copyright and/or related rights. It has been brought to you by ScholarWorks@UNO with permission from the rights-holder(s). You are free to use this Thesis in any way that is permitted by the copyright and related rights legislation that applies to your use. For other uses you need to obtain permission from the rights- holder(s) directly, unless additional rights are indicated by a Creative Commons license in the record and/or on the work itself. This Thesis has been accepted for inclusion in University of New Orleans Theses and Dissertations by an authorized administrator of ScholarWorks@UNO. For more information, please contact [email protected]. Separation of Vocal and Non-Vocal Components from Audio Clip Using Correlated Repeated Mask (CRM) A Thesis Submitted to the Graduate Faculty of the University of New Orleans in partial fulfillment of the requirements for the degree of Master of Science in Engineering – Electrical By Mohan Kumar Kanuri B.Tech., Jawaharlal Nehru Technological University, 2014 August 2017 This thesis is dedicated to my parents, Mr. -

Advance and Unedited Reporting Material (English Only)
13 March 2018 (corr.) Advance and unedited reporting material (English only) Seventy-third session Oceans and the law of the sea Report of the Secretary-General Summary In paragraph 339 of its resolution 71/257, as reiterated in paragraph 354 of resolution 72/73, the General Assembly decided that the United Nations Open-ended Informal Consultative Process on Oceans and the Law of the Sea would focus its discussions at its nineteenth meeting on the topic “Anthropogenic underwater noise”. The present report was prepared pursuant to paragraph 366 of General Assembly resolution 72/73 with a view to facilitating discussions on the topic of focus. It is being submitted for consideration by the General Assembly and also to the States parties to the United Nations Convention on the Law of the Sea, pursuant to article 319 of the Convention. Contents Page I. Introduction ............................................................... II. Nature and sources of anthropogenic underwater noise III. Environmental and socioeconomic aspects IV. Current activities and further needs with regard to cooperation and coordination in addressing anthropogenic underwater noise V. Conclusions ............................................................... 2 I. Introduction 1. The marine environment is subject to a wide array of human-made noise. Many human activities with socioeconomic significance introduce sound into the marine environment either intentionally for a specific purpose (e.g., seismic surveys) or unintentionally as a by-product of their activities (e.g., shipping). In addition, there is a range of natural sound sources from physical and biological origins such as wind, waves, swell patterns, currents, earthquakes, precipitation and ice, as well as the sounds produced by marine animals for communication, orientation, navigation and foraging. -

1 Study Guide for Unit 5 (Hearing, Audition, Music and Speech). Be
Psychology of Perception Lewis O. Harvey, Jr.–Instructor Psychology 4165-100 Andrew J. Mertens –Teaching Assistant Spring 2021 11:10–12:25 Tuesday, Thursday Study Guide for Unit 5 (hearing, audition, music and speech). Be able to answer the following questions and be familiar with the concepts involved in the answers. Review your textbook reading, lectures, homework and lab assignments and be familiar with the concepts included in them. 1. Diagram the three parts of the auditory system: Outer, middle and inner ear. How is sound mapped onto the basilar membrane? Know these terms: pinna, concha, external auditory canal, tympanic membrane, maleus, incus, stapes, semicircular canals, oval and round windows, cochlea, basilar membrane, organ of Corti, Eustachian tube, inner, outer hair cells. 2. What are the three main physical dimensions of the sound stimulus? What are the three main psychological dimensions of the sound experience? What are the relationships and interdependencies among them? 3. How does the basilar membrane carry out a frequency analysis of the physical sound stimulus? 4. What are roles of the inner and the outer hair cells on the organ of Corti? 5. What is the critical band? Describe three different methods for measuring the critical band. 6. According to Plomp and Levelt (1965), how far apart in frequency must two sine wave tones be in order to sound maximally unpleasant? Why do some musical notes (e.g., the octave or the fifth) sound consonant when played together with the tonic and some other notes (e.g., the second or the seventh) sound dissonant when played with the tonic? 7. -

Large Scale Sound Installation Design: Psychoacoustic Stimulation
LARGE SCALE SOUND INSTALLATION DESIGN: PSYCHOACOUSTIC STIMULATION An Interactive Qualifying Project Report submitted to the Faculty of the WORCESTER POLYTECHNIC INSTITUTE in partial fulfillment of the requirements for the Degree of Bachelor of Science by Taylor H. Andrews, CS 2012 Mark E. Hayden, ECE 2012 Date: 16 December 2010 Professor Frederick W. Bianchi, Advisor Abstract The brain performs a vast amount of processing to translate the raw frequency content of incoming acoustic stimuli into the perceptual equivalent. Psychoacoustic processing can result in pitches and beats being “heard” that do not physically exist in the medium. These psychoac- oustic effects were researched and then applied in a large scale sound design. The constructed installations and acoustic stimuli were designed specifically to combat sensory atrophy by exer- cising and reinforcing the listeners’ perceptual skills. i Table of Contents Abstract ............................................................................................................................................ i Table of Contents ............................................................................................................................ ii Table of Figures ............................................................................................................................. iii Table of Tables .............................................................................................................................. iv Chapter 1: Introduction ................................................................................................................. -

The Audiogram
Recently,Recently, I’veI’ve been trying to orga- evaluations, and they are truly im- nize some of the columns and articles pressive, the information and insights RI’veI’ve written overover the past ten years.years. provided by the simple audiogram As I was looking through them, it be- can still provide the most pertinent came apparent that I’ve neglected to information to explain the behavioral discuss what is perhaps the implications of a hearing loss. most important hearing di- Perhaps the most important in- mension of all, the simple sight of all is an appreciation of how The audiogram. specifi c audiograms impact upon the In reality, however, perception of certain speech sounds. the “simple” audiogram, Without including speech in the Audiogram: and particularly its im- equation, it is simply not possible to Audiogram: plications, is not quite so intelligibly discuss the audiogram. simple. Even though just This, after all, is the signal we are about everybody who re- most interested in hearing (not to Explanation ceives a hearing aid has his minimize the specifi c needs of certain or her hearing tested with groups of people for other types of a pure-tone audiometer, sounds, such as musicians). and not everybody receives a comprehensive explanation Figure One Audiogram — of exactly what the results The “Speech Banana” Signifi cance mean and what the impli- cations are for them. The audiogram of a fairly typical And even for those who audiogram can be seen in Figure 1. do, at a time when prospec- (My thanks to Brad Ingrao for creat- By Mark Ross tive hearing aid purchasers ing these fi gures for me.) Let’s fi rst go are being inundated with through the fundamentals. -

Appendix J Fish Hearing and Sensitivity to Acoustic
APPENDIX J FISH HEARING AND SENSITIVITY TO ACOUSTIC IMPACTS Fish Hearing and Sensitivity to Acoustic Impacts J-iii TABLE OF CONTENTS Page 1. INTRODUCTION ............................................................................................................................ J-1 1.1. What is Injury for Fishes?........................................................................................................ J-1 1.2. Fish........................................................................................................................................... J-1 1.3. Fish Bioacoustics – Overview.................................................................................................. J-2 1.4. Metrics of Sound Exposure...................................................................................................... J-2 2. BACKGROUND ON FISH HEARING........................................................................................... J-3 2.1. Sound in Water ........................................................................................................................ J-3 2.2. Hearing Sensitivity................................................................................................................... J-3 2.3. Other Aspects of Fish Hearing................................................................................................. J-7 3. EFFECTS OF HUMAN-GENERATED SOUND ON FISHES – OVERVIEW ............................. J-8 4. EFFECTS OF ANTHROPOGENIC SOUNDS ON HEARING ..................................................... -
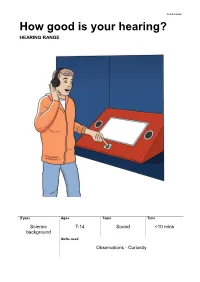
How Good Is Your Hearing? HEARING RANGE
Exhibit Sheet How good is your hearing? HEARING RANGE (Type) Ages Topic Time Science 7-14 Sound <10 mins background Skills used Observations - Curiosity Overview for adults Hearing Range lets you test your hearing. As you listen through headphones, sounds of different frequencies are played, starting quietly and getting louder. You press a button when you hear the sound and at the end get an estimate of your “hearing age”. What’s the science? Frequency is the number of sound waves per second. It’s measured in hertz (Hz). Humans can hear sounds at frequencies between 20 hertz (a cat purring) and 20,000 hertz (a bat squeaking). The sounds you can hear are linked to your age. An 8-year-old hears the widest range of sounds. Then, as you get older, it becomes harder to hear high-frequency sounds. Science in your world Different animals have different hearing ranges. Dogs and cats can hear much higher sounds than we can – up to 50,000hz. That’s why dog whistles work. They produce really high frequency sounds that we can’t hear but dogs can hear them loud and clear. Things to think and talk about … Why do you think hearing gets worse as you get older? What could make your hearing better or worse? Things to investigate … How good is your hearing? Who the best hearing in your group? Are they the youngest? Museum links When microphones were invented, they could only pick up small ranges of frequencies. To record people speaking, you needed lots of different microphones of different sizes – from tiny ones to pick up high frequency sounds to big ones to pick up the low frequency sounds. -

The Human Ear Hearing, Sound Intensity and Loudness Levels
UIUC Physics 406 Acoustical Physics of Music The Human Ear Hearing, Sound Intensity and Loudness Levels We’ve been discussing the generation of sounds, so now we’ll discuss the perception of sounds. Human Senses: The astounding ~ 4 billion year evolution of living organisms on this planet, from the earliest single-cell life form(s) to the present day, with our current abilities to hear / see / smell / taste / feel / etc. – all are the result of the evolutionary forces of nature associated with “survival of the fittest” – i.e. it is evolutionarily{very} beneficial for us to be able to hear/perceive the natural sounds that do exist in the environment – it helps us to locate/find food/keep from becoming food, etc., just as vision/sight enables us to perceive objects in our 3-D environment, the ability to move /locomote through the environment enhances our ability to find food/keep from becoming food; Our sense of balance, via a stereo-pair (!) of semi-circular canals (= inertial guidance system!) helps us respond to 3-D inertial forces (e.g. gravity) and maintain our balance/avoid injury, etc. Our sense of taste & smell warn us of things that are bad to eat and/or breathe… Human Perception of Sound: * The human ear responds to disturbances/temporal variations in pressure. Amazingly sensitive! It has more than 6 orders of magnitude in dynamic range of pressure sensitivity (12 orders of magnitude in sound intensity, I p2) and 3 orders of magnitude in frequency (20 Hz – 20 KHz)! * Existence of 2 ears (stereo!) greatly enhances 3-D localization of sounds, and also the determination of pitch (i.e. -

Psychological Measurement for Sound Description and Evaluation 11
11 Psychological measurement for sound description and evaluation Patrick Susini,1 Guillaume Lemaitre,1 and Stephen McAdams2 1Institut de Recherche et de Coordination Acoustique/Musique Paris, France 2CIRMMT, Schulich School of Music, McGill University Montréal, Québec, Canada 11.1 Introduction Several domains of application require one to measure quantities that are representa- tive of what a human listener perceives. Sound quality evaluation, for instance, stud- ies how users perceive the quality of the sounds of industrial objects (cars, electrical appliances, electronic devices, etc.), and establishes specifications for the design of these sounds. It refers to the fact that the sounds produced by an object or product are not only evaluated in terms of annoyance or pleasantness, but are also important in people’s interactions with the object. Practitioners of sound quality evaluation therefore need methods to assess experimentally, or automatic tools to predict, what users perceive and how they evaluate the sounds. There are other applications requir- ing such measurement: evaluation of the quality of audio algorithms, management (organization, retrieval) of sound databases, and so on. For example, sound-database retrieval systems often require measurements of relevant perceptual qualities; the searching process is performed automatically using similarity metrics based on rel- evant descriptors stored as metadata with the sounds in the database. The “perceptual” qualities of the sounds are called the auditory attributes, which are defined as percepts that can be ordered on a magnitude scale. Historically, the notion of auditory attribute is grounded in the framework of psychoacoustics. Psychoacoustical research aims to establish quantitative relationships between the physical properties of a sound (i.e., the properties measured by the methods and instruments of the natural sciences) and the perceived properties of the sounds, the auditory attributes. -

A Biological Rationale for Musical Consonance Daniel L
PERSPECTIVE PERSPECTIVE A biological rationale for musical consonance Daniel L. Bowlinga,1 and Dale Purvesb,1 aDepartment of Cognitive Biology, University of Vienna, 1090 Vienna, Austria; and bDuke Institute for Brain Sciences, Duke University, Durham, NC 27708 Edited by Solomon H. Snyder, Johns Hopkins University School of Medicine, Baltimore, MD, and approved June 25, 2015 (received for review March 25, 2015) The basis of musical consonance has been debated for centuries without resolution. Three interpretations have been considered: (i) that consonance derives from the mathematical simplicity of small integer ratios; (ii) that consonance derives from the physical absence of interference between harmonic spectra; and (iii) that consonance derives from the advantages of recognizing biological vocalization and human vocalization in particular. Whereas the mathematical and physical explanations are at odds with the evidence that has now accumu- lated, biology provides a plausible explanation for this central issue in music and audition. consonance | biology | music | audition | vocalization Why we humans hear some tone combina- perfect fifth (3:2), and the perfect fourth revolution in the 17th century, which in- tions as relatively attractive (consonance) (4:3), ratios that all had spiritual and cos- troduced a physical understanding of musi- and others as less attractive (dissonance) has mological significance in Pythagorean phi- cal tones. The science of sound attracted been debated for over 2,000 years (1–4). losophy (9, 10). many scholars of that era, including Vincenzo These perceptual differences form the basis The mathematical range of Pythagorean and Galileo Galilei, Renee Descartes, and of melody when tones are played sequen- consonance was extended in the Renaissance later Daniel Bernoulli and Leonard Euler.