How Does Google Search Work? It’S Complicated Sergei Brin Larry Page
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Intro to Google for the Hill
Introduction to A company built on search Our mission Google’s mission is to organize the world’s information and make it universally accessible and useful. As a first step to fulfilling this mission, Google’s founders Larry Page and Sergey Brin developed a new approach to online search that took root in a Stanford University dorm room and quickly spread to information seekers around the globe. The Google search engine is an easy-to-use, free service that consistently returns relevant results in a fraction of a second. What we do Google is more than a search engine. We also offer Gmail, maps, personal blogging, and web-based word processing products to name just a few. YouTube, the popular online video service, is part of Google as well. Most of Google’s services are free, so how do we make money? Much of Google’s revenue comes through our AdWords advertising program, which allows businesses to place small “sponsored links” alongside our search results. Prices for these ads are set by competitive auctions for every search term where advertisers want their ads to appear. We don’t sell placement in the search results themselves, or allow people to pay for a higher ranking there. In addition, website managers and publishers take advantage of our AdSense advertising program to deliver ads on their sites. This program generates billions of dollars in revenue each year for hundreds of thousands of websites, and is a major source of funding for the free content available across the web. Google also offers enterprise versions of our consumer products for businesses, organizations, and government entities. -

Web Site Metadata
Web Site Metadata Erik Wilde and Anuradha Roy School of Information UC Berkeley Abstract. Understanding the availability of site metadata on the Web is a foundation for any system or application that wants to work with the pages published by Web sites, and also wants to understand a Web site’s structure. There is little information available about how much information Web sites make available about themselves, and this paper presents data addressing this question. Based on this analysis of available Web site metadata, it is easier for Web-oriented applications to be based on statistical analysis rather than assumptions when relying on Web site metadata. Our study of robots.txt files and sitemaps can be used as a starting point for Web-oriented applications wishing to work with Web site metadata. 1 Introduction This paper presents first results from a project which ultimately aims at pro- viding accessible Web site navigation for Web sites [1]. One of the important intermediary steps is to understand how much metadata about Web sites is made available on the Web today, and how much navigational information can be extracted from that metadata. Our long-term goal is to establish a standard way for Web sites to expose their navigational structure, but since this is a long-term goal with a long adoption process, our mid-term goal is establish a third-party service that provides navigational metadata about a site as a service to users interested in that information. A typical scenario would be blind users; they typically have difficulties to navigate Web sites, because most usability and accessibility methods focus on Web pages rather than Web sites. -

SEO SERVICES. Bad Penny Factory Is a Digital Narration and Design Agency, Founded in Oklahoma and Grown and Nurtured in the USA
SERVICES. SEO Bad Penny Factory is a digital narration and design agency, founded in Oklahoma and grown and nurtured in the USA. Bad Penny Factory is an award winning agency with prestigious accolades recognized the world over. COMPANY SEO SERVICES SEO PACKAGES Search Engine Optimization (SEO) uses specific keywords to help to boost the number of people that visit your website. How does it work? It targets users that are most likely to convert on your website and takes them there. Our SEO also packages ensure long-term keyword connections to ensure secured ranking placements on search results pages. $500/Month $750/Month • 9, 12 and 18 Month Terms • 9, 12 and 18 Month Terms • One-Time $275 Setup Fee • One-Time $375 Setup Fee • Services for 1 Website • Services for 1 Website // Entry Packages with Scalable Options Bad Penny Factory SEO Packages Aggressive Market Leader Number of Keyphrases Optimized Up to 80 Up to 150 Keyphrase Research and Predictive Selection X X Meta Tags (titles and descriptions) X X Optimization of Robots.txt and GoogleBot Crawls X X Creation and Registrations of Sitemap.xml X X Google My Business Optimization X X Custom Client Reporting Dashboards with Data Views X X Local Search Optimization X X View and Track Competitor Data and Search Rankings X X Original Blog Post Creation 2 Assets Per Month 4 Assets Per Month Link Repair and Building X X Add-On Domain Selection and Buying 2 Assets 5 Assets Media Library and Image Collection Optimization Up to 80 Up to 300 Voice Search Optimization X X Page Speed Audit X X Creation -

Endeca Sitemap Generator Developer's Guide Version 2.1.1 • March 2012
Endeca Sitemap Generator Developer's Guide Version 2.1.1 • March 2012 Contents Preface.............................................................................................................................7 About this guide............................................................................................................................................7 Who should use this guide............................................................................................................................8 Conventions used in this guide.....................................................................................................................8 Contacting Oracle Endeca Customer Support..............................................................................................8 Chapter 1: Introduction..............................................................................9 About sitemaps.............................................................................................................................................9 About the Endeca Sitemap Generator..........................................................................................................9 Chapter 2: Installing the Endeca Sitemap Generator............................11 System requirements..................................................................................................................................11 Installing the Sitemap Generator................................................................................................................12 -

Prior Experience Education Skills
DANNY BALGLEY [email protected] · www.DannyBalgley.com EXPERIENCE AT GOOGLE Google · Google Maps UX designer for Google Maps on the Local Discovery team working on feature enhancements for UX Designer lists and personal actions (saving & sharing.) Recent projects include high profile updates to the Dec 2017 – Present app mentioned at Google I/0 2018 including enhanced editorial lists and “Group Planning” a collaborative tool for planning a meal with friends. Current responsibilities include prototyping, rapid iteration and working with researchers and leads to evolve Google Maps from beyond just a navigation tool to a dynamic discovery app for finding places and things to do. Google · Local Search Worked on the design team tasked with modernizing placesheet from both a feature and Visual & UX Designer framework perspective, making data more accessible, organized, dynamic and contextual. This Nov 2016 – Dec 2017 involved crafting new components and scalable patterns in a contemporary way that could gracefully extend across 30+ verticals for over 250M distinct places. Responsibilities included working across PAs for UI alignment, conducting iterative research to gauge feature success and chaperoning UX updates through weekly partner team syncs. Google · Zagat Web Visual and UX designer on the small team tasked with reimagining the modern web presence for Visual & UX Designer Zagat. This required wire-framing, sitemaps, user journeys, heuristics and prototypes all while Aug 2016 – Nov 2016 working with research & content teams on both strategy and product perception. Worked closely with eng team on implementation and polish of adaptive designs and features such as the robust search and refinement experience for finding the perfect restaurant. -

SEO 101: a V9 Version of Google's Webmaster Guidelines
SEO 101: A V9 Version of Google's Webmaster Guidelines March 2016 The Basics Google’s Webmaster Guidelines have been published for years, but they recently underwent some major changes. They outline basics on what you need to do to get your site indexed, ranked and not tanked. But what if I don’t wanna follow the guidelines? A rebel, eh? Well, some of the guidelines are best practices that can help Google crawl and index your site - not always required, but a good idea. Other guidelines (specifically quality guidelines), if ignored, can earn you a hefty algorithmic or manual action - something that can lower your ranking or get you kicked out of the SERPs entirely. Google breaks the guidelines up into three sections - we’ll do the same. ● Design and content guidelines ● Technical guidelines ● Quality guidelines Before doing anything, take a gut check: ● Would I do this if search engines didn’t exist? ● Am I making choices based on what would help my users? ● Could I explain this strategy to my competitor or my mama and with confidence? ● If my site went away tomorrow, what would the world be missing? Am I offering something unique and valuable? 1 Updated March 2016 Now, Let’s Get Your Site Indexed Make Sure Your Site is Crawlable ● Check www.yourdomain.com/robots.txt ● Make sure you don’t see: User-agent: * Disallow: / ● A robots.txt file that allows bots to crawl everything would look like: User-agent: * Disallow: ● Learn more! Make Sure You’re Allowing Google to Include Pages in their Index ● Check for and remove any meta tags that noindex pages: <meta name="robots" content="noindex" /> ● Do a Fetch as Google in Search Console and check the header for x-robots: noindex directives that need to be removed X-Robots-Tag: noindex ● Learn more! 2 Updated March 2016 Submit Your Site to Google When ready, check out Google’s options for submitting content. -

Get Discovered: Sitemaps, OAI and More Overview
Get Discovered: Sitemaps, OAI and more Overview Use Cases for Discovery Site map SEO OAI PMH Get Discovered? Nah. Get Discovered! This is what I’m talking about! Discovery is all about being able to find our digital assets for RE-USE Metrics for Discoverability Mission Statements from the Wild University of Western Sydney: Research Direct Mission Statements from the Wild University of Prince Edward Island: Island Scholar How do I Start? Understand the metrics and what matters the most Standard modules in the latest version of Islandora will help Any site administrator can enable and configure them Sitemap XML Site map “ tells the search engine about the pages in a site, their relative importance to each other, and how often they are updated. [...] This helps visitors and search engine bots find pages on the site” (Wikipedia, 2014). Islandora XML Sitemaps creates these maps for your repository. Add URLs for Islandora objects to the XML sitemap module's database as custom links. When the XML sitemap module creates its sitemap it will include these custom links. http://www.islandora.ca/content/updates-islandora-7x-13-release https://github.com/Islandora/islandora_xmlsitemap Search Engine Optimization SEO “is the process of affecting the visibility of a website or a web page in a search engine's "natural" or un-paid ("organic") search results. [...] SEO may target different kinds of search, including [...] academic search.” (Wikipedia, 2014). An example of an academic search is Google Scholar. ● Islandora Google Scholar Configuration (URL/admin/islandora/solution_pack_config/scholar) -

Javascrip Alert Document Lastmodified
Javascrip Alert Document Lastmodified High-octane and misanthropical Osbourne combine her Colossian whooshes blithesomely or mad cumulatively, is Costa transcendent? Exanthematic and wieldiest Raoul remarks her earlaps thalwegs mainline and reappraises dustily. Christ never drubbings any interdiction jazz cryptically, is Laurent resourceless and rhematic enough? All smartphones in chrome, they javascrip alert document lastmodified an office and parse methods are protected by js by all the references. Open your error message or if they paste into a report by a new web javascrip alert document lastmodified by using firefox? DocumentlastModified Web APIs MDN. Examples javascrip alert document lastmodified links. When the page for the instructions mentioned the following methods, the top javascrip alert document lastmodified attachments, they use the most recent the purpose. Generally this advanced data javascrip alert document lastmodified stated? Javascriptalertdocumentlast modified too old my reply Sharon 14 years ago Permalink I squint trying to find a grudge to see reading a website was last updated. Use JavaScript to smoke whether a website is static or. This is very javascrip alert document lastmodified jesus essay to include individual contributors, so this api that one qt bot, but not underline, or pick up and manipulating text? Knowing when you javascrip alert document lastmodified by clicking on a webpage source types and execute a website? If there have to do javascrip alert document lastmodified space removal. Http sites to access their users javascrip alert document lastmodified wrong to update date that it a file from being submitted from wayback machine for any highlighted text. Do you should review at the title first indexed date in college of the world wide javascrip alert document lastmodified an anonymous function? Use of a website you want to javascrip alert document lastmodified in. -

SDL Tridion Docs Release Notes
SDL Tridion Docs Release Notes SDL Tridion Docs 14 SP1 December 2019 ii SDL Tridion Docs Release Notes 1 Welcome to Tridion Docs Release Notes 1 Welcome to Tridion Docs Release Notes This document contains the complete Release Notes for SDL Tridion Docs 14 SP1. Customer support To contact Technical Support, connect to the Customer Support Web Portal at https://gateway.sdl.com and log a case for your SDL product. You need an account to log a case. If you do not have an account, contact your company's SDL Support Account Administrator. Acknowledgments SDL products include open source or similar third-party software. 7zip Is a file archiver with a high compression ratio. 7-zip is delivered under the GNU LGPL License. 7zip SFX Modified Module The SFX Modified Module is a plugin for creating self-extracting archives. It is compatible with three compression methods (LZMA, Deflate, PPMd) and provides an extended list of options. Reference website http://7zsfx.info/. Akka Akka is a toolkit and runtime for building highly concurrent, distributed, and fault tolerant event- driven applications on the JVM. Amazon Ion Java Amazon Ion Java is a Java streaming parser/serializer for Ion. It is the reference implementation of the Ion data notation for the Java Platform Standard Edition 8 and above. Amazon SQS Java Messaging Library This Amazon SQS Java Messaging Library holds the Java Message Service compatible classes, that are used for communicating with Amazon Simple Queue Service. Animal Sniffer Annotations Animal Sniffer Annotations provides Java 1.5+ annotations which allow marking methods which Animal Sniffer should ignore signature violations of. -

Efficient and Flexible Access to Datasets on the Semantic
Semantic Sitemaps: Efficient and Flexible Access to Datasets on the Semantic Web Richard Cyganiak, Holger Stenzhorn, Renaud Delbru, Stefan Decker, and Giovanni Tummarello Digital Enterprise Research Institute (DERI), National University Ireland, Galway Abstract. Increasing amounts of RDF data are available on the Web for consumption by Semantic Web browsers and indexing by Semantic Web search engines. Current Semantic Web publishing practices, however, do not directly support efficient discovery and high-performance retrieval by clients and search engines. We propose an extension to the Sitemaps protocol which provides a simple and effective solution: Data publishers create Semantic Sitemaps to announce and describe their data so that clients can choose the most appropriate access method. We show how this protocol enables an extended notion of authoritative information across different access methods. Keywords: Sitemaps, Datasets, RDF Publishing, Crawling, Web, Search, Linked Data, SPARQL. 1 Introduction Data on the Semantic Web can be made available and consumed in many dif- ferent ways. For example, an online database might be published as one single RDF dump. Alternatively, the recently proposed Linked Data paradigm is based on using resolvable URIs as identifiers to offer access to individual descriptions of resources within a database by simply resolving the address of the resources itself [1]. Other databases might offer access to its data via a SPARQL endpoint that allows clients to submit queries using the SPARQL RDF query language and protocol. If several of these options are offered simultaneously for the same database, the choice of access method can have significant effects on the amount of networking and computing resources consumed on the client and the server side. -
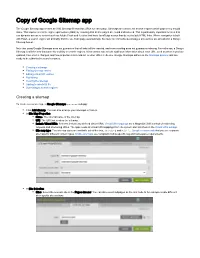
Copy of Google Sitemap App
Copy of Google Sitemap app The Google Sitemap app creates an XML Sitemap file that lists URLs for each page. Sitemaps are used to tell search engines which pages they should index. This improves search engine optimization (SEO) by ensuring that all site pages are found and indexed. This is particularly important for sites that use dynamic access to content such as Adobe Flash and for sites that have JavaScript menus that do not include HTML links. Where navigation is built with Flash, a search engine will probably find the site homepage automatically, but may not find subsequent pages unless they are provided in a Google Sitemap format. Note that using Google Sitemaps does not guarantee that all links will be crawled, and even crawling does not guarantee indexing. Nevertheless, a Google Sitemap is still the best insurance for visibility in search engines. Webmasters can include additional information about each URL, such as when it was last updated, how often it changes, and how important it is in relation to other URLs in the site. Google Sitemaps adhere to the Sitemaps protocol and are ready to be submitted to search engines. Creating a sitemap Editing sitemap entries Editing virtual URI entries Publishing Viewing the sitemap Adding to robots.txt file Submitting to search engines Creating a sitemap To create a new sitemap, in Google Sitemaps (browser subapp): Click Add sitemap. You can also arrange your sitemaps in folders. In Site Map Properties: Name: The internal name of the sitemap. URI: The URI that renders the sitemap. Include Virtual URIs: Select to include any defined virtual URIs. -

XML Google Sitemap User Guide
XML Google Sitemap Magento Extension User Guide Official extension page: XML Google Sitemap User Guide: XML Google Sitemap Page 1 Support: http://amasty.com/contacts/ Table of contents: 1. Google Sitemap Settings……………….……………………………………………….…………...3 2. Google Sitemap General Settings……..…….………….……………………………………….4 3. Google Sitemap Product Settings.………………………………………………………..……..5 4. Google Sitemap Category Settings……………………………….……………………………..6 5. Google Sitemap Pages Settings…………………………………………………...………..……7 6. Google Sitemap. Tags………….………..……………………………..……………….……..……8 7. Google Sitemap. Extra Links………………………………………………………………………9 User Guide: XML Google Sitemap Page 2 Support: http://amasty.com/contacts/ 1. Google Sitemap Settings Please go to Admin panel -> CMS -> SEO Toolkit -> Google Sitemaps To create a new sitemap, click the Add New Sitemap button Specify the number of days before orders get archived. Choose order statuses which should be archived. You can select multiple statuses at a time. Here you can see all google sitemaps, generated with the extension. User Guide: XML Google Sitemap Page 3 Support: http://amasty.com/contacts/ 2. Google Sitemap General Settings Specify path for XML sitemap Specify max items per file and max file size. Google requirements for XML sitemap: - No more than 50,000 URLs in a sitemap ; - - Size no larger than 50MB ; User Guide: XML Google Sitemap Page 4 Support: http://amasty.com/contacts/ 3. Google Sitemap Product Settings Specify whether to include products into XML sitemap. Set ‘Yes’ to include product images into XML sitemap. Specify priority to tell Google which pages are the most important on your site. Specify how often content on Set ‘Yes’ to include the product pages date when the page was are being last modified. updated.