Ant Colony Optimization for Predicting Flood Based on River Water Level
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Bukit Arang Tertiary Basin in Chuping, Perlis
GeoL. Soc. MaLaYJia, BuLLetin 42, December 1998; pp. 179-186 The Bukit Arang Tertiary Basin in Chuping, Perlis C.Y. LEE School of Physics Universiti Sains Malaysia 11800 USM Penang Abstract: The Bukit Arang Tertiary Basin extends from the Perlis-Thailand border at Bukit Arang Bukit Tinggi southwards to the Chuping area of eastern Perlis. It is part of the larger Sadao Basin located across the border in Thailand. Another southern extension of this main basin is found in the vicinity ofBukit Kayu Hitam, north of Changlun, just a few kilometres to the east across the interstate boundary in Kedah. Based on sparse geological evidence, the original postulated areal extent of the basin within Perlis was approximately 26 square kilometres with a minimum thickness of about 200 m. Recent gravity data indicate that it is at least twice as large in area and up to 800 m thick. The sediments consist ofloose and partially consolidated gravels, sands, silts and clays oflacustrine and fluvio-deltaic origin of Late Tertiary age. They are underlain by shales, mudstones and siltstones of the Kubang Pasu Formation of Carboniferous age. Geophysical evidence suggests that this basement is uneven, with a ridge-like feature in a north-south orientation. The basement appears to be faulted as well with WNW-ESE and approximately N-S strikes. Stratigraphically these Tertiary Beds can be correlated with the very similar strata of the Batu Arang Tertiary Basin of Late Oligocene to Late Miocene age in Selangor and with other Tertiary basins of similar lithology elsewhere in the peninsula. The Bukit Arang Tertiary Beds contain several seams of low quality coal of not much economic significance. -

Factors for Success of Sunnah Movement in Perlis State
International Journal of Academic Research in Business and Social Sciences Vol. 10, No. 4, April, 2020, E-ISSN: 2222-6990 © 2020 HRMARS Factors for Success of Sunnah Movement in Perlis State Abdul Ghafur Abdul Hadi and Basri Ibrahim To Link this Article: http://dx.doi.org/10.6007/IJARBSS/v10-i4/7137 DOI:10.6007/IJARBSS/v10-i4/7137 Received: 18 February 2020, Revised: 04 March 2020, Accepted: 26 March 2020 Published Online: 10 April 2020 In-Text Citation: (Hadi & Ibrahim, 2020) To Cite this Article: Hadi, A. G. A., & Ibrahim, B. (2020). Factors for Success of Sunnah Movement in Perlis State. International Journal of Academic Research in Business and Social Sciences, 10(4), 336–347. Copyright: © 2020 The Author(s) Published by Human Resource Management Academic Research Society (www.hrmars.com) This article is published under the Creative Commons Attribution (CC BY 4.0) license. Anyone may reproduce, distribute, translate and create derivative works of this article (for both commercial and non-commercial purposes), subject to full attribution to the original publication and authors. The full terms of this license may be seen at: http://creativecommons.org/licences/by/4.0/legalcode Vol. 10, No. 4, 2020, Pg. 336 - 347 http://hrmars.com/index.php/pages/detail/IJARBSS JOURNAL HOMEPAGE Full Terms & Conditions of access and use can be found at http://hrmars.com/index.php/pages/detail/publication-ethics 336 International Journal of Academic Research in Business and Social Sciences Vol. 10, No. 4, April, 2020, E-ISSN: 2222-6990 © 2020 HRMARS Factors for Success of Sunnah Movement in Perlis State Abdul Ghafur Abdul Hadi1 and Basri Ibrahim2 1Universiti Islam Malaysia, Cyberjaya, Malaysia, 2Universiti Islam Malaysia, Cyberjaya, Malaysia/ Faculty of Islamic Contemporary Studies, Universiti Sultan Zainal Abidin, Terengganu, Malaysia. -

(Cerbera Odollam) with Impregnation in Phosphoric Acid (H3PO4) A
Preparation and Characterization of Activated Carbon from the Sea Mango (Cerbera Odollam) with Impregnation in Phosphoric Acid (H3PO4) A. Nur Hidayah 1 M. A. Umi Fazara*,1 Z. Nor Fauziah 2 M. K. Aroua 3 1 School of Environmental Engineering, University Malaysia Perlis, Kompleks Pusat Pengajian Jejawi 3, 02600 Arau, Perlis, Malaysia. 2 Faculty of Engineering Technology, University Malaysia Perlis, Engineering Centre, 1st floor, Administration Building, Pauh Putra Main Campus, 02600 Arau, Perlis.. 3 Chemical Engineering Department, Faculty of Engineering, University of Malaya, 50603, Kuala Lumpur, Malaysia. *e-mail : [email protected] The properties of the activated carbon from Sea Mango (Cerbera Odollam) prepared from chemical and physical activation was studied. The sample was impregnated with phosphoric acid (H3PO4) at the impregnation ratio of precursor to activant as 1:2 and ° followed by thermal activation at 500 C with different flowing gas i.e. nitrogen (N2), carbon dioxide (CO2), steam and at the absent of any gases for duration of 2 hours. The sample experienced two different steps of preparation which were Method 1 and Method 2. In Method 1, the precursor will be thermally heated after the chemical activation process, and the samples were denoted as RIHM1-N, RIHM1-CO2, RIHM1-S and RIHM1-A which utilize either N2, CO2, steam and absent of any gases, respectively. Meanwhile in Method 2, the ° carbonization process with N2 flow at 200 C was done prior to chemical and thermal activation. This type of treatment method was denoted as RCIHM2-N, RCIHM2-CO2 RCIHM2-S and RCIHM2-A, which use the same flowing gases as described previously. -

Distribution and Analysis of Heavy Metals Contamination in Soil, Perlis, Malaysia
E3S Web of Conferences 34, 02040 (2018) https://doi.org/10.1051/e3sconf/20183402040 CENVIRON 2017 Distribution and Analysis of Heavy Metals Contamination in Soil, Perlis, Malaysia Ain Nihla Kamarudzaman1,*, Yee Shan Woo1, and Mohd Faizal Ab Jalil2 1School of Environmental Engineering, Universiti Malaysia Perlis, Kompleks Pusat Pengajian Jejawi 3, 02600 Arau, Perlis, Malaysia 2Perlis State Department of Environment, 2nd Floor, KWSP Building, Jalan Bukit Lagi, 01000 Kangar, Perlis, Malaysia Abstract. The concentration of six heavy metals such as Cu, Cr, Ni, Cd, Zn and Mn were studied in the soils around Perlis. The aim of the study is to assess the heavy metals contamination distribution due to industrialisation and agricultural activities. Soil samples were collected at depth of 0 – 15 cm in five stations around Perlis. The soil samples are subjected to soil extraction and the concentration of heavy metals was determined via ICP - OES. Overall concentrations of Cr, Cu, Zn, Ni, Cd and Mn in the soil samples ranged from 0.003 - 0.235 mg/L, 0.08 - 41.187 mg/L, 0.065 - 45.395 mg/L, 0.031 - 2.198 mg/L, 0.01 - 0.174 mg/L and 0.165 - 63.789 mg/L respectively. The concentration of heavy metals in the soil showed the following decreasing trend, Mn > Zn > Cu > Ni > Cr > Cd. From the result, the level of heavy metals in the soil near centralised Chuping industrial areas gives maximum value compared to other locations in Perlis. As a conclusion, increasing anthropogenic activities have influenced the environment, especially in increasing the pollution loading. -

Morphological Variability Identification of Harumanis Mango (Mangifera Indica L.) Harvested from Different Location and Tree Age
Morphological Variability Identification of Harumanis Mango (Mangifera indica L.) Harvested from Different Location and Tree Age Authors: Siti Nur Arina Yusuf, Ahmad Mukhlis Abdul Rahman, Zarina Zakaria, Vijay Kumar Subbiah, Maz Jamilah Masnan and Zakaria Wahab *Correspondence: [email protected] DOI: https://doi.org/10.21315/tlsr2020.31.2.6 Highlights • Fifty accessions of Harumanis harvested from different location and tree age were evaluated based on their morphological variation. • The result of Principal Component Analysis (PCA) provided a good approximation of the data which majorly contributed by parameters of weight, fruit dimensional characteristics, peel percentage and hue angle, h. • Preliminary screening of important morphological characteristics which contribute to the phenotypic diversity of Harumanis is successfully achieved. TLSR, 31(2), 2020 © Penerbit Universiti Sains Malaysia, 2020 Tropical Life Sciences Research, 31(2), 107–143, 2020 Morphological Variability Identification of Harumanis Mango (Mangifera indica L.) Harvested from Different Location and Tree Age 1Siti Nur Arina Yusuf, 1Ahmad Mukhlis Abdul Rahman*, 1Zarina Zakaria, 2Vijay Kumar Subbiah, 3Maz Jamilah Masnan and 4Zakaria Wahab 1Department of Chemical Engineering Technology, Faculty of Engineering Technology, Universiti Malaysia Perlis, Sungai Chuchuh, 02100 Padang Besar, Perlis, Malaysia 2Biotechnology Research Institute, Universiti Malaysia Sabah, Jalan UMS, 88400 Kota Kinabalu, Sabah, Malaysia 3Institute of Engineering Mathematics, Universiti Malaysia Perlis, Kampus Pauh Putra, 02600 Arau, Perlis, Malaysia 4Department of Mechanical Engineering Technology, Faculty of Engineering Technology, Universiti Malaysia Perlis, Sungai Chuchuh, 02100 Padang Besar, Perlis, Malaysia Publication date: 6 August 2020 To cite this article: Siti Nur Arina Yusuf, Ahmad Mukhlis Abdul Rahman, Zarina Zakaria, Vijay Kumar Subbiah, Maz Jamilah Masnan and Zakaria Wahab. -

Senarai Premis Yang Berjaya Mendapat Pensijilan (Mesti)
SENARAI PREMIS YANG BERJAYA MENDAPAT PENSIJILAN (MESTI) BIL NAMA SYARIKAT ALAMAT SYARIKAT NAMA WAKIL SYARIKAT NO TELEFON PRODUK LOT 19, JALAN INDUSTRI, KAWASAN PERINDUSTRIAN, 02000 Tel: 04-9853089 1 IGLOO ICE SDN BHD CHUA SHUI CHWN AIS KUALA PERLIS Faks: 04-9853122 2 RAROSYA ENTERPRISE 42 KAMPUNG BANGGOL SENA KANGAR RAFEDAH BINTI ISMAIL@MUSA 017-5121048 SOS CILI KOMPLEKS GERAK TANI WAWASAN E-1 (MADA) 02700 SIMPANG 3 PPK E-1 SIMPANG EMPAT EMPAT AL-HIDAYAH BT ALIAS 04-9807248 / 012-5883542 MINI POPIA PERLIS LOT 7 & 8, KAWASAN PERINDUSTRIAN MIEL JEJAWI FASA 2, 013-5846717 / 4 HPA INDUSTRIES SDN. BHD. A. ZAKARIA ABU BAKAR / NORASYIKIN KOPI RADIX, RADIX DIET JALAN JEJAWI SEMATANG, 02600 ARAU, PERLIS 019-6330727/049760741 5 SBA FOOD ENTERPRISE AB, JALAN KG SYED OMAR 01000 KANGAR SARIMAH BT ANI 017-5319490 REMPEYEK NO. 5&6, KAW PERINDUSTRIAN RINGAN, JALAN BESAR 02100 6 MEGA DUTAMAS SDN. BHD. TEOH YICK XIANG 017-4128967 COKLAT PADANG BESAR, PERLIS LOT A-5, KAWASAN MIEL, JEJAWI PHASE 1, 02600 JEJAWI, 019-4752188 7 ATLAS EDIBLE ICE SDN BHD LOW BEE BEE Ais tiub & Ais hancur PERLIS. 04-9777388 019-4907826 NO 2, 4 & 6, JALAN MURAI BATU, TAMAN KIM, 02100 PADANG 8 MEGA DUTAMAS SDN. BHD. YAP YUEN SER 04-9492788 COKLAT BESAR, PERLIS 04-9491788(F) 9 TERIAU ENTERPRISE NO 12 A KAMPUNG GUAR UJUNG BATU UTAN AJI 01000 KANGAR JAMINAH BT TERIAH 04-9766071 KACANG BERSALUT 109, LORONG SRI INAI, KAMPUNG JEJAWI DALAM 02600 ARAU 10 FAUZIAH BT ISMAIL FAUZIAH BINTI ISMAIL 017-4614385 REMPEYEK PERLIS LOT 555, JALAN BATAS LINTANG, 02700 SIMPANG EMPAT, 11 PERUSAHAAN PASTA ITIFAQ MOHD TARMIZIE ROMLI 017-5568953 MEE KUNING PERLIS 019-4549889 PERTUBUHAN PELADANG KAWASAN PAYA, KM 4 JALAN KAKI 12 PPK PAYA RAHMAH BT SALAMAT 04-9760280 CIP BUAH-BUAHAN BUKIT, 01000 KANGAR PERLIS 04-9761140 13 SYAFI BAKERY 500, JALAN MASJID KG. -

Asal Nama Negeri Perlis
Maklumat Lanjut DOSM/DOSM.PERLIS/1.2020/SIRI 84 Asal nama Negeri Perlis Nama Negeri Perlis dikatakan berasal daripada perkataan Siam prow-lowy yang bererti ‘kelapa hanyut’, daripada perkataan dialek Melayu Utara ‘perelus’ iaitu ‘kaki termasuk ke dalam atau ke celah sesuatu’, atau daripada nama Peran Leh yang dikatakan seorang peran atau pelawak mahsyur bernama Saleh. Selain itu, nama Perlis turut dikatakan bermula daripada perkataan ‘peroleh’ yang bermakna ‘mendapat, sempena nama pembesar bergelar Tok Perlis dan dikaitkan dengan ‘perlit’ yang bererti batu. Tambahan juga, Perlis juga biasa disebut sebagai Kayang. Nama Kayang ini dipendekkan bersempena nama Kota Indera Kayangan yang diasaskan oleh Sultan Dhiauddin Al-Mukarram Shah I berhampiran Kuala Sungai Perlis. Baginda adalah Sultan Kedah yang kelima belas dan memerintah dari tahun 1661 sehingga 1687. Sumber : Portal Rasmi Diraja Perlis Terletak di utara Semenanjung Malaysia dan 821km2 1 Pihak Berkuasa bersempadan dengan wilayah selatan Thailand Keluasan Tempatan (PBT) (Satun dan Songkhla), dengan keluasan hanya 821km2 (negeri terkecil di Malaysia) pentadbiran 3Parlimen Negeri Perlis diterajui oleh intitusi Diraja dan dibahagikan kepada 3 Parlimen iaitu, Kangar, 22Mukim Padang Besar dan Arau dengan pecahan 15 1Daerah Dewan Undangan Negeri dan mempunyai 22 15Dewan Pentadbiran Mukim. Selain daripada Wilayah Persekutuan Undangan Negeri Putrajaya dan Labuan, Perlis merupakan antara (DUN) negeri yang mempunyai hanya 1 Daerah Pentadbiran iaitu Perlis. 1 Evolusi Penduduk Perlis Evolusi Penduduk Perlis 2010 - 2020e (‘000) Pertumbuhan penduduk Negeri Perlis mulai260.0 1.6 254.0 254.9 255.0 253.5 1.4 tahun 2010 sehingga tahun 2020 secara 251.0 252.0 1.2 purata pada kadar 0.8 peratus setahun250.0. -

Tourism and Political Boundaries: Border Markets As Tourist Attractions
Mat Som, Ahmad Puad (First Author) School of Housing, Building & Planning, Universiti Sains Malaysia a h m a d . m at - s o m,.d st rat h . ac. u k. a h m ad p u ad_m at s o m (rJ) ya h o o. c o. u k Mohamed. Badaruddin School of Housing, Building & Planning, Universiti Sains Malaysia badaf(Dusm.my Wong, Kong-Yew Faculty of Economics and Management, Universiti Putra Malaysia kywon gl'r? eco n. upm. edu. m ), Title: Tourism and Political Boundaries: Border Markets as Tourist Attractions Abstract Tourism appears to be an increasingly important industry in many border areas because many tourist destinations exist across boundaries. In many ways, the existence and functions of political boundaries influence the nature of the tourism industry itself and the spatial development of the tourist destinations (Timothy, 1995). Eriksson (1979) further suggests that the level ofattractiveness ofborder areas depends on the natural, social and cultural environment near the border and the degree of freedom or difficulty in crossing it. By conducting in-depth interviews, this study attempts to investigate whether the growth of tourism industry on both sides of Malaysia and Thailand promotes local economy as well as cohesion between the two tourist areas and between communities with dissimilar cultures. The findings argue that the growth of tourism-related activities especially the border market has increased local participation in tourism. But, the degree of involvement tends to decrease over time due to high permeability between two different societies, which allows intrusion of foreign traders into local territories. -

Urban Land Use & Territorial Planning
PRESENTATIONS SPECIAL SESSION 6 SPECIAL SESSION 6: Urban Land Use and Territorial Planning in the Pacific Host Sponsors and Co-organizers SPECIAL SESSION 6: Urban Land Use and Territorial Planning in the Pacific Day 2 (2 July, 2019. Nadi, Republic of Fiji). Organized by: Commonwealth Association of Planners (CAP) Speakers: • Mr. Bryce Julyan, Vice President (NZ-Pacific), Commonwealth Association of Planners • Dr. Wendy Saunders – Senior Social Scientist, GNS Science, New Zealand • Ms. Lesley Hopkins - Technical Director, Beca International Consultants, New Zealand • Dr Azmizam Abdul Rashid, Urbanice, Malaysia This Special Session was hosted by the Commonwealth Association of Planners (CAP). CAP is a major global institution in planning and is playing an increasingly significant role in the worldwide promotion of planning as a fundamental part of governance for sustainable human settlement. CAP currently represents over 40 000 planners from 27 countries throughout the Commonwealth including African, Asian, Australasian and Caribbean countries. Drawing on examples and observations of planners and practitioners from Commonwealth members the session ex- amined urban land use and territorial planning in the context of rapid urbanisation and climate change, and looked at its application in the Pacific Region. The presentations illustrated urban and territorial land use planning projects and tools that are being applied and developed to plan for land use changes in the context of coastal, tropical and island nations facing climate change and urbanisation rates that stretch land and infrastructure resources. Presentations were followed by a panel discussion on the key challenges, and then group discussion on what tools and actions can we use to improve, strengthen plans and planning to achieve sustainable, positive outcomes for our land use and urban areas, whilst acknowledging and responding to climate change by building resilience in our urban settlements. -
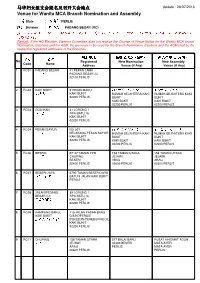
Venue for Wanita MCA Branch Nomination and Assembly 马华妇女
马华妇女组支会提名及召开大会地点 Update : 26/07/2013 Venue for Wanita MCA Branch Nomination and Assembly 州属 State : 玻璃市 PERLIS 区会 Division : 巴冬勿杀 PADANG BESAR (RC ) 注注注:如果总部选举指导委员会没有收到更换提名、大会或选举地点通知,妇女组支会的提名、大会或选举地点必须是该支 会的注册地址。 Remark : If the HQ Elections Steering Committee does not receive the Change of Venue Notice for the Wanita MCA branch Nomination, Elections and the AGM, the premises to be used for the Branch Nomination, Elections and the AGM shall be the respective registered addresses of the Branches. 注册地址 新提名地点(((如有(如有))) 新大会地点(((如有(如有))) 编号 名称 No Registered New Nomination New Assembly Code Name Address Venue (if Any) Venue (if Any) 1 RC01 PADANG BESAR 41 PEKAN LAMA 巴冬勿杀 PADANG BESAR (U) 02100 PERLIS 2 RC02 KAKI BUKIT 5 PEKAN BARU 加基武吉老人院礼堂 加基武吉老人院礼堂 加基武吉 KAKI BUKIT RUMAH SEJAHTERA KAKI RUMAH SEJAHTERA KAKI 02200 PERLIS BUKIT BUKIT KAKI BUKIT KAKI BUKIT 02200 PERLIS 02200 PERLIS 3 RC03 GUA IKAN 31 LORONG 1 拿督公 RPA BATU 16 KAKI BUKIT 02200 PERLIS 4 RC04 PEKAN SAYUR NO 307 加基武吉老人院礼堂 加基武吉老人院礼堂 长江寮 BELAKANG PEKAN SAYOR RUMAH SEJAHTERA KAKI RUMAH SEJAHTERA KAKI KAKI BUKIT BUKIT BUKIT 02200 PERLIS KAKI BUKIT KAKI BUKIT 02200 PERLIS 02200 PERLIS 5 RC06 BESERI EF 47 TAMAN PPB 158 TAMAN UTARA 158 TAMAN UTARA 柏斯里 CHUPING JEJAWI JEJAWI BESERI ARAU ARAU 02400 PERLIS 02600 PERLIS 02600 PERLIS 6 RC07 BESERI JAYA 2790 TAMAN BESERI JAYA 柏斯里再也 BATU 9 JALAN KAKI BUKIT PERLIS 7 RC08 JALAN PEDANG 39 LORONG 1 BESAR (U) RPA BATU 16 巴登勿刹路 KAKI BUKIT 02200 PERLIS 8 RC09 KAMPUNG BARU, 115 JALAN PASAR BARU KAKI BUKIT D/A KOPERASI 加基武吉甘光峇汝 PEKEBUN-PEKEBUN KECIL KAKI -

Map Guide PERLIS English.Pdf
Places of Interest MALAYSIA Perlis 1A 4 8 Situated in the heart of Southeast Asia, Malaysia Known as the Northern Gem, Perlis is the northern gateway to Malaysia. Despite its small size, Perlis is a vibrant destination with a diversity of cultures Thailand has an abundance of attractions that make it a great MAP OF MALAYSIA Sulu and traditions. This tropical paradise boasts pristine PERLIS Sea destination, be it for adventure-lovers, shopping jungles and verdant national parks that are teeming KEDAH enthusiasts or holidaymakers in search of a relaxing with numerous species of birds and wildlife. Malaysia’s KELANTAN vacation. Perlis is flanked by Kedah in the south PENANG sun-drenched islands and beaches are home to a LABUAN SABAH TERENGGANU stunning range of marine life. Its natural wealth is and Thailand (Malaysia’s northern neighbor) in the PERAK north. The state is characterised by sprawling paddy Brunei complemented by magnificent modern landmarks Darussalam plains and picturesque views of the countryside, and heritage buildings. There is something to charm PAHANG South China Sea interspersed with rustic villages, limestone outcrops SELANGOR Celebes every visitor, be it a history-lover, nature-enthusiast, KUALA LUMPUR Sea and serene lakes. Its capital city, PERLIS STATE PARK, WANG KELIAN EMAS KERAJANG DUTY-FREE COMPLEX, PADANG BESAR GALERI DIRAJA (PERLIS ROYAL GALLERY), ARAU sun-seeker or an avid shopper. Explore the length PUTRAJAYA Kangar, is a great destination NEGERI SEMBILAN SARAWAK and breadth of the country to discover the many This 5,000 hectare park is home to Malaysia’s only semi deciduous Located at the northern border of Malaysia, this is one of the most The Royal Gallery showcases an impressive collection of the with delightful orchards and MELAKA White Meranti Gerutu Seasonal Forest, as well as the 500-million state’s royal regalia, portraits, ceremonial court items, ancient attractions of Malaysia! JOHOR popular shopping spots for locals and visitors from around the verdant recreational parks. -

Kaki Bukit 加基武吉 Perlis Date of Completion: April 2021
UTAR NEW VILLAGE COMMUNITY PROJECT REPORT NAME OF NEW VILLAGE: KAKI BUKIT 加基武吉 PERLIS Project carried out by: Student Name ID Number Course Year / Semester 1. NG YEE HOI YUKI 1704032 BF Y3S3 2. NG YEE WEE 1802980 BF Y3S3 DATE OF COMPLETION: APRIL 2021 KAKI BUKIT ABSTRACT Kaki Bukit is a new village established in 2016, and is not one of the traditional new villages created during the waning days of British rule. This new village is in Perlis, the smallest and northernmost state in Malaysia. The nearest town to this new village is Padang Besar, which is 15 km away. The main attraction in Kaki Bukit is Gua Kelam, the limestone cave that was gouged out during the tin-mining days. The main economic activities in the village are small businesses and agriculture. 2 KAKI BUKIT INTRODUCTION Kaki Bukit is located in Perlis, and 26 kilometres north of the state capital, Kangar. Perlis is the northernmost state in Malaysia and being the smallest, it has no districts. Padang Besar is the nearest town to Kaki Bukit and around 15 kilometres away on the boundary between Malaysia and Thailand. Wang Kelian is also on the border and 8 kilometres away. Because of the geographical factor, this new village is composed of Chinese and Thais (the latter’s population is very low). Its population in 2021 is approximately 1,700. When the village was founded in 2016, it had a population of almost 1800. Over the years, the population decreased by a small number only. Kaki Bukit, literally “foot hill” translated from Bahasa Malaysia, is surrounded by hills.