An Introduction to Fourier Analysis Fourier Series, Partial Differential Equations and Fourier Transforms
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

B1. Fourier Analysis of Discrete Time Signals
B1. Fourier Analysis of Discrete Time Signals Objectives • Introduce discrete time periodic signals • Define the Discrete Fourier Series (DFS) expansion of periodic signals • Define the Discrete Fourier Transform (DFT) of signals with finite length • Determine the Discrete Fourier Transform of a complex exponential 1. Introduction In the previous chapter we defined the concept of a signal both in continuous time (analog) and discrete time (digital). Although the time domain is the most natural, since everything (including our own lives) evolves in time, it is not the only possible representation. In this chapter we introduce the concept of expanding a generic signal in terms of elementary signals, such as complex exponentials and sinusoids. This leads to the frequency domain representation of a signal in terms of its Fourier Transform and the concept of frequency spectrum so that we characterize a signal in terms of its frequency components. First we begin with the introduction of periodic signals, which keep repeating in time. For these signals it is fairly easy to determine an expansion in terms of sinusoids and complex exponentials, since these are just particular cases of periodic signals. This is extended to signals of a finite duration which becomes the Discrete Fourier Transform (DFT), one of the most widely used algorithms in Signal Processing. The concepts introduced in this chapter are at the basis of spectral estimation of signals addressed in the next two chapters. 2. Periodic Signals VIDEO: Periodic Signals (19:45) http://faculty.nps.edu/rcristi/eo3404/b-discrete-fourier-transform/videos/chapter1-seg1_media/chapter1-seg1- 0.wmv http://faculty.nps.edu/rcristi/eo3404/b-discrete-fourier-transform/videos/b1_02_periodicSignals.mp4 In this section we define a class of discrete time signals called Periodic Signals. -

FOURIER TRANSFORM Very Broadly Speaking, the Fourier Transform Is a Systematic Way to Decompose “Generic” Functions Into
FOURIER TRANSFORM TERENCE TAO Very broadly speaking, the Fourier transform is a systematic way to decompose “generic” functions into a superposition of “symmetric” functions. These symmetric functions are usually quite explicit (such as a trigonometric function sin(nx) or cos(nx)), and are often associated with physical concepts such as frequency or energy. What “symmetric” means here will be left vague, but it will usually be associated with some sort of group G, which is usually (though not always) abelian. Indeed, the Fourier transform is a fundamental tool in the study of groups (and more precisely in the representation theory of groups, which roughly speaking describes how a group can define a notion of symmetry). The Fourier transform is also related to topics in linear algebra, such as the representation of a vector as linear combinations of an orthonormal basis, or as linear combinations of eigenvectors of a matrix (or a linear operator). To give a very simple prototype of the Fourier transform, consider a real-valued function f : R → R. Recall that such a function f(x) is even if f(−x) = f(x) for all x ∈ R, and is odd if f(−x) = −f(x) for all x ∈ R. A typical function f, such as f(x) = x3 + 3x2 + 3x + 1, will be neither even nor odd. However, one can always write f as the superposition f = fe + fo of an even function fe and an odd function fo by the formulae f(x) + f(−x) f(x) − f(−x) f (x) := ; f (x) := . e 2 o 2 3 2 2 3 For instance, if f(x) = x + 3x + 3x + 1, then fe(x) = 3x + 1 and fo(x) = x + 3x. -

Fourier Transforms & the Convolution Theorem
Convolution, Correlation, & Fourier Transforms James R. Graham 11/25/2009 Introduction • A large class of signal processing techniques fall under the category of Fourier transform methods – These methods fall into two broad categories • Efficient method for accomplishing common data manipulations • Problems related to the Fourier transform or the power spectrum Time & Frequency Domains • A physical process can be described in two ways – In the time domain, by h as a function of time t, that is h(t), -∞ < t < ∞ – In the frequency domain, by H that gives its amplitude and phase as a function of frequency f, that is H(f), with -∞ < f < ∞ • In general h and H are complex numbers • It is useful to think of h(t) and H(f) as two different representations of the same function – One goes back and forth between these two representations by Fourier transforms Fourier Transforms ∞ H( f )= ∫ h(t)e−2πift dt −∞ ∞ h(t)= ∫ H ( f )e2πift df −∞ • If t is measured in seconds, then f is in cycles per second or Hz • Other units – E.g, if h=h(x) and x is in meters, then H is a function of spatial frequency measured in cycles per meter Fourier Transforms • The Fourier transform is a linear operator – The transform of the sum of two functions is the sum of the transforms h12 = h1 + h2 ∞ H ( f ) h e−2πift dt 12 = ∫ 12 −∞ ∞ ∞ ∞ h h e−2πift dt h e−2πift dt h e−2πift dt = ∫ ( 1 + 2 ) = ∫ 1 + ∫ 2 −∞ −∞ −∞ = H1 + H 2 Fourier Transforms • h(t) may have some special properties – Real, imaginary – Even: h(t) = h(-t) – Odd: h(t) = -h(-t) • In the frequency domain these -

Fourier Analysis
Chapter 1 Fourier analysis In this chapter we review some basic results from signal analysis and processing. We shall not go into detail and assume the reader has some basic background in signal analysis and processing. As basis for signal analysis, we use the Fourier transform. We start with the continuous Fourier transformation. But in applications on the computer we deal with a discrete Fourier transformation, which introduces the special effect known as aliasing. We use the Fourier transformation for processes such as convolution, correlation and filtering. Some special attention is given to deconvolution, the inverse process of convolution, since it is needed in later chapters of these lecture notes. 1.1 Continuous Fourier Transform. The Fourier transformation is a special case of an integral transformation: the transforma- tion decomposes the signal in weigthed basis functions. In our case these basis functions are the cosine and sine (remember exp(iφ) = cos(φ) + i sin(φ)). The result will be the weight functions of each basis function. When we have a function which is a function of the independent variable t, then we can transform this independent variable to the independent variable frequency f via: +1 A(f) = a(t) exp( 2πift)dt (1.1) −∞ − Z In order to go back to the independent variable t, we define the inverse transform as: +1 a(t) = A(f) exp(2πift)df (1.2) Z−∞ Notice that for the function in the time domain, we use lower-case letters, while for the frequency-domain expression the corresponding uppercase letters are used. A(f) is called the spectrum of a(t). -

STATISTICAL FOURIER ANALYSIS: CLARIFICATIONS and INTERPRETATIONS by DSG Pollock
STATISTICAL FOURIER ANALYSIS: CLARIFICATIONS AND INTERPRETATIONS by D.S.G. Pollock (University of Leicester) Email: stephen [email protected] This paper expounds some of the results of Fourier theory that are es- sential to the statistical analysis of time series. It employs the algebra of circulant matrices to expose the structure of the discrete Fourier transform and to elucidate the filtering operations that may be applied to finite data sequences. An ideal filter with a gain of unity throughout the pass band and a gain of zero throughout the stop band is commonly regarded as incapable of being realised in finite samples. It is shown here that, to the contrary, such a filter can be realised both in the time domain and in the frequency domain. The algebra of circulant matrices is also helpful in revealing the nature of statistical processes that are band limited in the frequency domain. In order to apply the conventional techniques of autoregressive moving-average modelling, the data generated by such processes must be subjected to anti- aliasing filtering and sub sampling. These techniques are also described. It is argued that band-limited processes are more prevalent in statis- tical and econometric time series than is commonly recognised. 1 D.S.G. POLLOCK: Statistical Fourier Analysis 1. Introduction Statistical Fourier analysis is an important part of modern time-series analysis, yet it frequently poses an impediment that prevents a full understanding of temporal stochastic processes and of the manipulations to which their data are amenable. This paper provides a survey of the theory that is not overburdened by inessential complications, and it addresses some enduring misapprehensions. -

Fourier Transform, Convolution Theorem, and Linear Dynamical Systems April 28, 2016
Mathematical Tools for Neuroscience (NEU 314) Princeton University, Spring 2016 Jonathan Pillow Lecture 23: Fourier Transform, Convolution Theorem, and Linear Dynamical Systems April 28, 2016. Discrete Fourier Transform (DFT) We will focus on the discrete Fourier transform, which applies to discretely sampled signals (i.e., vectors). Linear algebra provides a simple way to think about the Fourier transform: it is simply a change of basis, specifically a mapping from the time domain to a representation in terms of a weighted combination of sinusoids of different frequencies. The discrete Fourier transform is therefore equiv- alent to multiplying by an orthogonal (or \unitary", which is the same concept when the entries are complex-valued) matrix1. For a vector of length N, the matrix that performs the DFT (i.e., that maps it to a basis of sinusoids) is an N × N matrix. The k'th row of this matrix is given by exp(−2πikt), for k 2 [0; :::; N − 1] (where we assume indexing starts at 0 instead of 1), and t is a row vector t=0:N-1;. Recall that exp(iθ) = cos(θ) + i sin(θ), so this gives us a compact way to represent the signal with a linear superposition of sines and cosines. The first row of the DFT matrix is all ones (since exp(0) = 1), and so the first element of the DFT corresponds to the sum of the elements of the signal. It is often known as the \DC component". The next row is a complex sinusoid that completes one cycle over the length of the signal, and each subsequent row has a frequency that is an integer multiple of this \fundamental" frequency. -

A Hilbert Space Theory of Generalized Graph Signal Processing
1 A Hilbert Space Theory of Generalized Graph Signal Processing Feng Ji and Wee Peng Tay, Senior Member, IEEE Abstract Graph signal processing (GSP) has become an important tool in many areas such as image pro- cessing, networking learning and analysis of social network data. In this paper, we propose a broader framework that not only encompasses traditional GSP as a special case, but also includes a hybrid framework of graph and classical signal processing over a continuous domain. Our framework relies extensively on concepts and tools from functional analysis to generalize traditional GSP to graph signals in a separable Hilbert space with infinite dimensions. We develop a concept analogous to Fourier transform for generalized GSP and the theory of filtering and sampling such signals. Index Terms Graph signal proceesing, Hilbert space, generalized graph signals, F-transform, filtering, sampling I. INTRODUCTION Since its emergence, the theory and applications of graph signal processing (GSP) have rapidly developed (see for example, [1]–[10]). Traditional GSP theory is essentially based on a change of orthonormal basis in a finite dimensional vector space. Suppose G = (V; E) is a weighted, arXiv:1904.11655v2 [eess.SP] 16 Sep 2019 undirected graph with V the vertex set of size n and E the set of edges. Recall that a graph signal f assigns a complex number to each vertex, and hence f can be regarded as an element of n C , where C is the set of complex numbers. The heart of the theory is a shift operator AG that is usually defined using a property of the graph. -
20. the Fourier Transform in Optics, II Parseval’S Theorem
20. The Fourier Transform in optics, II Parseval’s Theorem The Shift theorem Convolutions and the Convolution Theorem Autocorrelations and the Autocorrelation Theorem The Shah Function in optics The Fourier Transform of a train of pulses The spectrum of a light wave The spectrum of a light wave is defined as: 2 SFEt {()} where F{E(t)} denotes E(), the Fourier transform of E(t). The Fourier transform of E(t) contains the same information as the original function E(t). The Fourier transform is just a different way of representing a signal (in the frequency domain rather than in the time domain). But the spectrum contains less information, because we take the magnitude of E(), therefore losing the phase information. Parseval’s Theorem Parseval’s Theorem* says that the 221 energy in a function is the same, whether f ()tdt F ( ) d 2 you integrate over time or frequency: Proof: f ()tdt2 f ()t f *()tdt 11 F( exp(j td ) F *( exp(j td ) dt 22 11 FF() *(') exp([j '])tdtd ' d 22 11 FF( ) * ( ') [2 ')] dd ' 22 112 FF() *() d F () d * also known as 22Rayleigh’s Identity. The Fourier Transform of a sum of two f(t) F() functions t g(t) G() Faft() bgt () aF ft() bFgt () t The FT of a sum is the F() + sum of the FT’s. f(t)+g(t) G() Also, constants factor out. t This property reflects the fact that the Fourier transform is a linear operation. Shift Theorem The Fourier transform of a shifted function, f ():ta Ffta ( ) exp( jaF ) ( ) Proof : This theorem is F ft a ft( a )exp( jtdt ) important in optics, because we often encounter functions Change variables : uta that are shifting (continuously) along fu( )exp( j [ u a ]) du the time axis – they are called waves! exp(ja ) fu ( )exp( judu ) exp(jaF ) ( ) QED An example of the Shift Theorem in optics Suppose that we’re measuring the spectrum of a light wave, E(t), but a small fraction of the irradiance of this light, say , takes a different path that also leads to the spectrometer. -
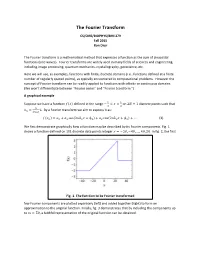
The Fourier Transform
The Fourier Transform CS/CME/BIOPHYS/BMI 279 Fall 2015 Ron Dror The Fourier transform is a mathematical method that expresses a function as the sum of sinusoidal functions (sine waves). Fourier transforms are widely used in many fields of sciences and engineering, including image processing, quantum mechanics, crystallography, geoscience, etc. Here we will use, as examples, functions with finite, discrete domains (i.e., functions defined at a finite number of regularly spaced points), as typically encountered in computational problems. However the concept of Fourier transform can be readily applied to functions with infinite or continuous domains. (We won’t differentiate between “Fourier series” and “Fourier transform.”) A graphical example ! ! Suppose we have a function � � defined in the range − < � < on 2� + 1 discrete points such that ! ! ! � = �. By a Fourier transform we aim to express it as: ! !!!! � �! = �! + �! cos 2��!� + �! + �! cos 2��!� + �! + ⋯ (1) We first demonstrate graphically how a function may be described by its Fourier components. Fig. 1 shows a function defined on 101 discrete data points integer � = −50, −49, … , 49, 50. In fig. 2, the first Fig. 1. The function to be Fourier transformed few Fourier components are plotted separately (left) and added together (right) to form an approximation to the original function. Finally, fig. 3 demonstrates that by including the components up to � = 50, a faithful representation of the original function can be obtained. � ��, �� & �� Single components Summing over components up to m 0 �! = 0.6 �! = 0 �! = 0 1 �! = 1.9 �! = 0.01 �! = 2.2 2 �! = 0.27 �! = 0.02 �! = −1.3 3 �! = 0.39 �! = 0.03 �! = 0.4 Fig.2. -

Fourier Series, Haar Wavelets and Fast Fourier Transform
FOURIER SERIES, HAAR WAVELETS AND FAST FOURIER TRANSFORM VESA KAARNIOJA, JESSE RAILO AND SAMULI SILTANEN Abstract. This handout is for the course Applications of matrix computations at the University of Helsinki in Spring 2018. We recall basic algebra of complex numbers, define the Fourier series, the Haar wavelets and discrete Fourier transform, and describe the famous Fast Fourier Transform (FFT) algorithm. The discrete convolution is also considered. Contents 1. Revision on complex numbers 1 2. Fourier series 3 2.1. Fourier series: complex formulation 5 3. *Haar wavelets 5 3.1. *Theoretical approach as an orthonormal basis of L2([0, 1]) 6 4. Discrete Fourier transform 7 4.1. *Discrete convolutions 10 5. Fast Fourier transform (FFT) 10 1. Revision on complex numbers A complex number is a pair x + iy := (x, y) ∈ C of x, y ∈ R. Let z = x + iy, w = a + ib ∈ C be two complex numbers. We define the sum as z + w := (x + a) + i(y + b) • Version 1. Suggestions and corrections could be send to jesse.railo@helsinki.fi. • Things labaled with * symbol are supposed to be extra material and might be more advanced. • There are some exercises in the text that are supposed to be relatively easy, even trivial, and support understanding of the main concepts. These are not part of the official course work. 1 2 VESA KAARNIOJA, JESSE RAILO AND SAMULI SILTANEN and the product as zw := (xa − yb) + i(ya + xb). These satisfy all the same algebraic rules as the real numbers. Recall and verify that i2 = −1. However, C is not an ordered field, i.e. -

Extended Fourier Analysis of Signals
Dr.sc.comp. Vilnis Liepiņš Email: [email protected] Extended Fourier analysis of signals Abstract. This summary of the doctoral thesis [8] is created to emphasize the close connection of the proposed spectral analysis method with the Discrete Fourier Transform (DFT), the most extensively studied and frequently used approach in the history of signal processing. It is shown that in a typical application case, where uniform data readings are transformed to the same number of uniformly spaced frequencies, the results of the classical DFT and proposed approach coincide. The difference in performance appears when the length of the DFT is selected greater than the length of the data. The DFT solves the unknown data problem by padding readings with zeros up to the length of the DFT, while the proposed Extended DFT (EDFT) deals with this situation in a different way, it uses the Fourier integral transform as a target and optimizes the transform basis in the extended frequency set without putting such restrictions on the time domain. Consequently, the Inverse DFT (IDFT) applied to the result of EDFT returns not only known readings, but also the extrapolated data, where classical DFT is able to give back just zeros, and higher resolution are achieved at frequencies where the data has been extrapolated successfully. It has been demonstrated that EDFT able to process data with missing readings or gaps inside or even nonuniformly distributed data. Thus, EDFT significantly extends the usability of the DFT based methods, where previously these approaches have been considered as not applicable [10-45]. The EDFT founds the solution in an iterative way and requires repeated calculations to get the adaptive basis, and this makes it numerical complexity much higher compared to DFT. -

Fourier Analysis of Discrete-Time Signals
Fourier analysis of discrete-time signals (Lathi Chapt. 10 and these slides) Towards the discrete-time Fourier transform • How we will get there? • Periodic discrete-time signal representation by Discrete-time Fourier series • Extension to non-periodic DT signals using the “periodization trick” • Derivation of the Discrete Time Fourier Transform (DTFT) • Discrete Fourier Transform Discrete-time periodic signals • A periodic DT signal of period N0 is called N0-periodic signal f[n + kN0]=f[n] f[n] n N0 • For the frequency it is customary to use a different notation: the frequency of a DT sinusoid with period N0 is 2⇡ ⌦0 = N0 Fourier series representation of DT periodic signals • DT N0-periodic signals can be represented by DTFS with 2⇡ fundamental frequency ⌦ 0 = and its multiples N0 • The exponential DT exponential basis functions are 0k j⌦ k j2⌦ k jn⌦ k e ,e± 0 ,e± 0 ,...,e± 0 Discrete time 0k j! t j2! t jn! t e ,e± 0 ,e± 0 ,...,e± 0 Continuous time • Important difference with respect to the continuous case: only a finite number of exponentials are different! • This is because the DT exponential series is periodic of period 2⇡ j(⌦ 2⇡)k j⌦k e± ± = e± Increasing the frequency: continuous time • Consider a continuous time sinusoid with increasing frequency: the number of oscillations per unit time increases with frequency Increasing the frequency: discrete time • Discrete-time sinusoid s[n]=sin(⌦0n) • Changing the frequency by 2pi leaves the signal unchanged s[n]=sin((⌦0 +2⇡)n)=sin(⌦0n +2⇡n)=sin(⌦0n) • Thus when the frequency increases from zero, the number of oscillations per unit time increase until the frequency reaches pi, then decreases again towards the value that it had in zero.