Linked Research on the Decentralised Web
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Link ? Rot: URI Citation Durability in 10 Years of Ausweb Proceedings
Link? Rot. URI Citation Durability in 10 Years of AusWeb Proceedings. Link? Rot. URI Citation Durability in 10 Years of AusWeb Proceedings. Baden Hughes [HREF1], Research Fellow, Department of Computer Science and Software Engineering [HREF2] , The University of Melbourne [HREF3], Victoria, 3010, Australia. [email protected] Abstract The AusWeb conference has played a significant role in promoting and advancing research in web technologies in Australia over the last decade. Papers contributed to AusWeb are highly connected to the web in general, to digital libraries and to other conference sites in particular, owing to the publication of proceedings in HTML and full support for hyperlink based referencing. Authors have exploited this medium progressively more effectively, with the vast majority of references for AusWeb papers now being URIs as opposed to more traditional citation forms. The objective of this paper is to examine the reliability of URI citations in 10 years worth of AusWeb proceedings, particularly to determine the durability of such references, and to classify their causes of unavailability. Introduction The AusWeb conference has played a significant role in promoting and advancing research in web technologies in Australia over the last decade. In addition, the AusWeb forum serves as a point of reflection for practitioners engaged in web infrastructure, content and policy development; allowing the distillation of best practice in the management of web services particularly in higher educational institutions in the Australasian region. Papers contributed to AusWeb are highly connected to the web in general, to digital libraries and to other conference sites in particular, owing to the publication of proceedings in HTML and full support for hyperlink based referencing. -

Duckduckgo Search Engines Android
Duckduckgo search engines android Continue 1 5.65.0 10.8MB DuckduckGo Privacy Browser 1 5.64.0 10.8MB DuckduckGo Privacy Browser 1 5.63.1 10.78MB DuckduckGo Privacy Browser 1 5.62.0 10.36MB DuckduckGo Privacy Browser 1 5.61.2 10.36MB DuckduckGo Privacy Browser 1 5.60.0 10.35MB DuckduckGo Privacy Browser 1 5.59.1 10.35MB DuckduckGo Privacy Browser 1 5.58.1 10.33MB DuckduckGo Privacy Browser 1 5.57.1 10.31MB DuckduckGo Privacy browser © DuckduckGo. Privacy, simplified. This article is about the search engine. For children's play, see duck, duck, goose. Internet search engine DuckDuckGoScreenshot home page DuckDuckGo on 2018Type search engine siteWeb Unavailable inMultilingualHeadquarters20 Paoli PikePaoli, Pennsylvania, USA Area servedWorldwideOwnerDuck Duck Go, Inc., createdGabriel WeinbergURLduckduckgo.comAlexa rank 158 (October 2020 update) CommercialRegregedSeptember 25, 2008; 12 years ago (2008-09-25) was an Internet search engine that emphasized the privacy of search engines and avoided the filter bubble of personalized search results. DuckDuckGo differs from other search engines by not profiling its users and showing all users the same search results for this search term. The company is based in Paoli, Pennsylvania, in Greater Philadelphia and has 111 employees since October 2020. The name of the company is a reference to the children's game duck, duck, goose. The results of the DuckDuckGo Survey are a compilation of more than 400 sources, including Yahoo! Search BOSS, Wolfram Alpha, Bing, Yandex, own web scanner (DuckDuckBot) and others. It also uses data from crowdsourcing sites, including Wikipedia, to fill in the knowledge panel boxes to the right of the results. -

CHAPTER 12 Making Your Web Site Mashable
CHAPTER 12 Making Your Web Site Mashable This chapter is a guide to content producers who want to make their web sites friendly to mashups. That is, this chapter answers the question, how would you as a content producer make your digital content most effectively remixable and mashable to users and developers? Most of this book is addressed to creators of mashups who are therefore consumers of data and services. Why then should I shift in this chapter to addressing producers of data and services? Well, you have already seen aspects of APIs and web content that make it either easier or harder to remix, and you’ve seen what makes APIs easy and enjoyable to use. Showing content and data producers what would make life easier for consumers of their content provides useful guidance to service providers who might not be fully aware of what it’s like for consumers. The main audience for the book—as consumers (as opposed to producers) of services—should still find this chapter a helpful distillation of best practices for creating mashups. In some ways, this chapter is a review of Chapters 1–11 and a preview of Chapters 13–19. Chapters 1–11 prepared you for how to create mashups in general. I presented a lot of the technologies and showed how to build a reasonably sophisticated mashup with PHP and JavaScript as well as using mashup tools. Some of the discussion in this chapter will be amplified by in-depth discussions in Chapters 13–19. For example, I’ll refer to topics such as geoRSS, iCalendar, and microformats that I discuss in greater detail in those later chapters. -

EFF, Duckduckgo, and Internet Archive Amicus Brief
Case: 17-16783, 11/27/2017, ID: 10667942, DktEntry: 42, Page 1 of 39 NO. 17-16783 IN THE UNITED STATES COURT OF APPEALS FOR THE NINTH CIRCUIT HIQ LABS, INC., PLAINTIFF-APPELLEE, V. LINKEDIN CORPORATION, DEFENDANT-APPELLANT. On Appeal from the United States District Court for the Northern District of California Case No. 3:17-cv-03301-EMC The Honorable Edward M. Chen, District Court Judge BRIEF OF AMICI CURIAE ELECTRONIC FRONTIER FOUNDATION, DUCKDUCKGO, AND INTERNET ARCHIVE IN SUPPORT OF PLAINTIFF-APPELLEE Jamie Williams Corynne McSherry Cindy Cohn Nathan Cardozo ELECTRONIC FRONTIER FOUNDATION 815 Eddy Street San Francisco, CA 94109 Email: [email protected] Telephone: (415) 436-9333 Counsel for Amici Curiae Case: 17-16783, 11/27/2017, ID: 10667942, DktEntry: 42, Page 2 of 39 DISCLOSURE OF CORPORATE AFFILIATIONS AND OTHER ENTITIES WITH A DIRECT FINANCIAL INTEREST IN LITIGATION Pursuant to Rule 26.1 of the Federal Rules of Appellate Procedure, Amici Curiae Electronic Frontier Foundation, DuckDuckGo, and Internet Archive each individually state that they do not have a parent corporation and that no publicly held corporation owns 10 percent or more of their stock. i Case: 17-16783, 11/27/2017, ID: 10667942, DktEntry: 42, Page 3 of 39 TABLE OF CONTENTS CORPORATE DISCLOSURE STATEMENTS ..................................................... i TABLE OF CONTENTS ...................................................................................... ii TABLE OF AUTHORITIES ............................................................................... -

Validating RDF Data Using Shapes
83 Validating RDF data using Shapes a Jose Emilio Labra Gayo a University of Oviedo, Spain Abstract RDF forms the keystone of the Semantic Web as it enables a simple and powerful knowledge representation graph based data model that can also facilitate integration between heterogeneous sources of information. RDF based applications are usually accompanied with SPARQL stores which enable to efficiently manage and query RDF data. In spite of its well known benefits, the adoption of RDF in practice by web programmers is still lacking and SPARQL stores are usually deployed without proper documentation and quality assurance. However, the producers of RDF data usually know the implicit schema of the data they are generating, but they don't do it traditionally. In the last years, two technologies have been developed to describe and validate RDF content using the term shape: Shape Expressions (ShEx) and Shapes Constraint Language (SHACL). We will present a motivation for their appearance and compare them, as well as some applications and tools that have been developed. Keywords RDF, ShEx, SHACL, Validating, Data quality, Semantic web 1. Introduction In the tutorial we will present an overview of both RDF is a flexible knowledge and describe some challenges and future work [4] representation language based of graphs which has been successfully adopted in semantic web 2. Acknowledgements applications. In this tutorial we will describe two languages that have recently been proposed for This work has been partially funded by the RDF validation: Shape Expressions (ShEx) and Spanish Ministry of Economy, Industry and Shapes Constraint Language (SHACL).ShEx was Competitiveness, project: TIN2017-88877-R proposed as a concise and intuitive language for describing RDF data in 2014 [1]. -
TMS Xdata Documentation
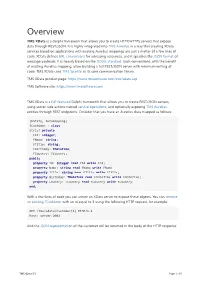
Overview TMS XData is a Delphi framework that allows you to create HTTP/HTTPS servers that expose data through REST/JSON. It is highly integrated into TMS Aurelius in a way that creating XData services based on applications with existing Aurelius mappings are just a matter of a few lines of code. XData defines URL conventions for adressing resources, and it specifies the JSON format of message payloads. It is heavily based on the OData standard. Such conventions, with the benefit of existing Aurelius mapping, allow building a full REST/JSON server with minimum writing of code. TMS XData uses TMS Sparkle as its core communication library. TMS XData product page: https://www.tmssoftware.com/site/xdata.asp TMS Software site: https://www.tmssoftware.com TMS XData is a full-featured Delphi framework that allows you to create REST/JSON servers, using server-side actions named service operations, and optionally exposing TMS Aurelius entities through REST endpoints. Consider that you have an Aurelius class mapped as follows: [Entity, Automapping] TCustomer = class strict private FId: integer; FName: string; FTitle: string; FBirthday: TDateTime; FCountry: TCountry; public property Id: Integer read FId write FId; property Name: string read FName write FName; property Title: string read FTitle write FTitle; property Birthday: TDateTime read FDateTime write FDateTime; property Country: TCountry read FCountry write FCountry; end; With a few lines of code you can create an XData server to expose these objects. You can retrieve an existing TCustomer -

V a Lida T in G R D F Da
Series ISSN: 2160-4711 LABRA GAYO • ET AL GAYO LABRA Series Editors: Ying Ding, Indiana University Paul Groth, Elsevier Labs Validating RDF Data Jose Emilio Labra Gayo, University of Oviedo Eric Prud’hommeaux, W3C/MIT and Micelio Iovka Boneva, University of Lille Dimitris Kontokostas, University of Leipzig VALIDATING RDF DATA This book describes two technologies for RDF validation: Shape Expressions (ShEx) and Shapes Constraint Language (SHACL), the rationales for their designs, a comparison of the two, and some example applications. RDF and Linked Data have broad applicability across many fields, from aircraft manufacturing to zoology. Requirements for detecting bad data differ across communities, fields, and tasks, but nearly all involve some form of data validation. This book introduces data validation and describes its practical use in day-to-day data exchange. The Semantic Web offers a bold, new take on how to organize, distribute, index, and share data. Using Web addresses (URIs) as identifiers for data elements enables the construction of distributed databases on a global scale. Like the Web, the Semantic Web is heralded as an information revolution, and also like the Web, it is encumbered by data quality issues. The quality of Semantic Web data is compromised by the lack of resources for data curation, for maintenance, and for developing globally applicable data models. At the enterprise scale, these problems have conventional solutions. Master data management provides an enterprise-wide vocabulary, while constraint languages capture and enforce data structures. Filling a need long recognized by Semantic Web users, shapes languages provide models and vocabularies for expressing such structural constraints. -

Security Applications of Formal Language Theory
Dartmouth College Dartmouth Digital Commons Computer Science Technical Reports Computer Science 11-25-2011 Security Applications of Formal Language Theory Len Sassaman Dartmouth College Meredith L. Patterson Dartmouth College Sergey Bratus Dartmouth College Michael E. Locasto Dartmouth College Anna Shubina Dartmouth College Follow this and additional works at: https://digitalcommons.dartmouth.edu/cs_tr Part of the Computer Sciences Commons Dartmouth Digital Commons Citation Sassaman, Len; Patterson, Meredith L.; Bratus, Sergey; Locasto, Michael E.; and Shubina, Anna, "Security Applications of Formal Language Theory" (2011). Computer Science Technical Report TR2011-709. https://digitalcommons.dartmouth.edu/cs_tr/335 This Technical Report is brought to you for free and open access by the Computer Science at Dartmouth Digital Commons. It has been accepted for inclusion in Computer Science Technical Reports by an authorized administrator of Dartmouth Digital Commons. For more information, please contact [email protected]. Security Applications of Formal Language Theory Dartmouth Computer Science Technical Report TR2011-709 Len Sassaman, Meredith L. Patterson, Sergey Bratus, Michael E. Locasto, Anna Shubina November 25, 2011 Abstract We present an approach to improving the security of complex, composed systems based on formal language theory, and show how this approach leads to advances in input validation, security modeling, attack surface reduction, and ultimately, software design and programming methodology. We cite examples based on real-world security flaws in common protocols representing different classes of protocol complexity. We also introduce a formalization of an exploit development technique, the parse tree differential attack, made possible by our conception of the role of formal grammars in security. These insights make possible future advances in software auditing techniques applicable to static and dynamic binary analysis, fuzzing, and general reverse-engineering and exploit development. -

Semantics Developer's Guide
MarkLogic Server Semantic Graph Developer’s Guide 2 MarkLogic 10 May, 2019 Last Revised: 10.0-8, October, 2021 Copyright © 2021 MarkLogic Corporation. All rights reserved. MarkLogic Server MarkLogic 10—May, 2019 Semantic Graph Developer’s Guide—Page 2 MarkLogic Server Table of Contents Table of Contents Semantic Graph Developer’s Guide 1.0 Introduction to Semantic Graphs in MarkLogic ..........................................11 1.1 Terminology ..........................................................................................................12 1.2 Linked Open Data .................................................................................................13 1.3 RDF Implementation in MarkLogic .....................................................................14 1.3.1 Using RDF in MarkLogic .........................................................................15 1.3.1.1 Storing RDF Triples in MarkLogic ...........................................17 1.3.1.2 Querying Triples .......................................................................18 1.3.2 RDF Data Model .......................................................................................20 1.3.3 Blank Node Identifiers ..............................................................................21 1.3.4 RDF Datatypes ..........................................................................................21 1.3.5 IRIs and Prefixes .......................................................................................22 1.3.5.1 IRIs ............................................................................................22 -

Seamless Interoperability and Data Portability in the Social Web for Facilitating an Open and Heterogeneous Online Social Network Federation
Seamless Interoperability and Data Portability in the Social Web for Facilitating an Open and Heterogeneous Online Social Network Federation vorgelegt von Dipl.-Inform. Sebastian Jürg Göndör geb. in Duisburg von der Fakultät IV – Elektrotechnik und Informatik der Technischen Universität Berlin zur Erlangung des akademischen Grades Doktor der Ingenieurwissenschaften - Dr.-Ing. - genehmigte Dissertation Promotionsausschuss: Vorsitzender: Prof. Dr. Thomas Magedanz Gutachter: Prof. Dr. Axel Küpper Gutachter: Prof. Dr. Ulrik Schroeder Gutachter: Prof. Dr. Maurizio Marchese Tag der wissenschaftlichen Aussprache: 6. Juni 2018 Berlin 2018 iii A Bill of Rights for Users of the Social Web Authored by Joseph Smarr, Marc Canter, Robert Scoble, and Michael Arrington1 September 4, 2007 Preamble: There are already many who support the ideas laid out in this Bill of Rights, but we are actively seeking to grow the roster of those publicly backing the principles and approaches it outlines. That said, this Bill of Rights is not a document “carved in stone” (or written on paper). It is a blog post, and it is intended to spur conversation and debate, which will naturally lead to tweaks of the language. So, let’s get the dialogue going and get as many of the major stakeholders on board as we can! A Bill of Rights for Users of the Social Web We publicly assert that all users of the social web are entitled to certain fundamental rights, specifically: Ownership of their own personal information, including: • their own profile data • the list of people they are connected to • the activity stream of content they create; • Control of whether and how such personal information is shared with others; and • Freedom to grant persistent access to their personal information to trusted external sites. -

Deciding SHACL Shape Containment Through Description Logics Reasoning
Deciding SHACL Shape Containment through Description Logics Reasoning Martin Leinberger1, Philipp Seifer2, Tjitze Rienstra1, Ralf Lämmel2, and Steffen Staab3;4 1 Inst. for Web Science and Technologies, University of Koblenz-Landau, Germany 2 The Software Languages Team, University of Koblenz-Landau, Germany 3 Institute for Parallel and Distributed Systems, University of Stuttgart, Germany 4 Web and Internet Science Research Group, University of Southampton, England Abstract. The Shapes Constraint Language (SHACL) allows for for- malizing constraints over RDF data graphs. A shape groups a set of constraints that may be fulfilled by nodes in the RDF graph. We investi- gate the problem of containment between SHACL shapes. One shape is contained in a second shape if every graph node meeting the constraints of the first shape also meets the constraints of the second. Todecide shape containment, we map SHACL shape graphs into description logic axioms such that shape containment can be answered by description logic reasoning. We identify several, increasingly tight syntactic restrictions of SHACL for which this approach becomes sound and complete. 1 Introduction RDF has been designed as a flexible, semi-structured data format. To ensure data quality and to allow for restricting its large flexibility in specific domains, the W3C has standardized the Shapes Constraint Language (SHACL)5. A set of SHACL shapes are represented in a shape graph. A shape graph represents constraints that only a subset of all possible RDF data graphs conform to. A SHACL processor may validate whether a given RDF data graph conforms to a given SHACL shape graph. A shape graph and a data graph that act as a running example are pre- sented in Fig. -

PDF Formats; the XHTML Version Has Active Links That You Can Follow
Semantic Web @ W3C: Activities, Recommendations and State of Adoption Athens, GA, USA, 2006-11-09 Ivan Herman, W3C Ivan Herman, W3C RDF(S), tools We have a solid specification since 2004: well defined (formal) semantics, clear RDF/XML syntax Lots of tools are available. Are listed on W3C’s wiki: RDF programming environment for 14+ languages, including C, C++, Python, Java, Javascript, Ruby, PHP,… (no Cobol or Ada yet ) 13+ Triple Stores, ie, database systems to store datasets 16+ general development tools (specialized editors, application builders, …) etc Ivan Herman, W3C RDF(S), tools (cont.) Note the large number of large corporations among the tool developers: Adobe, IBM, Software AG, Oracle, HP, Northrop Grumman, … …but the small companies and independent developers also play a major role! Some of the tools are Open Source, some are not; some are very mature, some are not : it is the usual picture of software tools, nothing special any more! Anybody can start developing RDF-based applications today Ivan Herman, W3C RDF(S), tools (cont.) There are lots of tutorials, overviews, or books around the wiki page on books lists 20+ (English) textbooks; 19+ proceedings for 2005 & 2006 alone… again, some of them good, some of them bad, just as with any other areas… Active developers’ communities Ivan Herman, W3C Large datasets are accumulating IngentaConnect bibliographic metadata storage: over 200 million triplets UniProt Protein Database: 262 million triplets RDF version of Wikipedia: more than 47 million triplets RDFS/OWL Representation