Raag Detection in Music Using Supervised Machine Learning Approach
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

1 Syllabus for MA (Previous) Hindustani Music Vocal/Instrumental
Syllabus for M.A. (Previous) Hindustani Music Vocal/Instrumental (Sitar, Sarod, Guitar, Violin, Santoor) SEMESTER-I Core Course – 1 Theory Credit - 4 Theory : 70 Internal Assessment : 30 Maximum Marks : 100 Historical and Theoretical Study of Ragas 70 Marks A. Historical Study of the following Ragas from the period of Sangeet Ratnakar onwards to modern times i) Gaul/Gaud iv) Kanhada ii) Bhairav v) Malhar iii) Bilawal vi) Todi B. Development of Raga Classification system in Ancient, Medieval and Modern times. C. Study of the following Ragangas in the modern context:- Sarang, Malhar, Kanhada, Bhairav, Bilawal, Kalyan, Todi. D. Detailed and comparative study of the Ragas prescribed in Appendix – I Internal Assessment 30 marks Core Course – 2 Theory Credit - 4 Theory : 70 Internal Assessment : 30 Maximum Marks : 100 Music of the Asian Continent 70 Marks A. Study of the Music of the following - China, Arabia, Persia, South East Asia, with special reference to: i) Origin, development and historical background of Music ii) Musical scales iii) Important Musical Instruments B. A comparative study of the music systems mentioned above with Indian Music. Internal Assessment 30 marks Core Course – 3 Practical Credit - 8 Practical : 70 Internal Assessment : 30 Maximum Marks : 100 Stage Performance 70 marks Performance of half an hour’s duration before an audience in Ragas selected from the list of Ragas prescribed in Appendix – I Candidate may plan his/her performance in the following manner:- Classical Vocal Music i) Khyal - Bada & chota Khyal with elaborations for Vocal Music. Tarana is optional. Classical Instrumental Music ii) Alap, Jor, Jhala, Masitkhani and Razakhani Gat with eleaborations Semi Classical Music iii) A short piece of classical music /Thumri / Bhajan/ Dhun /a gat in a tala other than teentaal may also be presented. -
Note Staff Symbol Carnatic Name Hindustani Name Chakra Sa C
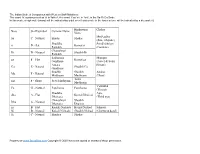
The Indian Scale & Comparison with Western Staff Notations: The vowel 'a' is pronounced as 'a' in 'father', the vowel 'i' as 'ee' in 'feet', in the Sa-Ri-Ga Scale In this scale, a high note (swara) will be indicated by a dot over it and a note in the lower octave will be indicated by a dot under it. Hindustani Chakra Note Staff Symbol Carnatic Name Name MulAadhar Sa C - Natural Shadaj Shadaj (Base of spine) Shuddha Swadhishthan ri D - flat Komal ri Rishabh (Genitals) Chatushruti Ri D - Natural Shudhh Ri Rishabh Sadharana Manipur ga E - Flat Komal ga Gandhara (Navel & Solar Antara Plexus) Ga E - Natural Shudhh Ga Gandhara Shudhh Shudhh Anahat Ma F - Natural Madhyam Madhyam (Heart) Tivra ma F - Sharp Prati Madhyam Madhyam Vishudhh Pa G - Natural Panchama Panchama (Throat) Shuddha Ajna dha A - Flat Komal Dhaivat Dhaivata (Third eye) Chatushruti Shudhh Dha A - Natural Dhaivata Dhaivat ni B - Flat Kaisiki Nishada Komal Nishad Sahsaar Ni B - Natural Kakali Nishada Shudhh Nishad (Crown of head) Så C - Natural Shadaja Shadaj Property of www.SarodSitar.com Copyright © 2010 Not to be copied or shared without permission. Short description of Few Popular Raags :: Sanskrut (Sanskrit) pronunciation is Raag and NOT Raga (Alphabetical) Aroha Timing Name of Raag (Karnataki Details Avroha Resemblance) Mood Vadi, Samvadi (Main Swaras) It is a old raag obtained by the combination of two raags, Ahiri Sa ri Ga Ma Pa Ga Ma Dha ni Så Ahir Bhairav Morning & Bhairav. It belongs to the Bhairav Thaat. Its first part (poorvang) has the Bhairav ang and the second part has kafi or Så ni Dha Pa Ma Ga ri Sa (Chakravaka) serious, devotional harpriya ang. -

Fusion Without Confusion Raga Basics Indian
Fusion Without Confusion Raga Basics Indian Rhythm Basics Solkattu, also known as konnakol is the art of performing percussion syllables vocally. It comes from the Carnatic music tradition of South India and is mostly used in conjunction with instrumental music and dance instruction, although it has been widely adopted throughout the world as a modern composition and performance tool. Similarly, the music of North India has its own system of rhythm vocalization that is based on Bols, which are the vocalization of specific sounds that correspond to specific sounds that are made on the drums of North India, most notably the Tabla drums. Like in the south, the bols are used in musical training, as well as composition and performance. In addition, solkattu sounds are often referred to as bols, and the practice of reciting bols in the north is sometimes referred to as solkattu, so the distinction between the two practices is blurred a bit. The exercises and compositions we will discuss contain bols that are found in both North and South India, however they come from the tradition of the North Indian tabla drums. Furthermore, the theoretical aspect of the compositions is distinctly from the Hindustani, (north Indian) tradition. Hence, for the purpose of this presentation, the use of the term Solkattu refers to the broader, more general practice of Indian rhythmic language. South Indian Percussion Mridangam Dolak Kanjira Gattam North Indian Percussion Tabla Baya (a.k.a. Tabla) Pakhawaj Indian Rhythm Terms Tal (also tala, taal, or taala) – The Indian system of rhythm. Tal literally means "clap". -

Modeling a Performance in Indian Classical Music: Multinomial
Archive of Cornell University e-library; arXiv:0809.3214v1[cs.SD][stat.AP]. http://arxiv.org/abs/0809.3214 A Statistical Approach to Modeling Indian Classical Music Performance 1Soubhik Chakraborty*, 2Sandeep Singh Solanki, 3Sayan Roy, 4Shivee Chauhan, 5Sanjaya Shankar Tripathy and 6Kartik Mahto 1Department of Applied Mathematics, BIT Mesra, Ranchi-835215, India 2, 3, 4, 5,6Department of Electronics and Communication Engineering, BIT Mesra, Ranchi-835215, India Email:[email protected](S.Chakraborty) [email protected] (S.S. Solanki) [email protected](S. Roy) [email protected](S. Chauhan) [email protected] (S.S.Tripathy) [email protected] *S. Chakraborty is the corresponding author (phone: +919835471223) Words make you think a thought. Music makes you feel a feeling. A song makes you feel a thought. -------- E. Y. Harburg (1898-1981) Abstract A raga is a melodic structure with fixed notes and a set of rules characterizing a certain mood endorsed through performance. By a vadi swar is meant that note which plays the most significant role in expressing the raga. A samvadi swar similarly is the second most significant note. However, the determination of their significance has an element of subjectivity and hence we are motivated to find some truths through an objective analysis. The paper proposes a probabilistic method of note detection and demonstrates how the relative frequency (relative number of occurrences of the pitch) of the more important notes stabilize far more quickly than that of others. In addition, a count for distinct transitory and similar looking non-transitory (fundamental) frequency movements (but possibly embedding distinct emotions!) between the notes is also taken depicting the varnalankars or musical ornaments decorating the notes and note sequences as rendered by the artist. -

Hindustani Classic Music
HINDUSTANI CLASSIC MUSIC: Junior Grade or Prathamik : Syllabus : No theory exam in this grade Swarajnana Talajnana essential Ragajnana Practicals: 1. Beginning of swarabyasa - in three layas 2. 2 Swaramalikas 5 Lakshnageete Chotakyal Alap - 4 ragas Than - 4 Drupad - should be practiced 3. Bhajan - Vachana - Dasapadas 4. Theental, Dadara, Ektal (Dhruth), Chontal, Juptal, Kheruva Talu - Sam-Pet-Husi-Matras - should practice Tekav. 5. Swarajnana 6. Knowledge of the words - nada, shruthi, Aroha, Avaroha, Vadi - Samvedi, Komal - Theevra - Shuddha - Sasthak - Ganasamay - Thaat - Varjya. 7. Swaralipi - should be learnt. Senior Grade: (Madhyamik) Syllabus : Theory: 1. Paribhashika words 2. Sound & place of emergence of sound 3. The practice of different ragas out of “thaat” - based on Pandith Venkatamukhi Mela System 4. To practice ragalaskhanas of different ragas 5. Different Talas - 9 (Trital, Dadra, Jup, Kherva, Chantal, Tilawad, Roopak, Damar, Deepchandi) explanation of talas with Tekas. 6. Chotakhyal, Badakhyal, Bhajan, Tumari, Geethprakaras - Lakshanas. 7. Life history of Jayadev, Sarangdev, Surdas, Purandaradas, Tansen, Akkamahadevi, Sadarang, Kabeer, Meera, Haridas. 8. Knowledge of musical instrument Practicals: 1. Among 20 ragas - Chotakhyal in each 2. Badakhyal - for 10 ragas (Bhoopali, Yamani, Bheempalas, Bageshree, Malkonnse, Alhaiah Bilawal, Bahar, Kedar, Poorvi, Shankara. 3. Learn to sing one drupad in Tay, Dugun & Changun - one Damargeete. VIDHWAN PROFICIENCY Syllabus: Theory 1. Paribhashika Shabdas. 2. 7 types of Talas - their parts (angas) 3. Tabala bol - Tala Jnana, Vilambitha Ektal, Jumra, Adachontal, Savari, Panjabi, Tappa. 4. Raga lakshanas of Bhairav, Shuddha Sarang, Peelu, Multhani, Sindura, Adanna, Jogiya, Hamsadhwani, Gandamalhara, Ragashree, Darbari, Kannada, Basanthi, Ahirbhairav, Todi etc., Alap, Swaravisthara, Sama Prakruthi, Ragas criticism, Gana samay - should be known. -

Evaluation of the Effects of Music Therapy Using Todi Raga of Hindustani Classical Music on Blood Pressure, Pulse Rate and Respiratory Rate of Healthy Elderly Men
Volume 64, Issue 1, 2020 Journal of Scientific Research Institute of Science, Banaras Hindu University, Varanasi, India. Evaluation of the Effects of Music Therapy Using Todi Raga of Hindustani Classical Music on Blood Pressure, Pulse Rate and Respiratory Rate of Healthy Elderly Men Samarpita Chatterjee (Mukherjee) 1, and Roan Mukherjee2* 1 Department of Hindustani Classical Music (Vocal), Sangit-Bhavana, Visva-Bharati (A Central University), Santiniketan, Birbhum-731235,West Bengal, India 2 Department of Human Physiology, Hazaribag College of Dental Sciences and Hospital, Demotand, Hazaribag 825301, Jharkhand, India. [email protected] Abstract Several studies have indicated that music therapy may affect I. INTRODUCTION cardiovascular health; in particular, it may bring positive changes Music may be regarded as the projection of ideas as well as in blood pressure levels and heart rate, thereby improving the emotions through significant sounds produced by an instrument, overall quality of life. Hence, to regulate blood pressure, music voices, or both by taking into consideration different elements of therapy may be regarded as a significant complementary and alternative medicine (CAM). The respiratory rate, if maintained melody, rhythm, and harmony. Music plays an important role in within the normal range, may promote good cardiac health. The everyone’s life. Music has the power to make one experience aim of the present study was to evaluate the changes in blood harmony, emotional ecstasy, spiritual uplifting, positive pressure, pulse rate and respiratory rate in healthy and disease-free behavioral changes, and absolute tranquility. The annoyance in males (age 50-60 years), at the completion of 30 days of music life may increase in lack of melody and harmony. -

Track Name Singers VOCALS 1 RAMKALI Pt. Bhimsen Joshi 2 ASAWARI TODI Pt
Track name Singers VOCALS 1 RAMKALI Pt. Bhimsen Joshi 2 ASAWARI TODI Pt. Bhimsen Joshi 3 HINDOLIKA Pt. Bhimsen Joshi 4 Thumri-Bhairavi Pt. Bhimsen Joshi 5 SHANKARA MANIK VERMA 6 NAT MALHAR MANIK VERMA 7 POORIYA MANIK VERMA 8 PILOO MANIK VERMA 9 BIHAGADA PANDIT JASRAJ 10 MULTANI PANDIT JASRAJ 11 NAYAKI KANADA PANDIT JASRAJ 12 DIN KI PURIYA PANDIT JASRAJ 13 BHOOPALI MALINI RAJURKAR 14 SHANKARA MALINI RAJURKAR 15 SOHONI MALINI RAJURKAR 16 CHHAYANAT MALINI RAJURKAR 17 HAMEER MALINI RAJURKAR 18 ADANA MALINI RAJURKAR 19 YAMAN MALINI RAJURKAR 20 DURGA MALINI RAJURKAR 21 KHAMAJ MALINI RAJURKAR 22 TILAK-KAMOD MALINI RAJURKAR 23 BHAIRAVI MALINI RAJURKAR 24 ANAND BHAIRAV PANDIT JITENDRA ABHISHEKI 25 RAAG MALA PANDIT JITENDRA ABHISHEKI 26 KABIR BHAJAN PANDIT JITENDRA ABHISHEKI 27 SHIVMAT BHAIRAV PANDIT JITENDRA ABHISHEKI 28 LALIT BEGUM PARVEEN SULTANA 29 JOG BEGUM PARVEEN SULTANA 30 GUJRI JODI BEGUM PARVEEN SULTANA 31 KOMAL BHAIRAV BEGUM PARVEEN SULTANA 32 MARUBIHAG PANDIT VASANTRAO DESHPANDE 33 THUMRI MISHRA KHAMAJ PANDIT VASANTRAO DESHPANDE 34 JEEVANPURI PANDIT KUMAR GANDHARVA 35 BAHAR PANDIT KUMAR GANDHARVA 36 DHANBASANTI PANDIT KUMAR GANDHARVA 37 DESHKAR PANDIT KUMAR GANDHARVA 38 GUNAKALI PANDIT KUMAR GANDHARVA 39 BILASKHANI-TODI PANDIT KUMAR GANDHARVA 40 KAMOD PANDIT KUMAR GANDHARVA 41 MIYA KI TODI USTAD RASHID KHAN 42 BHATIYAR USTAD RASHID KHAN 43 MIYA KI TODI USTAD RASHID KHAN 44 BHATIYAR USTAD RASHID KHAN 45 BIHAG ASHWINI BHIDE-DESHPANDE 46 BHINNA SHADAJ ASHWINI BHIDE-DESHPANDE 47 JHINJHOTI ASHWINI BHIDE-DESHPANDE 48 NAYAKI KANADA ASHWINI -

The Thaat-Ragas of North Indian Classical Music: the Basic Atempt to Perform Dr
The Thaat-Ragas of North Indian Classical Music: The Basic Atempt to Perform Dr. Sujata Roy Manna ABSTRACT Indian classical music is divided into two streams, Hindustani music and Carnatic music. Though the rules and regulations of the Indian Shastras provide both bindings and liberties for the musicians, one can use one’s innovations while performing. As the Indian music requires to be learnt under the guidance of Master or Guru, scriptural guidelines are never sufficient for a learner. Keywords: Raga, Thaat, Music, Performing, Alapa. There are two streams of Classical music of India – the Ragas are to be performed with the basic help the North Indian i.e., Hindustani music and the of their Thaats. Hence, we may compare the Thaats South Indian i.e., Carnatic music. The vast area of with the skeleton of creature, whereas the body Indian Classical music consists upon the foremost can be compared with the Raga. The names of the criterion – the origin of the Ragas, named the 10 (ten) Thaats of North Indian Classical Music Thaats. In the Carnatic system, there are 10 system i.e., Hindustani music are as follows: Thaats. Let us look upon the origin of the 10 Thaats Sl. Thaats Ragas as well as their Thaat-ragas (i.e., the Ragas named 01. Vilabal Vilabal, Alhaiya–Vilaval, Bihag, according to their origin). The Indian Shastras Durga, Deshkar, Shankara etc. 02. Kalyan Yaman, Bhupali, Hameer, Kedar, throw light on the rules and regulations, the nature Kamod etc. of Ragas, process of performing these, and the 03. Khamaj Khamaj, Desh, Tilakkamod, Tilang, liberty and bindings of the Ragas while Jayjayanti / Jayjayvanti etc. -

Indian Traditional Grade 6
Foreword Welcome to the Musicea Arts and Culture Council Musicea Arts and Culture Council is a non-profit educational institution incorporated as a Section 8 Company of the Indian Companies Act, 2013. The primary objective of incorporation is to prepare curriculum, offer examinations, create career and jobs, recognise, award and honour achievements and promote young candidates in the field of music, dance, theatre, language, arts and sports. Musicea Arts and Culture Council is a college of national and international educators sharing the common dream of creating a world-class institution based in India to meet the requirements, demands and provide solutions to students and teachers. Musicea Arts and Culture Council have been formed to deliver an international standard grade-based music education system along with designing the national framework of music education in India. Several innovative and path-breaking measures implemented by the college council make it inclusive, holistic, and apt for 21st-century music education. The pioneering measures have already transformed the lives of thousands of educators and students and it is playing an active role in building a strong nation by assisting millions of aspiring students and teachers. Several initiatives are in place to protect, serve, and empower the teachers and students including a pension reward benefit. Musicea Arts and Culture Council have set benchmarks in creating international standard curriculum, offering examination, and performance, and by providing support, service, empowerment, inclusivity, decentralisation, growth, opportunity, career, finance, earnings, livelihood, award, reward and honour to thousands of teachers and students. Member teachers and students receive a series of direct benefits, honour and advantages from the Musicea Arts and Culture Council. -

Transcription and Analysis of Ravi Shankar's Morning Love For
Louisiana State University LSU Digital Commons LSU Doctoral Dissertations Graduate School 2013 Transcription and analysis of Ravi Shankar's Morning Love for Western flute, sitar, tabla and tanpura Bethany Padgett Louisiana State University and Agricultural and Mechanical College, [email protected] Follow this and additional works at: https://digitalcommons.lsu.edu/gradschool_dissertations Part of the Music Commons Recommended Citation Padgett, Bethany, "Transcription and analysis of Ravi Shankar's Morning Love for Western flute, sitar, tabla and tanpura" (2013). LSU Doctoral Dissertations. 511. https://digitalcommons.lsu.edu/gradschool_dissertations/511 This Dissertation is brought to you for free and open access by the Graduate School at LSU Digital Commons. It has been accepted for inclusion in LSU Doctoral Dissertations by an authorized graduate school editor of LSU Digital Commons. For more information, please [email protected]. TRANSCRIPTION AND ANALYSIS OF RAVI SHANKAR’S MORNING LOVE FOR WESTERN FLUTE, SITAR, TABLA AND TANPURA A Written Document Submitted to the Graduate Faculty of the Louisiana State University and Agricultural and Mechanical College in partial fulfillment of the requirements for the degree of Doctor of Musical Arts in The School of Music by Bethany Padgett B.M., Western Michigan University, 2007 M.M., Illinois State University, 2010 August 2013 ACKNOWLEDGEMENTS I am entirely indebted to many individuals who have encouraged my musical endeavors and research and made this project and my degree possible. I would first and foremost like to thank Dr. Katherine Kemler, professor of flute at Louisiana State University. She has been more than I could have ever hoped for in an advisor and mentor for the past three years. -

Bala Bhavan Bhajans Contents
Bala Bhavan Bhajans 9252, Miramar Road, San Diego, CA 92126 www.vcscsd.org Bala Bhavan Bhajans Contents GANESHA BHAJANS .................................................................................................. 5 1. Ganesha Sharanam, Sharanam Ganesha ............................................................ 5 2. Gauree Nandana Gajaanana ............................................................................... 5 3. Paahi Paahi Gajaanana Raga: Abheri .......................................... 5 4. Shuklambaradharam ........................................................................................... 5 5. Ganeshwara Gajamukeshwara ........................................................................... 6 6. Gajavadana ......................................................................................................... 6 7. Gajanana ............................................................................................................. 6 8. Ga-yi-yeh Ganapathi Raga: Mohana ........................................ 6 9. Gananatham Gananatham .................................................................................. 7 10. Jaya Ganesha ...................................................................................................... 7 11. Jaya Jaya Girija Bala .......................................................................................... 7 12. Jaya Ganesha ...................................................................................................... 8 13. Sri Maha Ganapathe .......................................................................................... -

Tonal Hierarchies in the Music of North India Mary A
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Crossref ri Journal of Experimental Psychology: General . „ u , C?Py 8ht 1984 by the 1984, Vol. 113, No. 3, 394-412 American Psychological Association, Inc. Tonal Hierarchies in the Music of North India Mary A. Castellano J. J. Bharucha Cornell University Dartmouth College Carol L. Krumhansl Cornell University SUMMARY Cross-culturally, most music is tonal in the sense that one particular tone, called the tonic, provides a focus around which the other tones are organized. The specific orga- nizational structures around the tonic show considerable diversity. Previous studies of the perceptual response to Western tonal music have shown that listeners familiar with this musical tradition have internalized a great deal about its underlying organization. Krumhansl and Shepard (1979) developed a probe tone method for quantifying the perceived hierarchy of stability of tones. When applied to Western tonal contexts, the measured hierarchies were found to be consistent with music-theoretic accounts. In the present study, the probe tone method was used to quantify the perceived hierarchy of tones of North Indian music. Indian music is tonal and has many features in common with Western music. One of the most significant differences is that the primary means of expressing tonality in Indian music is through melody, whereas in Western music it is through harmony (the use of chords). Indian music is based on a standard set of melodic forms (called rags), which are themselves built on a large set of scales (thats). The tones within a rag are thought to be organized in a hierarchy of importance.