Diagnostics for Logistic Regression an Important Part of Model Testing Is Examining Your Model for Indications That Statistical Assumptions Have Been Violated
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Logistic Regression, Dependencies, Non-Linear Data and Model Reduction
COMP6237 – Logistic Regression, Dependencies, Non-linear Data and Model Reduction Markus Brede [email protected] Lecture slides available here: http://users.ecs.soton.ac.uk/mb8/stats/datamining.html (Thanks to Jason Noble and Cosma Shalizi whose lecture materials I used to prepare) COMP6237: Logistic Regression ● Outline: – Introduction – Basic ideas of logistic regression – Logistic regression using R – Some underlying maths and MLE – The multinomial case – How to deal with non-linear data ● Model reduction and AIC – How to deal with dependent data – Summary – Problems Introduction ● Previous lecture: Linear regression – tried to predict a continuous variable from variation in another continuous variable (E.g. basketball ability from height) ● Here: Logistic regression – Try to predict results of a binary (or categorical) outcome variable Y from a predictor variable X – This is a classification problem: classify X as belonging to one of two classes – Occurs quite often in science … e.g. medical trials (will a patient live or die dependent on medication?) Dependent variable Y Predictor Variables X The Oscars Example ● A fictional data set that looks at what it takes for a movie to win an Oscar ● Outcome variable: Oscar win, yes or no? ● Predictor variables: – Box office takings in millions of dollars – Budget in millions of dollars – Country of origin: US, UK, Europe, India, other – Critical reception (scores 0 … 100) – Length of film in minutes – This (fictitious) data set is available here: https://www.southampton.ac.uk/~mb1a10/stats/filmData.txt Predicting Oscar Success ● Let's start simple and look at only one of the predictor variables ● Do big box office takings make Oscar success more likely? ● Could use same techniques as below to look at budget size, film length, etc. -

Fast Computation of the Deviance Information Criterion for Latent Variable Models
Crawford School of Public Policy CAMA Centre for Applied Macroeconomic Analysis Fast Computation of the Deviance Information Criterion for Latent Variable Models CAMA Working Paper 9/2014 January 2014 Joshua C.C. Chan Research School of Economics, ANU and Centre for Applied Macroeconomic Analysis Angelia L. Grant Centre for Applied Macroeconomic Analysis Abstract The deviance information criterion (DIC) has been widely used for Bayesian model comparison. However, recent studies have cautioned against the use of the DIC for comparing latent variable models. In particular, the DIC calculated using the conditional likelihood (obtained by conditioning on the latent variables) is found to be inappropriate, whereas the DIC computed using the integrated likelihood (obtained by integrating out the latent variables) seems to perform well. In view of this, we propose fast algorithms for computing the DIC based on the integrated likelihood for a variety of high- dimensional latent variable models. Through three empirical applications we show that the DICs based on the integrated likelihoods have much smaller numerical standard errors compared to the DICs based on the conditional likelihoods. THE AUSTRALIAN NATIONAL UNIVERSITY Keywords Bayesian model comparison, state space, factor model, vector autoregression, semiparametric JEL Classification C11, C15, C32, C52 Address for correspondence: (E) [email protected] The Centre for Applied Macroeconomic Analysis in the Crawford School of Public Policy has been established to build strong links between professional macroeconomists. It provides a forum for quality macroeconomic research and discussion of policy issues between academia, government and the private sector. The Crawford School of Public Policy is the Australian National University’s public policy school, serving and influencing Australia, Asia and the Pacific through advanced policy research, graduate and executive education, and policy impact. -

A Generalized Linear Model for Binomial Response Data
A Generalized Linear Model for Binomial Response Data Copyright c 2017 Dan Nettleton (Iowa State University) Statistics 510 1 / 46 Now suppose that instead of a Bernoulli response, we have a binomial response for each unit in an experiment or an observational study. As an example, consider the trout data set discussed on page 669 of The Statistical Sleuth, 3rd edition, by Ramsey and Schafer. Five doses of toxic substance were assigned to a total of 20 fish tanks using a completely randomized design with four tanks per dose. Copyright c 2017 Dan Nettleton (Iowa State University) Statistics 510 2 / 46 For each tank, the total number of fish and the number of fish that developed liver tumors were recorded. d=read.delim("http://dnett.github.io/S510/Trout.txt") d dose tumor total 1 0.010 9 87 2 0.010 5 86 3 0.010 2 89 4 0.010 9 85 5 0.025 30 86 6 0.025 41 86 7 0.025 27 86 8 0.025 34 88 9 0.050 54 89 10 0.050 53 86 11 0.050 64 90 12 0.050 55 88 13 0.100 71 88 14 0.100 73 89 15 0.100 65 88 16 0.100 72 90 17 0.250 66 86 18 0.250 75 82 19 0.250 72 81 20 0.250 73 89 Copyright c 2017 Dan Nettleton (Iowa State University) Statistics 510 3 / 46 One way to analyze this dataset would be to convert the binomial counts and totals into Bernoulli responses. -

Chapter 4: Model Adequacy Checking
Chapter 4: Model Adequacy Checking In this chapter, we discuss some introductory aspect of model adequacy checking, including: • Residual Analysis, • Residual plots, • Detection and treatment of outliers, • The PRESS statistic • Testing for lack of fit. The major assumptions that we have made in regression analysis are: • The relationship between the response Y and the regressors is linear, at least approximately. • The error term ε has zero mean. • The error term ε has constant varianceσ 2 . • The errors are uncorrelated. • The errors are normally distributed. Assumptions 4 and 5 together imply that the errors are independent. Recall that assumption 5 is required for hypothesis testing and interval estimation. Residual Analysis: The residuals , , , have the following important properties: e1 e2 L en (a) The mean of is 0. ei (b) The estimate of population variance computed from the n residuals is: n n 2 2 ∑()ei−e ∑ei ) 2 = i=1 = i=1 = SS Re s = σ n − p n − p n − p MS Re s (c) Since the sum of is zero, they are not independent. However, if the number of ei residuals ( n ) is large relative to the number of parameters ( p ), the dependency effect can be ignored in an analysis of residuals. Standardized Residual: The quantity = ei ,i = 1,2, , n , is called d i L MS Re s standardized residual. The standardized residuals have mean zero and approximately unit variance. A large standardized residual ( > 3 ) potentially indicates an outlier. d i Recall that e = (I − H )Y = (I − H )(X β + ε )= (I − H )ε Therefore, / Var()e = var[]()I − H ε = (I − H )var(ε )(I −H ) = σ 2 ()I − H . -

Comparison of Some Chemometric Tools for Metabonomics Biomarker Identification ⁎ Réjane Rousseau A, , Bernadette Govaerts A, Michel Verleysen A,B, Bruno Boulanger C
Available online at www.sciencedirect.com Chemometrics and Intelligent Laboratory Systems 91 (2008) 54–66 www.elsevier.com/locate/chemolab Comparison of some chemometric tools for metabonomics biomarker identification ⁎ Réjane Rousseau a, , Bernadette Govaerts a, Michel Verleysen a,b, Bruno Boulanger c a Université Catholique de Louvain, Institut de Statistique, Voie du Roman Pays 20, B-1348 Louvain-la-Neuve, Belgium b Université Catholique de Louvain, Machine Learning Group - DICE, Belgium c Eli Lilly, European Early Phase Statistics, Belgium Received 29 December 2006; received in revised form 15 June 2007; accepted 22 June 2007 Available online 29 June 2007 Abstract NMR-based metabonomics discovery approaches require statistical methods to extract, from large and complex spectral databases, biomarkers or biologically significant variables that best represent defined biological conditions. This paper explores the respective effectiveness of six multivariate methods: multiple hypotheses testing, supervised extensions of principal (PCA) and independent components analysis (ICA), discriminant partial least squares, linear logistic regression and classification trees. Each method has been adapted in order to provide a biomarker score for each zone of the spectrum. These scores aim at giving to the biologist indications on which metabolites of the analyzed biofluid are potentially affected by a stressor factor of interest (e.g. toxicity of a drug, presence of a given disease or therapeutic effect of a drug). The applications of the six methods to samples of 60 and 200 spectra issued from a semi-artificial database allowed to evaluate their respective properties. In particular, their sensitivities and false discovery rates (FDR) are illustrated through receiver operating characteristics curves (ROC) and the resulting identifications are used to show their specificities and relative advantages.The paper recommends to discard two methods for biomarker identification: the PCA showing a general low efficiency and the CART which is very sensitive to noise. -

Outlier Detection and Influence Diagnostics in Network Meta- Analysis
Outlier detection and influence diagnostics in network meta- analysis Hisashi Noma, PhD* Department of Data Science, The Institute of Statistical Mathematics, Tokyo, Japan ORCID: http://orcid.org/0000-0002-2520-9949 Masahiko Gosho, PhD Department of Biostatistics, Faculty of Medicine, University of Tsukuba, Tsukuba, Japan Ryota Ishii, MS Biostatistics Unit, Clinical and Translational Research Center, Keio University Hospital, Tokyo, Japan Koji Oba, PhD Interfaculty Initiative in Information Studies, Graduate School of Interdisciplinary Information Studies, The University of Tokyo, Tokyo, Japan Toshi A. Furukawa, MD, PhD Departments of Health Promotion and Human Behavior, Kyoto University Graduate School of Medicine/School of Public Health, Kyoto, Japan *Corresponding author: Hisashi Noma Department of Data Science, The Institute of Statistical Mathematics 10-3 Midori-cho, Tachikawa, Tokyo 190-8562, Japan TEL: +81-50-5533-8440 e-mail: [email protected] Abstract Network meta-analysis has been gaining prominence as an evidence synthesis method that enables the comprehensive synthesis and simultaneous comparison of multiple treatments. In many network meta-analyses, some of the constituent studies may have markedly different characteristics from the others, and may be influential enough to change the overall results. The inclusion of these “outlying” studies might lead to biases, yielding misleading results. In this article, we propose effective methods for detecting outlying and influential studies in a frequentist framework. In particular, we propose suitable influence measures for network meta-analysis models that involve missing outcomes and adjust the degree of freedoms appropriately. We propose three influential measures by a leave-one-trial-out cross-validation scheme: (1) comparison-specific studentized residual, (2) relative change measure for covariance matrix of the comparative effectiveness parameters, (3) relative change measure for heterogeneity covariance matrix. -
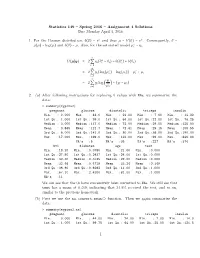
Statistics 149 – Spring 2016 – Assignment 4 Solutions Due Monday April 4, 2016 1. for the Poisson Distribution, B(Θ) =
Statistics 149 { Spring 2016 { Assignment 4 Solutions Due Monday April 4, 2016 1. For the Poisson distribution, b(θ) = eθ and thus µ = b′(θ) = eθ. Consequently, θ = ∗ g(µ) = log(µ) and b(θ) = µ. Also, for the saturated model µi = yi. n ∗ ∗ D(µSy) = 2 Q yi(θi − θi) − b(θi ) + b(θi) i=1 n ∗ ∗ = 2 Q yi(log(µi ) − log(µi)) − µi + µi i=1 n yi = 2 Q yi log − (yi − µi) i=1 µi 2. (a) After following instructions for replacing 0 values with NAs, we summarize the data: > summary(mypima2) pregnant glucose diastolic triceps insulin Min. : 0.000 Min. : 44.0 Min. : 24.00 Min. : 7.00 Min. : 14.00 1st Qu.: 1.000 1st Qu.: 99.0 1st Qu.: 64.00 1st Qu.:22.00 1st Qu.: 76.25 Median : 3.000 Median :117.0 Median : 72.00 Median :29.00 Median :125.00 Mean : 3.845 Mean :121.7 Mean : 72.41 Mean :29.15 Mean :155.55 3rd Qu.: 6.000 3rd Qu.:141.0 3rd Qu.: 80.00 3rd Qu.:36.00 3rd Qu.:190.00 Max. :17.000 Max. :199.0 Max. :122.00 Max. :99.00 Max. :846.00 NA's :5 NA's :35 NA's :227 NA's :374 bmi diabetes age test Min. :18.20 Min. :0.0780 Min. :21.00 Min. :0.000 1st Qu.:27.50 1st Qu.:0.2437 1st Qu.:24.00 1st Qu.:0.000 Median :32.30 Median :0.3725 Median :29.00 Median :0.000 Mean :32.46 Mean :0.4719 Mean :33.24 Mean :0.349 3rd Qu.:36.60 3rd Qu.:0.6262 3rd Qu.:41.00 3rd Qu.:1.000 Max. -

Bayesian Methods: Review of Generalized Linear Models
Bayesian Methods: Review of Generalized Linear Models RYAN BAKKER University of Georgia ICPSR Day 2 Bayesian Methods: GLM [1] Likelihood and Maximum Likelihood Principles Likelihood theory is an important part of Bayesian inference: it is how the data enter the model. • The basis is Fisher’s principle: what value of the unknown parameter is “most likely” to have • generated the observed data. Example: flip a coin 10 times, get 5 heads. MLE for p is 0.5. • This is easily the most common and well-understood general estimation process. • Bayesian Methods: GLM [2] Starting details: • – Y is a n k design or observation matrix, θ is a k 1 unknown coefficient vector to be esti- × × mated, we want p(θ Y) (joint sampling distribution or posterior) from p(Y θ) (joint probabil- | | ity function). – Define the likelihood function: n L(θ Y) = p(Y θ) | i| i=1 Y which is no longer on the probability metric. – Our goal is the maximum likelihood value of θ: θˆ : L(θˆ Y) L(θ Y) θ Θ | ≥ | ∀ ∈ where Θ is the class of admissable values for θ. Bayesian Methods: GLM [3] Likelihood and Maximum Likelihood Principles (cont.) Its actually easier to work with the natural log of the likelihood function: • `(θ Y) = log L(θ Y) | | We also find it useful to work with the score function, the first derivative of the log likelihood func- • tion with respect to the parameters of interest: ∂ `˙(θ Y) = `(θ Y) | ∂θ | Setting `˙(θ Y) equal to zero and solving gives the MLE: θˆ, the “most likely” value of θ from the • | parameter space Θ treating the observed data as given. -

Residuals, Part II
Biostatistics 650 Mon, November 5 2001 Residuals, Part II Key terms External Studentization Outliers Added Variable Plot — Partial Regression Plot Partial Residual Plot — Component Plus Residual Plot Key ideas/results ¢ 1. An external estimate of ¡ comes from refitting the model without observation . Amazingly, it has an easy formula: £ ¦!¦ ¦ £¥¤§¦©¨ "# 2. Externally Studentized Residuals $ ¦ ¦©¨ ¦!¦)( £¥¤§¦&% ' Ordinary residuals standardized with £*¤§¦ . Also known as R-Student. 3. Residual Taxonomy Names Definition Distribution ¦!¦ ¦+¨-,¥¦ ,0¦ 1 Ordinary ¡ 5 /. &243 ¦768¤§¦©¨ ¦ ¦!¦ 1 ¦!¦ PRESS ¡ &243 9' 5 $ Studentized ¦©¨ ¦ £ ¦!¦ ¤0> % = Internally Studentized : ;<; $ $ Externally Studentized ¦+¨ ¦ £?¤§¦ ¦!¦ ¤0>¤A@ % R-Student = 4. Outliers are unusually large observations, due to an unmodeled shift or an (unmodeled) increase in variance. 5. Outliers are not necessarily bad points; they simply are not consistent with your model. They may posses valuable information about the inadequacies of your model. 1 PRESS Residuals & Studentized Residuals Recall that the PRESS residual has a easy computation form ¦ ¦©¨ PRESS ¦!¦ ( ¦!¦ It’s easy to show that this has variance ¡ , and hence a standardized PRESS residual is 9 ¦ ¦ ¦!¦ ¦ PRESS ¨ ¨ ¨ ¦ : £ ¦!¦ £ ¦!¦ £ ¦ ¦ % % % ' When we standardize a PRESS residual we get the studentized residual! This is very informa- ,¥¦ ¦ tive. We understand the PRESS residual to be the residual at ¦ if we had omitted from the 3 model. However, after adjusting for it’s variance, we get the same thing as a studentized residual. Hence the standardized residual can be interpreted as a standardized PRESS residual. Internal vs External Studentization ,*¦ ¦ The PRESS residuals remove the impact of point ¦ on the fit at . But the studentized 3 ¢ ¦ ¨ ¦ £?% ¦!¦ £ residual : can be corrupted by point by way of ; a large outlier will inflate the residual mean square, and hence £ . -

Chapter 39 Fit Analyses
Chapter 39 Fit Analyses Chapter Table of Contents STATISTICAL MODELS ............................568 LINEAR MODELS ...............................569 GENERALIZED LINEAR MODELS .....................572 The Exponential Family of Distributions ....................572 LinkFunction..................................573 The Likelihood Function and Maximum-Likelihood Estimation . .....574 ScaleParameter.................................576 Goodness of Fit .................................576 Quasi-Likelihood Functions ..........................577 NONPARAMETRIC SMOOTHERS ......................580 SmootherDegreesofFreedom.........................581 SmootherGeneralizedCrossValidation....................582 VARIABLES ...................................583 METHOD .....................................585 OUTPUT .....................................587 TABLES ......................................590 ModelInformation...............................590 ModelEquation.................................590 X’X Matrix . .................................591 SummaryofFitforLinearModels.......................592 SummaryofFitforGeneralizedLinearModels................593 AnalysisofVarianceforLinearModels....................594 AnalysisofDevianceforGeneralizedLinearModels.............595 TypeITests...................................595 TypeIIITests..................................597 ParameterEstimatesforLinearModels....................599 ParameterEstimatesforGeneralizedLinearModels..............601 C.I.forParameters...............................602 Collinearity -

Heteroscedastic Errors
Heteroscedastic Errors ◮ Sometimes plots and/or tests show that the error variances 2 σi = Var(ǫi ) depend on i ◮ Several standard approaches to fixing the problem, depending on the nature of the dependence. ◮ Weighted Least Squares. ◮ Transformation of the response. ◮ Generalized Linear Models. Richard Lockhart STAT 350: Heteroscedastic Errors and GLIM Weighted Least Squares ◮ Suppose variances are known except for a constant factor. 2 2 ◮ That is, σi = σ /wi . ◮ Use weighted least squares. (See Chapter 10 in the text.) ◮ This usually arises realistically in the following situations: ◮ Yi is an average of ni measurements where you know ni . Then wi = ni . 2 ◮ Plots suggest that σi might be proportional to some power of 2 γ γ some covariate: σi = kxi . Then wi = xi− . Richard Lockhart STAT 350: Heteroscedastic Errors and GLIM Variances depending on (mean of) Y ◮ Two standard approaches are available: ◮ Older approach is transformation. ◮ Newer approach is use of generalized linear model; see STAT 402. Richard Lockhart STAT 350: Heteroscedastic Errors and GLIM Transformation ◮ Compute Yi∗ = g(Yi ) for some function g like logarithm or square root. ◮ Then regress Yi∗ on the covariates. ◮ This approach sometimes works for skewed response variables like income; ◮ after transformation we occasionally find the errors are more nearly normal, more homoscedastic and that the model is simpler. ◮ See page 130ff and check under transformations and Box-Cox in the index. Richard Lockhart STAT 350: Heteroscedastic Errors and GLIM Generalized Linear Models ◮ Transformation uses the model T E(g(Yi )) = xi β while generalized linear models use T g(E(Yi )) = xi β ◮ Generally latter approach offers more flexibility. -

Logistic Regression Maths and Statistics Help Centre
Logistic regression Maths and Statistics Help Centre Many statistical tests require the dependent (response) variable to be continuous so a different set of tests are needed when the dependent variable is categorical. One of the most commonly used tests for categorical variables is the Chi-squared test which looks at whether or not there is a relationship between two categorical variables but this doesn’t make an allowance for the potential influence of other explanatory variables on that relationship. For continuous outcome variables, Multiple regression can be used for a) controlling for other explanatory variables when assessing relationships between a dependent variable and several independent variables b) predicting outcomes of a dependent variable using a linear combination of explanatory (independent) variables The maths: For multiple regression a model of the following form can be used to predict the value of a response variable y using the values of a number of explanatory variables: y 0 1x1 2 x2 ..... q xq 0 Constant/ intercept , 1 q co efficients for q explanatory variables x1 xq The regression process finds the co-efficients which minimise the squared differences between the observed and expected values of y (the residuals). As the outcome of logistic regression is binary, y needs to be transformed so that the regression process can be used. The logit transformation gives the following: p ln 0 1x1 2 x2 ..... q xq 1 p p p probabilty of event occuring e.g. person dies following heart attack, odds ratio 1- p If probabilities of the event of interest happening for individuals are needed, the logistic regression equation exp x x ....